我们知道无论是pytorch还是keras中,数据生成器DataGenerator都是很重要的一个部分。对于常规8位灰度图或者彩色图,框架爱提供的API足够我们使用,但是对于特定场景比如医学图像16位数据时就不能采用该模式(至少我是没找到加载16位图的方式,谁找到可以联系告诉我),这时候还是需要我们实际重写该部分;
fit_generator 训练逻辑过程 (极重要!)
可以看出来fit_generator使用过程中在每个epoch结束后没有进行重置,这一点看了源码才了解其工作机制。
callbacks.on_train_begin()
while epoch < epochs:
callbacks.on_epoch_begin(epoch)
while steps_done < steps_per_epoch:
#generator_output是一个死循环while True,因为model.fit_generator()在使用在个函数的时候, 并不会在每一个epoch之后重新调用,那么如果这时候generator自己结束了就会有问题。
generator_output = next(output_generator) #生成器next函数取输入数据进行训练,每次取一个batch大小的量
callbacks.on_batch_begin(batch_index, batch_logs)
outs = self.train_on_batch(x, y,sample_weight=sample_weight,class_weight=class_weight)
callbacks.on_batch_end(batch_index, batch_logs)
end of while steps_done < steps_per_epoch
self.evaluate_generator(...) #当一个epoch的最后一次batch执行完毕,执行一次训练效果的评估
callbacks.on_epoch_end(epoch, epoch_logs) #在这个执行过程中实现模型数据的保存操作
end of while epoch < epochs
callbacks.on_train_end()
``
# 回调函数
通过传递回调函数列表到模型的.fit()中,即可在给定的训练阶段调用该函数集中的函数。eras的回调函数是一个类
```python
keras.callbacks.Callback()
https://blog.csdn.net/weixin_42612033/article/details/85410788?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-2.control
fit_generator API与示例
def fit_generator(self, generator,
steps_per_epoch=None,
epochs=1,
verbose=1,
callbacks=None,
validation_data=None,
