准备工作
首先是准备工作,导入需要使用的库,读取并创建数据表取名为loandata。
import numpy as np
import pandas as pd
loandata=pd.DataFrame(pd.read_excel('loan_data.xlsx'))

设置索引字段
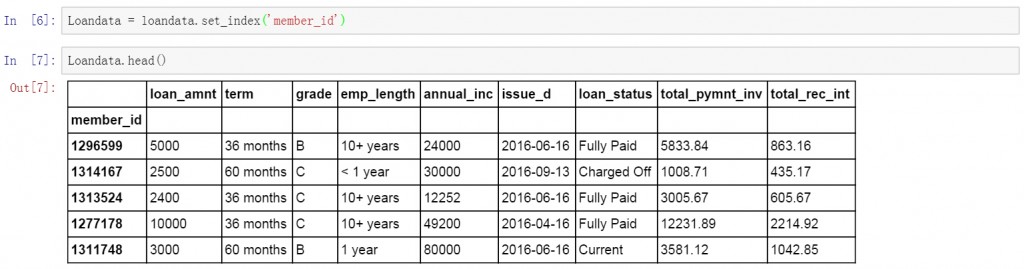
在开始提取数据前,先将member_id列设置为索引字段。然后开始提取数据。
Loandata = loandata.set_index('member_id')
按行提取信息
第一步是按行提取数据,例如提取某个用户的信息。下面使用ix函数对member_id为1303503的用户信息进行了提取。
loandata.ix[1303503]

按列提取信息
第二步是按列提取数据,例如提取用户工作年限列的所有信息,下面是具体的代码和提取结果,显示了所有用户的工作年龄信息。
loandata.ix[:,'emp_length']

按行与列提取信息
第三步是按行和列提取信息,把前面两部的查询条件放在一起,查询特定用户的特定信息,下面是查询member_id为1303503的用户的emp_length信息。
loandata.ix[1303503,'emp_length']

在前面的基础上继续增加条件,增加一行同时查询两个特定用户的贷款金额信息。具体代码和查询结果如下。结果中分别列出了两个用户的代码金额。
loandata.ix[[1303503,1298717],'loan_amnt']

在前面的代码后增加sum函数,对结果进行求和,同样是查询两个特定用户的贷款进行,下面的结果中直接给出了贷款金额的汇总值。
loandata.ix[[1303503,1298717],'loan_amnt'].sum()

除了增加行的查询条件以外,还可以增加列的查询条件,下面的代码中查询了一个特定用户的贷款金额和年收入情况,结果中分别显示了这两个字段的结果。
loandata.ix[1303503,['loan_amnt','annual_inc']]

多个列的查询也可以进行求和计算,在前面的代码后增加sum函数,对这个用户的贷款金额和年收入两个字段求和,并显示出结果。
loandata.ix[1303503,['loan_amnt','annual_inc']].sum()

