在CV方向得模型搭建中,我们常常需要对输入得图片进行数据增强,这将会减少模型对数据的过拟合从儿提升模型的性能。在实际工程中。如工业缺陷、医疗图像等场景,我们获得的数据毕竟有限,通过数据增强来提升模型的性能是非常有用的。此时只能够依靠图像增强的方法来建立训练所需要的数据集。
目录
一、监督的数据增强
1.1、单样本数据增强
1.1.1、 几何空间变换
1.1.2、像素颜色变换类
1.2、多样本合成类
1.2.1、 SMOTE
1.2.2、SamplePairing
1.2.3、 mixup
1.3、实战:tf.data中数据增强的实现
1.3.1、Tensorflow中imgaug库的使用
1.3.2、Tensorflow中mixup数据增强的实现
二、无监督的数据增强
2.1、GAN
2.2、AutoAugment
这里我们介绍一种比较强大的数据增强工具,所有你能想到的增强方法都有——imgaug。imgaug是用于机器学习实验中图像增强的库。它支持广泛的扩充技术,可以轻松地组合它们并以随机顺序或在多个CPU内核上执行它们,具有简单而强大的随机界面,不仅可以扩充图像,还可以扩充关键点/地标,边界框,热图和分段图。

imgaug安装命令:
pip install imgaug这里先介绍常用的数据增强方法,后续介绍如何在Tensorflow2中应用这些增强方法。
具体使用方法,如下:
import cv2
import imgaug.augmenters as iaa
seq = iaa.Sequential([
iaa.Fliplr(0.5), # horizontally flip 50% of the images
])
img=cv2.imread("D:\PycharmProjects\my_project\GHIM-20\GHIM-20\19\19_9597.jpg")
[img_seq,]=seq(images=[img])
cv2.imshow("test",img_seq)
cv2.waitKey(0)显示结果:

一、监督的数据增强
1.1、单样本数据增强
1.1.1、 几何空间变换
几何变换类即对图像进行几何变换,包括翻转,旋转,裁剪,变形,缩放等各类操作。
- 翻转
翻转包括水平翻转和垂直翻转。
iaa.Fliplr(0.5) # 左右翻转
iaa.Flipud(1) #上下翻转
- 剪切
裁剪图片的感兴趣区域(ROI),通常在训练的时候,会采用随机裁剪的方法。
剪切和padding
iaa.CropAndPad(px=None,
percent=None,
pad_mode='constant',
pad_cval=0,
keep_size=True,
sample_independently=True,
name=None,
deterministic=False,
random_state=None)
参数:
- px: 想要crop(negative values)的或者pad(positive values)的像素点。注意与percent不能同时存在。如果是None, pixel级别的crop不会被使用。int或者int list与上面相同。如果是一个4个元素的tuple,那么4个元素分别代表(top, right, bottom, left),每个元素可以是int或者int tuple或者int list。
- percent:按比例来crop或者pad, 与px相同。但是两者不能同时存在。
- pad_mode: 填充方式。可以是All, string, string list。可选的填充方式有:
constant, edge, linear_ramp, maximum, median, minimum, reflect, symmetric, wrap。具体含义可查numpy文档。 - pad_cval:
float、int、float tuple、int tuple、float list、int list。当pad_mode=constant的时候选择填充的值。 - keep_size: bool类型。经过crop后,图像大小会改变。如果该值设置为1,则在crop或者pad后再缩放成原来的大小。
- sample_independently : bool类型。如果设置为False,则每次从px或者percent中选出来的值会作用在四个方位。
剪切
iaa.Crop((0,0,100,100))
- 仿射类
同时对图片做裁剪、旋转、转换、模式调整等多重操作。例如,这里对图像做-30~30度之间旋转操作。
iaa.Affine(rotate=(-30, 30))
- 缩放变形
随机选取图像的一部分,然后将其缩放到原图像尺度。例如,将每个图像的大小调整为高度=100和宽度=100:
iaa.Resize({"height": 100, "width": 100})
1.1.2、像素颜色变换类
- 噪声类
随机噪声是在原来的图片的基础上,随机叠加一些噪声。
#高斯噪声(又称白噪声)。
#将高斯噪声添加到图像中,每个像素从正态分布N(0,s)采样一次,其中s对每个图像采样并在0和0.05 * 255之#间变化:
iaa.AdditiveGaussianNoise(scale=(0, 0.05 * 255))
#矩形丢弃增强器
#在面积大小可选定、位置随机的矩形区域上丢失信息实现转换,所有通道的信息丢失产生黑色矩形块,部分通道
#的信息丢失产生彩色噪声。
#通过将所有像素转换为黑色像素来丢弃2%,但是在具有原始大小的50%的图像的较低分辨率版本上执行此操作,#丢弃2x2的正方形:
iaa.CoarseDropout(0.02, size_percent=0.5)
#丢弃2%的图像,但是在具有原始大小的50%的图像的较低分辨率版本上执行此操作,丢弃2x2个正方形。 此
#外,在50%的图像通道中执行此操作,以便仅将某些通道的信息设置为0,而其他通道保持不变:
iaa.CoarseDropout(0.02, size_percent=0.5, per_channel=0.5)
- 模糊类
减少各像素点值的差异实现图片模糊,实现像素的平滑化。
#使用高斯内核模糊图像的增强器。用高斯内核模糊每个图像,sigma为3.0:
iaa.GaussianBlur(sigma=(0.0, 3.0))
#像素位移增强器
#通过使用位移字段在本地移动像素来转换图像。
#通过在强度为0.25的失真场后移动单个像素来局部扭曲图像。 每个像素的移动强度范围为0到5.0:
iaa.ElasticTransformation(alpha=(0, 5.0), sigma=0.25)
- HSV对比度变换
通过向HSV空间中的每个像素添加或减少V值,修改色调和饱和度实现对比度转换。
iaa.WithColorspace(
to_colorspace="HSV",
from_colorspace="RGB",
children=iaa.WithChannels(0, iaa.Add((10, 50)))
- RGB颜色扰动
将图片从RGB颜色空间转换到另一颜色空间,增加或减少颜色参数后返回RGB颜色空间。
#每个图像转换成一个彩色空间与亮度相关的信道,提取该频道,之间加-30和30并转换回原始的色彩空间。
iaa.AddToBrightness((-30, 30))
#从离散的均匀范围中采样随机值[-50..50],将其转换为角度表示形式,并将其添加到色相(即色空间中的H通
#道)中HSV。
iaa.AddToHue((-50, 50))
#通过随机值增加或减少色相和饱和度。
#增强器首先将图像转换为HSV色彩空间,然后向H和S通道添加随机值,然后转换回RGB。
#在色相和饱和度之间添加随机值(对于每个通道独立添加-100,100对于该通道内的所有像素均添加相同的
#值)。
iaa.AddToHueAndSaturation((-100, 100), per_channel=True)
#将随机值添加到图像的饱和度。
#增强器首先将图像转换为HSV色彩空间,然后将随机值添加到S通道,然后转换回RGB。
#如果要同时更改色相和饱和度,建议使用AddToHueAndSaturation,否则图像将被两次转换为HSV并返RGB。
#从离散的均匀范围内采样随机值[-50..50],并将其添加到饱和度,即添加到 色彩空间中的S通道HSV。
iaa.AddToSaturation((-50, 50))
- 超像素法(Superpixels)
在最大分辨率处生成图像的若干个超像素,并将其调整到原始大小,再将原始图像中所有超像素区域按一定比例替换为超像素,其他区域不改变。
#完全或部分地将图像变换为其超像素表示。
#每个图像生成大约64个超像素。 用平均像素颜色替换每个概率为50%。
iaa.Superpixels(p_replace=0.5, n_segments=64)
- 锐化(sharpen)与浮雕(emboss)
对图像执行某一程度的锐化或浮雕操作,通过某一通道将结果与图像融合。
#锐化图像,然后使用0.0到1.0之间的alpha将结果与原始图像重叠:
iaa.Sharpen(alpha=(0.0, 1.0), lightness=(0.75, 2.0))
#浮雕图像,然后使用0.0到1.0之间的alpha将结果与原始图像叠加:
iaa.Emboss(alpha=(0.0, 1.0), strength=(0.5, 1.5))
1.2、多样本合成类
1.2.1、 SMOTE