validation_steps=None,
class_weight=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
shuffle=True,
initial_epoch=0): def generate_arrays_from_file(path):
while True:
with open(path) as f:
for line in f:
# create numpy arrays of input data
# and labels, from each line in the file
x1, x2, y = process_line(line)
yield ({'input_1': x1, 'input_2': x2}, {'output': y})
model.fit_generator(generate_arrays_from_file('./my_folder'),
steps_per_epoch=10000, epochs=10)一个改造fit_generator的例子: https://www.zywvvd.com/2020/06/10/deep_learning/keras/get-gts-and-preds-from-evaluator/get-gts-and-preds-from-evaluator/
1.二分类问题
# coding=utf-8
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import numpy as np
import cv2
import os
data_gen_args = dict(rotation_range=10,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
zoom_range=0.05,
fill_mode='nearest')
save_to_dir=r"./result"
image_datagen = ImageDataGenerator(**data_gen_args)
image_generator = image_datagen.flow_from_directory(r"./img2",
color_mode="grayscale",
# classes=["1","2","3"],
class_mode="binary",
batch_size=4,
shuffle=True,
)
for i in range(1):
batch=image_generator.next()
#这里的gener的格式为[2,row,col,3],是网络可以输入的rensor格式,可以对其进行拆分
# print(img.shape)
# print("batch.shape:",batch.shape)
print("batch: ",batch)
print("label: ",batch[1])
print(batch[0].shape)
print(batch[1].shape)
