一种中文字符串相似度算法
- 概要
- 标记距离相似算法
- 扩展
概要
给定一个字符串a,在字符串列表B中找到与a最相似字符串b,或者让列表B按与a相似度排序。本文提出一种算法来较好的解决这个问题。并且该算法很容易扩展支持拼音模糊相似度计算,在语音识别应用如语音搜索联系人打电话方面有较好的优势。
标记距离相似算法
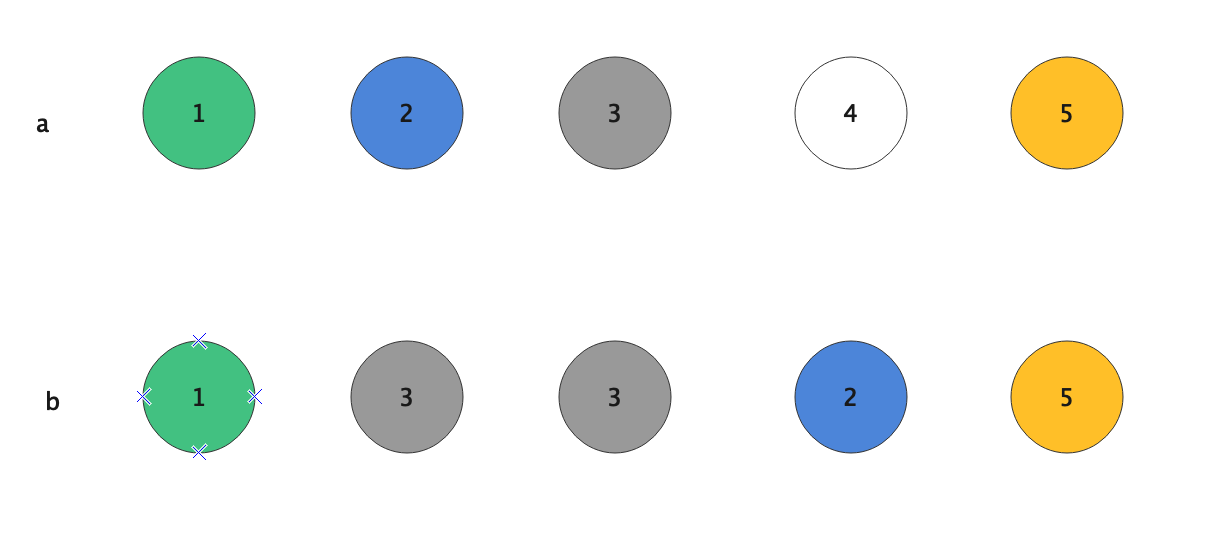
如图,我们需要计算a和b的相似度,需要执行三个步骤:
1、将a和b的相同字符一一进行标记,这里用相同颜色表示。
2、计算a每一个字符的相似得分。
3、将a的每一个字符最大得分相加就得到这两行字符串的总相似度分数。
第一步和第三步显然很简单,我们来讨论第二步,如何计算每个字符的相似得分:
我们这样定义相同字符的距离:
a和b中两个相同颜色字符的索引减去他们前面的相同颜色字符的索引之间的差就是这两个字符的距离。如上图,从左到右,设an和bm的颜色相同,ax和by的颜色相同,且an、bm是ax、by左边第一个满足Indexan < Indexax && Indexbm < Indexby,那么ax、by的相似距离就是:
d
=
∣
(
I
n
d
e
x
a
n
−
I
n
d
e
x
a
n
)
−
(
I
n
d
e
x
b
y
−
I
n
d
e
x
b
m
)
∣
d = |(Index_{a_n} - Index_{a_n}) - (Index_{b_y} - Index_{b_m})|
d=∣(Indexan−Indexan)−(Indexby−Indexbm)∣
在上面的例子中:
a1的距离为 |(0 - 0) - (0 - 0)| = 0
a2的距离为 |(1 - 0) - (3 - 0)| = 2
a3的距离有两个 |(2 - 0) - (1 - 0)| = 1; |(2 - 0) - (2 - 0)| = 0;
a4的距离为无穷大
a5的距离为 |(4 - 2) - (4 - 2)| = 0;
我们定义这样的一个单个字符相似得分公式:
s
=
1
(
1
+
d
)
s = frac {1} {(1 + d)}
s=(1+d)1
总相似得分公式为:
S
总
=
(
s
a
1
+
s
a
2
+
⋯
+
s
a
n
)
∗
S
u
m
a
h
i
t
S
u
m
a
n
S_总 = (s_{a_1} + s_{a_2} + cdots + s_{a_n}) * frac {Sum_{a_{hit}}} {Sum_{a_{n}}}
S总=(sa1+sa2+⋯+san)∗SumanSumahit
于是a1 = 1,a2 = 1/3,a3 = 1/2或1,a5 = 1,ahit标记总数为4,an总字符个数为5,所以a和b的相似度得分就是2.6666
上面的单个字符得分公式不是固定的,你也可以使用
S
=
2
(
2
+
d
)
S = frac {2} {(2 + d)}
S=(2+d)2
来计算,因为这只是相似字符的区分度问题,选择合适的公式来达到你想要的区分度。
扩展
在拼音模糊搜索中,可以根据拼音之间的相似度给得分公式乘以不同的系数。如liang和lian很相似,那么将这两个拼音也标记上同一种颜色,只是在计算得分时乘以系数比如: S = 1 ( 1 + d ) ∗ 0.9 S = frac {1} {(1 + d)} * 0.9 S=(1+d)1∗0.90.9就是这两个拼音的相似度。
通过该算法,开源了一个模糊搜索的Android项目,实现了字符串发音相似度模糊搜索功能,可以应用在语音查找联系人等场景。欢迎查看提出问题 https://github.com/bamboofly/vsearch
最后
以上就是开放啤酒最近收集整理的关于一种中文字符串相似度算法概要的全部内容,更多相关一种中文字符串相似度算法概要内容请搜索靠谱客的其他文章。








发表评论 取消回复