一、关于爬虫与反爬虫对抗过程以及策略
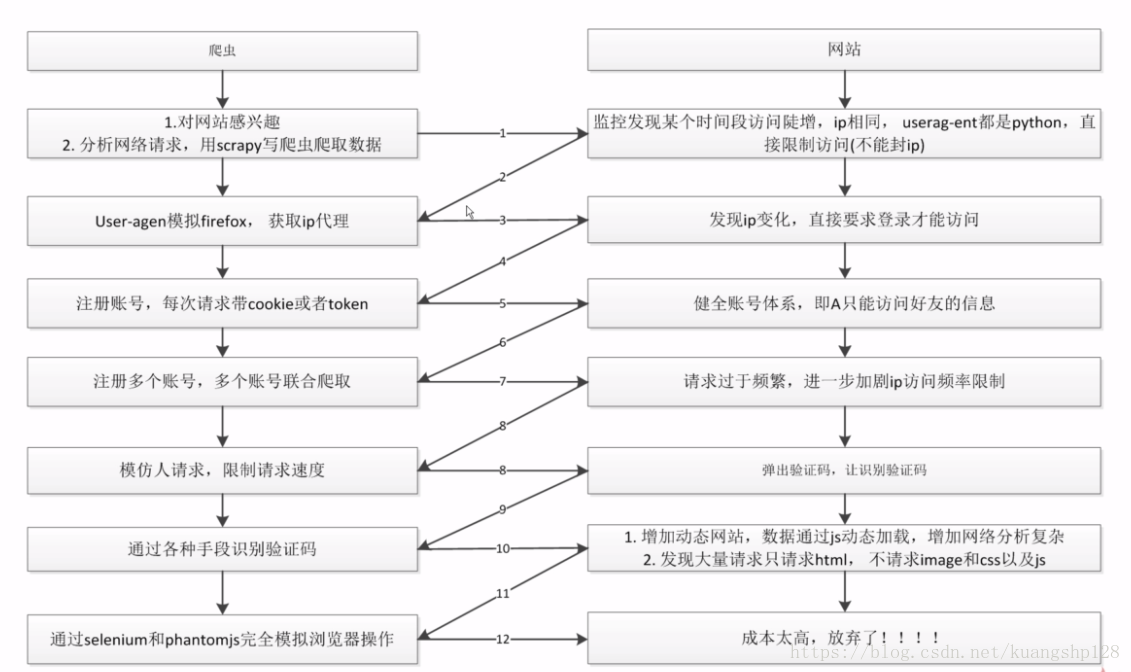
二、爬虫突破反爬虫的常见方法
- 1、随机的修改请求头(
User-Agent)模拟浏览器请求 - 2、随机更改请求
ip地址 - 3、设置请求时间(不要请求过频繁)
- 4、云打码识别图片验证码
- 5、模拟人工操作对滑动解锁
三、自己在settings.py中定义一个请求头列表来模拟浏览器请求
1、在配置文件中定义一个列表
user_agent_list = [ 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel …) Gecko/20100101 Firefox/59.0' ]2、在
middlewares.py中书写中间件import random # 定义一个随机切换头部的中间件 class RandomUserAgentMiddleware(object): def __init__(self, crawler): super(RandomUserAgentMiddleware, self).__init__() # 获取到配置文件中user_agent_list的列表 self.user_agent_list = crawler.settings.get('user_agent_list', []) @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): request.headers.setdefault('User-Agent', self.user_agent_list[random.randint(0, (len(self.user_agent_list)))])3、在
settings.py中配置DOWNLOADER_MIDDLEWARES = { # 自己写的 'job.middlewares.RandomUserAgentMiddleware': 543, # 把默认的设置为None 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, }
四、使用第三方插件来模拟浏览器请求
- 1、
github上搜索fake-useragent传送门 - 2、安装插件
3、使用插件
from fake_useragent import UserAgent # 定义一个随机切换头部的中间件 class RandomUserAgentMiddleware(object): def __init__(self): super(RandomUserAgentMiddleware, self).__init__() self.ua = UserAgent() def process_request(self, request, spider): print('请求头===', self.ua.random) request.headers.setdefault('User-Agent', self.ua.random)- 4、同样在
settings.py中配置
五、使用代理IP来访问
1、把西刺上的
IP地址存入到数据库中import requests from scrapy.selector import Selector import pymysql conn = pymysql.connect(host='127.0.0.1', user='root', passwd='***', db='nodejs', port=3306, charset='utf8') cursor = conn.cursor() def crawl_ips(): """ 创建一个抓取西刺代理网上高密的ip存到到本地数据中 """ headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"} # 遍历全部的页面 for i in range(2, 2890): response = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers) # 获取的页面内容 selector = Selector(text=response.text) all_trs = selector.css('#ip_list tr') ip_list = [] for tr in all_trs[1: ]: speed_str = tr.css(".bar::attr(title)").extract()[0] if speed_str: speed = float(speed_str.split("秒")[0]) all_texts = tr.css("td::text").extract() ip = all_texts[0] port = all_texts[1] proxy_type = all_texts[5] ip_list.append((ip, port, speed, proxy_type,)) try: print(ip_list) sql = 'insert into proxy_ip (ip, port, speed, proxy_type) values (%s, %s, %s, %s)' for ip_info in ip_list: if ip_info[0] and ip_info[1] and ip_info[2] and ip_info[3]: cursor.execute(sql, (ip_info[0], ip_info[1], ip_info[2], ip_info[3])) print('入库成功~~~') conn.commit() else: continue except pymysql.Error as e: print(e) conn.rollback() finally: if conn: conn.close()2、定义一个随机获取
IP的类class GetIP(object): """ 定义一个获取ip的类 """ def delete_ip(self, ip): # 把没用的ip从数据库中删除 delete_sql = """ delete from proxy_ip where ip='{0}' """.format(ip) cursor.execute(delete_sql) conn.commit() return True def judge_ip(self, proxy_type, ip, port): # 判断一个ip是否有用 http_url = "http://www.baidu.com" proxy_url = "{0}://{1}:{2}".format(proxy_type, ip, port) try: proxy_dict = { proxy_type: proxy_url, } response = requests.get(http_url, proxies=proxy_dict) except Exception as e: print("invalid ip and port") self.delete_ip(ip) return False else: code = response.status_code if code >= 200 and code < 300: print("有效的ip", proxy_url) return True else: print("无用的ip", proxy_url) self.delete_ip(ip) return False def get_random_ip(self): # 随机获取一个ip random_sql = """ SELECT ip, port, proxy_type FROM proxy_ip ORDER BY RAND() LIMIT 1 """ result = cursor.execute(random_sql) for ip_info in cursor.fetchall(): ip = ip_info[0] port = ip_info[1] proxy_type = ip_info[2] # 判断当前的ip是否有效 judge_re = self.judge_ip(proxy_type, ip, port) if judge_re: return "{0}://{1}:{2}".format(proxy_type, ip, port) else: return self.get_random_ip()3、定义中间件
from tools.crawl_xici_ip import GetIP class RandomProxyMiddleware(object): #动态设置ip代理 def process_request(self, request, spider): get_ip = GetIP() request.meta["proxy"] = get_ip.get_random_ip()- 4、在
setting.py中配置
最后
以上就是甜甜饼干最近收集整理的关于关于爬虫与反爬虫对抗过程以及策略的全部内容,更多相关关于爬虫与反爬虫对抗过程以及策略内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复