image1=batch[0][0,:,:,:]
image2=batch[0][1,:,:,:]
print(image1.shape)
print(image2.shape)
# print(np.max(image1))
# label=batch[1]
print(batch[1])
# gener.next()
# next(gener)
prefix1=str(i+1).zfill(3)+"batch1_"+".png"
prefix2=str(i+1).zfill(3)+"batch2_"+".png"
# print(prefix1)
# print(os.path.join(save_to_dir,prefix1))
# print(os.path.join(save_to_dir,prefix2))
cv2.imwrite(os.path.join(save_to_dir,prefix1),image1)
cv2.imwrite(os.path.join(save_to_dir,prefix2),image2)
# cv2.imshow("2",image)
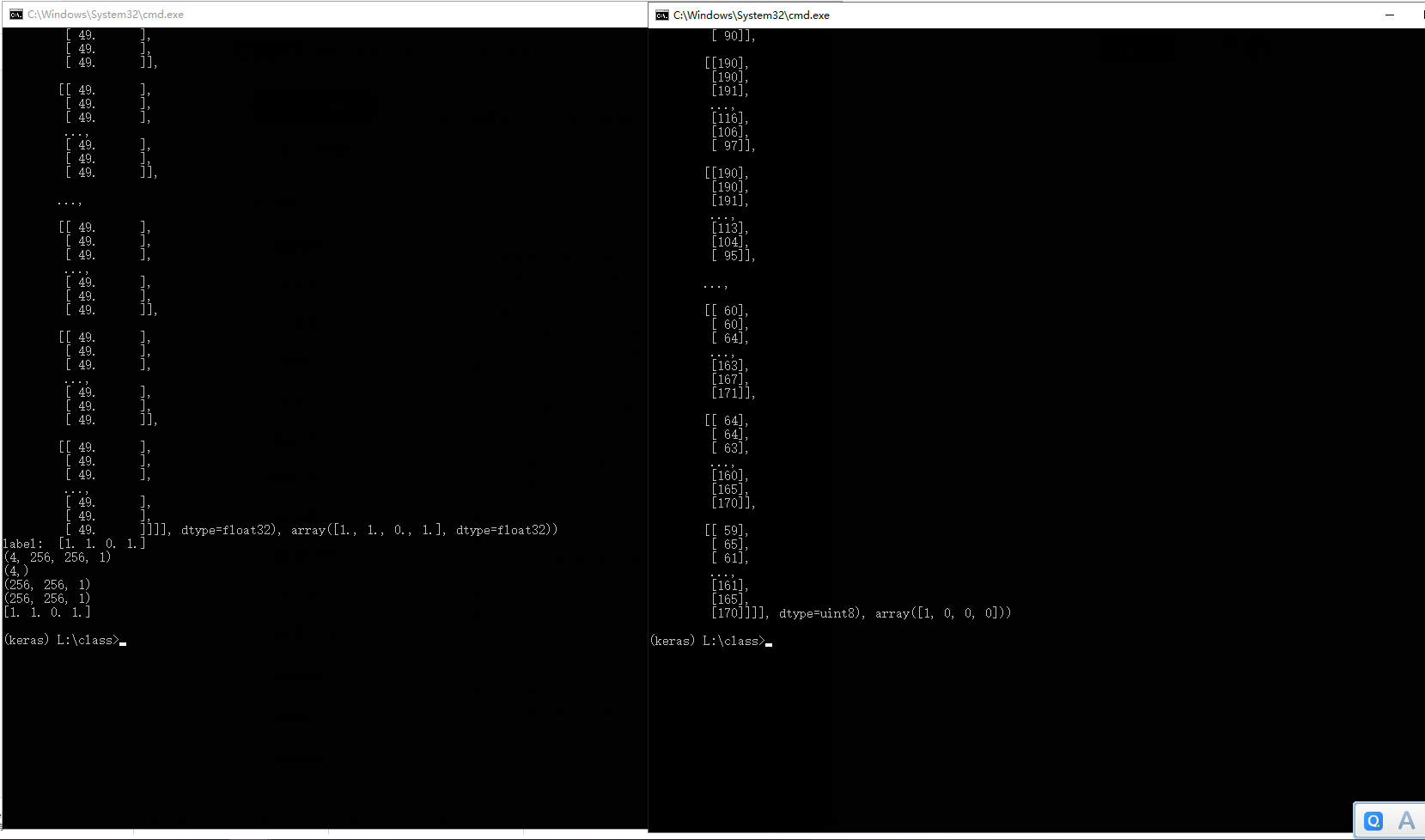
cv2.waitKey(10)重要研究下,batch_size=4时候,keras的生成器输出的batch数据为两个数组组成的元组,前个是四幅图,后个是四个图对应的标签,从batch[0](图像)和batch[1](标签)就可以看出来其结构。
batch[0].shape:(4, 256, 256, 1)
batch[0].shape:(4,)
输出:
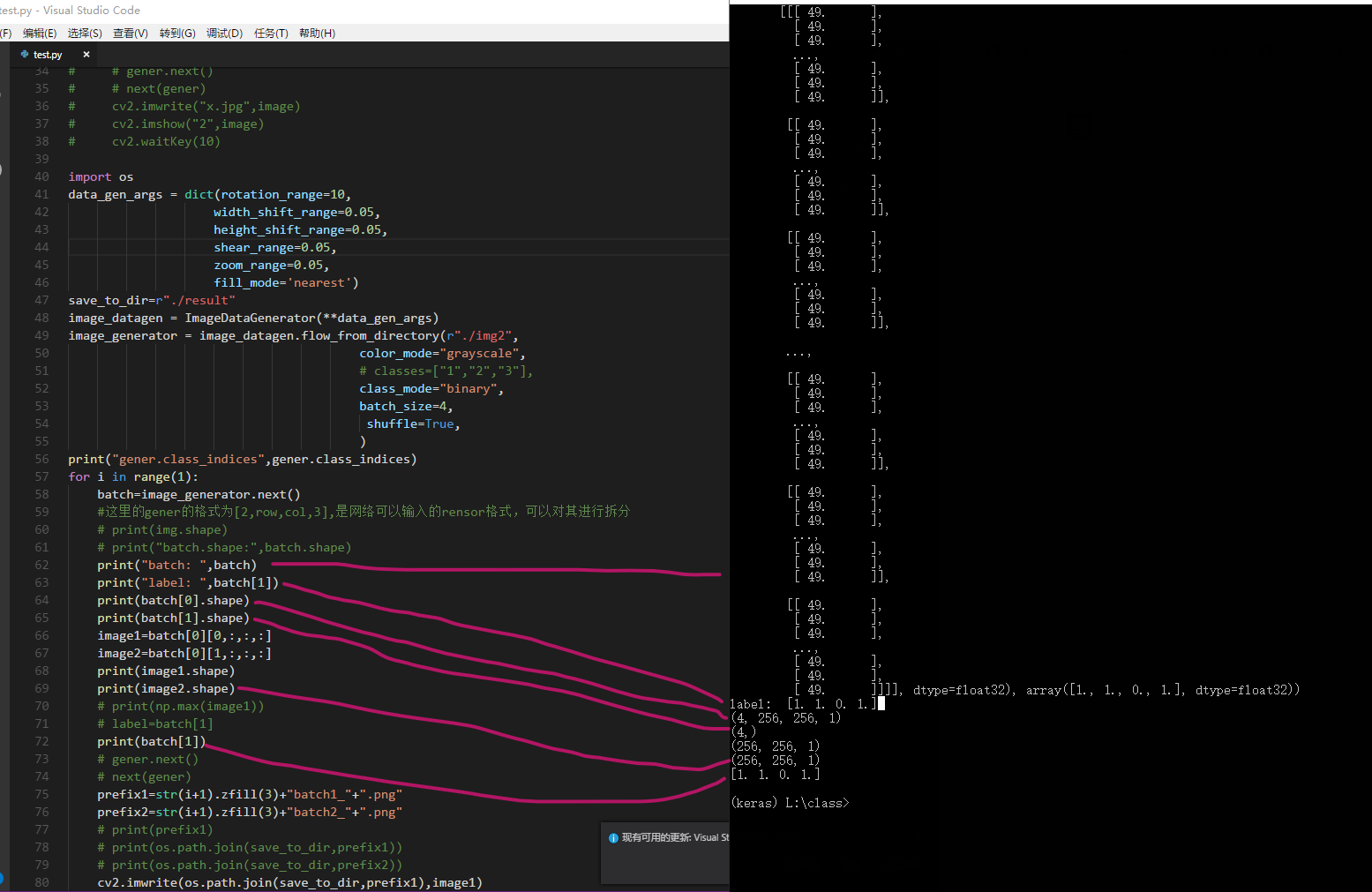
经过上面的输出分析,我们可以根据自己的数据特征来重写构造;
import numpy as np
import cv2
import os
path = r'L:classimg2'
img_list=[]
label_list=[]
batch_size=4
epochs=2
filelist = os.listdir(path)
# 三个if目的是为了找到矢状位的.lst文件路径
for name in filelist:
dirname=os.path.join(path,name) #F:zhangqmodeltestdata20180910 童艳玲 多肌 术前
for maindir, subdir, file_name_list in os.walk(dirname):
for f in file_name_list:
pathx=os.path.join(maindir,f)
path_tem=os.path.join(maindir,f)
#print(os.path.join(maindir,f))
try:
if pathx.find("jpg") != -1 or pathx.find("png")!=-1:
print(pathx)
img_list.append(pathx)
print((os.path.basename(pathx)).split("_")[0])