SMOTE,Synthetic Minority Over-sampling Technique,通过人工合成新样本来处理样本不平衡问题,提升分类器性能。
SMOTE原理:
-
选一个少数样本
-
对每一个小样本类样本(x,y),按欧氏距离找K个最近邻样本
-
从K个最近邻样本中随机选取一个样本点,假设选择的近邻点为(xn,yn)。在小样本类样本(x,y)与最近邻样本点(xn,yn)的连线段上随机选取一点作为新样本点,满足以下公式:
-
重复选取取样,直到大、小样本数量平衡。
在python中,SMOTE算法已经封装到了imbalanced-learn库中,如下图为算法实现的数据增强的实例,左图为原始数据特征空间图,右图为SMOTE算法处理后的特征空间图。
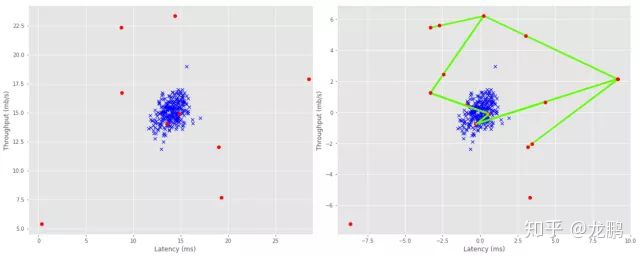
参考链接:
SMOTE__简单原理图示_算法实现及R和Python调包简单实现
1.2.2、SamplePairing
SamplePairing方法的处理流程如下图所示,从训练集中随机抽取两张图片分别经过基础数据增强操作(如随机翻转等)处理后经像素取平均值的形式叠加合成一个新的样本,标签为原样本标签中的一种。
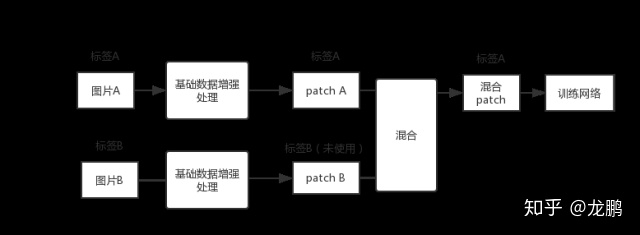
经SamplePairing处理后可使训练集的规模从N扩增到N*N,在CPU上也能完成处理。训练过程是交替禁用与使用SamplePairing处理操作的结合:
- 使用传统的数据增强训练网络,不使用SamplePairing 数据增强训练;
- 在ILSVRC数据集上完成一个epoch或在其他数据集上完成100个epoch后,加入SamplePairing 数据增强训练;
- 间歇性禁用 SamplePairing。对于 ILSVRC 数据集,为其中的300000 个图像启用SamplePairing,然后在接下来的100000个图像中禁用它。对于其他数据集,在开始的8个epoch中启用,在接下来的2个epoch中禁止;
- 在训练损失函数和精度稳定后进行微调,禁用SamplePairing。
实验结果表明,因SamplePairing数据增强操作可能引入不同标签的训练样本,导致在各数据集上使用SamplePairing训练的误差明显增加,而在检测误差方面使用SamplePairing训练的验证误差有较大幅度降低。尽管SamplePairing思路简单,性能上提升效果可观,符合奥卡姆剃刀原理,遗憾的是的可解释性不强,目前尚缺理论支撑。目前仅有图片数据的实验,还需下一步的实验与解读。
1.2.3、 mixup
mixup是基于邻域风险最小化(VRM)原则的数据增强方法,使用线性插值得到新样本数据。在邻域风险最小化原则下,根据特征向量线性插值将导致相关目标线性插值的先验知识,可得出简单且与数据无关的mixup公式:
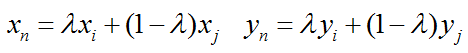
其中(xn,yn)是插值生成的新数据,(xi,yi) 和 (xj,yj)是训练集中随机选取的两个数据,λ的取值满足贝塔分布,取值范围介于0到1,超参数α控制特征目标之间的插值强度。
mixup的实验丰富,实验结果表明可以改进深度学习模型在ImageNet数据集、CIFAR数据集、语音数据集和表格数据集中的泛化误差,降低模型对已损坏标签的记忆,增强模型对对抗样本的鲁棒性和训练对抗生成网络的稳定性。mixup处理实现了边界模糊化,提供平滑的预测效果,增强模型在训练数据范围之外的预测能力。随着超参数α增大,实际数据的训练误差就会增加,而泛化误差会减少。说明mixup隐式地控制着模型的复杂性。随着模型容量与超参数的增加,训练误差随之降低。尽管有着可观的效果改进,但mixup在偏差—方差平衡方面尚未有较好的解释。在其他类型的有监督学习、无监督、半监督和强化学习中,mixup还有很大的发展空间。
小结:mixup、SMOTE、SamplePairing三者思路上有相同之处,都是试图将离散样本点连续化来拟合真实样本分布,但所增加的样本点在特征空间中仍位于已知小样本点所围成的区域内。但在特征空间中,小样本数据的真实分布可能并不限于该区域中,在给定范围之外适当插值,也许能实现更好的数据增强效果。
参考连接:
深度学习 | 训练网络trick——mixup
1.3、实战:tf.data中数据增强的实现
1.3.1、Tensorflow中imgaug库的使用
import imgaug.augmenters as iaa
#添加需要增强的操作
self.augmenter = iaa.Sequential([
iaa.Fliplr(config.sometimes),
iaa.Crop(percent=config.crop_percent),
...