提取特定日期的信息
数据提取中还有一种很常见的需求就是按日期维度对数据进行汇总和提取,如按月,季度的汇总数据提取和按特定时间段的数据提取等等。
设置索引字段
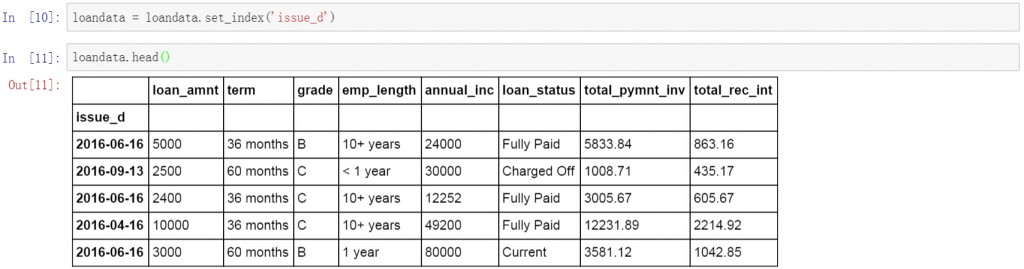
首先将索引字段改为数据表中的日期字段,这里将issue_d设置为数据表的索引字段。按日期进行查询和数据提取。
loandata = loandata.set_index('issue_d')
按日期提取信息
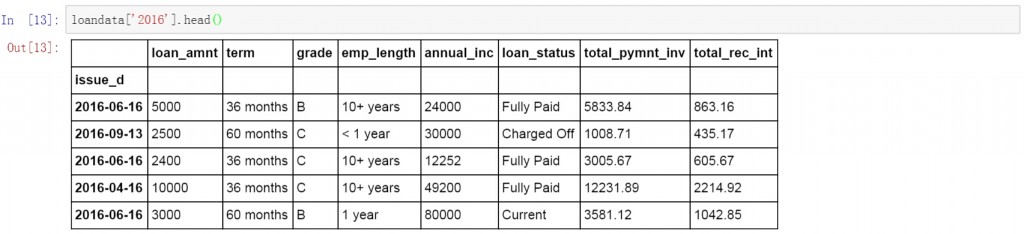
下面的代码查询了所有2016年的数据。
loandata['2016']
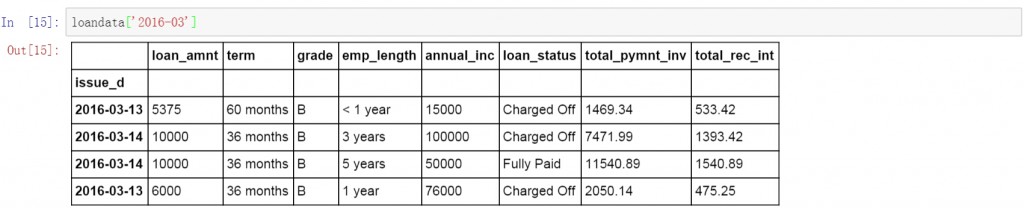
在前面代码的基础上增加月份,查询所有2016年3月的数据。
loandata['2016-03']
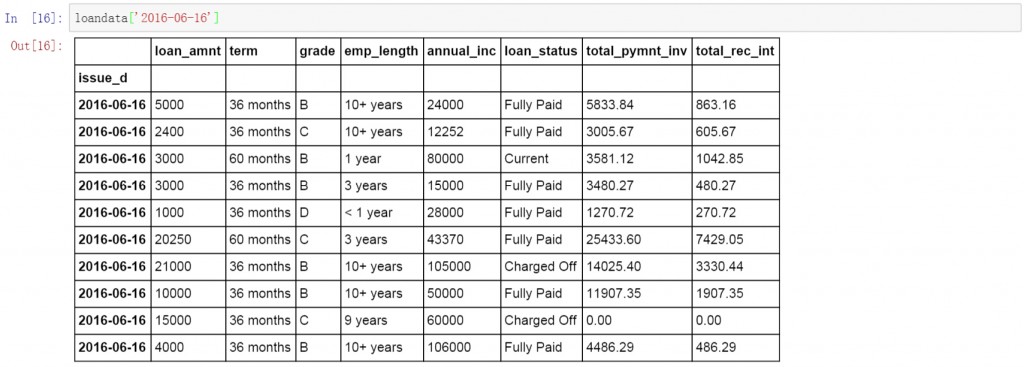
继续在前面代码的基础上增加日期,查询所有2016年6月16日的数据。
loandata['2016-06-16']
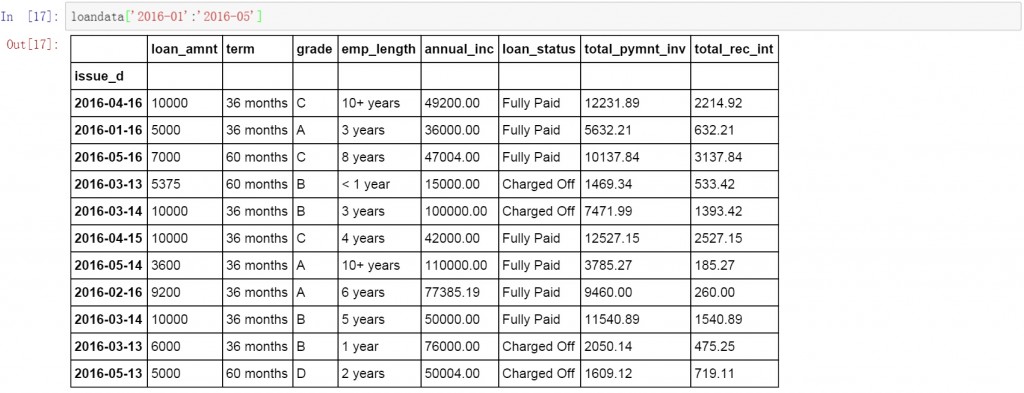
除了按单独日期查询以外,还可以按日期段进行数据查询,下面的代码中查询了所有2016年1月至5月的数据。下面显示了具体的查询结果,可以发现数据的日期都是在1-5月的,但是按日期维度显示的,这就需要我们对数据按月进行汇总。