label=(os.path.basename(pathx)).split("_")[0]
label_list.append(int(label))
except:
continue
# 一次性把全部批次需要迭代的id放入列表中一批批yield
print(len(label_list))
print(len(img_list))
imgs_total=[]
masks_total=[]
# 每个epoch需要shuffle一次文件名列表
import random
reminder=len(img_list) % batch_size
for e in range(epochs):
# img_temp=os.listdir(os.path.join(train_path,image_folder))
# mask_temp=os.listdir(os.path.join(train_path,mask_folder))
# img_temp=sorted(img_temp,key=lambda i:int(os.path.basename(i).split(".")[0]))
# mask_temp=sorted(mask_temp,key=lambda i:int(os.path.basename(i).split(".")[0]))
img_list1=[]
label_list1=[]
label_list1.extend(label_list)
img_list1.extend(img_list)
for re in range(batch_size-reminder):
img_list1.append(img_list[re])
label_list1.append(label_list[re])
# # print("epoch: ",len(img_temp))
c=list(zip(img_list1,label_list1))
random.shuffle(c)
imgs,masks=zip(*c)
imgs_total.extend(imgs)
masks_total.extend(masks)
# # imgs=img_temp
# # masks=mask_temp
# imgs_total.extend(img_list1)
# masks_total.extend(label_list1)
print(imgs_total)
print(masks_total)
print("reminder:",reminder)
print("len:",len(imgs_total))
print("len:",len(masks_total))
for i in range(0,len(imgs_total),batch_size):
temp_img=imgs_total[i:i+batch_size]
temp_mask=masks_total[i:i+batch_size]