], random_order=config.random_order)
#封装增强函数
def augment_fn(self):
def augment(images, labels):
img_dtype = images.dtype
img_shape = tf.shape(images)
images = tf.numpy_function(self.augmenter.augment_images,[images],img_dtype)
images = tf.reshape(images, shape = img_shape)
return images, labels
return augment1.3.2、Tensorflow中mixup数据增强的实现
参考连接:https://github.com/OFRIN/Tensorflow_MixUp/blob/master/Train_MixUp.py
MIXUP_ALPHA = 0.2
BATCH_SIZE = 64
# MixUp Function
def MixUp(images, labels):
indexs = np.random.permutation(BATCH_SIZE)
alpha = np.random.beta(MIXUP_ALPHA, MIXUP_ALPHA, BATCH_SIZE)
image_alpha = alpha.reshape((BATCH_SIZE, 1, 1, 1))
label_alpha = alpha.reshape((BATCH_SIZE, 1))
x1, x2 = images, images[indexs]
y1, y2 = labels, labels[indexs]
images = image_alpha * x1 + (1 - image_alpha) * x2
labels = label_alpha * y1 + (1 - label_alpha) * y2
return images, labels
二、无监督的数据增强
无监督数据增强主要包括两类:
- 通过模型学习数据的分布,随机生成与训练数据集分布一致的图片,代表方法,GAN。
- 通过模型,学习出适合当前任务的数据增强方法,代表方法,AutoAugment。
2.1、GAN
generative adversarial networks,译名生成对抗网络 ,它包含两个网络,一个是生成网络,一个是对抗网络,基本原理如下:
- G是一个生成图片的网络,它接收随机的噪声z,通过噪声生成图片,记做G(z) 。
- D是一个判别网络,判别一张图片是不是“真实的”,即是真实的图片,还是由G生成的图片。
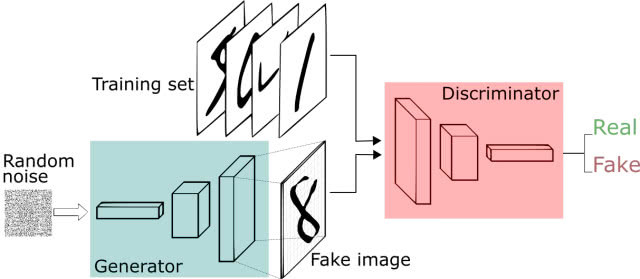
2.2、AutoAugment
虽然这是一篇论文,但是也可以看作一个研究方向。它的基本思路:使用增强学习从数据本身寻找最佳图像变换策略,对于不同的任务学习不同的增强方法。
基本原理:
- 准备16个数据增强操作。
- 从16个中选择5个操作,随机产生使用该操作的概率和幅度,将其称为一个sub-policy,一共产生5个sub-polices。
- 每一个batch中的图片,随机采用5个sub-polices操作中的一种。
- 通过childmodel在验证集上的泛化能力来反馈,使用增强学习方法。
- 经过80~100个epoch后开始有效果,能学习到sub-policies。
- 串接这5个sub-policies,然后再进行最后的训练。
参考链接:
【技术综述】深度学习中的数据增强方法都有哪些?
Python—imgaug图像数据增强,Pythonimgaug,图片
imgaug数据增强神器:增强器一览
最后
以上就是迷你音响最近收集整理的关于Tensorflow2 常见的数据增强方法及其实现汇总一、监督的数据增强二、无监督的数据增强的全部内容,更多相关Tensorflow2内容请搜索靠谱客的其他文章。








发表评论 取消回复