loandata['2016-01':'2016-05']
按日期汇总信息
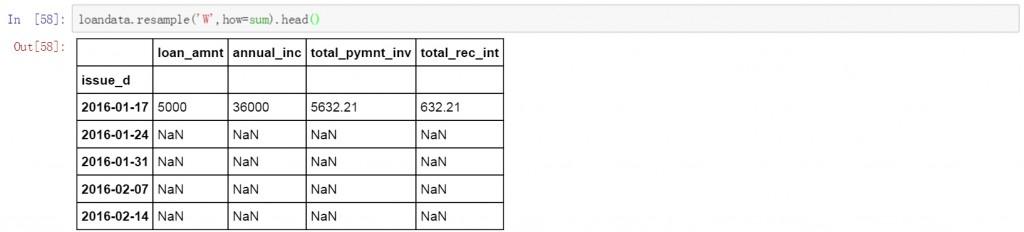
Pandas中的resample函数可以完成日期的聚合工作,包括按小时维度,日期维度,月维度,季度及年的维度等等。下面我们分别说明。首先是按周的维度对前面数据表的数据进行求和。下面的代码中W表示聚合方式是按周,how表示数据的计算方式,默认是计算平均值,这里设置为sum,进行求和计算。
loandata.resample('W',how=sum).head(10)
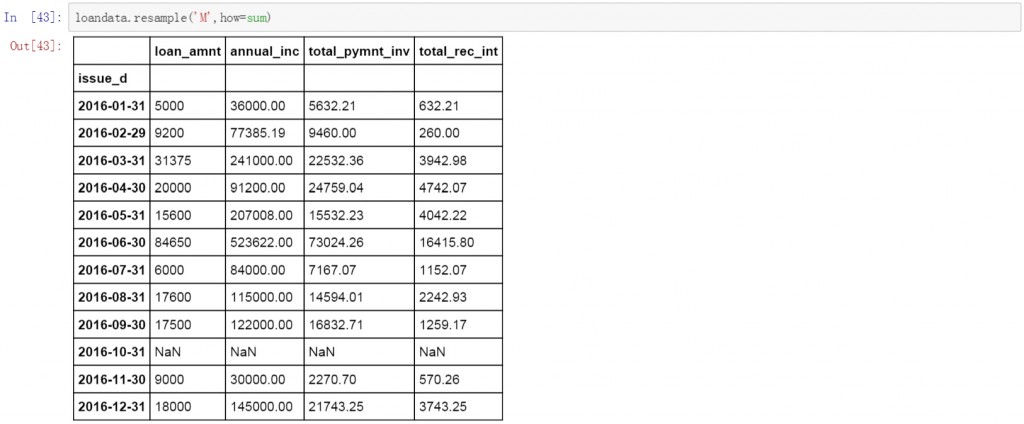
将W改为M,数据变成了按月聚合的方式。计算方式依然是求和。这里需要说明的是resample函数会显示出所有连续的时间段,例如前面按周的聚合操作会显示连续的周日期,这里的按月操作则会在结果中显示连续的月,如果某个时间段没有数据,会以NaN值显示。
loandata.resample('M',how=sum)
将前面代码中的M改为Q,则为按季度对数据进行聚合,计算方式依然为求和。从下面的数据表中看,日期显示的都是每个季度的最后一天,如果希望以每个季度的第一天显示,可以改为QS。
loandata.resample('Q',how=sum)