# print("i+batch_size: ",i+batch_size)
data_img=np.zeros((batch_size,320,320,1),dtype=np.uint8)
# data_mask=np.zeros((len(temp_mask)),dtype=np.uint8)
data_mask=[]
for j in range(batch_size):
# print(os.path.join(os.path.join(train_path,image_folder),temp_img[j]))
img=cv2.imread(temp_img[j],0)
# print("path:",temp_img[j])
if img is None:
print("no pic")
# print(img.dtype)
img=cv2.resize(img,(320,320),1)
# img=img.astype(np.float32)
# img=norm_img(img)
data_img[j,...,0]=img
data_mask.append(temp_mask[j])
# print(data_mask[j])
print("data_mask: ",data_mask) #data_mask: [2, 1, 1, 2]
labels=np.array(data_mask) #数组没有逗号
labels=np.where(labels==1,0,labels)
labels=np.where(labels==2,1,labels)
print("labels: ",labels) #labels: [1 1 0 0]
print("labels: ",list(labels)) #labels: [1, 1, 0, 0]
# labels=np.zeros((len(data_mask)))
# labels[]
# labels=np.array(data_mask)
# print(labels)
# labels=convert_to_one_hot(labels,num_classes=2)
# # print(labels)
batch_tup=(data_img,labels)
print(batch_tup)
# img_onehot,mask_onehot = adjustData(data_img,data_mask,flag_multi_class,num_class)
# yield img_onehot,mask_onehot二分类的输出对比,我们发现格式和keras自带的是一样的;
二,多分类问题
同理文件结构和代码如下;
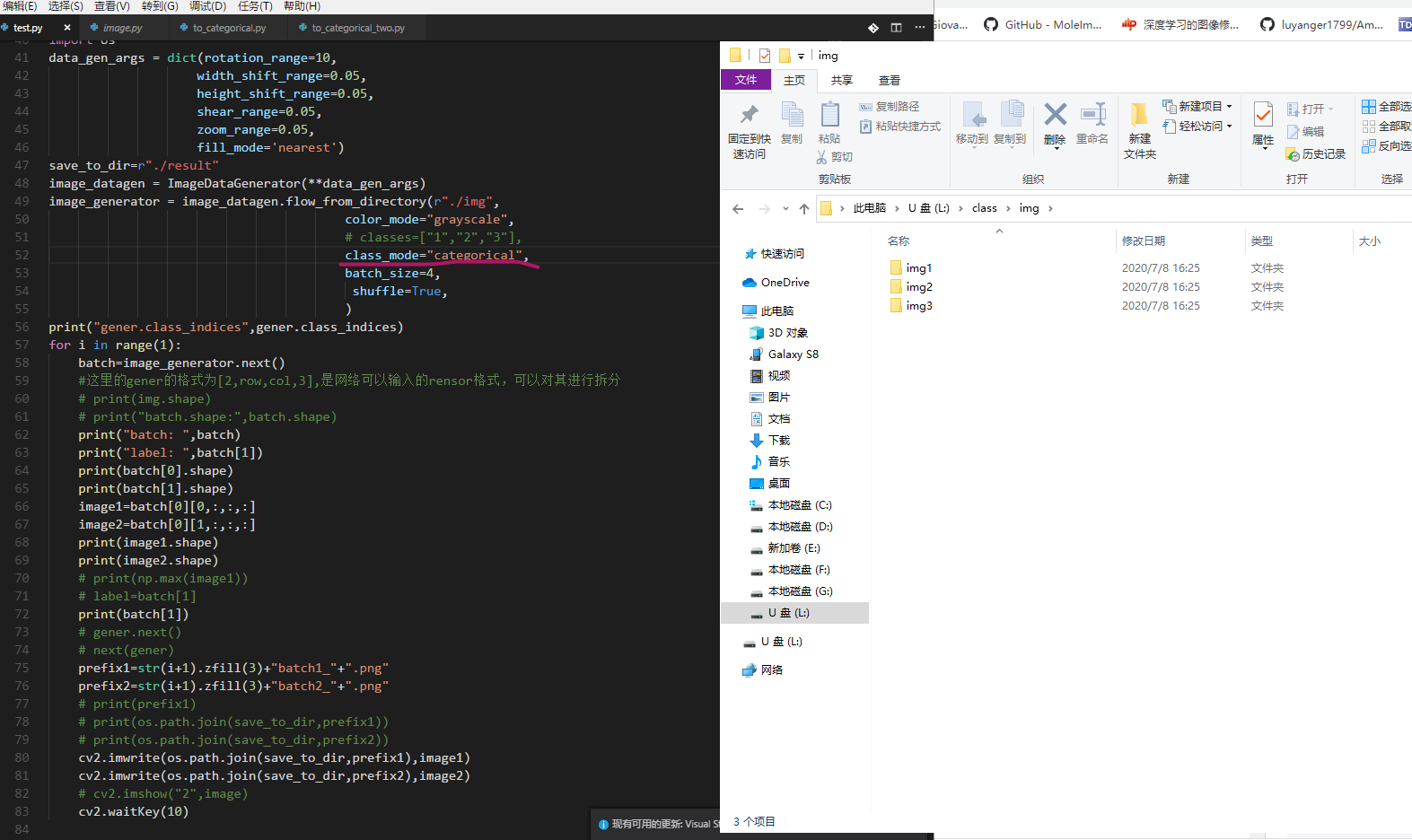
唯一的不同之处是要设置class_mode='categorical',而不是原来二分类问题的class_mode='binary',我们发现元组中后一个元素也就是标签数组部分(batch[1])有改变,是经过one_hot转化后的而不是之前的一位数组,其他部分不变;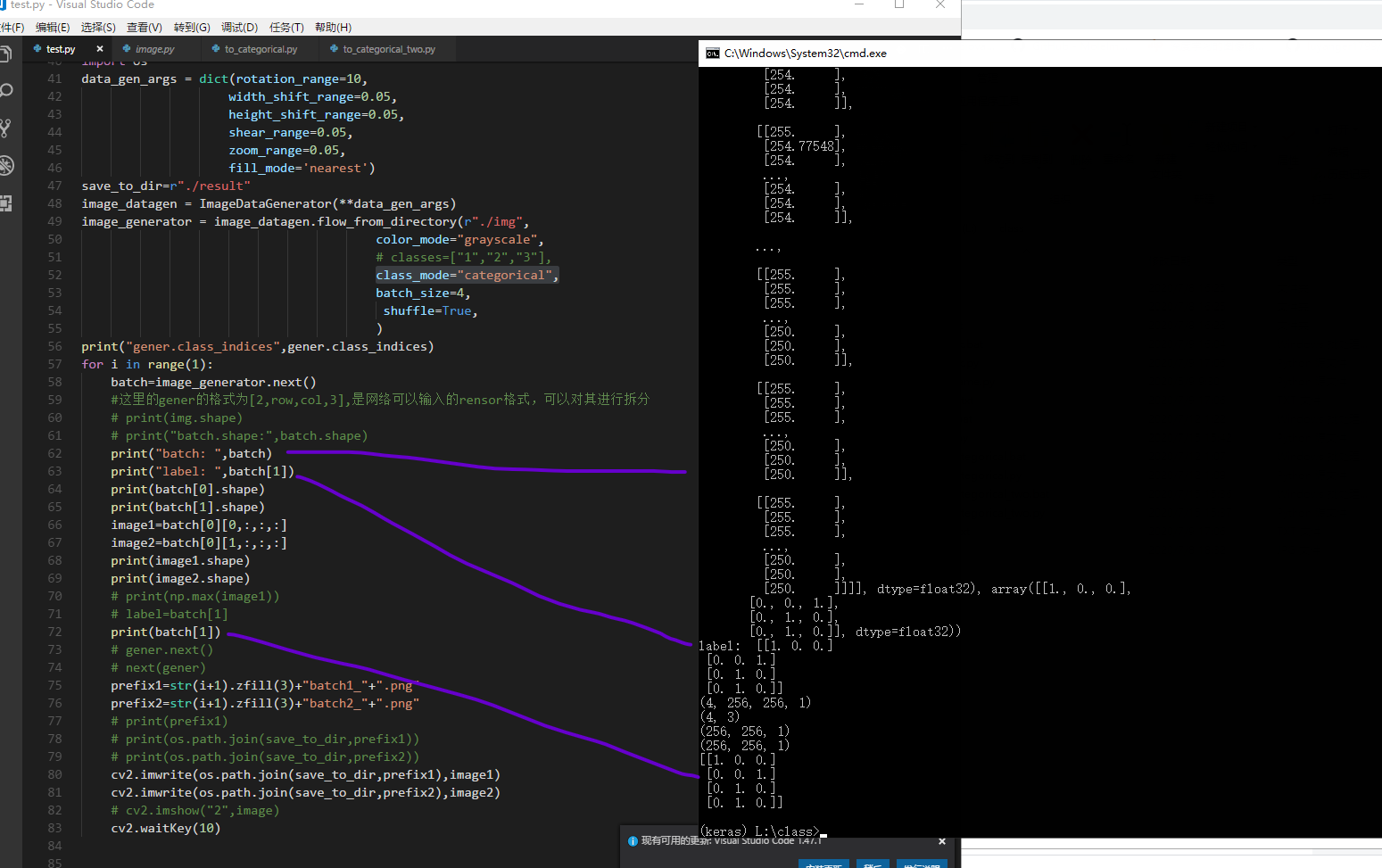
