一个项目的完成一般需要经过三个步骤:初始化、开发和部署。在前端开发过程中,我们经常需要依靠一些自动化构建工具来优化前端工作流程,来帮助我们完成一系列繁琐的工作,例如浏览器热更新、ES6编译、代码压缩、添加样式前缀、图片压缩等。
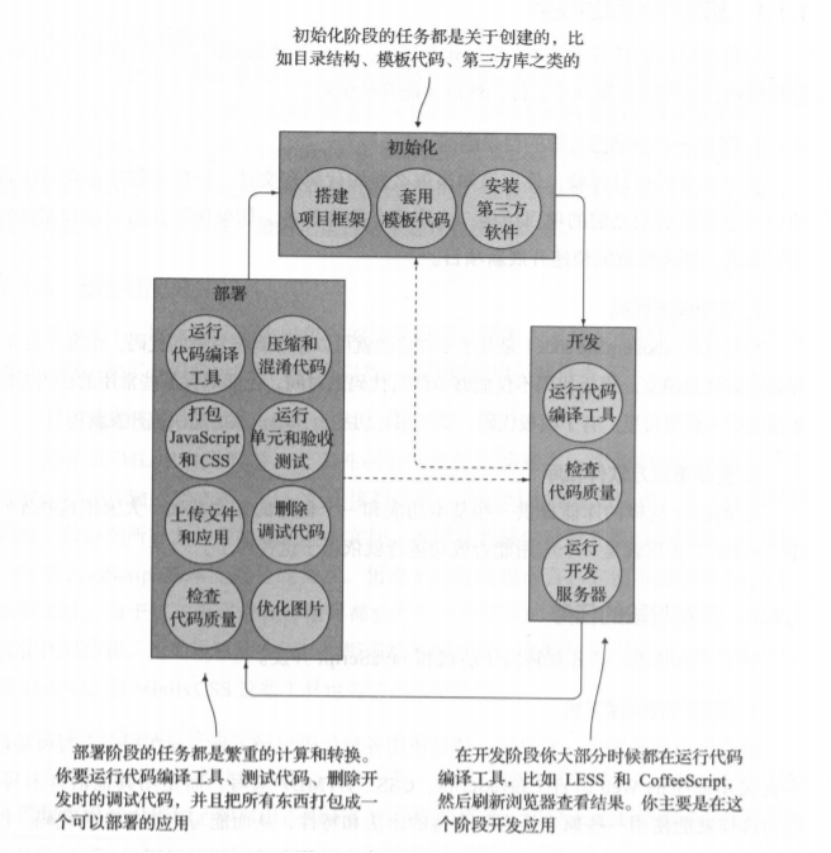
在这些自动化构建工具中,比较有名的就是Grunt和Gulp。相比Grunt,Gulp的人气更高。作为一个独特的构建工具,Gulp的构建方法和Grunt完全不同。Gulp有以下特点:①它的底层计算完全是在内存中运行的,而且读取数据非常快。②它可以并行执行任务。③gulpfile是纯Node.js代码,开发者可以在Gulp的任务中执行任何兼容Node的JavaScript代码。④Gulp可以创建出非常高级的构建管道,甚至超越其它一流的工具。
虽然现如今Gulp的市场份额也渐渐被模块打包工具Webpack吞并了,但还是有不少公司依旧在使用Gulp维护项目。对于初学者来说,通过学习Gulp了解如何去使用自动化构建工具进行项目构建其实是个不错的选择。
注意:Gulp和Webpack不是同一类东西,虽然它们的功能有交集,但Gulp是一款任务执行器,用来自动化处理常见的开发任务,例如项目的检查、构建、测试,以解放我们重复机械工作的双手,节省我们的开发时间。而Webpack是一款文件模块打包工具,主要用于模块化识别和编译模块化代码,把项目的各种JavaScript文件、CSS文件等打包合并成一个或多个文件。相对于打包工具,任务执行器聚焦在偏上层的问题,而打包部分的问题则留给打包工具。和Webpack类似的有Browserify,这两者是预编译模块化方案。而像AMD规范下的RequireJs和CMD规范下的SeaJs则是另一种在线编译模块化方案,让浏览器能够识别define、exports、module这些标识符。打包工具帮助我们取得准备用于部署的JavaScript和样式表,将它们转换为适合浏览器的可用格式。例如,JavaScript可以压缩、拆分模块和懒加载,以提高性能。在以前JavaScript这门语言还不支持模块化的时候,一般我们经常将Gulp和Webpack结合起来使用,进行项目自动化构建和模块化编译。Webpack后来通过引入插件的形式,不断扩充自己的功能,也可以像Gulp一样进行代码压缩、Babel编译等,功能越来越强大,于是人们就开始使用Webpack进行项目构建了。关于前端模块化路程,最近看到一篇比较详细的文章,有兴趣的朋友可以阅读了解一下:前端模块化的历史沿革 。
言归正传,今天这篇文章主要教大家如何使用Gulp进行前端项目的构建,通过这篇文章,你完全可以自己手动尝试搭建一个完整的前端开发环境进行代码压缩、文件合并、模块化编译、资源映射等一系列自动化构建过程,同时你也会了解到Gulp中的流(Vinyl 虚拟文件对象流)和普通的Node.js流有什么区别。Gulp的版本现在已经发展到4.0.2了,因此今天这篇文章就直接基于Gulp4,一步步带领大家构建一个较为完整的前端开发环境。在看这篇文章之前,我希望你已经先阅读过Gulp的官方文档,因为有些基本开发环境配置,在这里我不会花特别多的文字去赘述。关于开发环境的配置,请查看 Gulp官方文档-快速入门篇。
Gulp的使用需要依赖各种各样的包,npm是node的一个包管理工具,我们可以通过npm指令去下载各自项目中需要使用到的依赖包。不过,为了提高安装速度,这里推荐使用淘宝镜像cnpm代替npm进行安装,我们用npm安装的包都是从国外的服务器安装过来的,速度比较慢,而淘宝团队把国外的包每隔十分钟同步更新到国内的服务器,通过cnpm指令即可从国内服务器进行依赖包的获取。通过运行npm install cnpm -g 下载cnpm依赖 ( -g 表示全局安装 ),接下来便可通过cnpm指令进行其它依赖包的下载。
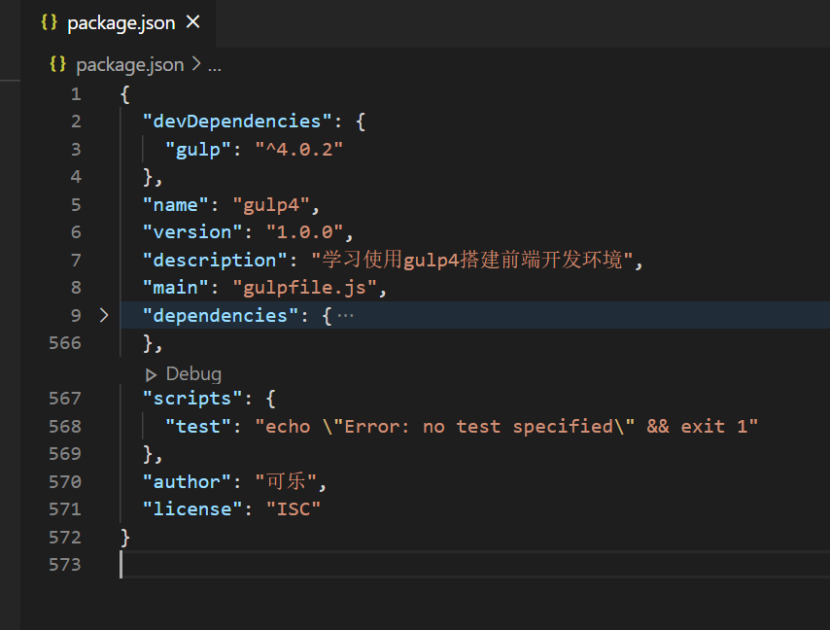
我们所有的包都保存在node_modules文件夹下,而如果你的安装指令后面添加了--save/ -S 或者 --save-dev / -D (后面的大写指令是前面的小写指令的简写方式),所安装的包及其对应版本就会被记录到 package.json 文件里(--save 表示记录为生产依赖, --save-dev 表示记录为开发依赖)。

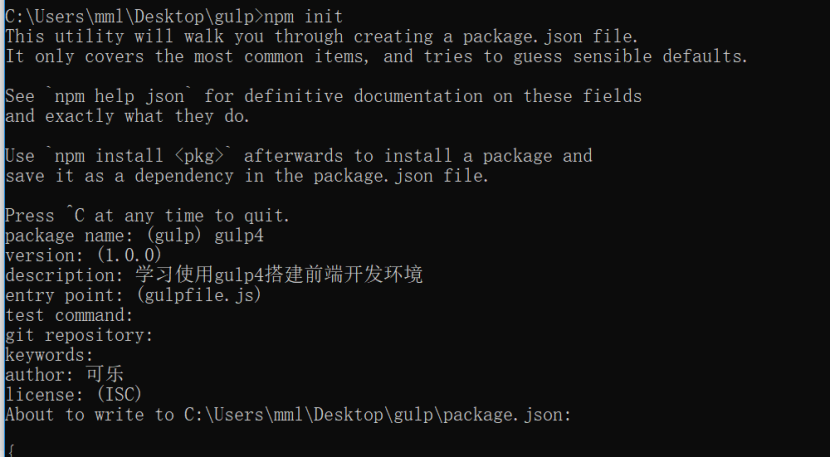
执行npm init指令后可以填写一些项目描述信息,这里也可以一路直接回车,最后package.json文件会显示我们配置的或者默认的描述信息:
接着我们通过执行命令 npx -p touch nodetouch gulpfile.js,或者手动创建一个空的 gulpfile.js 文件。接下来我们所有的自动化流程,就都是基于该文件进行配置的。

在进行配置之前,我们先确定好自己的目录结构,我暂时将目录结构按如下规范创建:
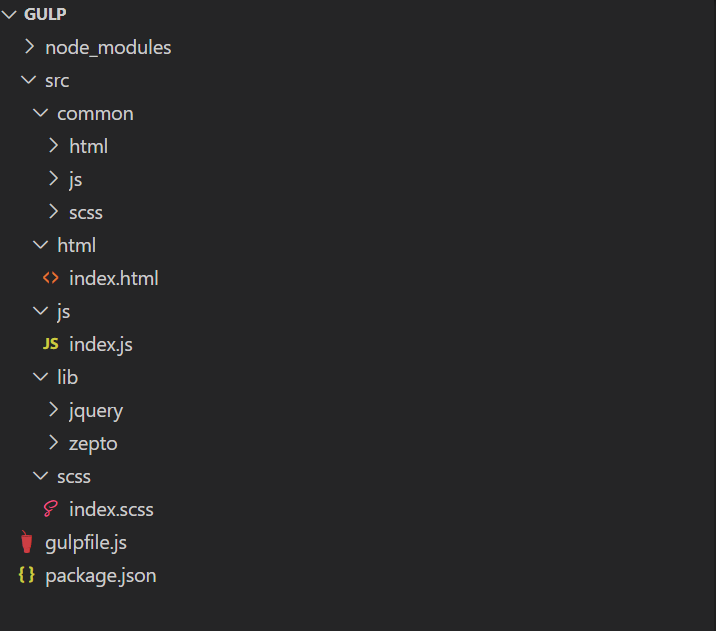
创建一个src目录,我们所有的前端代码接下来就写在这里面。common目录作为公共目录存放公共html片段、css样式和javascript文件。lib目录则存放我们所以依赖的第三方工具代码,比如jQuery。其它目录则分别用来编写独立的html、js和css文件。这里的scss文件初学者可能不太懂,Scss是一款css预处理器,可以让我们很方便的进行css开发。它的写法后面会演示,不知道的也可以先行百度。
接下来我们就开始详细讲解如何编写gulpfile.js文件。Gulp 的主要目标是定义一个处理文件的管道,让源文件通过一个个的处理步骤。每个步骤都会修改文件内容,然后把结果传递给下一个步骤,这就是为什么Gulp 自称是流式构建系统的原因。Gulp遵循 CommonJs 的模块化规范,即用 require 引入模块,使用 module.exports 或 exports 导出模块。
一开始我们先在 gulpfile.js 头部引入四个Gulp的基本方法,分别是 src、dest、series、和parallel,我们直接用ES6的对象解构赋值写法引入。相信看过文档的你一定知道这四个方法是干嘛用的,这里就不再解释了。
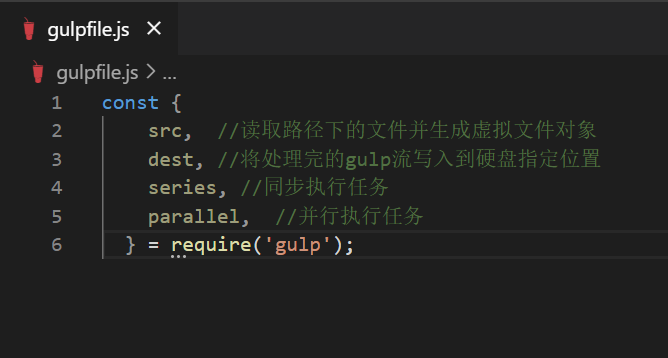
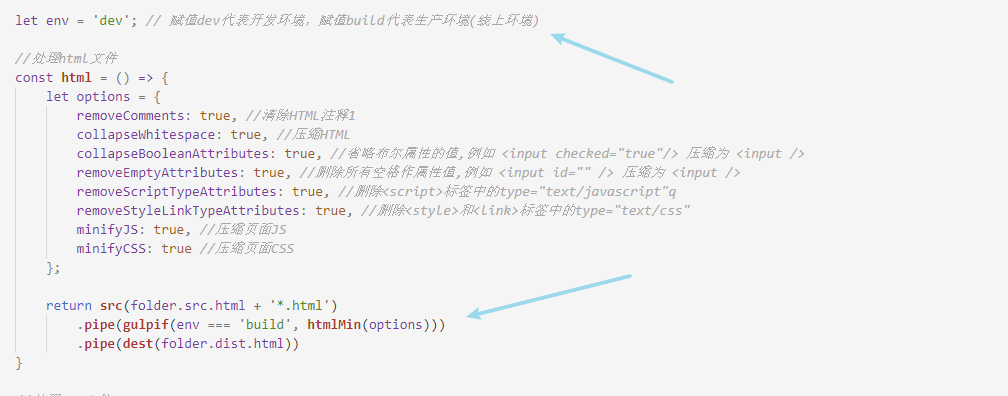
处理HTML文件:
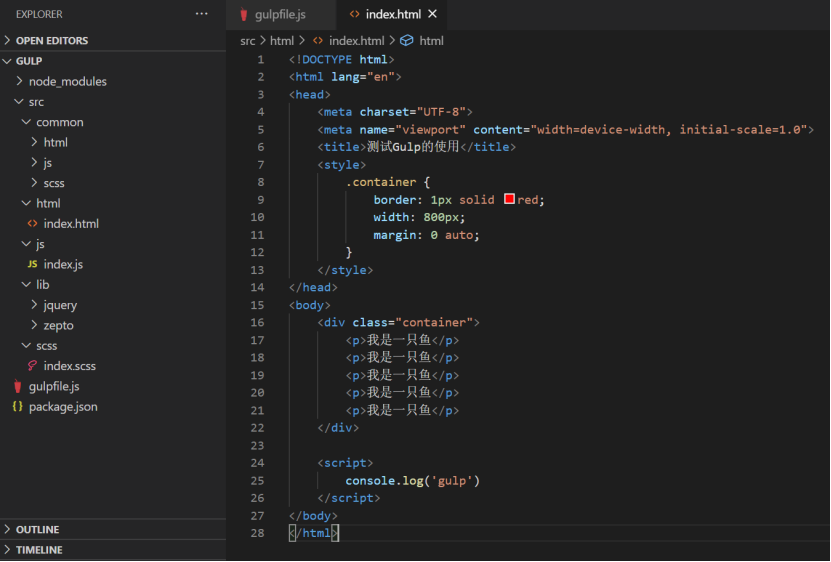
首先我们先对html文件进行处理。对html文件的处理,一般就只是需要压缩文件和引入公共头部和尾部。我们先在src目录下的html文件写一些内容:
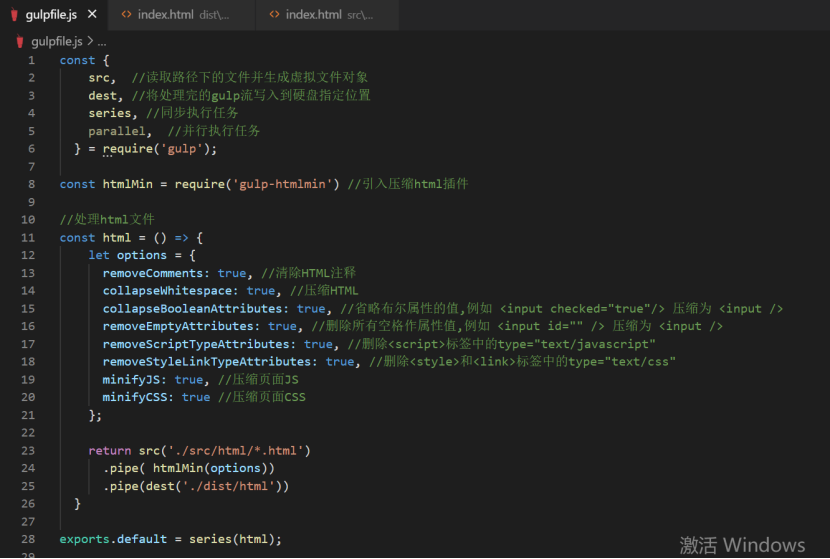
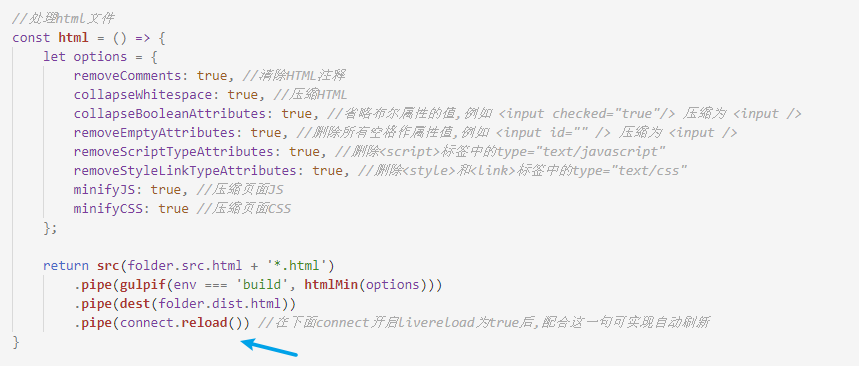
压缩 html 需要用到 gulp-htmlmin 插件,这个插件并不是gulp自带的,所以我们需要自己去下载,我们在gulp文件的命令行处执行 cnpm install --save-dev gulp-htmlmin。安装完后在 gulpfile.js 文件顶部引入,然后就可以在管道中使用了。这个插件需要配置一些参数,配置方式和使用如图所示:
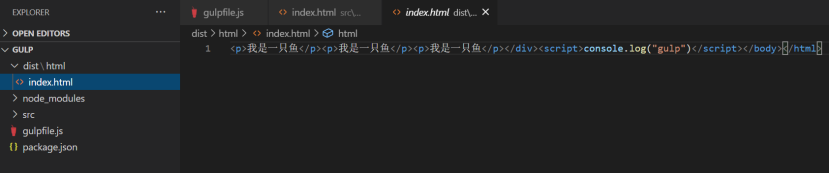
一般打包输入的代码都保存在dist目录下。现在我们在命令行中运行 gulp,如果后面不指定其它参数,则默认执行 gulpfile.js文件中导出的 default 方法。
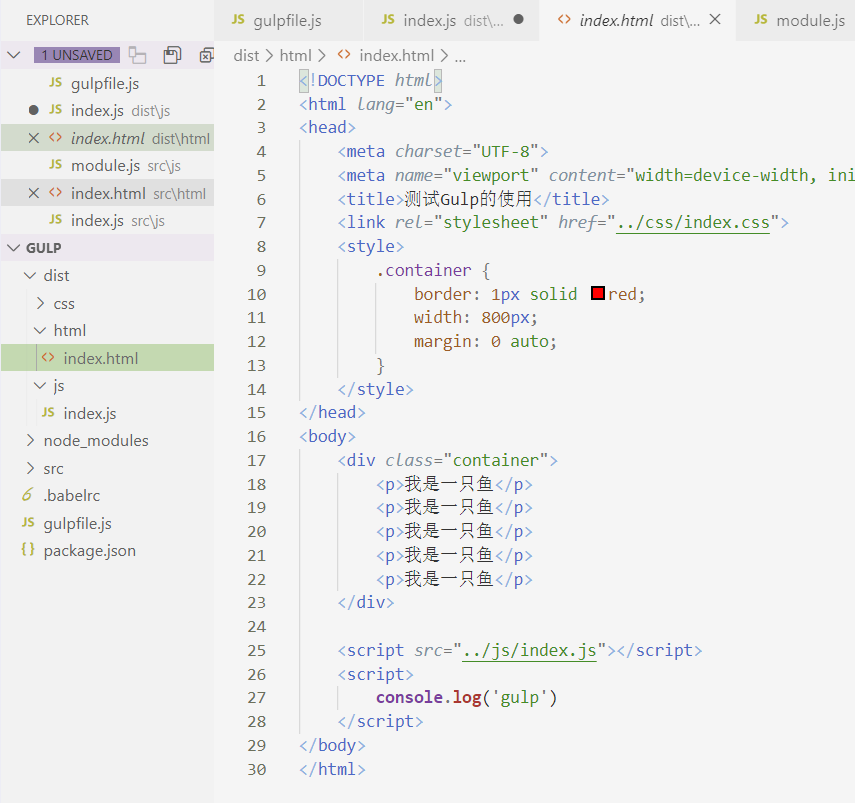
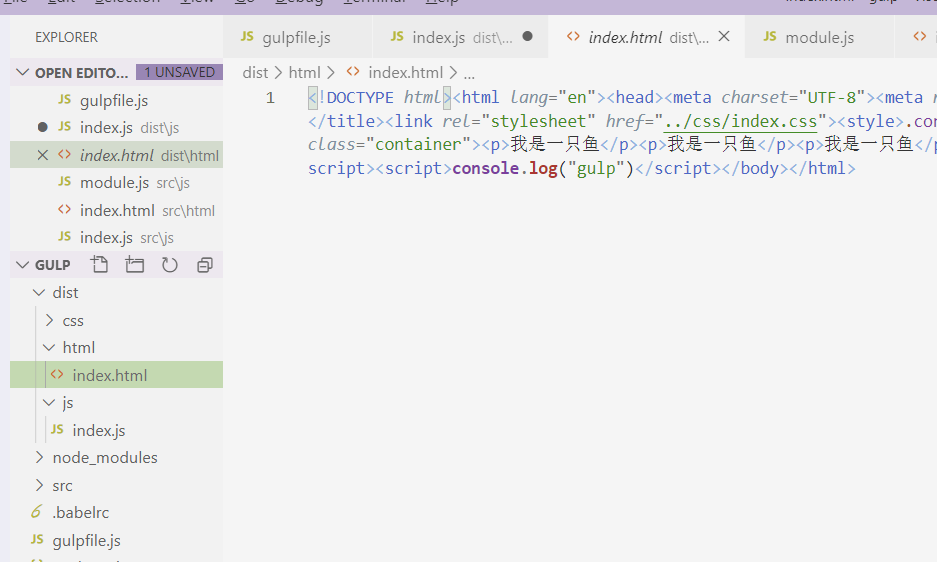
执行完后,我们看到了文件夹中多了一个dist文件,下面就是我们压缩完的html文件。
引用公共头部和尾部的方法暂时留到后面再说。
处理SCSS文件
接下来就是处理scss了,那就先来介绍什么是Scss。Scss跟Less之类的一样,都是为了提高css开发效率而诞生的css预处理器,我们可以用很灵活便捷的方式,去快速编辑css。当然,浏览器目前还不能直接识别scss的语法,所以我们编辑的scss文件,最后必须编译成浏览器可以直接识别的css文件。
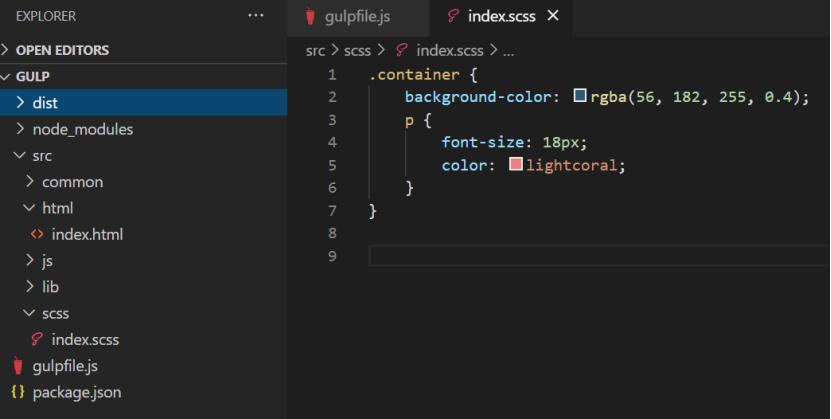
对于scss文件的处理,一般有进行scss编译、补充css样式前缀、压缩css代码。需要引入的插件如图所示:

运行安装插件命令( i 是install的简写形式 ):
![]()
在gulpfile.js中对编写对scss文件进行处理的函数:
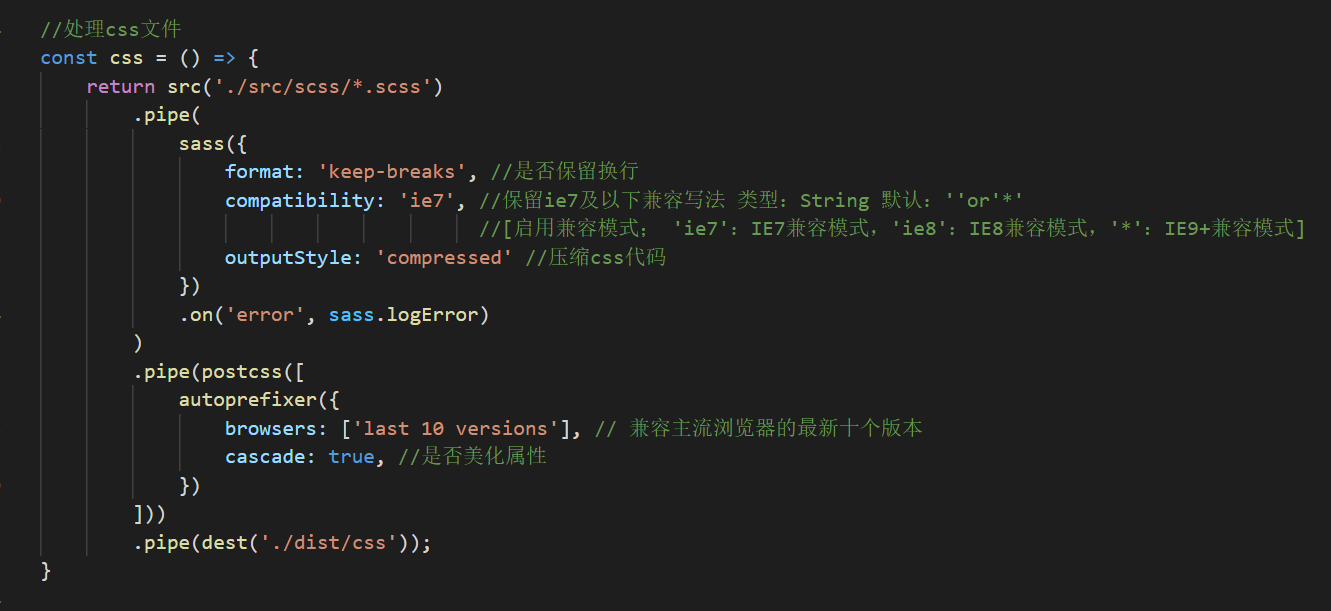
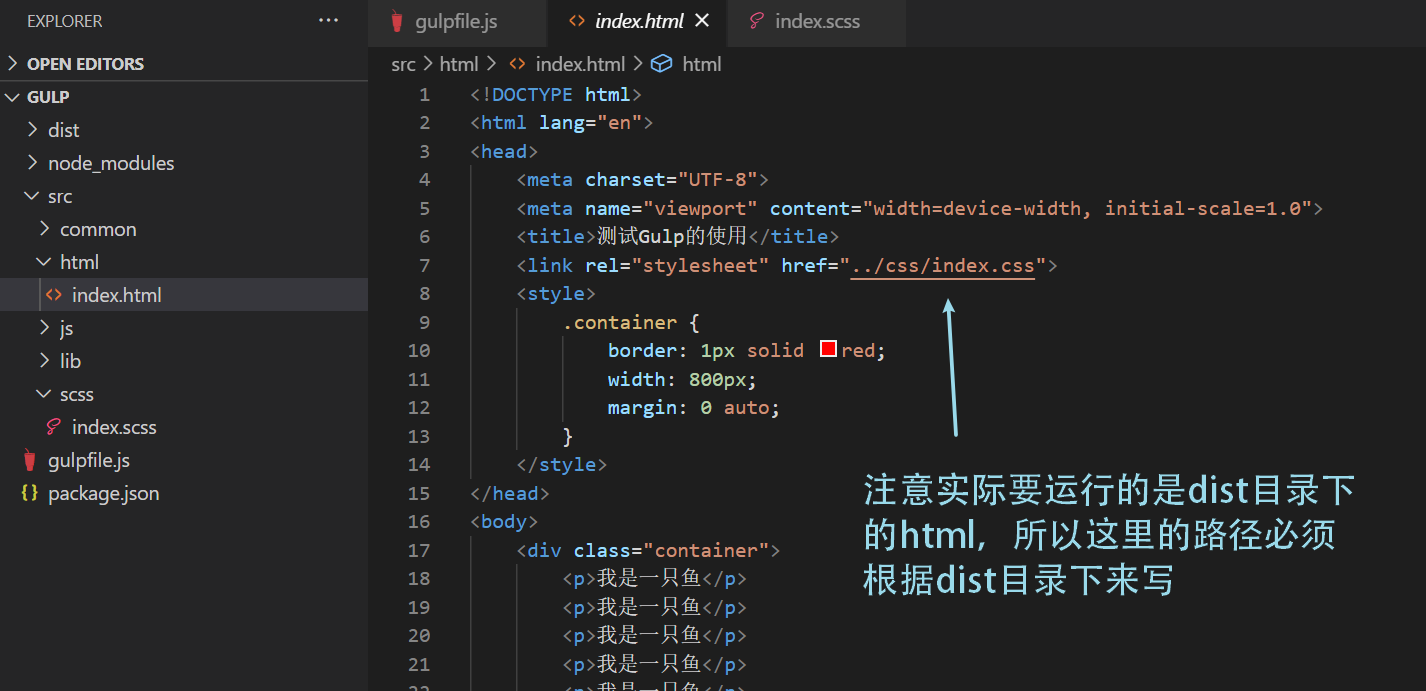
我们在src目录下的index.html文件也把样式文件引入一下,注意,引入的是编译后的css文件,而不是scss文件。
然后我们在gulpfile.js文件下面添加要执行的css函数:
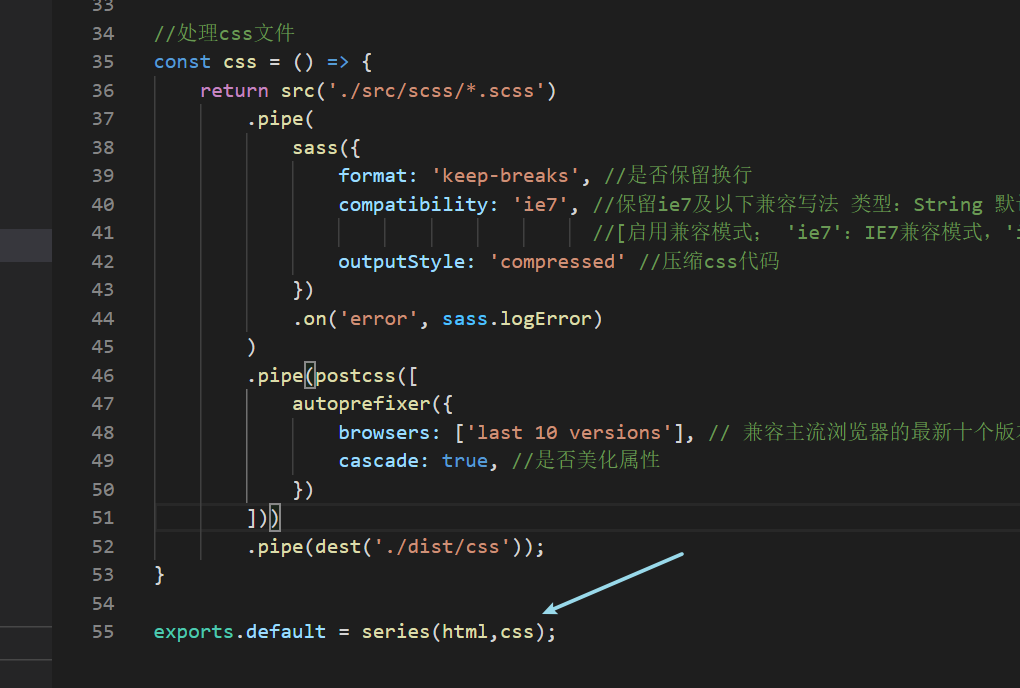
接下来继续运行gulp命令,我们可以看到dist目录下多了个编译好的index.css文件:

我们手动打开dist目录下的index.html文件,可以看到样式也是可以正常显示出来的:

处理JS文件
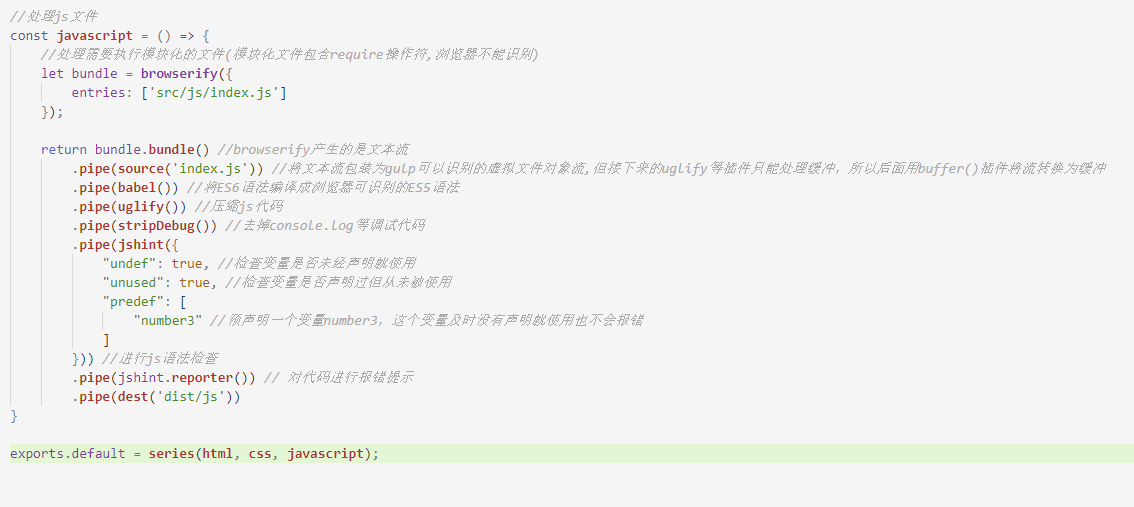
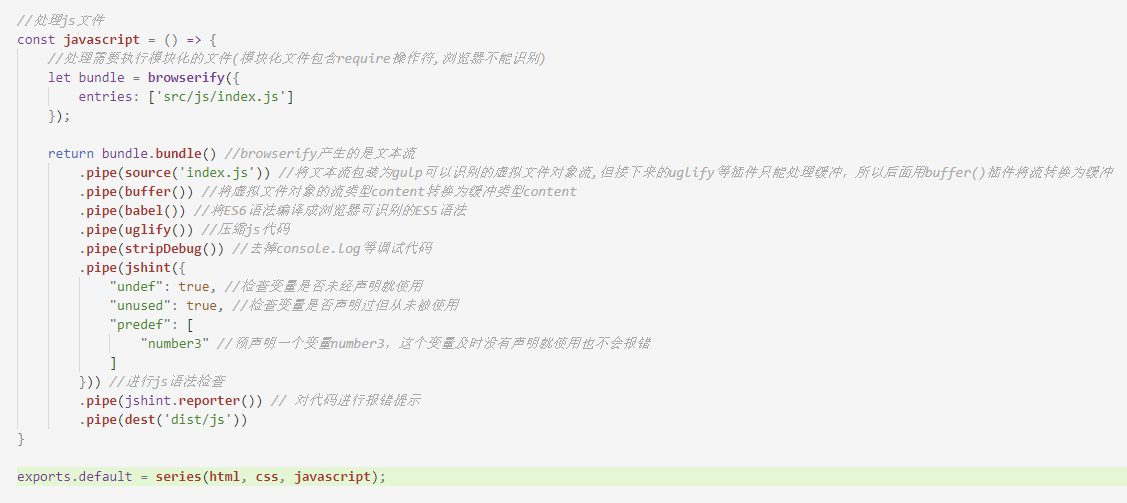
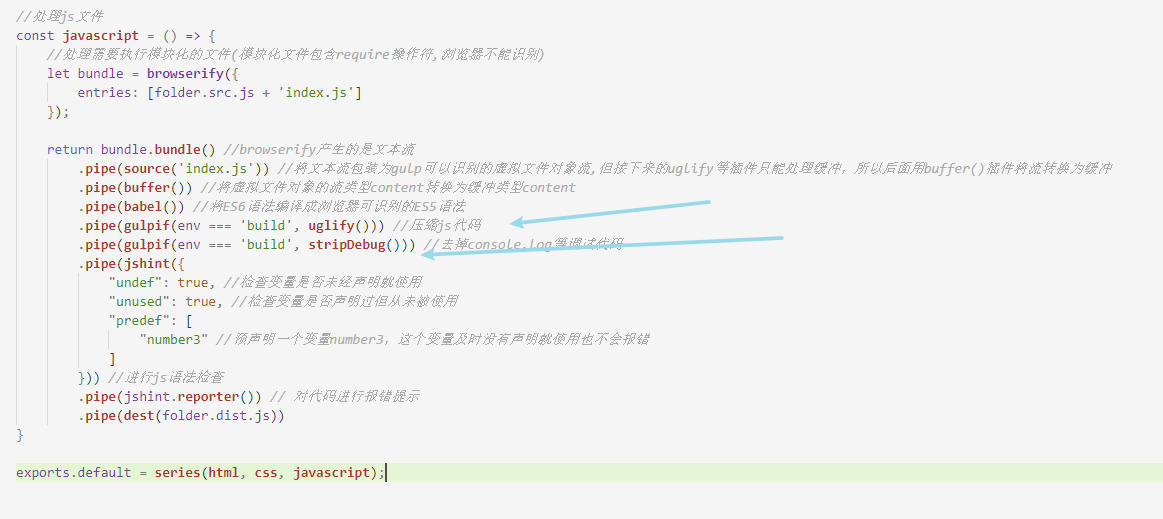
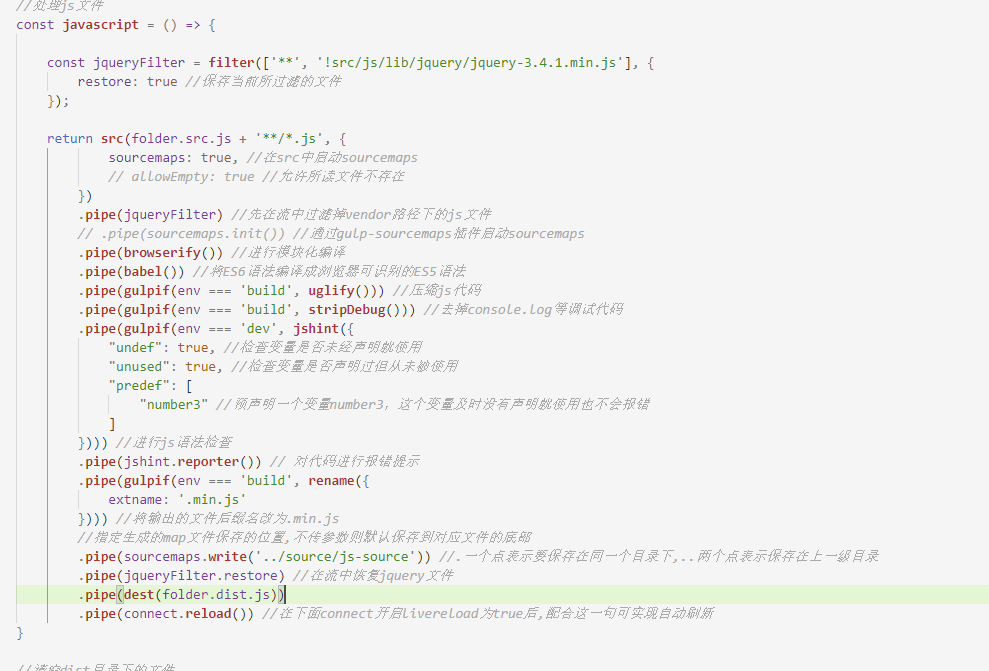
接下来我们来处理js文件,js文件的需要处理的内容稍微比较多,包括babel编译(将ES6语法编译为浏览器可以识别的ES5语法)、压缩JS代码、去掉调试语句(如console.log代码)、模块化编译、检查js语法错误。因为处理js涉及的插件比较复杂,我们这里一个一个来讲,首先介绍babel编译。
我们点击官网上方导航栏插件的位置,搜索一个叫做gulp-babel的工具。
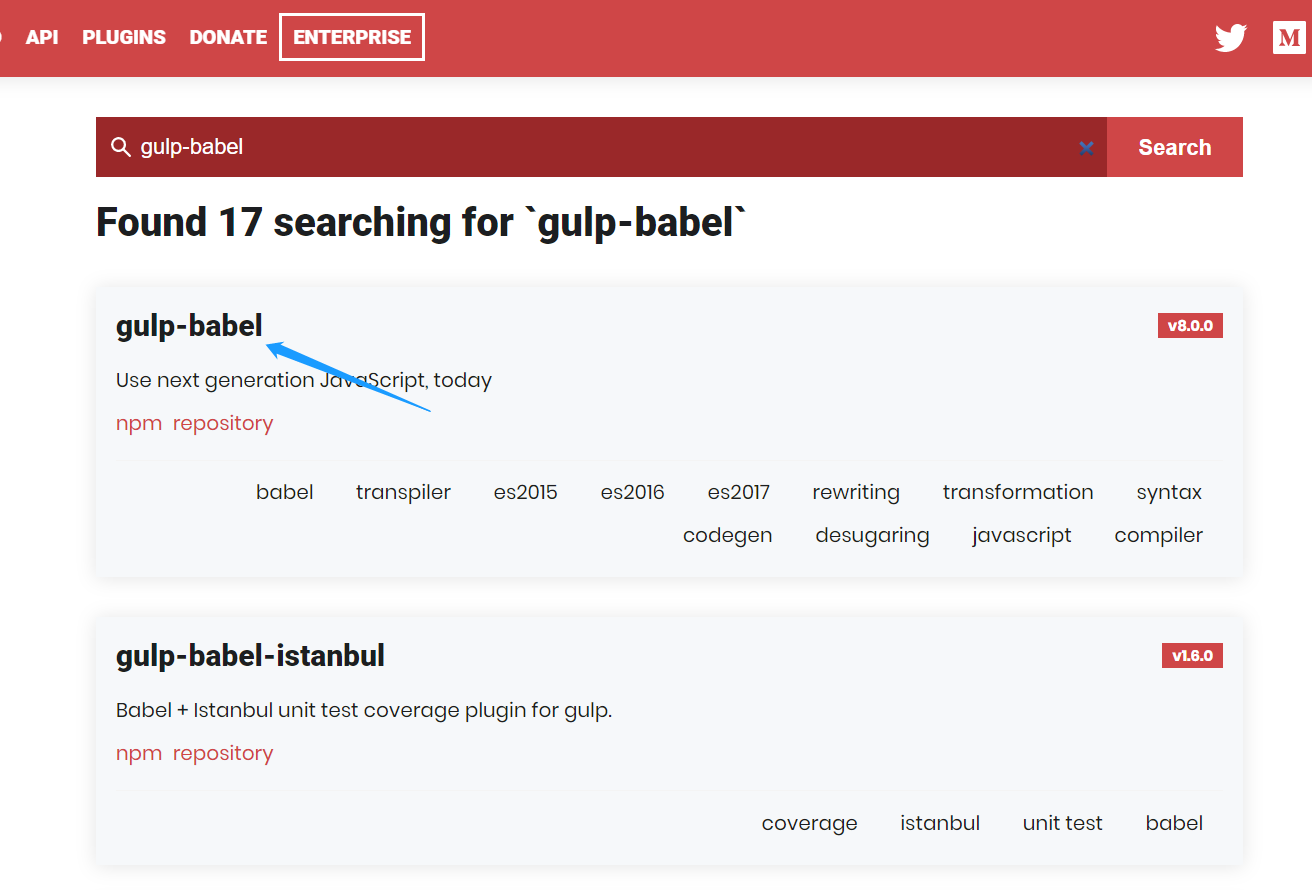
点进去之后根据提示,它要求执行两条语句中任意一条进行插件安装,我们选择最新的那条进行安装:
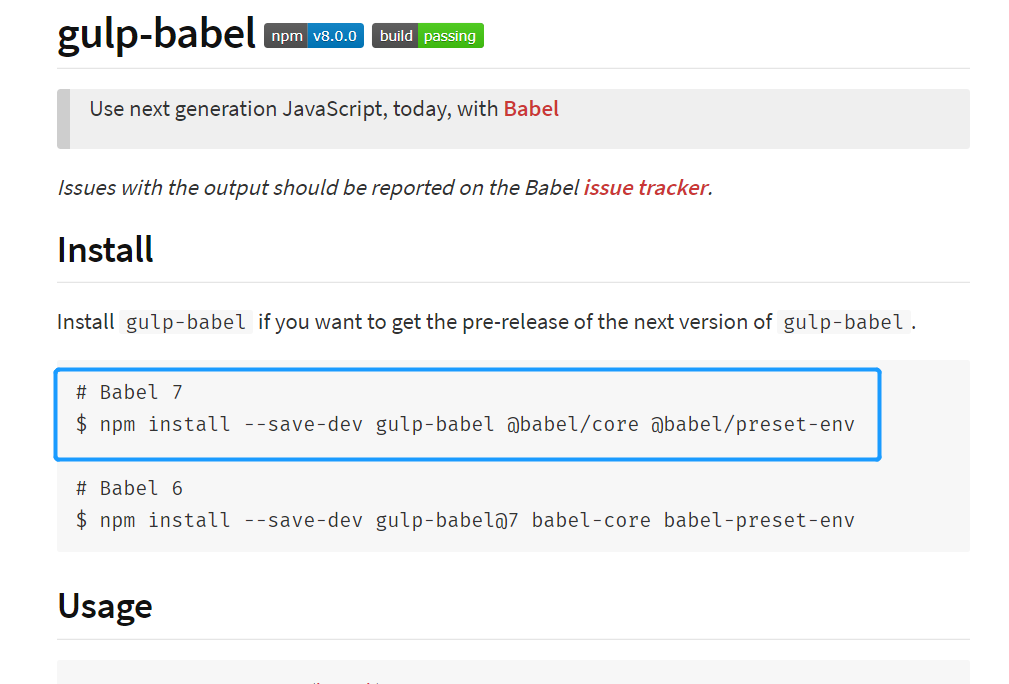
在命令行执行cnpm install --save-dev gulp-babel @babel/core @babel/preset-env :
![]()
(换了台电脑继续写这篇博客,所以路径不一样了哈)
接着我们在 gulpfile.js 文件编写javascript函数,并在src路径下的index.js文件随便写一些ES6语法的代码:


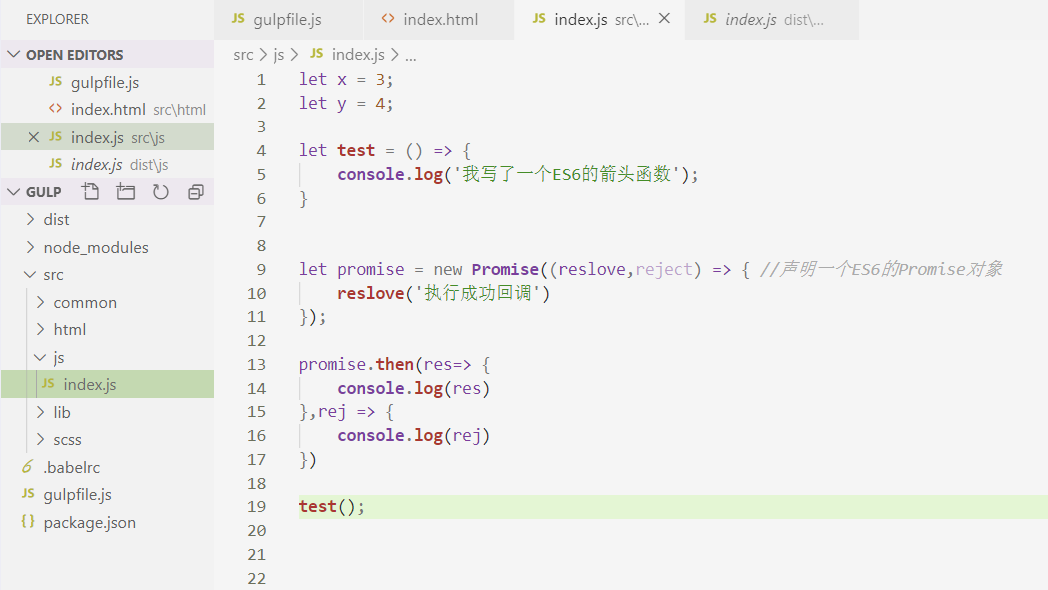
执行 gulp 指令,虽然顺利执行了,但编译出来的 js 文件并没有转换成ES5的语法......
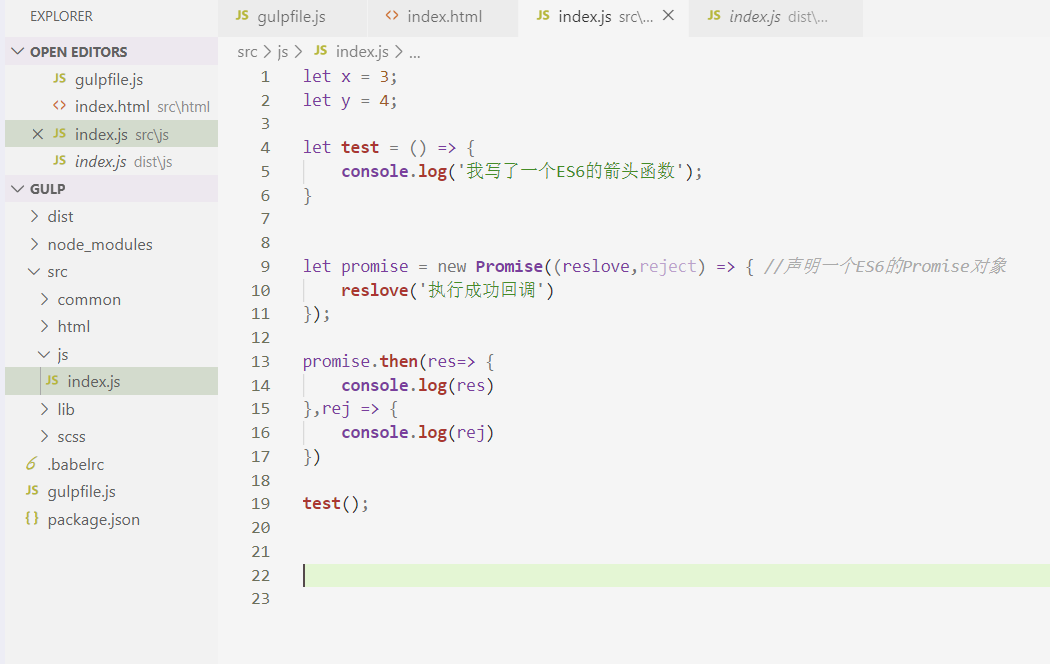
官网没有对此说明,百度了一下,说要添加一个叫做.babelrc的文件在根目录,我们创建这样一个文件,并输入以下代码:
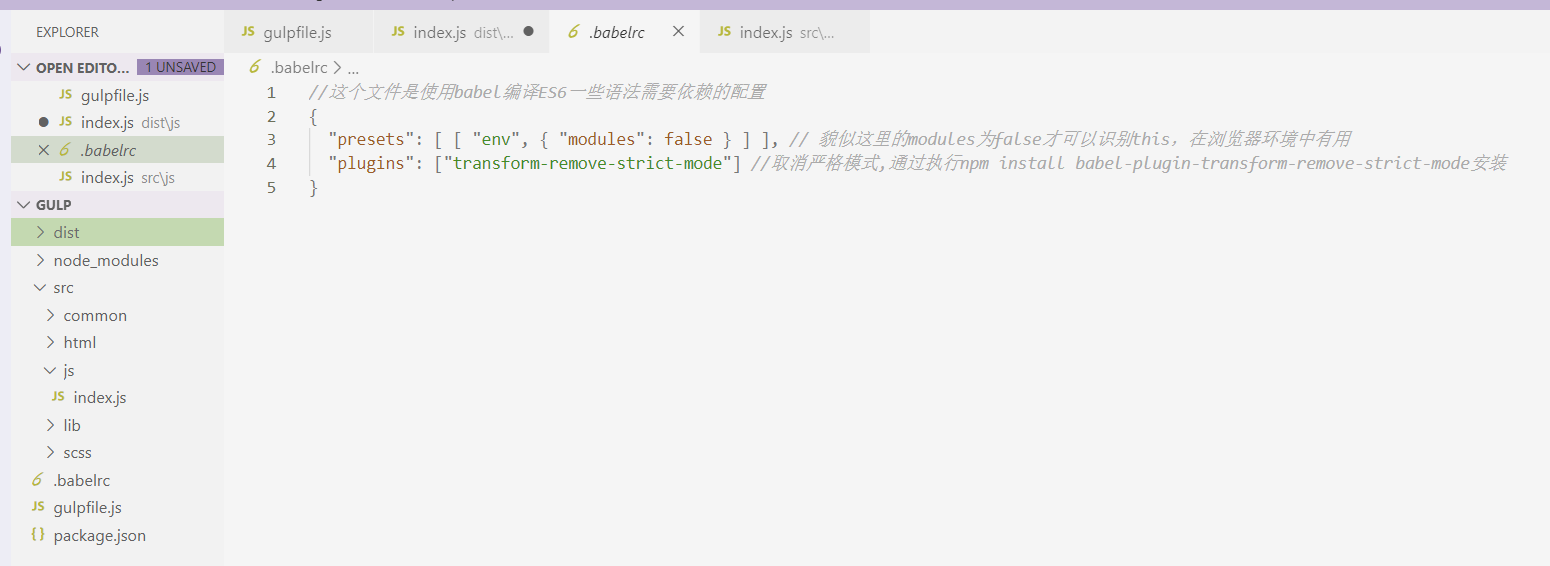
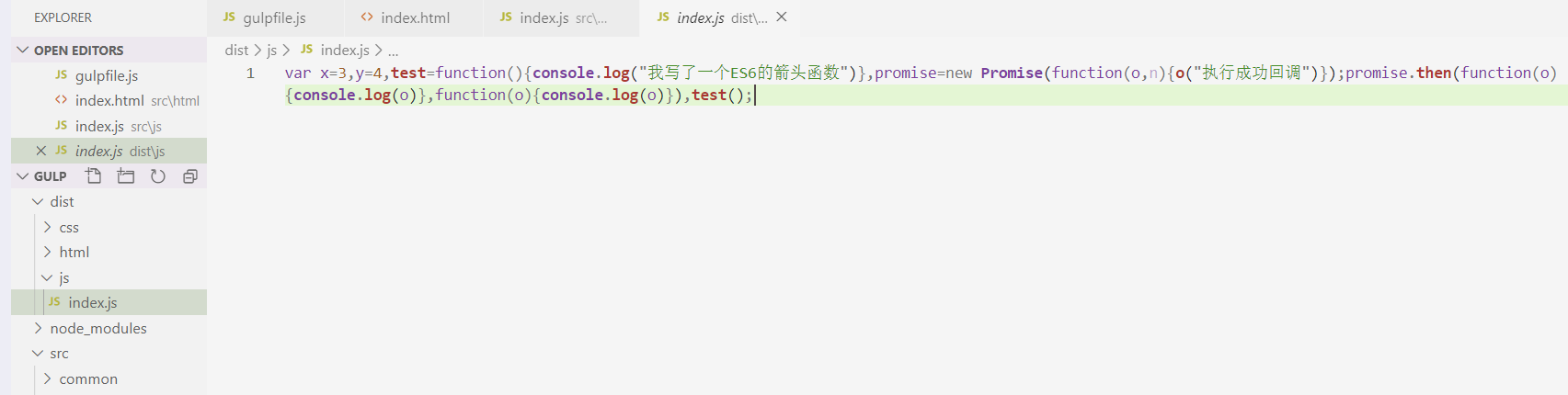
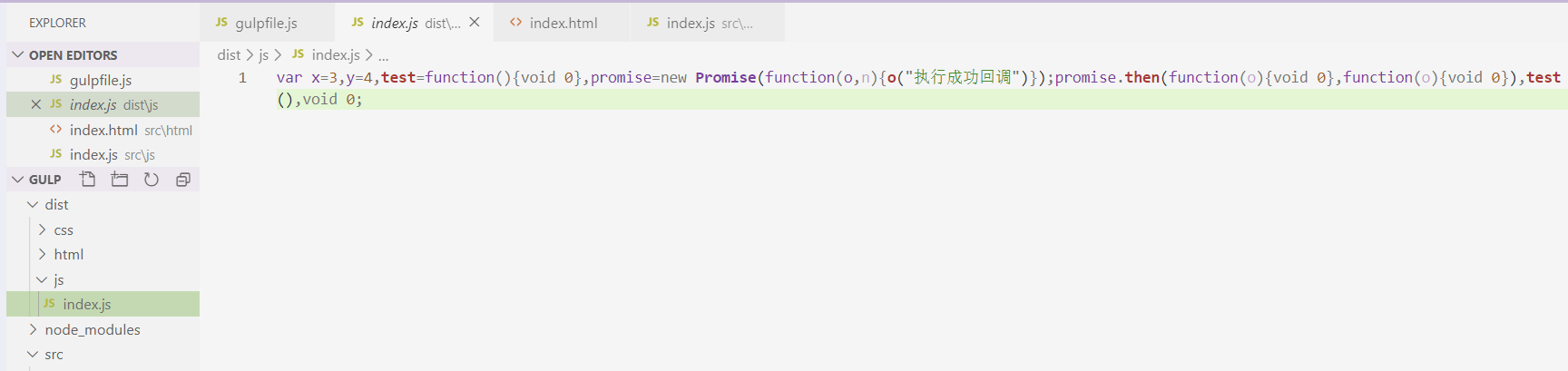
我们还要安装一个babel-plugin-transform-remove-strict-mode插件,执行cnpm i babel-plugin-transform-remove-strict-mode --save-dev ,接着继续运行gulp指令,发现js文件已经顺利转换为ES5了:
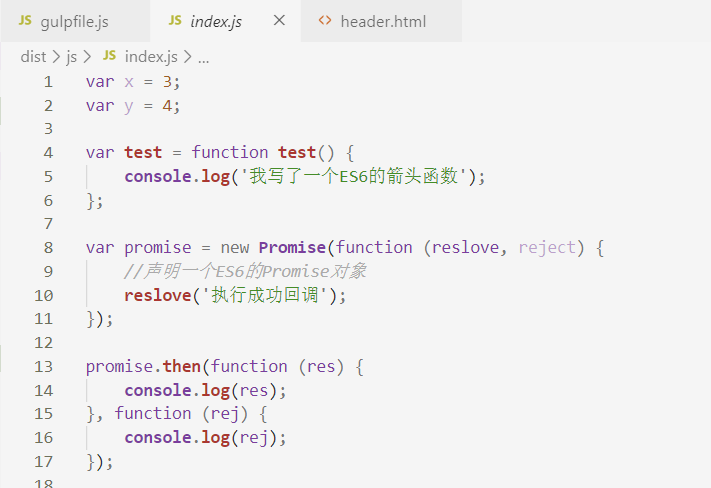
我们看到ES6特有的语法或者标识符,比如let、箭头函数都被转换为ES5的写法。当然,这里的Promise之所以没法转换,是因为Promise对象完全是ES6全新的东西,ES5并没有可以替代这个的语法。不过,现在新版的浏览器已经基本能识别Promise对象了。
我们接着介绍压缩JavaScript的插件gulp-uglify,这个插件使用比较简单,这里就不再赘述了,直接上图:


在使用之前依旧要记得先安装好这个插件,安装完后我们继续执行gulp指令,能看到dist目录下的js代码已经被压缩了:
关于js的第三个插件是去掉无用的调试代码,这里也不多说,直接上图:

执行gulp指令,发现dist目录下所有的console.log代码都被去掉了:
第四个关于js的功能是语法检查,这个功能依赖两个插件:jshint 和 gulp-jshint,我们执行cnpm i --save-dev jshint gulp-jshint同时安装这两个插件,它的使用方式如图所示:


我们在src下的js文件写点东西,然后运行gulp指令:
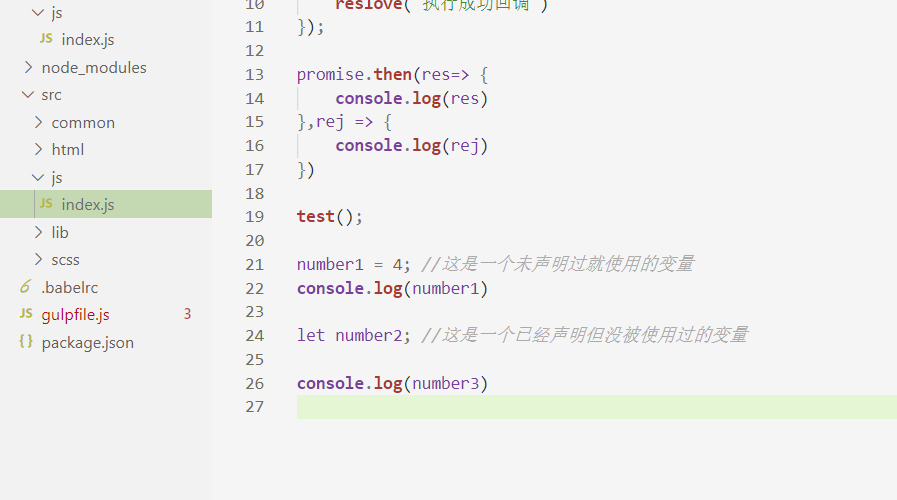
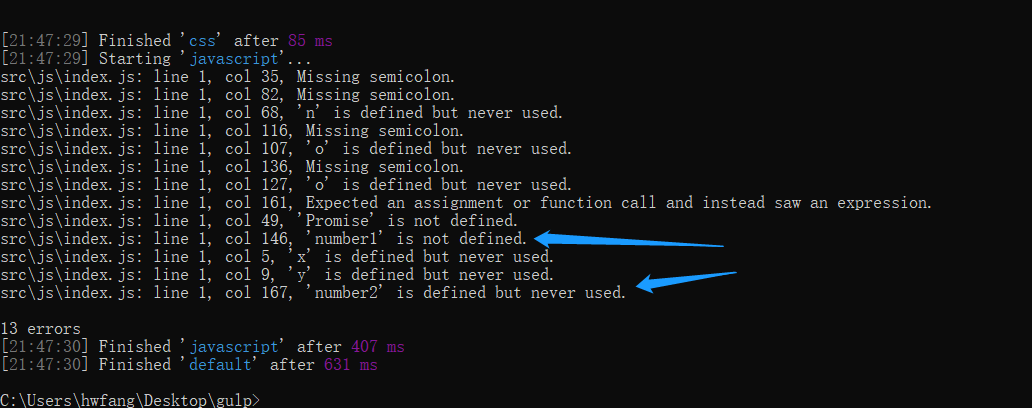
我们可以看到命令行窗口就对我们的代码的检查结果进行汇报了。
接着我们来介绍一下如何对 js 模块化,现在似乎用 webpack 的比较多,但这里我们使用 browserify 工具。首先要下载这三个插件,关于这三个插件的功能,接下来我会慢慢解释:

我们在src目录下创建一个module.js文件,用 module.exports 导出一个函数:
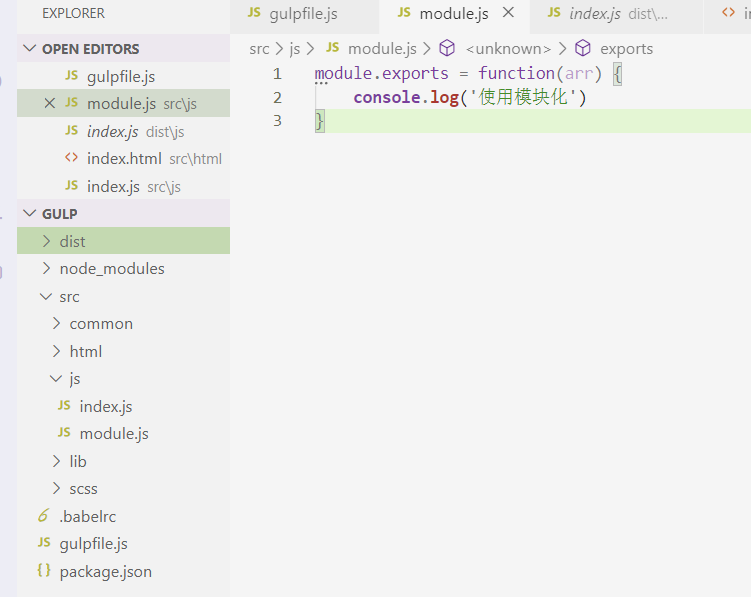
然后回到index.js文件下导入这个函数并执行:
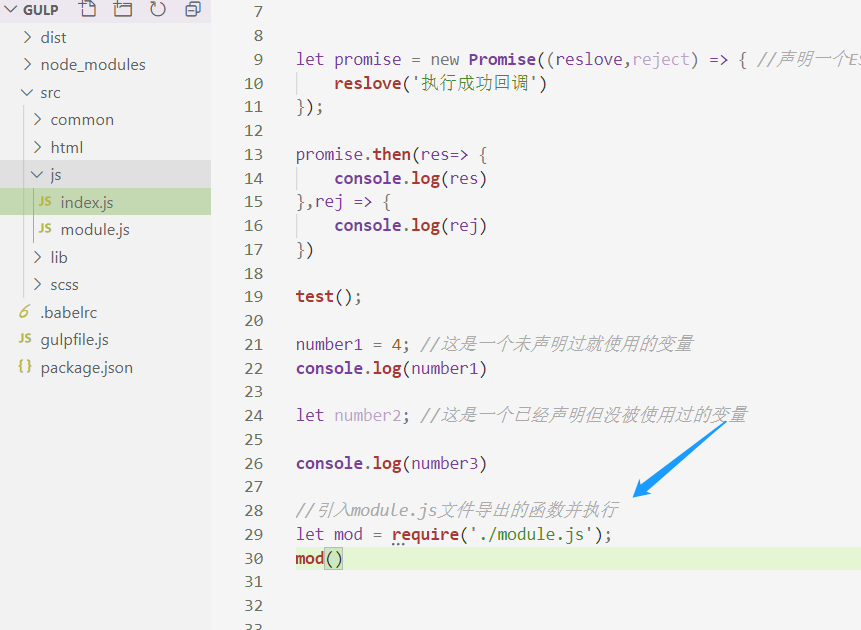
接着我们配置gulpfile.js文件,在配置之前我先解释一下Gulp的流。
在Gulp中,流是非常基本的概念,它是持续流动的数据。流一块一块的传递,从某个地方输入,最后在某个地方输出,中间对流的操作都是在内存中进行的。不过,虽然Gulp使用的是数据流Stream,但却不是普通的Node.js流,实际上,Gulp(以及Gulp插件)用的应该叫做虚拟文件对象流Vinyl File Object Stream。虚拟文件对象是硬盘里实际文件的替身,它包含了base、path和content三个属性:
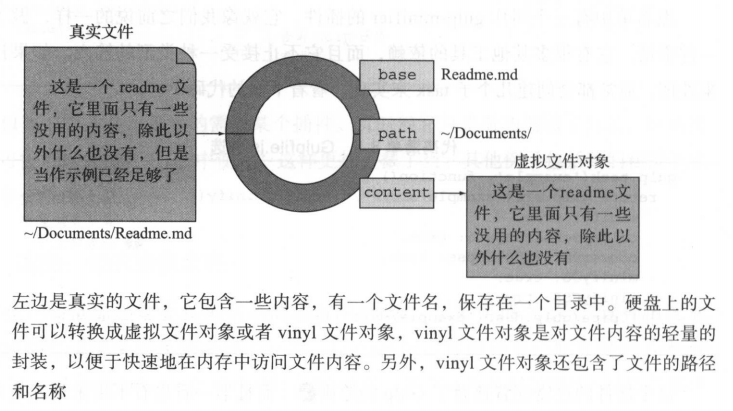
base和path属性表示文件的名称,每次当我们修改输出的文件名时(合并、重命名或者转换),都必须修改这两个属性(对于这些操作的插件,后面也会补充)。base属性只有文件的名称,而没有路径,便于快捷地重命名文件;path属性一般在你把一个文件从虚拟文件系统中保存到真正的文件系统中时(通过gulp.dest),才会被修改。而另一个属性content,则可以有两种类型的存在形式:缓存(buffer)或者Node.js流(node stream)。
一般来说。流在Node.js里面就是持续的数据流,这个数据可以一块一块地被读取(每一块的大小取决于这个流本身)。而Gulp.js流是基于对象(vinyl文件对象)的,每一块代表流中的一个文件。虚拟文件对象的内容也可以是某种流,比如可读文本流:
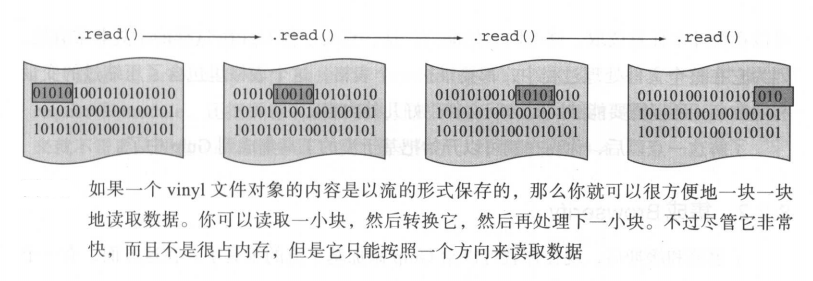
可读文本流可以非常快地处理数据,因为每次你处理的都是一小块(通常都是按行处理文件的),而且上一块处理好后就能把空间让给下一块了。但是这有点局限性: 每当一块数据已经处理好,并且你已经开始处理下一块时,你就不能再重新读取上一块数据了。
正因如此,有时候我们需要以缓冲的形式储存我们的数据。缓冲是计算机中预留的一部分内存,它在传输过程中是整个文件作为一个整体进行传输的,这些数据在内存里可以随意访问,有一个指针会给你想要的数据:

这个过程没有流那么快,因为你不能立刻抛弃你不再需要的结果。但换来的是可以在缓冲中任意读取、修改内容的能力。这一点对于像 gulp-uglify 这样的压缩代码的工具非常有用,因为它在整个文件处理过程中,都需要维护一个表格,这个表格里包含了压缩过的变量和函数名,所以需要能够同时访问文件中好几处内容。
了解了流和缓冲后,我们就可以给Gulp添加基于流的工具了,回到我们刚才的话题。模块化和依赖解决方案一直以来都是JavaScript的一个问题,Browserify发明了一个完全基于工具自身的解决方法,不需要JavaScript开发者学习任何新东西。它仅仅是把Node.js处理模块的方法加以修改,变成了浏览器也能用的方法,让我们能在开发客户端应用时像Node.js里那样引用模块。
Node.js的模块化方案是基于CommonJs规范的,什么是CommonJs规范呢?它导出导入模块的方式如图所示:
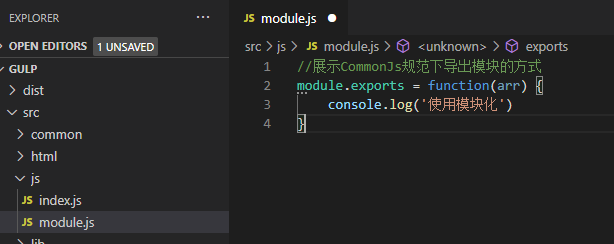
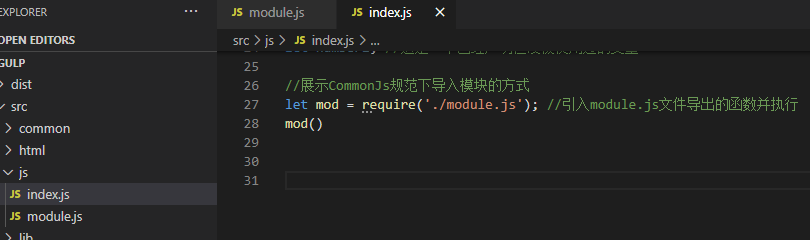
CommonJs规范规定使用 require() 方法导入模块,使用module.exports 或 exports 导出模块。但我们的浏览器并不认识require、module.exprots 这些关键字,而这就是Browserify诞生的原因。它不仅往全局命名空间里添加了require和module,还把所有引用的模块打成了包,浏览器加载好就能使用了,这样一来就不需要从硬盘(或者服务器)中加载文件了。
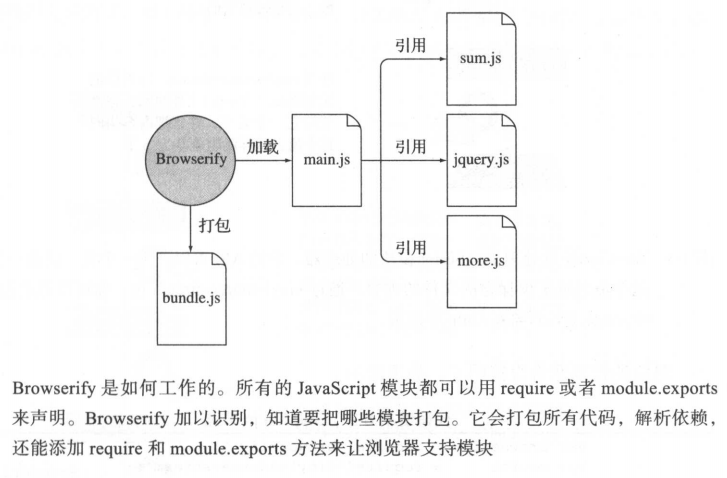
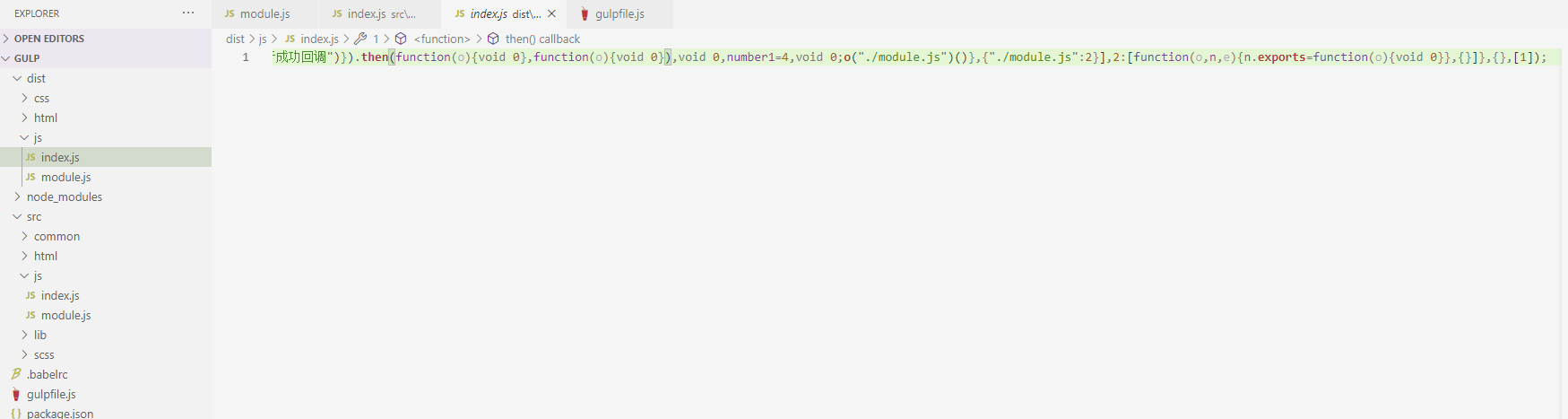
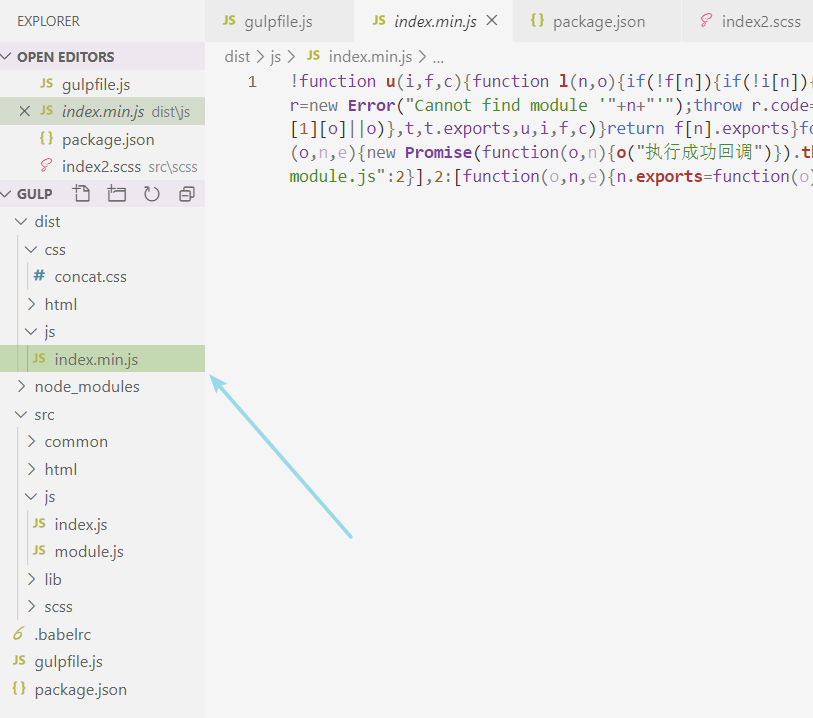
于是,我们在js文件中使用到的模块化代码,现在只要通过browserify工具编译就可以在浏览器正常运行了。但是,有一个问题在于,Browserify产生的是文本流,而Gulp使用的是虚拟文件对象流。两个流是不同类型的,但如果你仔细看了我前面的介绍,你会知道Gulp的content属性基本上也是一个文本流。
所以,只要创造一个空的虚拟文件对象,将content属性赋值为Browserify产生的文本流,再在这个对象中加入base属性和path属性,就可以创建一个Gulp管道可以处理的虚拟文件对象了。这个过程我们可以借助 Node.js 的 vinyl-source-stream 模块,也就是我前面处理模块化在文件中引入的第二个插件,这个插件可以将Node.js流包装成虚拟文件对象流。
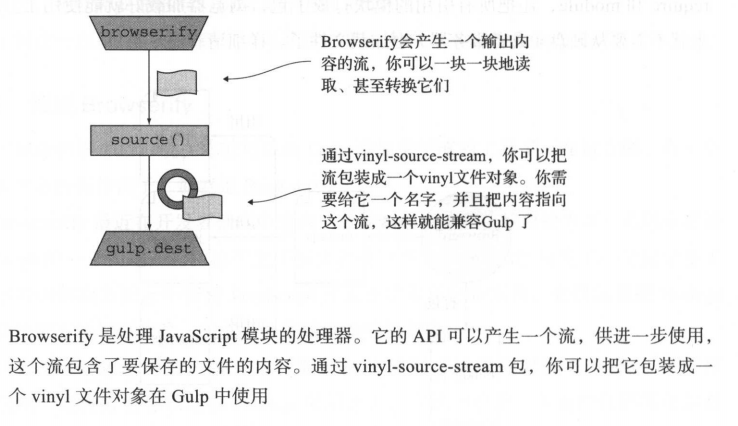
现在我们回到 gulpfile.js 文件处理 javascript 函数,我们先注释掉其它代码,关注模块化编译的过程:


执行gulp指令,可以看到dist目录下的 js 文件中的模块化代码已经被编译好了,它在顶部暴露模块化API,并将我们src目录下的module.js文件整合到了index.js文件中(仔细看上面的代码,我并没有读取module.js文件,但编译出来的index.js文件包含了module.js文件的内容):
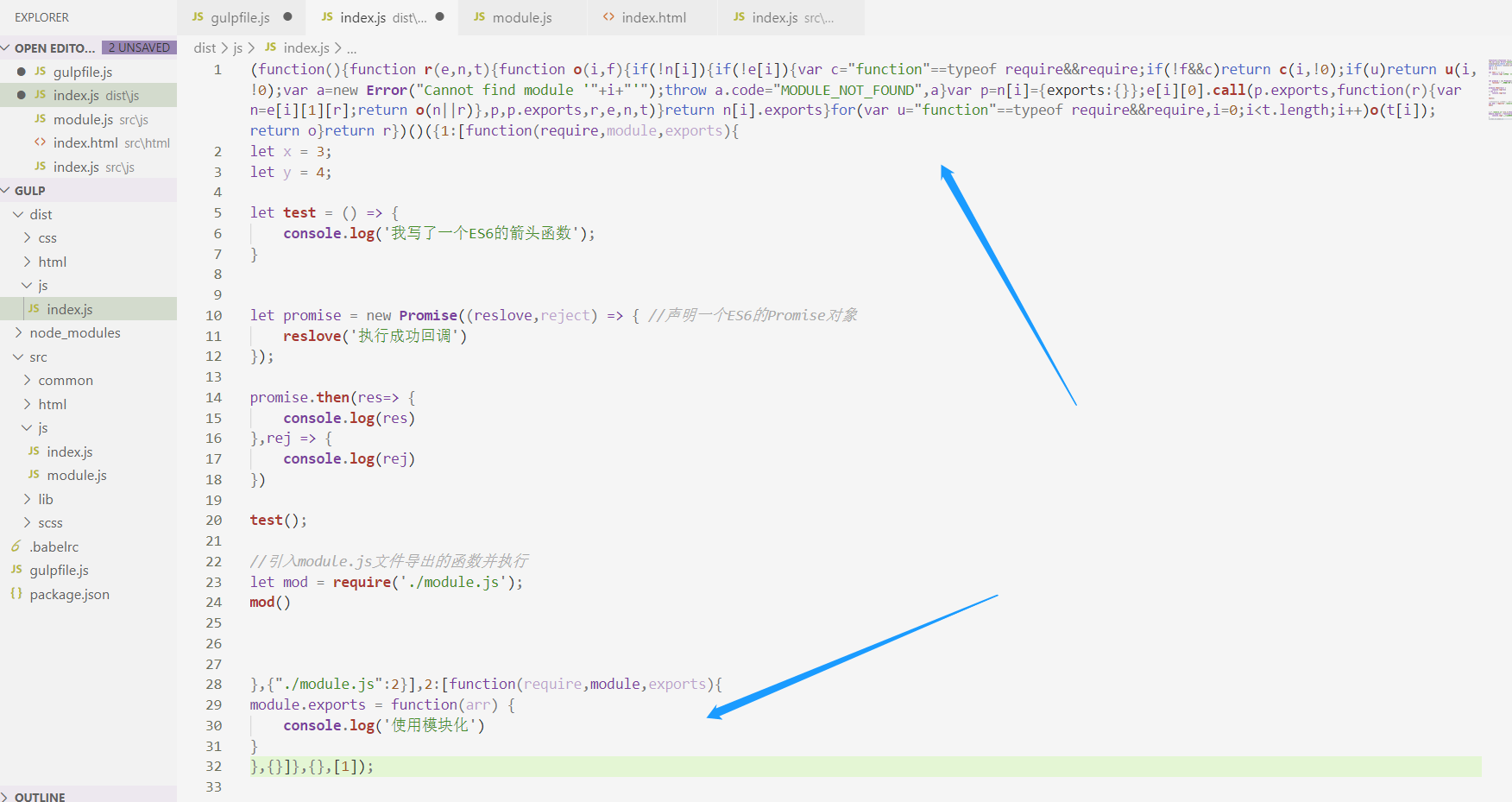
source方法自动帮我们将index.js文件和moudle.js文件合并为一个文件输出到dist目录下的index.js文件中,如果你已经在src目录下的index.html引入index.js文件了,运行完打开dist下的index.html文件,你还可以从控制台看到执行结果:
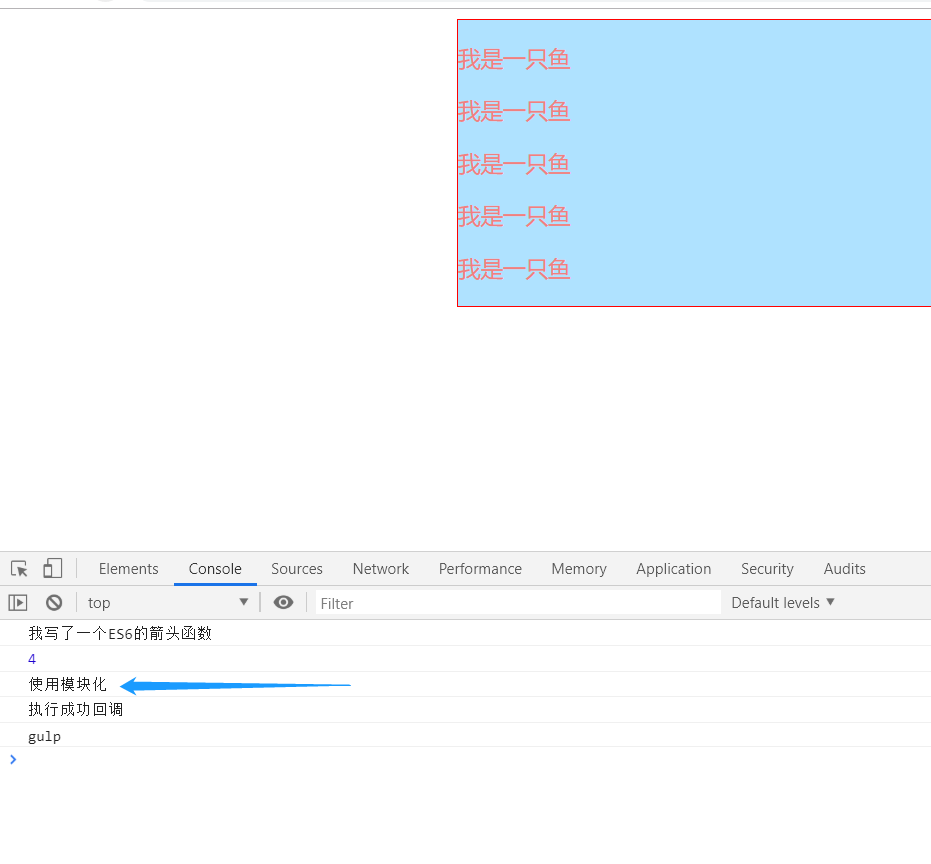
那我们还要对js代码进行babel编译、压缩代码等其它操作,我们把其它代码复制到dest()方法前面:
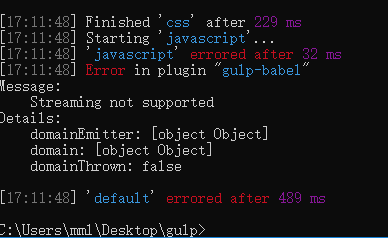
执行gulp指令后控制台会报一个错:
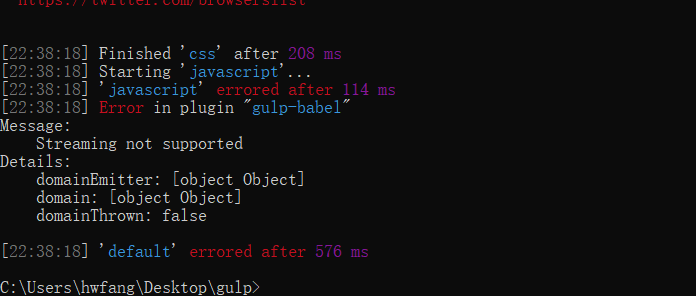
在运行到gulp-babel插件的,控制台提示流不支持。原因是之前browserify工具读取路径下的文件形成的是文本流再被vinyl-source-stream插件包装成虚拟文件对象的,而像 gulp-uglify 这些插件需要对JavaScript代码做语法分析,就必须保证代码的完整性,不能以文本流的形式去读取,而要一整块以缓冲 buffer 的形式去读取,因此在这里要把文本流转换为缓冲 buffer。那有人可能会问了,之前在使用 gulp-uglify 之前也没刻意进行转换,为什么之前的流能正常工作呢?其实,之前的虚拟文件对象流中的content是缓冲类型的,在我们一开始使用 src()方法时,这个方法就默认以缓冲的形式去读取路径下的数据了:

注意:各类Gulp插件虽然操作的都是虚拟文件对象,但可能会要求不同的content类型,有些需要以缓冲的形式处理,有些只需要以Node.js流的形式处理。
如果你把这里的buffer值设为false,则gulp会以文本流的形式去读取,那样还是会报出相同的错误的:

回到原来的代码,我们要解决这个问题,就要安装一个叫 vinyl-buffer 的插件,它能帮助我们将虚拟文件对象的content属性从流转换为缓冲,以兼容其它Gulp插件:

现在再运行gulp指令,你会发现可以正常运行了,browserify处理后的模块化代码也被正常压缩。
对于用Gulp搭建前端开发环境处理HTML、CSS和JavaScript,我已经将一些比较核心重要的内容介绍完,当然,还有很多是必须做补充的,接下来我会慢慢完善我们的 gulpfile.js文件。
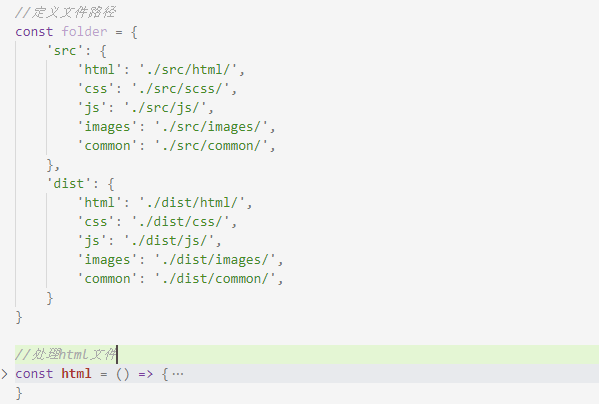
为了我们的文件路径便于维护,我们现在把所有公共路径都写到一个统一的 folder 对象里,然后将所有src和dest方法里的路径都替换拼接一下:



一般我们的代码打包输出到dist目录分为两种情况,一种是线上的代码,一种是开发时使用的代码。在开发的时候,我们并不需要对代码进行压缩,或者去掉调试语句,这些功能是为线上代码服务的。我们可以下载一个叫做 gulp-if 的插件,判断在不同的情况执行不同的代码。我们在全局定义一个变量 env 作为判断的条件:
![]()

前面我们把env变量赋值为 'dev',所以接下来我们执行gulp指令后,gulp-if 插件会判断当前第一个参数是否为true。如果为true 就执行后面的方法,如果为 false 则跳过。我们来试一下,看看执行gulp指令后dist目录下的文件是否没有再进行压缩了:
代码已经没被压缩了,说明 gulp-if 插件没有执行压缩代码的方法了。那我们把 env 变量赋值为 ‘build' 再执行一遍,看看是否会压缩:

代码又被压缩了。但在实际开发过程中,如果老是要手动去修改这个变量,就显得非常麻烦了。有没有什么更直接的方法,让我们不用去gulpfile.js文件里修改代码,就能改变env变量呢? 答案是肯定的。我们要引入一个Node.js中一个叫 yargs 的插件,引用方法如下:

然后我们在gulpfile.js文件中将env变量赋值为arguments对象中的env属性:

接着我们在命令行窗口执行 gulp --env=dev,这句话首先会将yargs插件中的argv对象(即我们在开头的arguments变量)中添加一个属性,名为env。并将env属性的值设置为 ’dev',然后自动执行gulp。我们安装完yargs插件后直接来试一下:
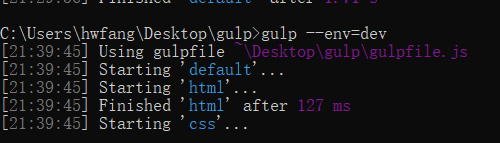
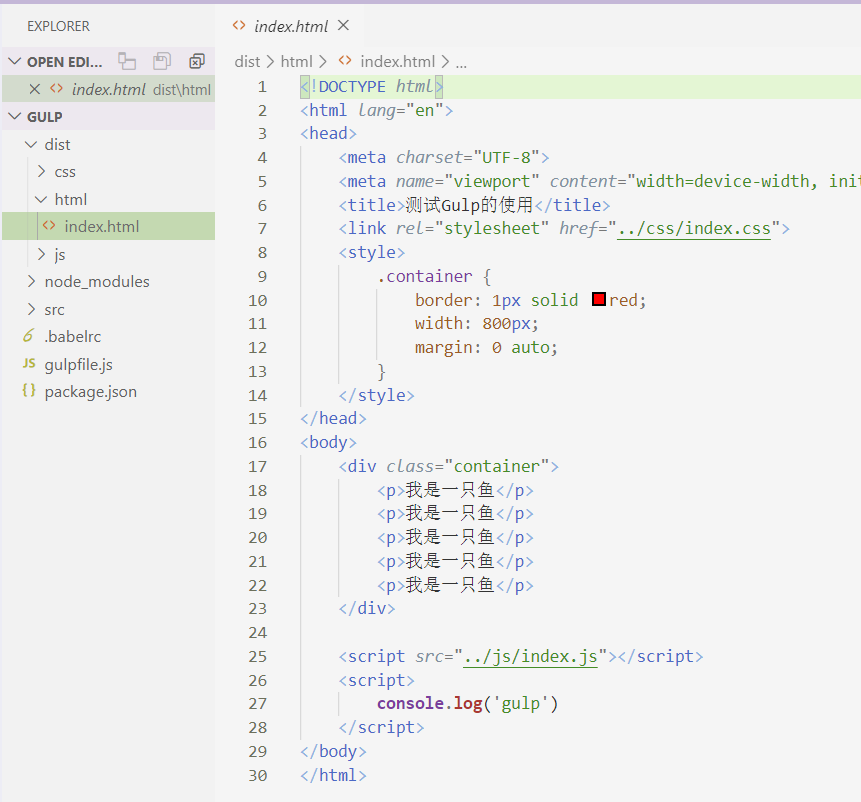
然后看回我们dist目录下的文件,发现代码又没压缩了:
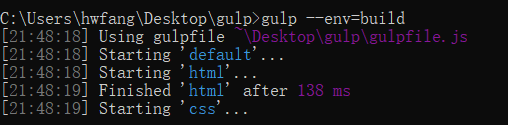
那我们执行gulp --env=build 来试一下:
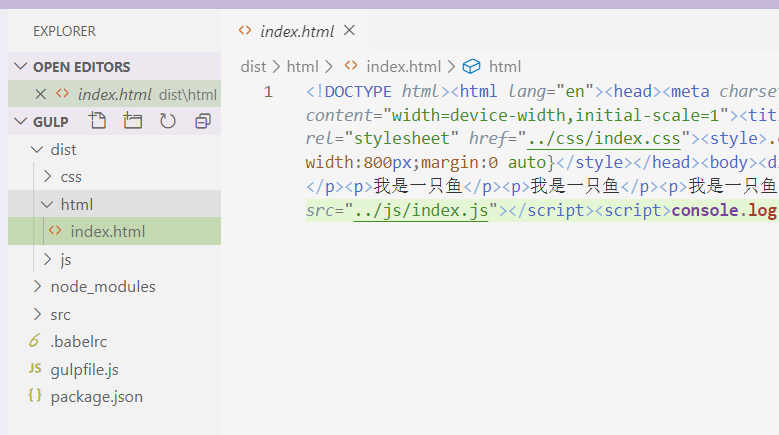
文件又压缩回去了。但每次在命令行给env赋值其实也很麻烦,我们能不能把这两条命令提前写好在某处,然后以其它更简便的方式运行呢?答案也是可以的。我们只需要打开package.json文件,并找到scripts属性后添加进这两行,然后以后运行就能以 npm run dev 或者 npm run build 的方式分别执行其中的gulp指令了:
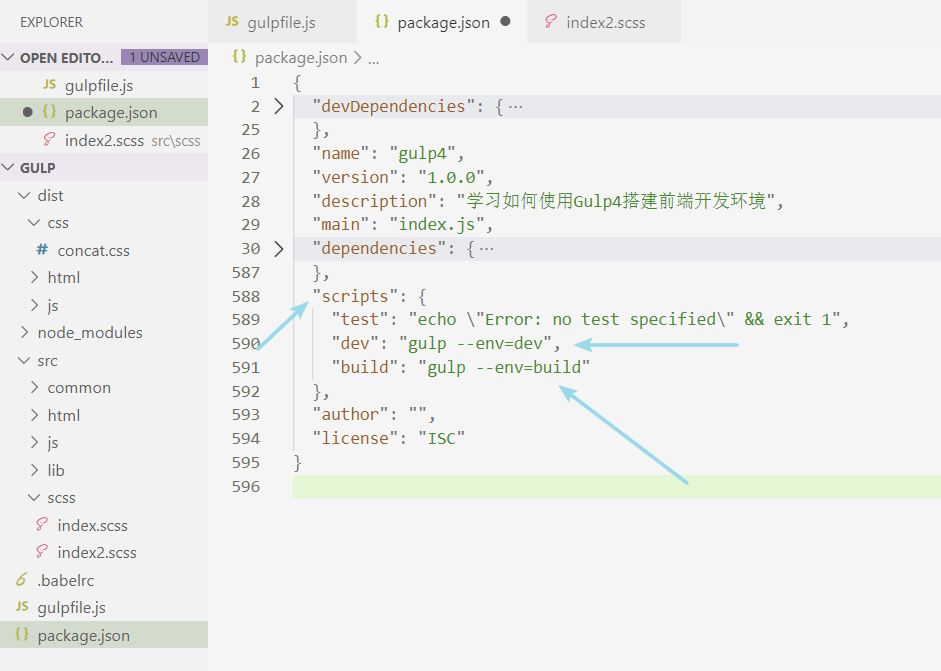