将前面代码中的Q改为A,就是按年对数据进行聚合,计算方式依然为求和。
loandata.resample('A',how=sum)

前面的方法都是对整个数据表进行聚合和求和操作,如果只需要对某一个字段的值进行聚合和求和,可以在数据表后增加列的名称。下面是将贷款金额字段按月聚合后求和,并用0填充空值。
loandata['loan_amnt'].resample('M',how=sum).fillna(0)
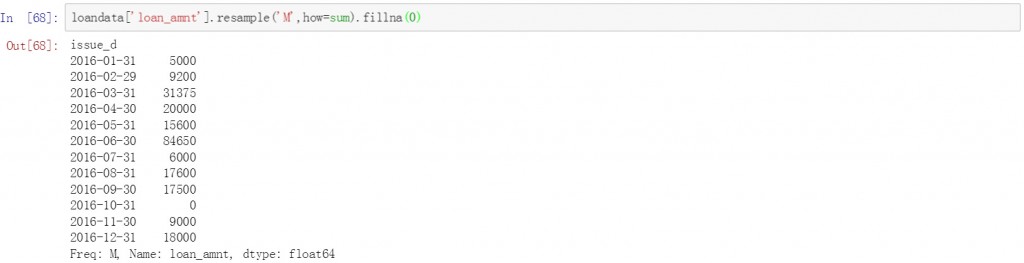
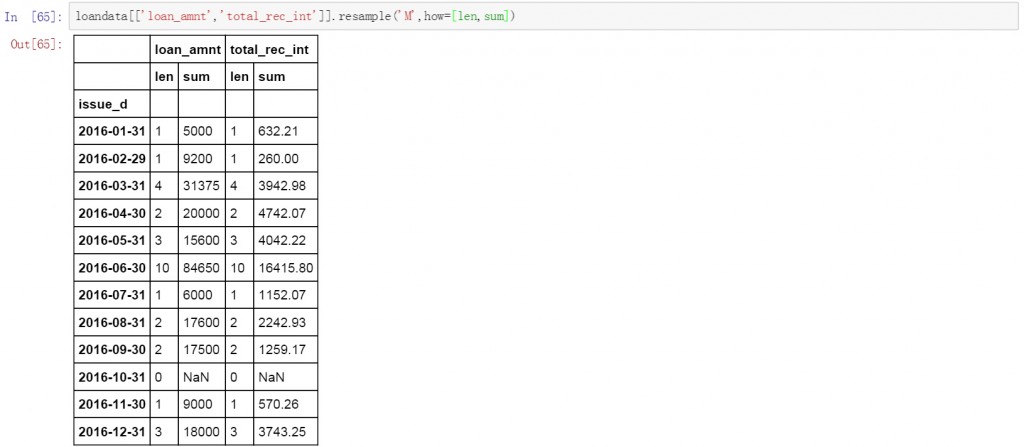
在前面代码的基础上再增加一个数值字段,并且在后面的计算方式中增加len用来计数。在下面的结果中分别对贷款金额和利息收入按月聚合,并进行求和和计数计算
loandata[['loan_amnt','total_rec_int']].resample('M',how=[len,sum])
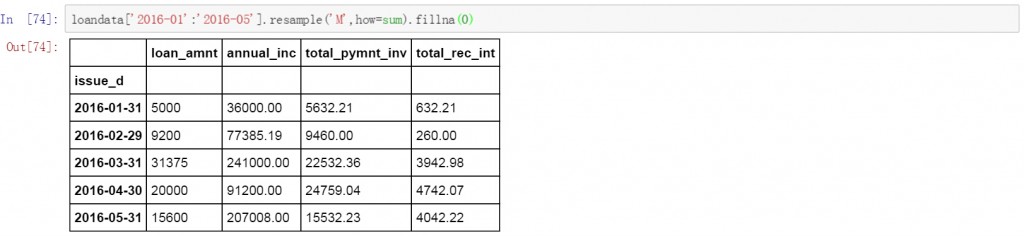
有时我们需要只对某一时间段的数据进行聚合和计算,下面的代码中对2016年1月至5月的数据按月进行了聚合,并计算求和。用0填充空值。