# import keras
# import numpy as np
# ohl=keras.utils.to_categorical([1,3])
# # ohl=keras.utils.to_categorical([[1],[3]])
# print(ohl)
# """
# [[0. 1. 0. 0.]
# [0. 0. 0. 1.]]
# """
# ohl=keras.utils.to_categorical([1,3],num_classes=5)
# print(ohl)
# """
# [[0. 1. 0. 0. 0.]
# [0. 0. 0. 1. 0.]]
# """
import numpy as np
def convert_to_one_hot(labels, num_classes):
#计算向量有多少行
num_labels = len(labels)
#生成值全为0的独热编码的矩阵
labels_one_hot = np.zeros((num_labels, num_classes))
#计算向量中每个类别值在最终生成的矩阵“压扁”后的向量里的位置
index_offset = np.arange(num_labels) * num_classes
#遍历矩阵,为每个类别的位置填充1
labels_one_hot.flat[index_offset + labels] = 1
return labels_one_hot
#进行测试
# b = [2, 4, 6, 8, 6, 2, 3, 7]
# print(convert_to_one_hot(b,9))
# import keras
label=[]
label.append(1)
label.append(2)
print(label)
labels=np.array(label)
print(labels)
# labels=keras.utils.to_categorical(labels,num_classes=3)
labels=convert_to_one_hot(labels,num_classes=3)
print(labels)
a=np.random.randint(0,2,(2,3))
print(a)
print(a.shape)
b=np.random.randint(0,2,(2,3))
# print(b)
a=np.expand_dims(a,axis=0)
a=np.expand_dims(a,axis=3)
b=np.expand_dims(b,axis=0)
b=np.expand_dims(b,axis=3)
print(a)
print(a.shape)
c=np.concatenate((a,b),axis=0)
print(c)
c=c.astype(np.float32)
print(c.shape)
print("*************label*************")
batch_tup=(c,labels)
print(batch_tup)
print("*************test*************")
d=[]
d.append(a)
d.append(b)
print(np.array(d).shape)
print("*************test*************")
import numpy as np
import cv2
import os
path = r'l:classimg'
img_list=[]
label_list=[]
batch_size=4
epochs=1
filelist = os.listdir(path)
# 三个if目的是为了找到矢状位的.lst文件路径
for name in filelist:
dirname=os.path.join(path,name) #F:zhangqmodeltestdata20180910 童艳玲 多肌 术前
for maindir, subdir, file_name_list in os.walk(dirname):
for f in file_name_list:
pathx=os.path.join(maindir,f)
path_tem=os.path.join(maindir,f)
#print(os.path.join(maindir,f))
try:
if pathx.find("jpg") != -1 or pathx.find("png")!=-1:
print(pathx)
img_list.append(pathx)
print((os.path.basename(pathx)).split("_")[0])
label=(os.path.basename(pathx)).split("_")[0]
label_list.append(int(label))
except:
continue
# 一次性把全部批次需要迭代的id放入列表中一批批yield
print(len(label_list))
print(len(img_list))
imgs_total=[]
masks_total=[]
# 每个epoch需要shuffle一次文件名列表
import random
reminder=len(img_list) % batch_size
for e in range(epochs):
# img_temp=os.listdir(os.path.join(train_path,image_folder))
# mask_temp=os.listdir(os.path.join(train_path,mask_folder))
# img_temp=sorted(img_temp,key=lambda i:int(os.path.basename(i).split(".")[0]))
# mask_temp=sorted(mask_temp,key=lambda i:int(os.path.basename(i).split(".")[0]))
img_list1=[]
