收集更多数据并不一定会带来更好的分析和洞察力。Gartner 预测,只有 20% 的数据和分析会产生真正的业务成果。如果企业希望在数据和分析计划方面取得更大成功,他们需要解决根深蒂固的数据问题,例如数据孤岛、无法访问的数据/分析以及过度依赖人工干预。
为了实现成功的数字化转型,数据团队需要超越清理不完整和重复的数据记录。像HongKe这样的多维数据可观察性解决方案可以帮助数据团队避免数据孤岛,使数据分析在整个组织中可访问,并实现更好的业务成果。数据团队还可以使用 HongKe 来利用 AI 进行高级数据清理和自动检测异常。
数据工程团队可以使用多维数据可观察性方法解决这三个重要的数据问题,我们将在下面概述:
1. 企业内的数据孤岛
如今,企业被数据淹没。Acceldata首席执行官 Rohit Choudhary在接受 Datatechvibe 采访时表示:“一些组织在一周内收集的数据比他们过去一年收集的数据还要多。 ” 因此,团队越来越多地使用更多的数据工具和技术来满足其组织的数据需求。
因此,数据孤岛已成为常态。这些孤立的数据孤岛会产生数据完整性问题,并增加分析成本和对数据的不信任。数据孤岛还为数据团队创造了更多工作,迫使他们将跨不同数据平台和技术的脆弱数据管道联合在一起。
使用HK-Torch获得数据和数据生命周期的单一、统一视图
数据可观察性可以通过提供整个数据管道的集中视图来帮助您避免数据孤岛。这样的视图显示了您的数据如何在整个数据生命周期中进行转换。更具体地说,HK-Torch提供数据管道和数据相关操作的统一视图,以帮助您避免孤岛。
这是 Airflow 中的典型数据管道。它显示了在 JOIN 操作之后如何创建数据集并将其写入RDS 位置(远程数据库)。之后,使用 Databricks 作业对数据进行转换,最后,将数据移动到 Snowflake 存储库中以供使用。
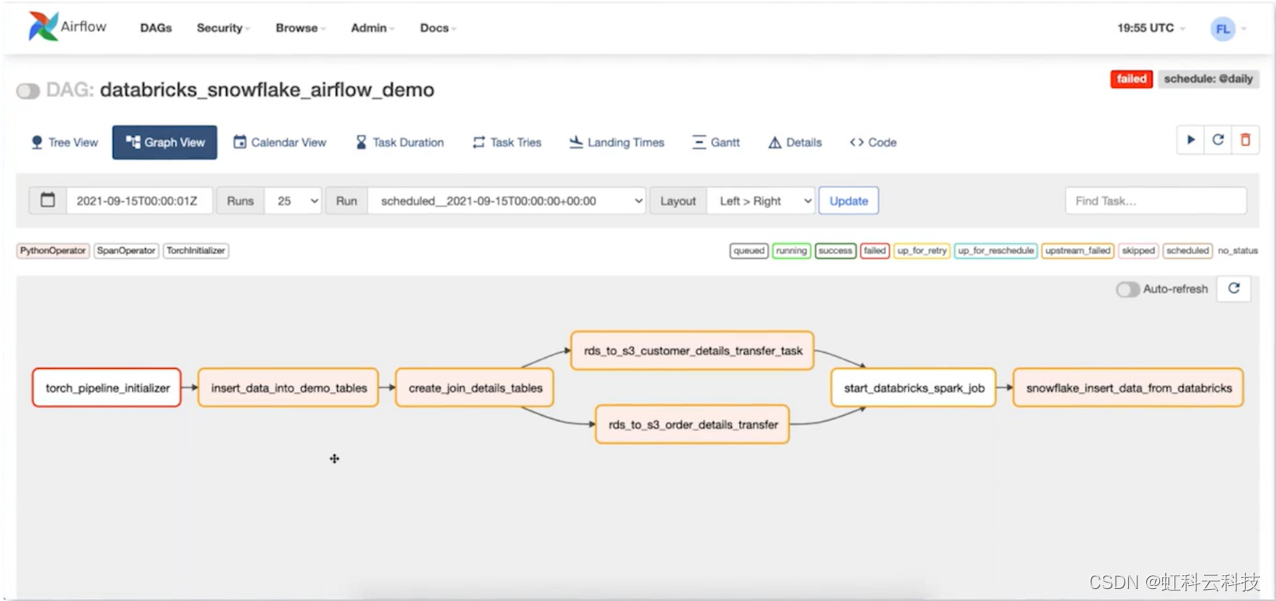
这是HK-Torch中的相同管道。红色框代表各种计算作业,而绿色框代表与计算作业交互的各种数据元素、位置和表。
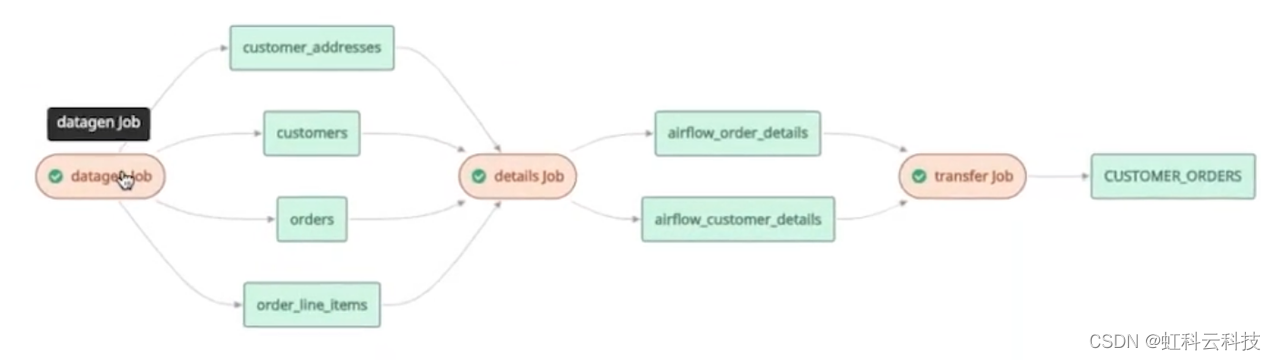
这种统一的视图可以帮助数据团队回退,了解数据如何在整个数据生命周期中进行转换,而与使用的平台无关。它还可以帮助他们发现潜在的管道问题并调试任何数据转换不匹配/问题。
2. 质量差加上无法访问的数据和分析
哈佛商业评论的一项调查表明,数据质量差 (42%)、缺乏有效的分析流程 (40%) 和无法访问的数据 (37%) 是产生可操作见解的最大障碍。
在这篇Venture Beat 文章中,IBM 数据科学和 AI 首席技术官 Deborah Leff 说:“我让数据科学家(和团队)看着我,说我们可以做那个项目,但我们做不到访问数据。” 换句话说,除非组织内所有级别的数据和分析都可以访问,否则企业无法获得可操作的见解。
没有对整个数据生命周期的统一视图可能会导致影响数据质量的不一致。此外,还有一个悖论,企业继续收集、存储和分析比以往更多的数据。但与此同时,处理和分析数据的成本也越来越高,技术也越来越密集。