loandata['2016-01':'2016-05'].resample('M',how=sum).fillna(0)
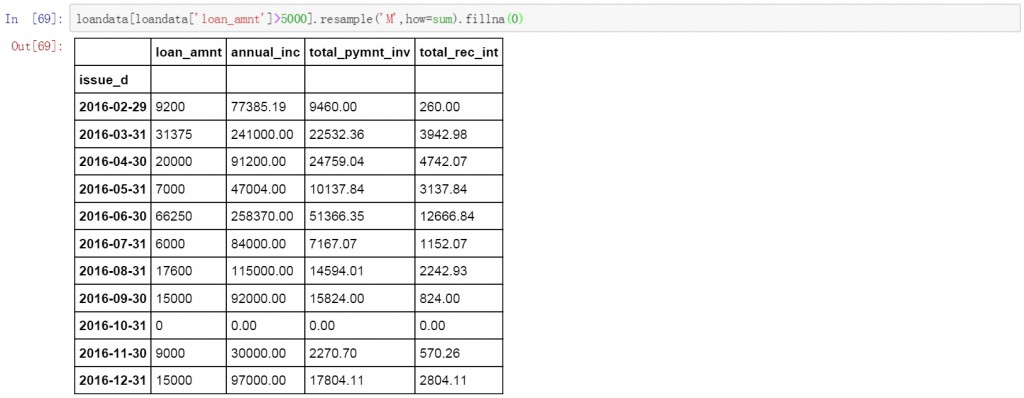
或者只对某些符合条件的数据进行聚合和计算。下面的代码中对于贷款金额大于5000的按月进行聚合,并计算求和。空值以0进行填充。
loandata[loandata['loan_amnt']>5000].resample('M',how=sum).fillna(0)
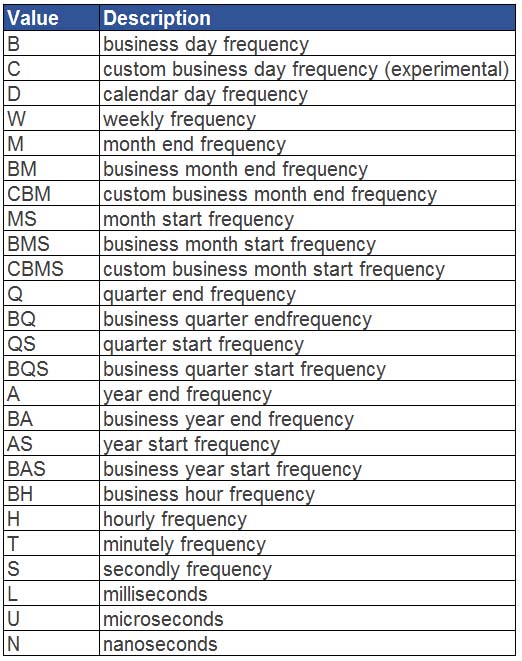
除了按周,月,季度和年以外,resample函数还可以按以下方式对日期进行聚合。
下面给出了具体的对应表和说明。
总结
以上就是利用python按特定的维度或条件对数据进行提取的全部内容,希望本文的内容对大家学习使用Python能有所帮助。
最后
以上就是舒适黄蜂最近收集整理的关于Python进行数据提取的方法总结的全部内容,更多相关Python进行数据提取内容请搜索靠谱客的其他文章。








发表评论 取消回复