label_list1=[]
label_list1.extend(label_list)
img_list1.extend(img_list)
for re in range(batch_size-reminder):
img_list1.append(img_list[re])
label_list1.append(label_list[re])
# # print("epoch: ",len(img_temp))
c=list(zip(img_list1,label_list1))
random.shuffle(c)
imgs,masks=zip(*c)
imgs_total.extend(imgs)
masks_total.extend(masks)
# # imgs=img_temp
# # masks=mask_temp
# imgs_total.extend(img_list1)
# masks_total.extend(label_list1)
print(imgs_total)
print(masks_total)
print("reminder:",reminder)
print("len:",len(imgs_total))
print("len:",len(masks_total))
for i in range(0,len(imgs_total),batch_size):
temp_img=imgs_total[i:i+batch_size]
temp_mask=masks_total[i:i+batch_size]
# print("i+batch_size: ",i+batch_size)
data_img=np.zeros((batch_size,320,320,1),dtype=np.uint8)
# data_mask=np.zeros((len(temp_mask)),dtype=np.uint8)
data_mask=[]
for j in range(batch_size):
# print(os.path.join(os.path.join(train_path,image_folder),temp_img[j]))
img=cv2.imread(temp_img[j],0)
# print("path:",temp_img[j])
if img is None:
print("no pic")
# print(img.dtype)
img=cv2.resize(img,(320,320),1)
# img=img.astype(np.float32)
# img=norm_img(img)
data_img[j,...,0]=img
data_mask.append(temp_mask[j])
# print(data_mask[j])
print(data_mask)
labels=np.array(data_mask)
print("labels:",labels)
labels=convert_to_one_hot(labels,num_classes=3)
# print(labels)
batch_tup=(data_img,labels)
print(batch_tup)
# img_onehot,mask_onehot = adjustData(data_img,data_mask,flag_multi_class,num_class)
# yield img_onehot,mask_onehot输出对比batch_tensor结构是一致的,注意上述标签我是根据图像id中提取出来的。
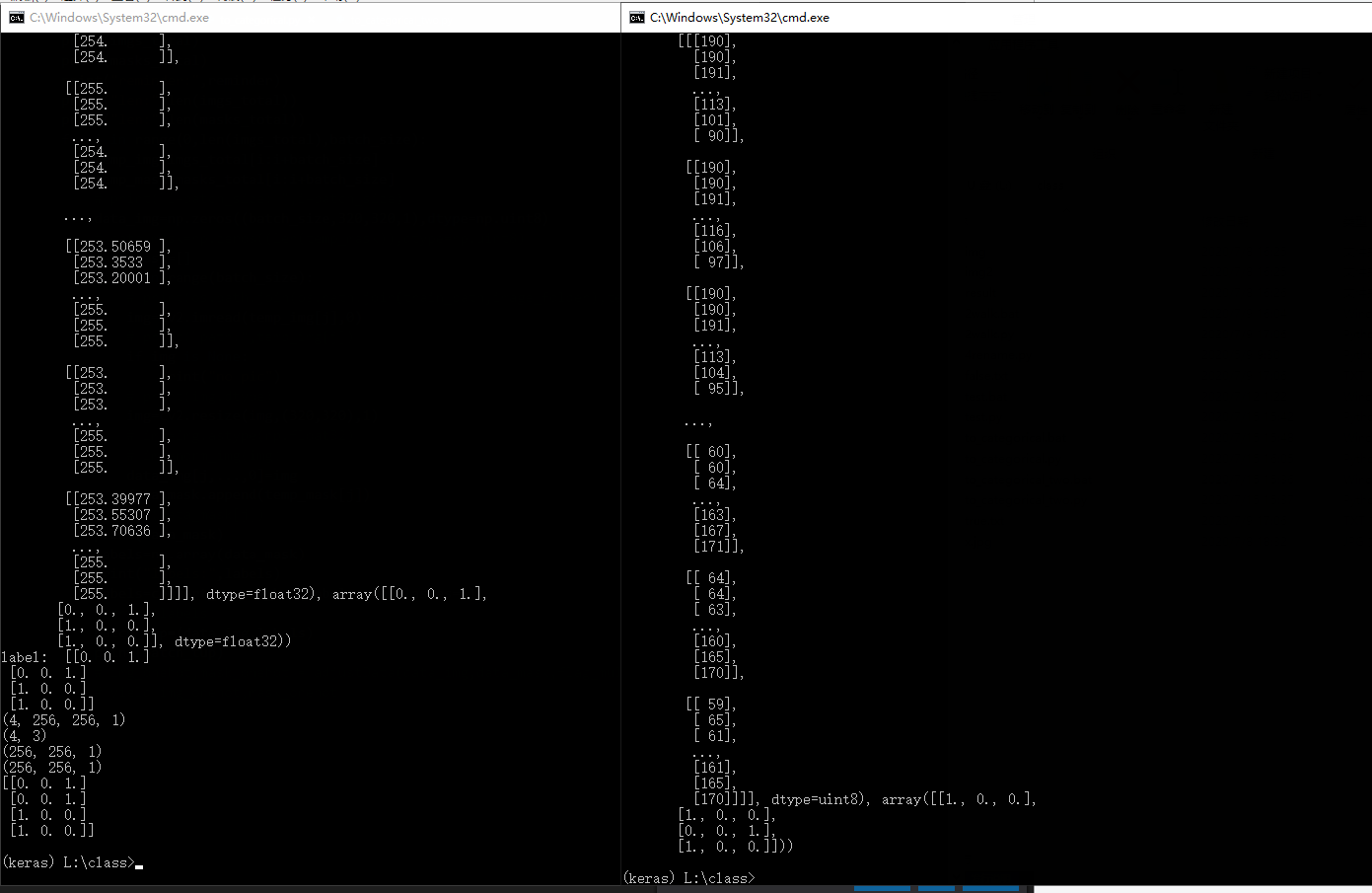
相关链接:https://blog.csdn.net/weixin_37737254/article/details/103884255
https://cloud.tencent.com/developer/article/1471282
other:
其他相关dataloader写法:
范例一:
class NoisyImageGenerator(Sequence):
def __init__(self, image_dir, source_noise_model, target_noise_model, batch_size=32, image_size=64):
image_suffixes = (".jpeg", ".jpg", ".png", ".bmp")
self.image_paths = [p for p in Path(image_dir).glob("**/*") if p.suffix.lower() in image_suffixes]
self.source_noise_model = source_noise_model
self.target_noise_model = target_noise_model
self.image_num = len(self.image_paths)
self.batch_size = batch_size
self.image_size = image_size
if self.image_num == 0:
raise ValueError("image dir '{}' does not include any image".format(image_dir))
def __len__(self):
return self.image_num // self.batch_size
def __getitem__(self, idx):
batch_size = self.batch_size
image_size = self.image_size
x = np.zeros((batch_size, image_size, image_size, 3), dtype=np.uint8)
y = np.zeros((batch_size, image_size, image_size, 3), dtype=np.uint8)