因此,数据和分析功能不容易在组织内的所有级别上使用和分析。相反,只有少数具有必要技能和访问权限的人能够使用少量数据。这意味着企业没有意识到其数据的全部潜力和价值。
使用 HK-Pulse 降低数据处理成本并实现实时分析
对于大多数企业而言,高昂的数据处理成本和过时的流程使他们无法在组织内的各个级别访问数据和分析。他们可以使用HK-Pulse来:
- 通过创建警报来监控基础设施组件的关键模块,例如 CPU、内存、数据库运行状况和 HDFS,使数据和基础设施层更易于观察。
- 通过帮助数据团队识别瓶颈、额外开销和优化查询来加速数据消耗。它还可以帮助数据团队提高数据管道的可靠性、优化 HDFS 性能、整合 Kafka 集群并降低总体数据成本。
- 在组织内的各个级别实现实时决策。
3. 仅依靠手动数据干预
如今,数据团队依靠人工干预来调试问题、检测异常并编写查询/脚本来为下游消费/分析准备原始数据。但这种方法不可扩展,也不能帮助您的数据团队处理不断增加的数据量。因此,数据团队需要利用人工智能和自动化。
但实施基于人工智能的自动化是一个复杂的问题。“这是世界历史上的一个新时期。我们在 AI 中构建模型和机器,其复杂程度超出我们的理解范围。” Uber AI Labs 和 ML Collective 的联合创始人Jason Yosinski说。
因此,三分之二的公司每年在大数据和人工智能方面的投资超过 5000 万美元,但只有 14.6% 的公司已将人工智能能力部署到生产中。
更糟糕的是,企业的数据团队因重复性的手动任务而超负荷,例如清理数据集、调试错误和修复数据中断。这使他们无法利用人工智能和自动化。
利用 AI 自动清理数据、检测异常并防止中断
使用 HK-Pulse 等数据可观察性解决方案利用 AI 功能:
- 实时自动清理和验证传入的数据流,因此数据团队不再需要编写耗时的手动脚本,而可以专注于优化基础架构和确保可靠性。
- 自动检测异常并自动进行预防性维护。它还可以加速根本原因分析,并根据历史比较、环境健康和资源争用关联事件。
- 通过以下方式自动分析意外行为变化的根本原因:
- 以可按严重性或服务搜索的时间直方图形式获取所有应用程序日志的概览
- 比较不同的查询及其运行时/配置参数
- 更好地了解不同查询的队列利用率
- 获取自动建议以纠正慢查询、预测资源可用性和适当调整容器大小
数据可观察性正在平衡竞争环境
顶级科技公司有能力聘请大量有才华的数据主管和工程师,从他们的数据和分析计划中获取业务成果。但财富 2000 强集团中的大多数公司不能遵循同样的模板。但是,他们仍然可以从数据和分析中获得更好的业务成果。
HongKe 的数据可观察性解决方案套件甚至可以帮助小型数据团队超越他们的体重。它可以帮助他们自动执行重复的手动任务,例如清理数据和检测异常。它可以帮助数据团队使数据和基础设施层更易于观察。它扩展了他们的分析能力。
“更多的公司需要在他们的数据计划上取得成功——而不仅仅是少数以互联网为重点的大型公司。我们正试图通过数据可观察性来平衡竞争环境,”Choudhary 说。
最后
以上就是俊秀纸鹤最近收集整理的关于数据可观察性可以解决的三个数据问题的全部内容,更多相关数据可观察性可以解决内容请搜索靠谱客的其他文章。








发表评论 取消回复