sample_id = 0
while True:
image_path = random.choice(self.image_paths)
image = cv2.imread(str(image_path))
h, w, _ = image.shape
if h >= image_size and w >= image_size:
h, w, _ = image.shape
i = np.random.randint(h - image_size + 1)
j = np.random.randint(w - image_size + 1)
clean_patch = image[i:i + image_size, j:j + image_size]
x[sample_id] = self.source_noise_model(clean_patch)
y[sample_id] = self.target_noise_model(clean_patch)
sample_id += 1
if sample_id == batch_size:
return x, y
***********************************************************************
generator = NoisyImageGenerator(image_dir, source_noise_model, target_noise_model, batch_size=batch_size,
image_size=image_size)
val_generator = ValGenerator(test_dir, val_noise_model)
output_path.mkdir(parents=True, exist_ok=True)
callbacks.append(LearningRateScheduler(schedule=Schedule(nb_epochs, lr)))
callbacks.append(ModelCheckpoint(str(output_path) + "/weights.{epoch:03d}-{loss:.3f}-{PSNR:.5f}.hdf5",
monitor="PSNR",
verbose=1,
mode="max",
save_best_only=True))
# model_checkpoint = ModelCheckpoint('unet.hdf5',monitor='loss',verbose=1,save_best_only=True)
hist = model.fit_generator(generator=generator,
steps_per_epoch=steps,
epochs=nb_epochs,
callbacks=callbacks
)范例二:https://github.com/ykamikawa/tf-keras-PSPNet/blob/master/generator.py
import os
import cv2
import numpy as np
from keras.preprocessing.image import img_to_array
def category_label(labels, dims, n_labels):
x = np.zeros([dims[0], dims[1], n_labels])
for i in range(dims[0]):
for j in range(dims[1]):
x[i, j, labels[i][j]] = 1
x = x.reshape(dims[0] * dims[1], n_labels)
return x
# generator that we will use to read the data from the directory
def data_gen_small(img_dir, mask_dir, lists, batch_size, dims, n_labels):
while True:
ix = np.random.choice(np.arange(len(lists)), batch_size)
imgs = []
labels = []
for i in ix:
# images
img_path = os.path.join(img_dir, lists.iloc[i, 0], ".jpg")
original_img = cv2.imread(img_path)[:, :, ::-1]
resized_img = cv2.resize(original_img, (dims[0], dims[1]))
array_img = img_to_array(resized_img) / 255
imgs.append(array_img)
# masks
mask_path = os.path.join(img_dir, lists.iloc[i, 0], ".png")
original_mask = cv2.imread(mask_path)
resized_mask = cv2.resize(original_mask, (dims[0], dims[1]))
array_mask = category_label(resized_mask[:, :, 0], dims, n_labels)
labels.append(array_mask)
imgs = np.array(imgs)
labels = np.array(labels)
yield imgs, labels
最后
以上就是无心饼干最近收集整理的关于keras框架里重写DataGenerator批数据生成器fit_generator 训练逻辑过程 (极重要!)fit_generator API与示例1.二分类问题二,多分类问题 的全部内容,更多相关keras框架里重写DataGenerator批数据生成器fit_generator内容请搜索靠谱客的其他文章。








发表评论 取消回复