自己尝试着运行你可以看到,以后你每次执行 npm run dev ,它都会去 package.json 文件下查找 scripts 属性下的dev属性,然后执行dev属性所对应的那条语句。
介绍完参数解析yargs插件,再来介绍一个gulp-clean插件。这个插件是用来帮助我们删除文件的,一般我们执行gulp生成新的dist目录下的文件时,是以覆盖的形式生成的。即原来如果已经存在dist目录,如果里面的文件和你新生成的文件没有冲突,那就还是会继续保留着。但我们显然不希望这样,而是希望每次都生成全新的dist目录。因此我们可以借助gulp-clean插件来实现这个目的:


我们先引入插件,并创建一个新的cleanDist任务,用于清空dist目录下的所有文件。然后在导出的方法中添加到series的最前面。这样以后执行都是先进行清空目录再输出新的dist目录。
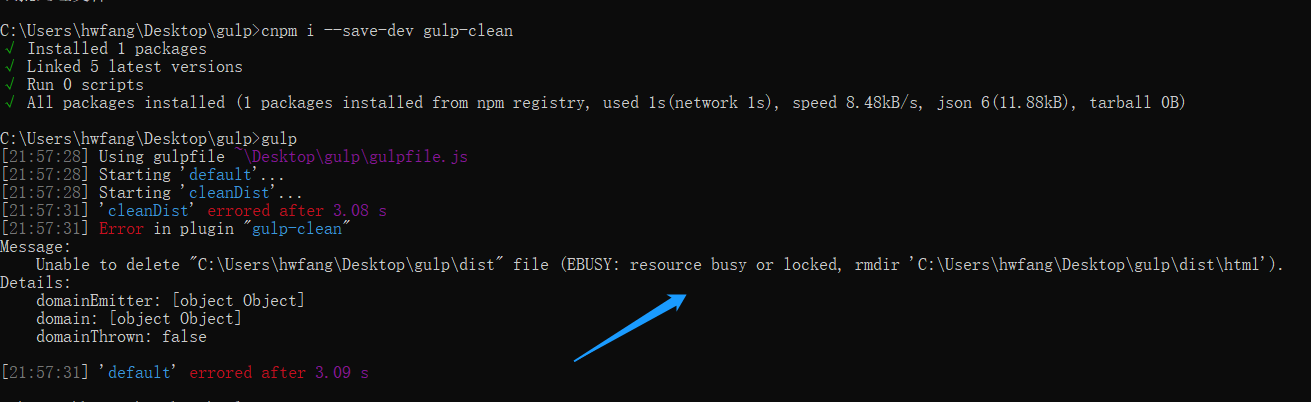
有时候执行会遇到这种情况,我也不知道为什么,手动删除也删不了。这种时候重启一下电脑再试试看吧。
还有一种情况要注意,如果你的文件夹中本来就没有dist文件,那么执行代码是会报下面这个错的,解决方法就是把 src 方法下的allowEmpty 属性设为true就可以了。
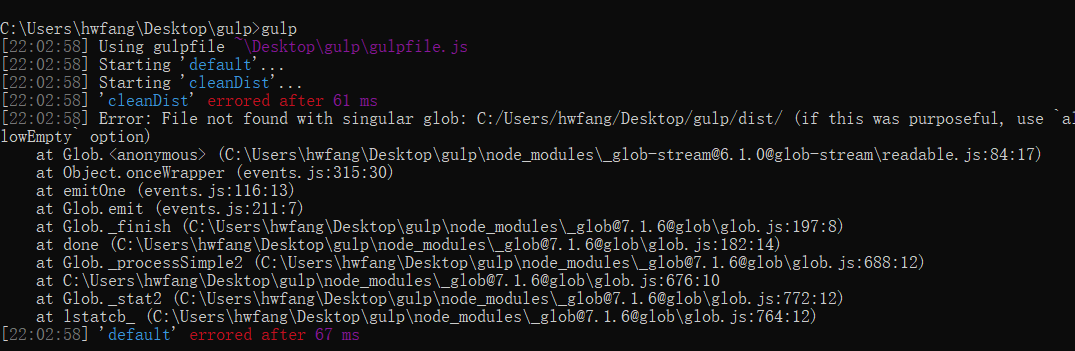

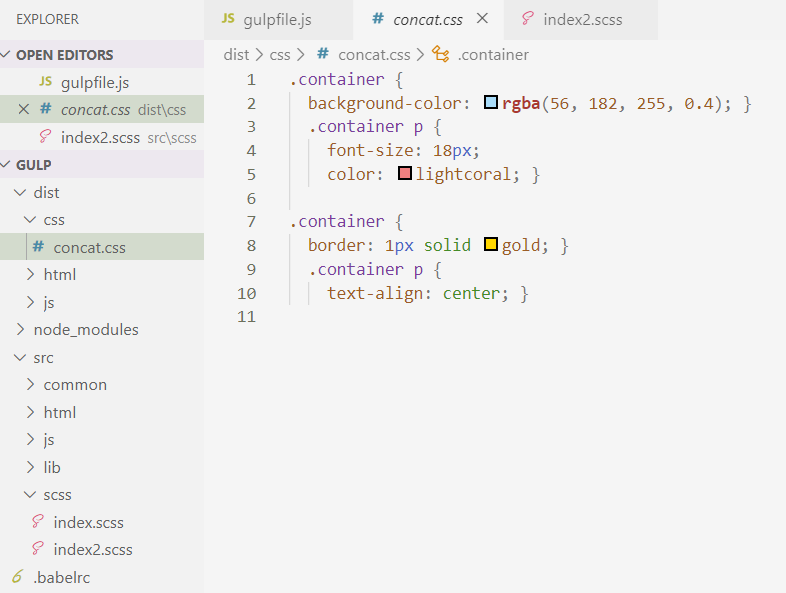
接下来教大家使用合并文件插件。为了减少网络请求,提高网站运行速度,我们经常会把多个文件合并成单个文件再进行引入,首先我们需要安装 gulp-concat 插件并引入:

我们举css为例,我们在src目录下再创建一个scss文件,写上一些内容:
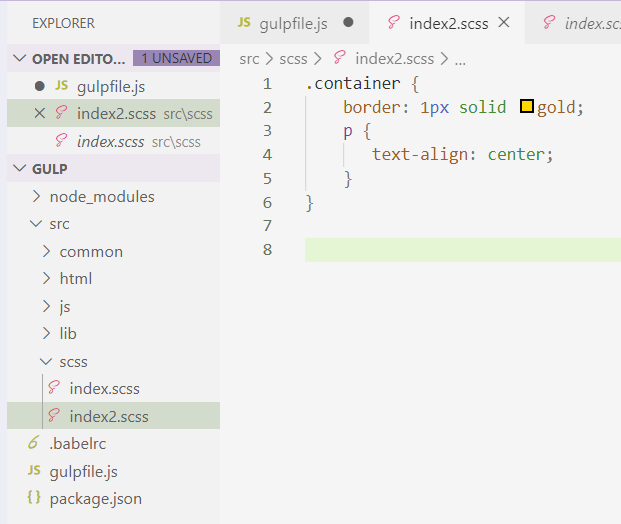
然后编辑css函数,再里面新增一行:

执行gulp指令,我们看到两个scss文件被顺利合并为一个concat.css文件了:
再介绍一个重命名插件 gulp-rename,我们的dest方法一般输出的文件名和原来的文件名是一致的,但如果我们想改一下文件名呢,比如对于压缩了的 .js 文件,我希望它的后缀名变成 .min.js ,我们就可以这样做:


我们执行 npm run build 指令,可以看到我们原来输出的 index.js 文件名被改为 index.min.js 啦:
再介绍一个 sourcemaps 插件,我们先改一下src目录下的index.html文件的引入路径,再改一下 gulpfile.js 这两个地方方便执行 npm run dev 的时候控制台有输出,然后执行一下 npm run dev并打开dist目录下的 index.html 文件 :
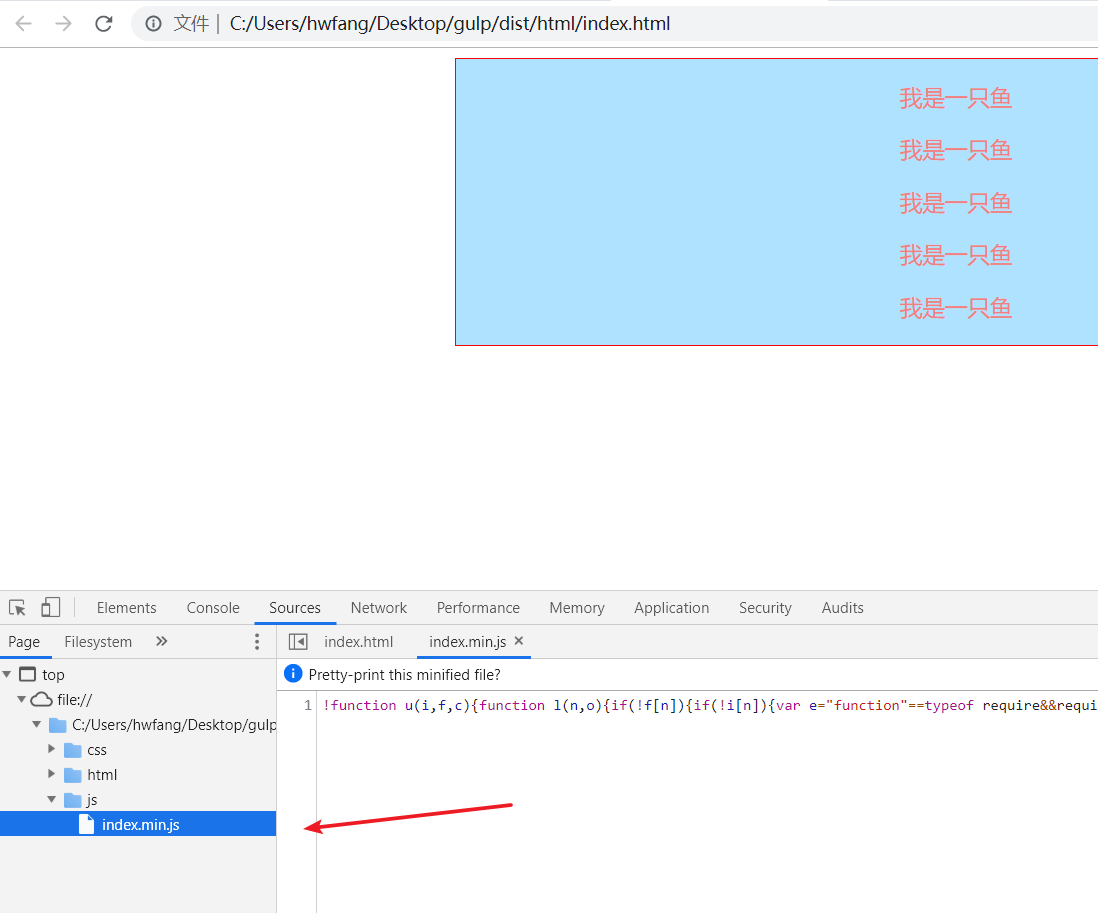
找到控制台Sources,点击并展开左边的目录,找到我们的 index.min.js 文件。或者如果你的控制台有输出信息并能链接到文件,你也可以这么点击:
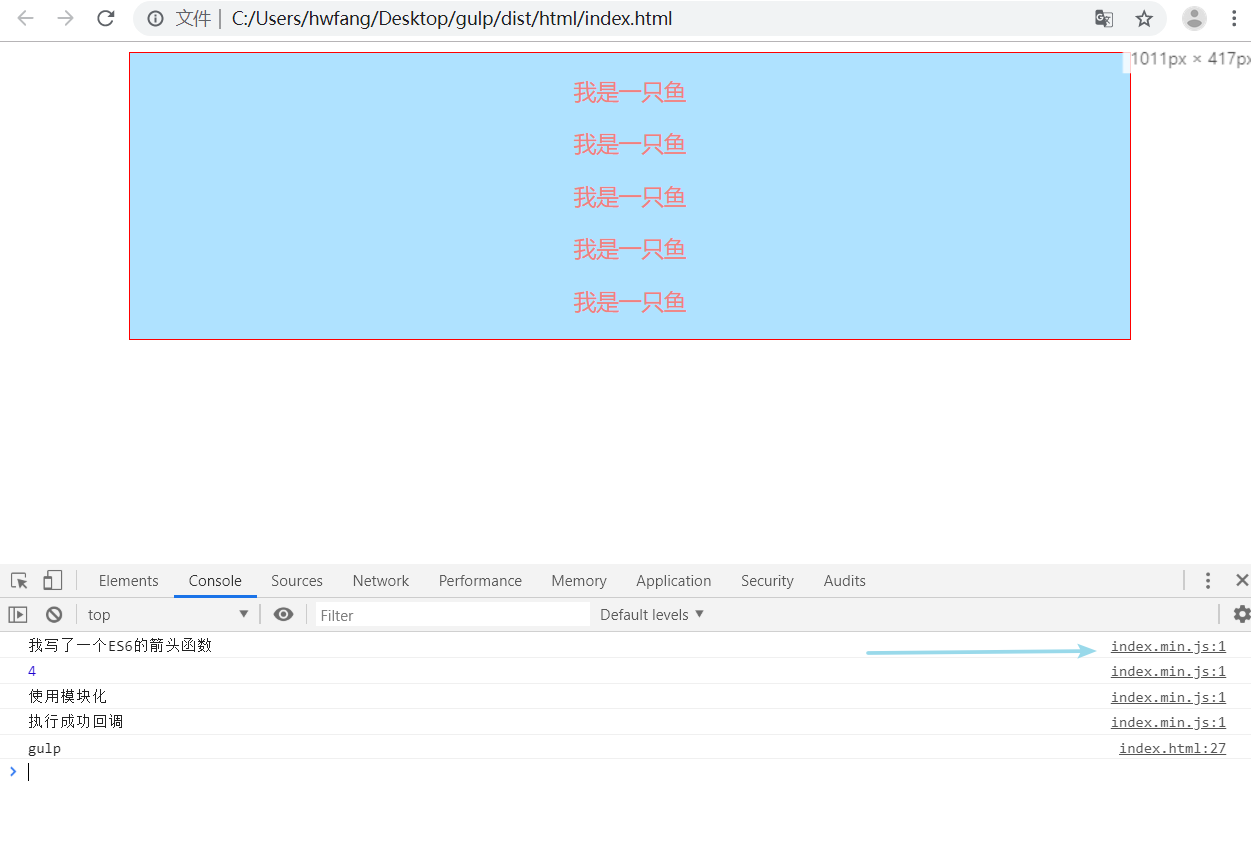
我们一般需要在控制台看文件,都是通过第二种形式去点击查看哪个文件出了报错信息。那问题来了,不管你用哪种方式点击去控制台找到这个文件,你看到的都是这个文件的压缩版。尽管这意味着我们的代码在生产环境被压缩得很好,但对于开发者而言,我们还是希望看到原始的代码。
那难道我们就不应该对代码进行压缩以防止查找不到线上意外生成的bug吗?当然不是。有些浏览器,比如Chrome,可以在一定程度上格式化代码,但我们还是看不出来变量名和函数名。为了克服这个问题,浏览器开发商Google和Mozilla合力推出了sourcemap。sourcemap是一种能够追踪编译代码源文件的技术,让浏览器知道如何获取所加载的代码的源文件。
有两种方法能够让浏览器知道sourcemap的存在,一种是在编译好的代码里的注释中加上 sourcemap 的URL,另一种是直接把sourcemap 添加在代码里。
sourcemap的内容是把编译好的代码分割成很多小块,每一小块在sourcemap里都有引用,分别包括三个属性:
① 代码来自于哪个源文件。
② 代码来自于源文件的哪几行。
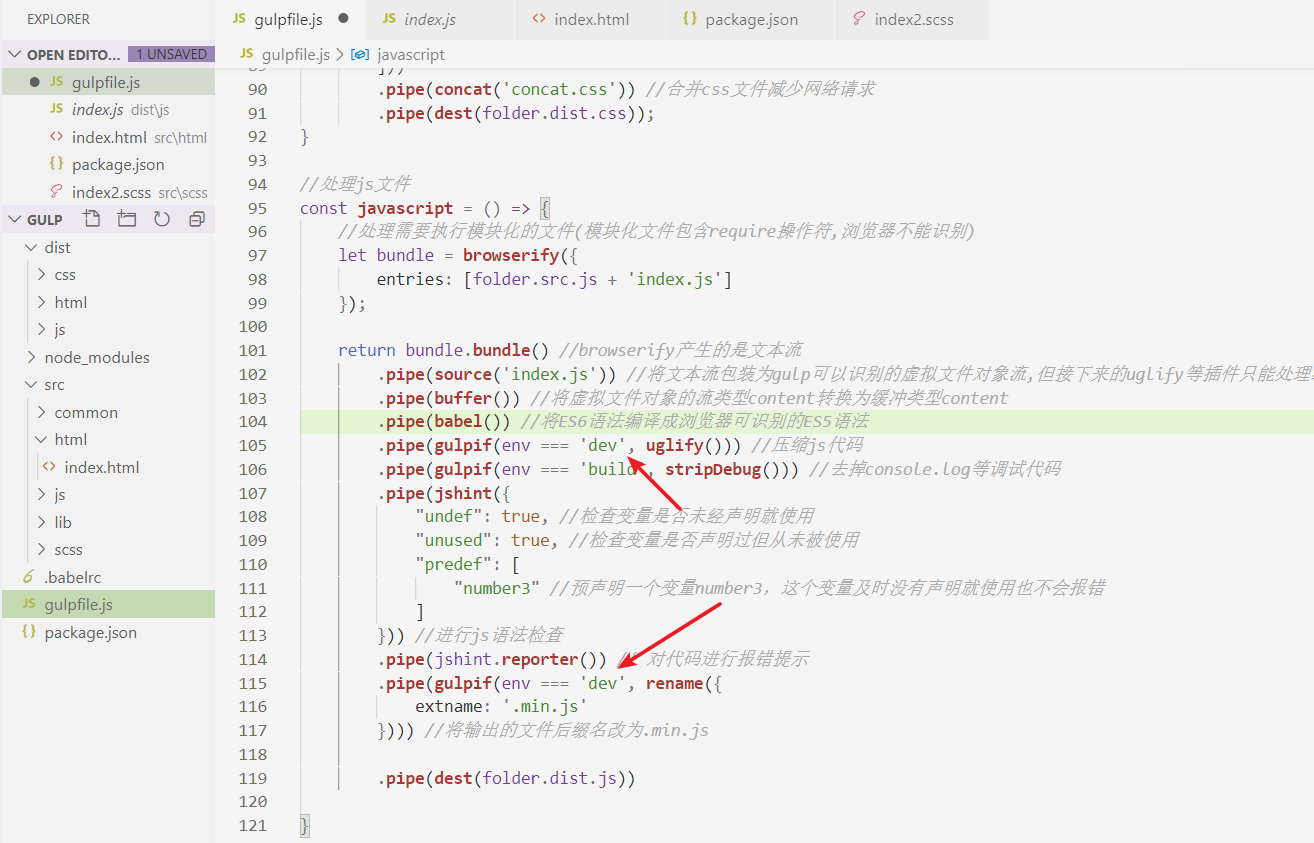
③ 如果代码用到了其他部分的变量,还会包括原来变量的名字。
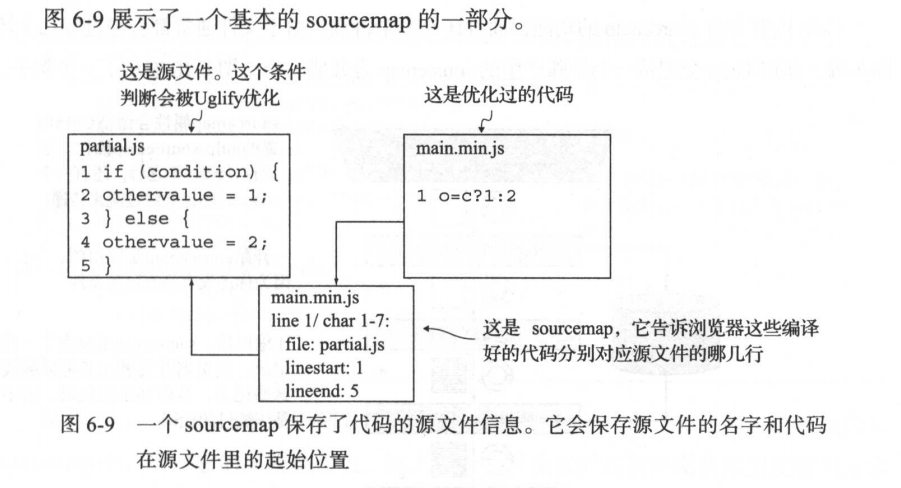
此外,源文件的代码也被包括在sourcemap里,这样就可以确保任何设备不需要源文件都能加载sourcemap。
Gulp内置支持sourcemap的功能,而且会把流处理的每个步骤产生的sourcemap合并成一个:
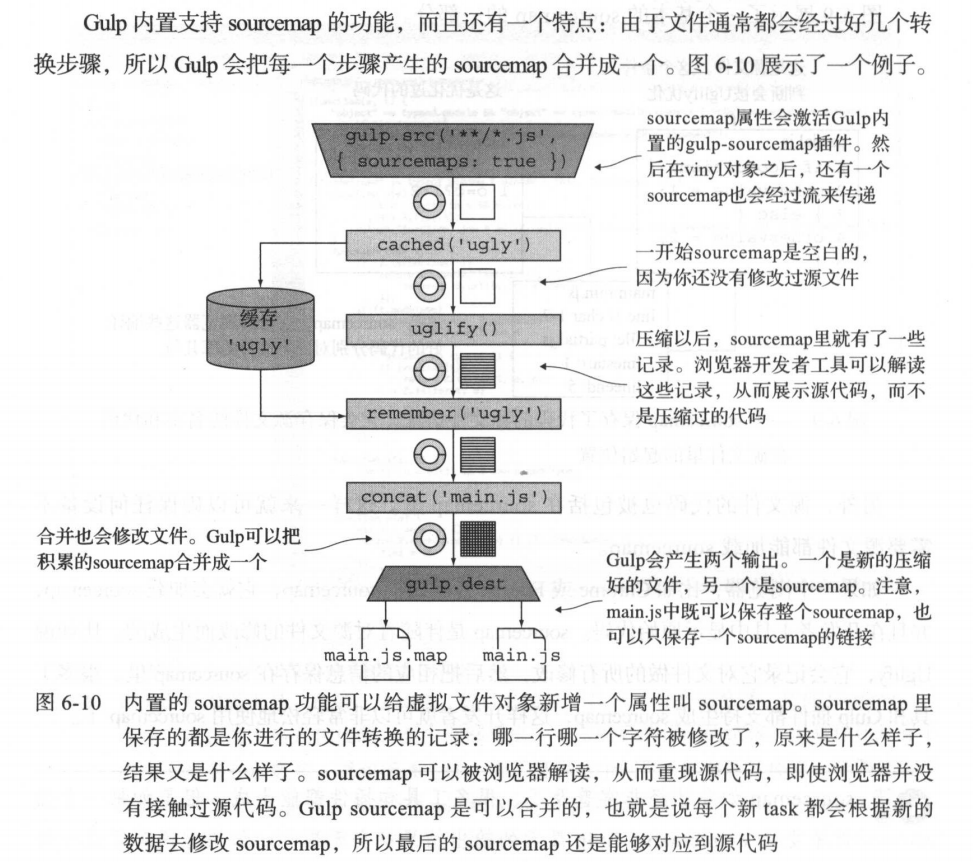
具体要怎么做呢?首先,我们要安装这个插件:

然后改一下javascript函数:

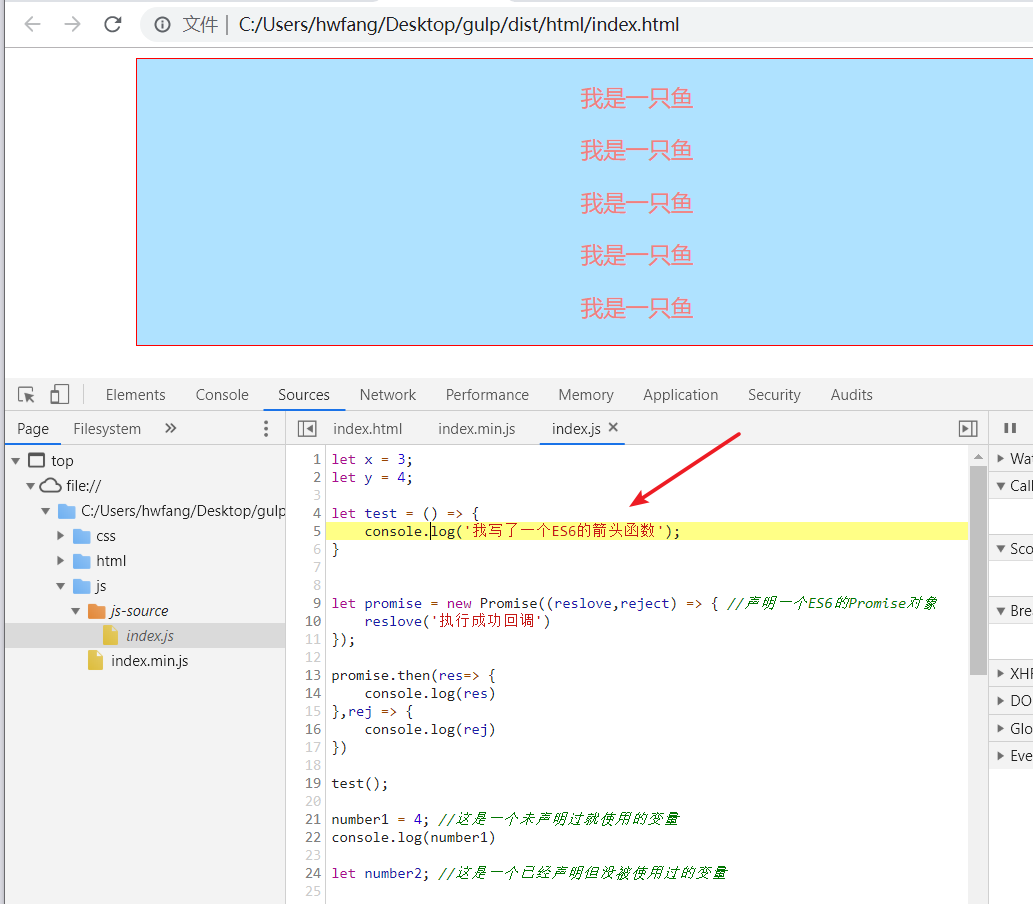
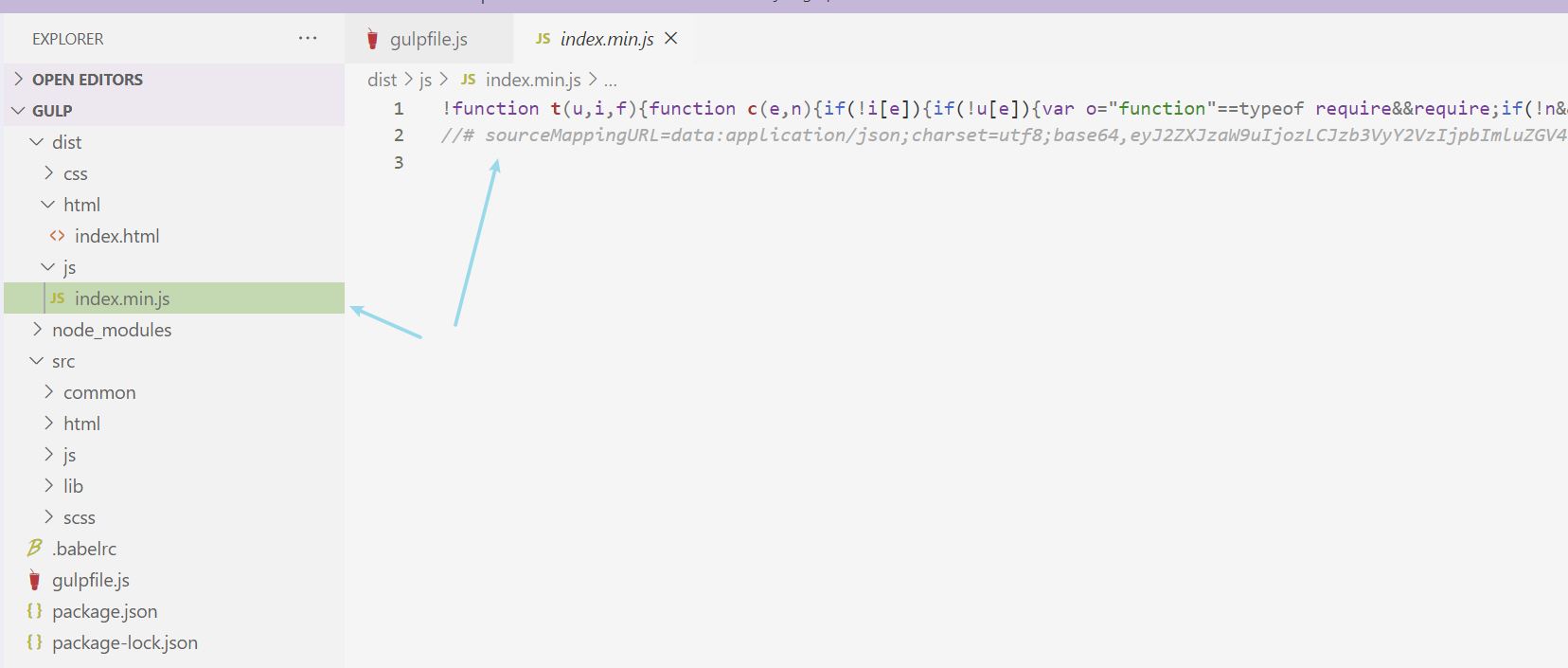
打开src的sourcemaps功能后,我们借助gulp-sourcemaps插件将生成的文件保存到 js-source文件夹中,接下来我们运行一下代码,你会发现dist目录下的js文件夹下多了一个 index.min.js.map 文件,这个就是 index.min.js 文件的映射文件。我们现在打开dist目录下的 index.min.js 文件看一下,发现它多了一行注释:
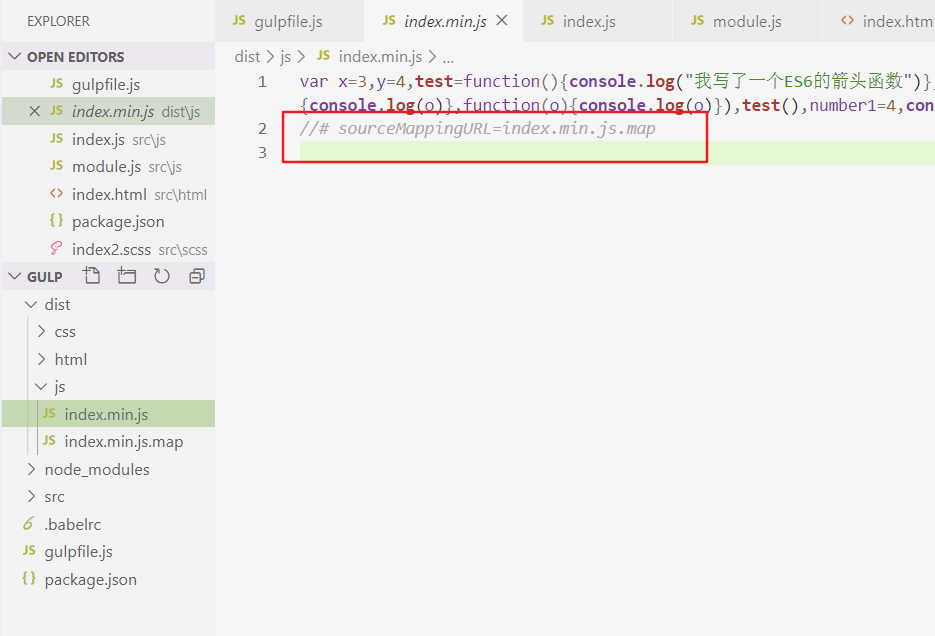
这一行注释其实就是告诉浏览器当前文件的对应的是哪一个映射文件,我们点开 index.min.js.map 看一下,里面是一些记录代码的数据,记录了 index.min.js 压缩文件在原来的未压缩时的文件里每行代码对应的位置。不信的话我们打开浏览器看一看:
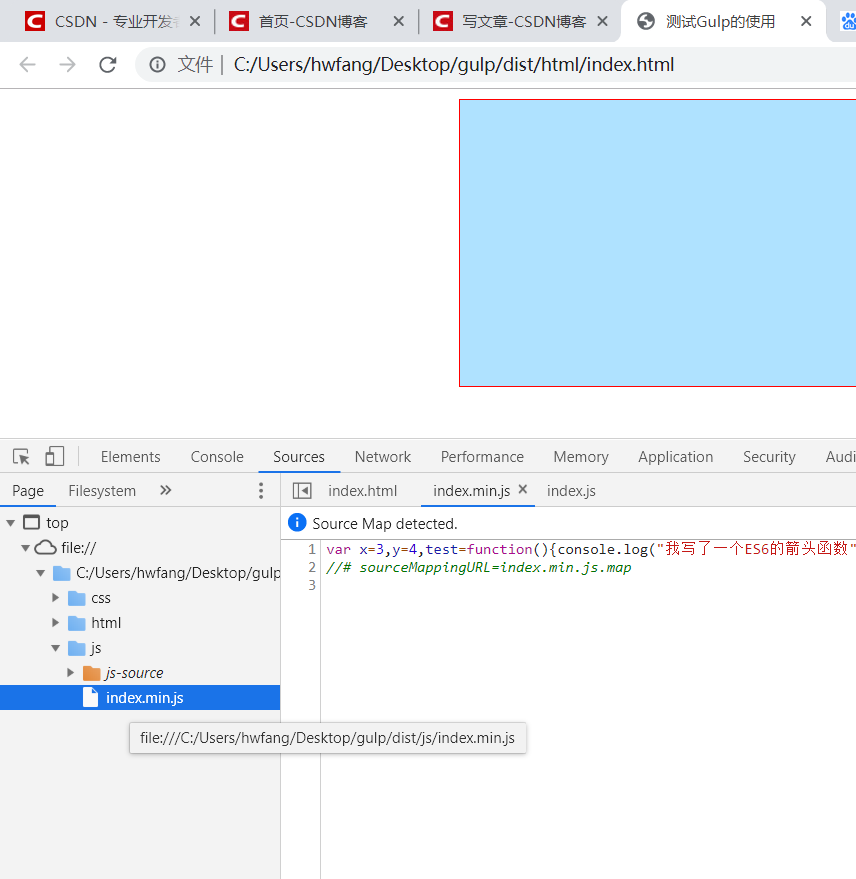
这里的index.min.js文件还是压缩版的,但打开同级的js-source,你会发现它保存着源文件的信息:
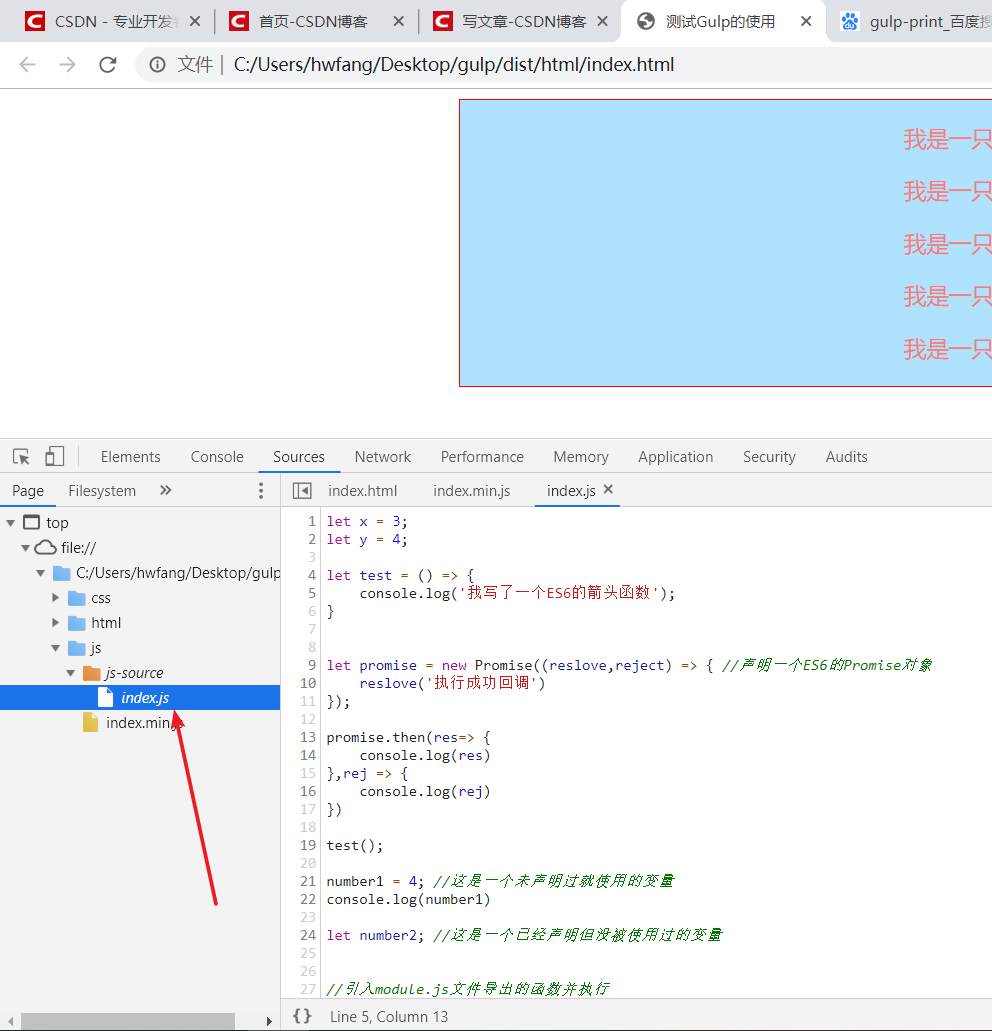
你现在到Console的地方去点击文件的位置,它也会直接给你跳到该index.js文件,并高亮对应的那行代码:
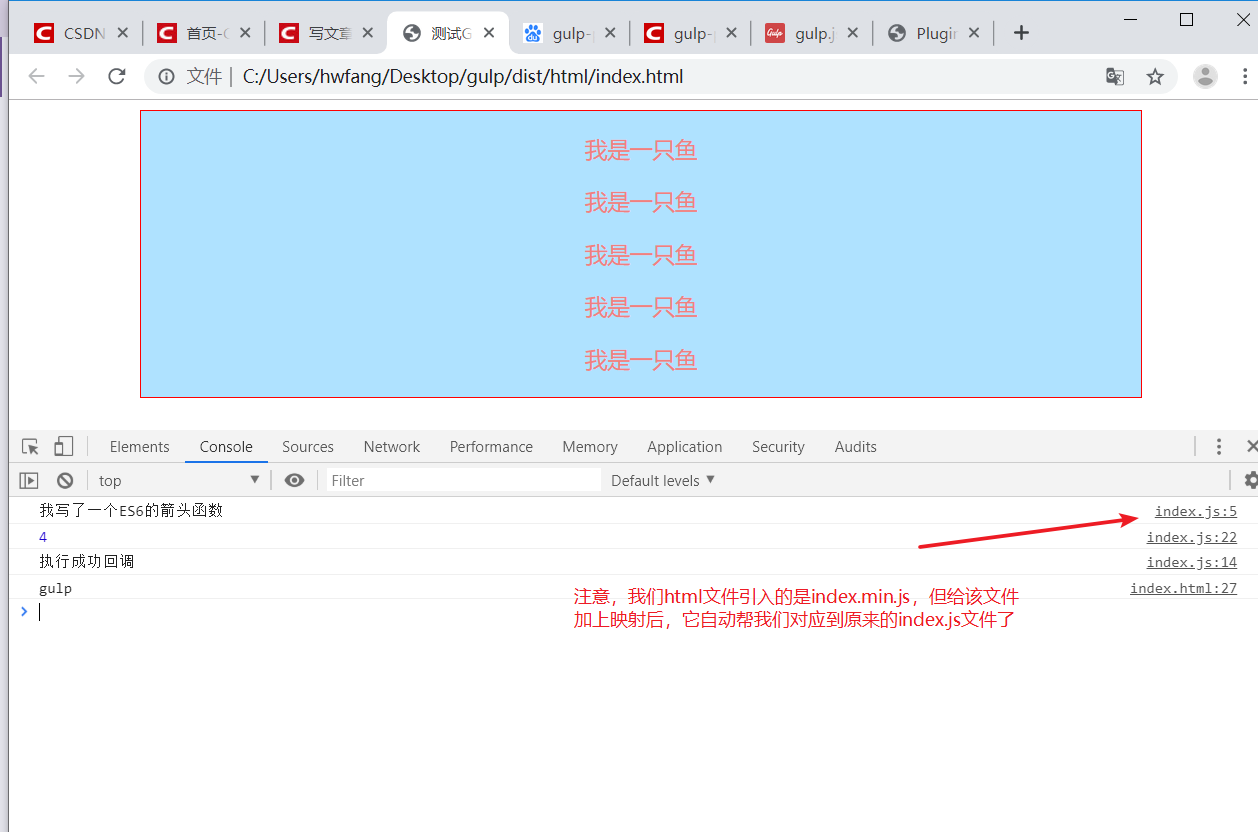
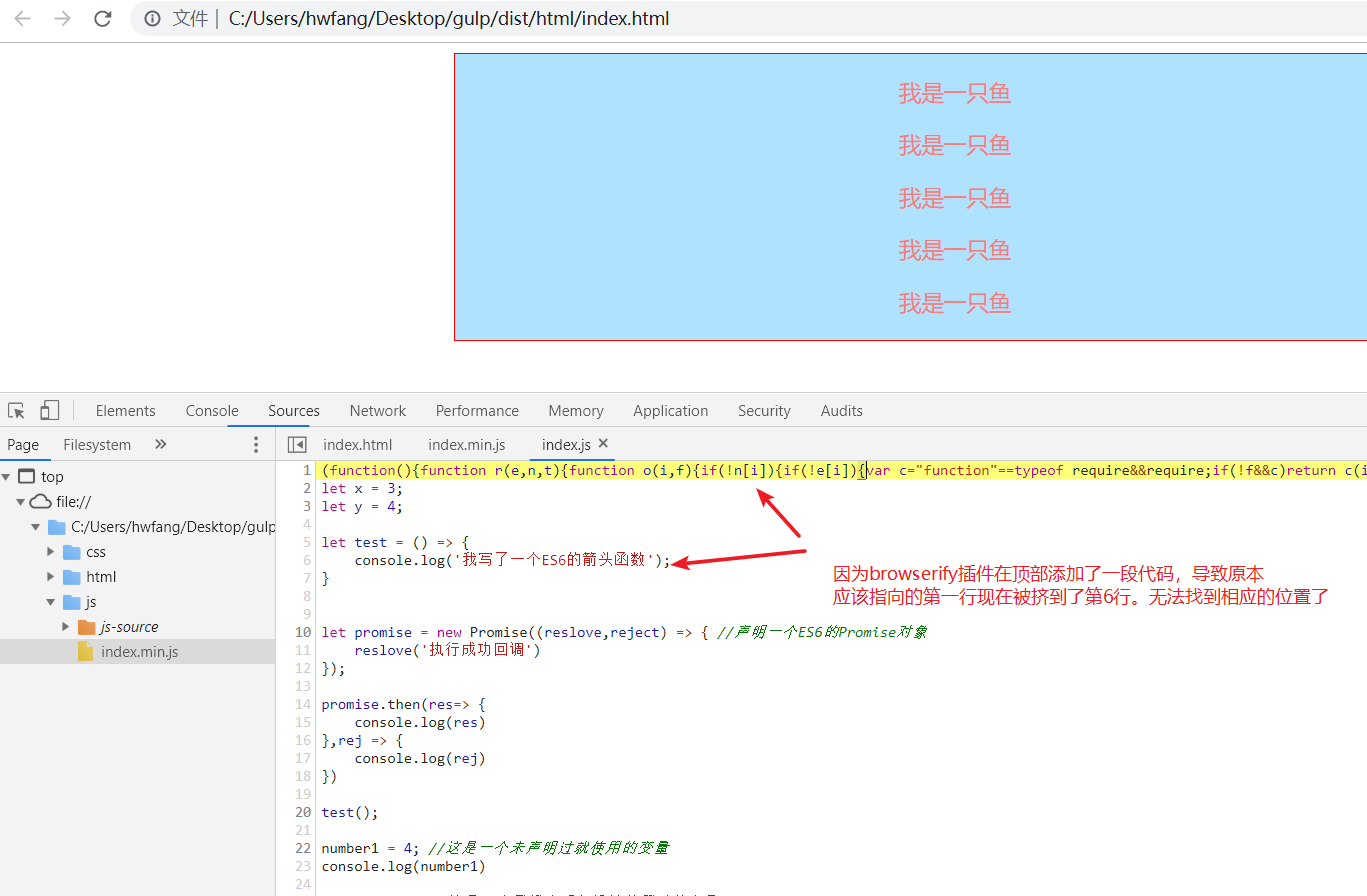
我们已经看到资源映射的功能了,那为什么我刚才要注释掉browserify插件呢,原因是它会在头部添加一段关于模块化的压缩代码,导致映射功能没法准确对应到它原本的位置。我们现在不使用 browserify 插件了,这个插件其实已经很旧了,而且用起来又非常麻烦。前面之所以介绍这个插件,是为了让大家能够了解一下gulp的虚拟文件对象以及虚拟文件对象content属性的Node Stream类型和缓冲类型。我们现在可以用一个叫 gulp-browserify的插件代替 browserify 插件,这个插件只需要一行代码就能替我们进行虚拟文件对象的包装和缓冲类型的转换:

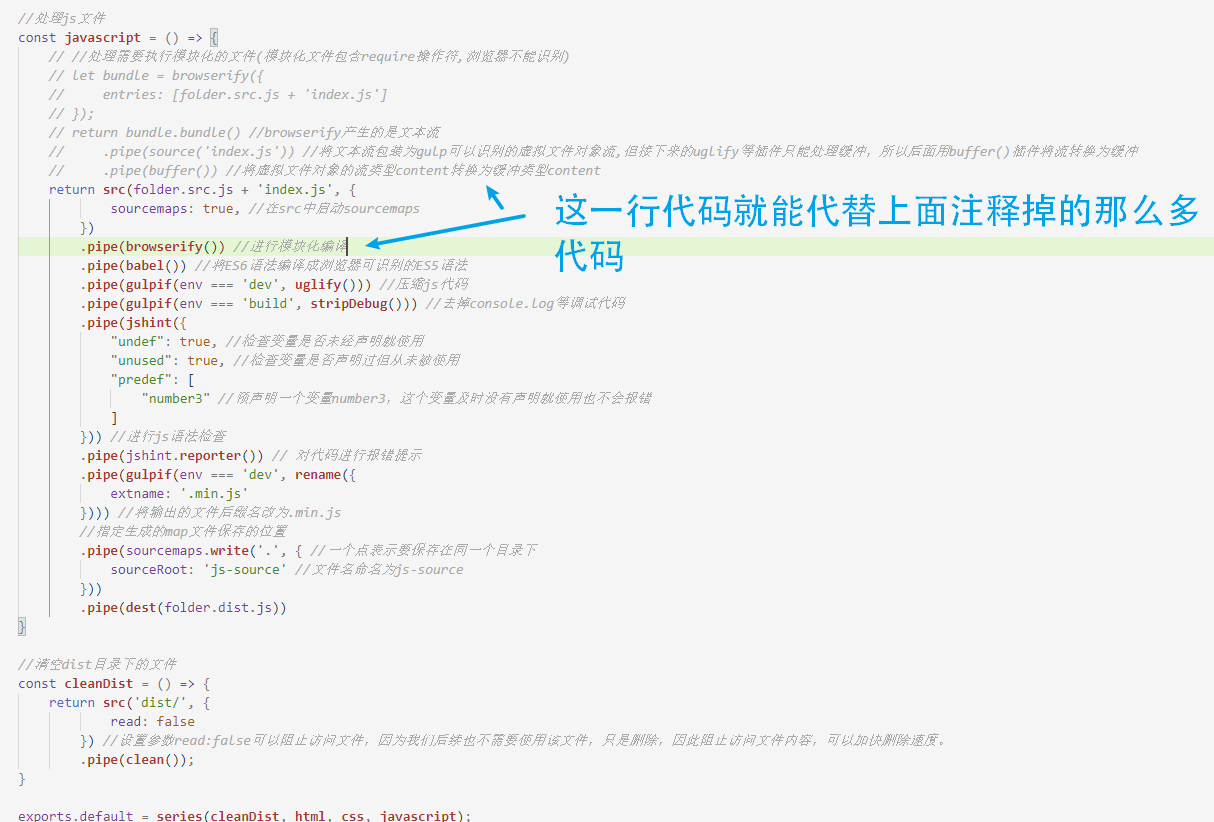
代码一下子简洁明了了许多,我们现在恢复了模块化功能,但对于sourcemap功能来说就没那么友好了,运行一下代码,像刚才一样去控制台Console的地方点击文件,你会发现现在已经没法完全正确的给你找出代码所对应的那一行了:
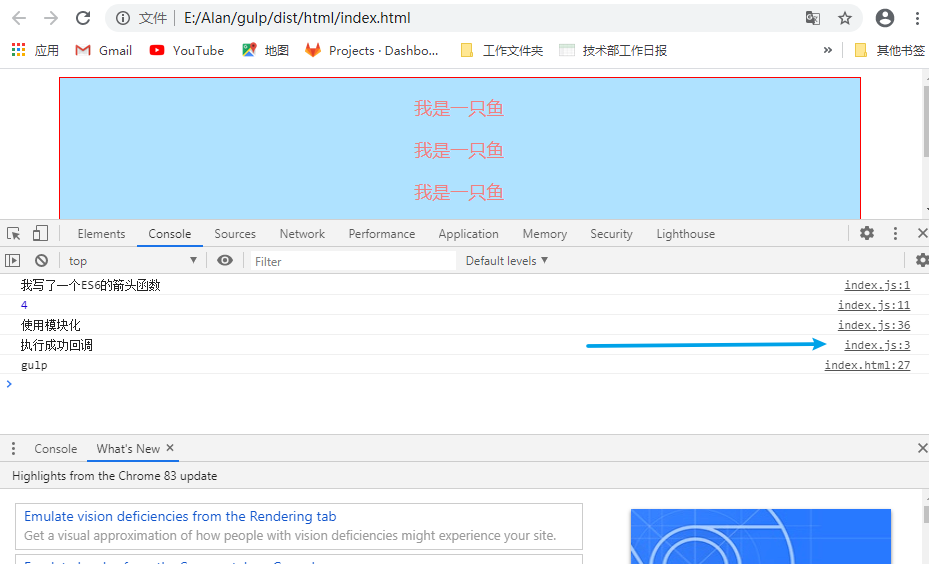
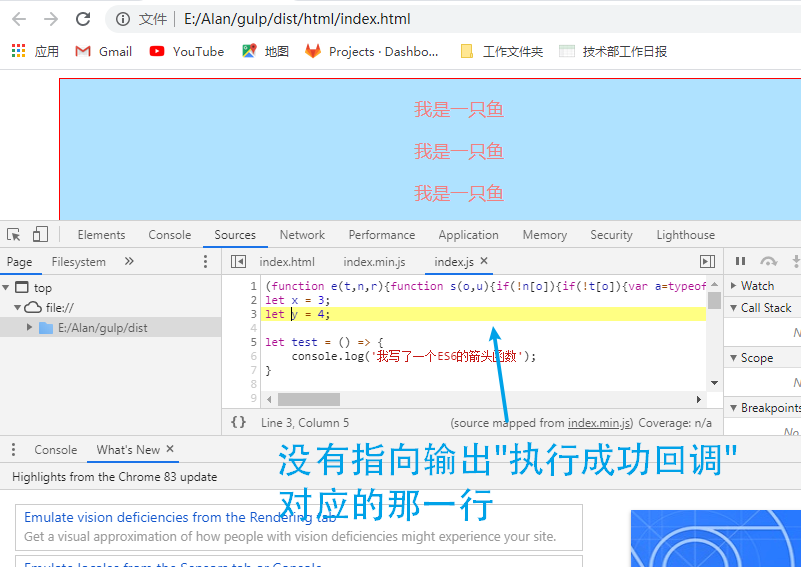
这模块化插件会在顶部添加一段模块化代码,打乱了原本记录好的顺序。但这个功能是否可修复本人目前并不清楚,如果有了解这个的朋友也欢迎留言解答。
我们也可以用 gulp-sourcemaps 插件的init() 方法去启动 sourcemap,还有,如果你不给sourcemaps.write() 方法指定保存路径,它默认会把映射的代码写到对应文件的底部:

其实平时我们一般把所有sourcemap文件集中放在同一个文件夹,在代码发布到线上的时候是不会跟着一起发布上去的。毕竟我们也不希望其它人轻易从浏览器中看懂我们的代码,所以我们一般会把sourcemap文件夹剪切保存出来,在需要进行线上调试的时候再把soucemap文件夹上传到服务器对应的位置进行调试(调试完记得删除)。
再介绍一个过滤路径插件 gulp-filter ,它可以让我们在某些流操作之前不对某个路径下的文件进行操作,然后等到操作结束后再把路径下的文件恢复到流中进行后面的操作。比如,对于引入的外部资源文件 jquery.min.js ,我们并不需要对它进行压缩或者语法检查(因为本来已经被压缩好了)。如果我们在不需要的情况下还对它进行操作,势必会浪费一些计算机的内存和Gulp的运行时间,那我们就可以把这些想要过滤的文件先暂时去掉,到最后再取出并输出到 dest 目录:


过滤掉没必要操作的第三方文件能极大的提高Gulp编译的速度。
接下来讲讲Gulp自带的文件监听功能 watch:
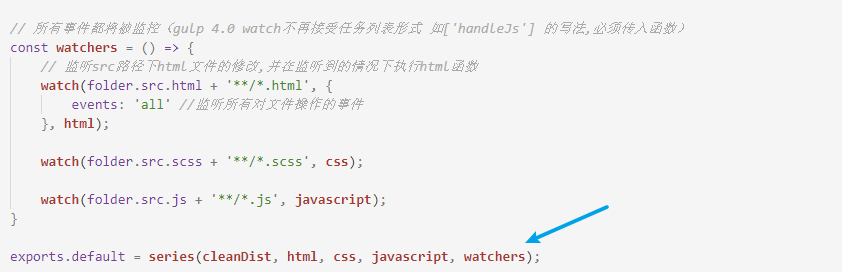
我们运行gulp,然后随便改动监听路径下的文件,你会发现你的操作会被监听到并且输出新的文件到dist目录下:
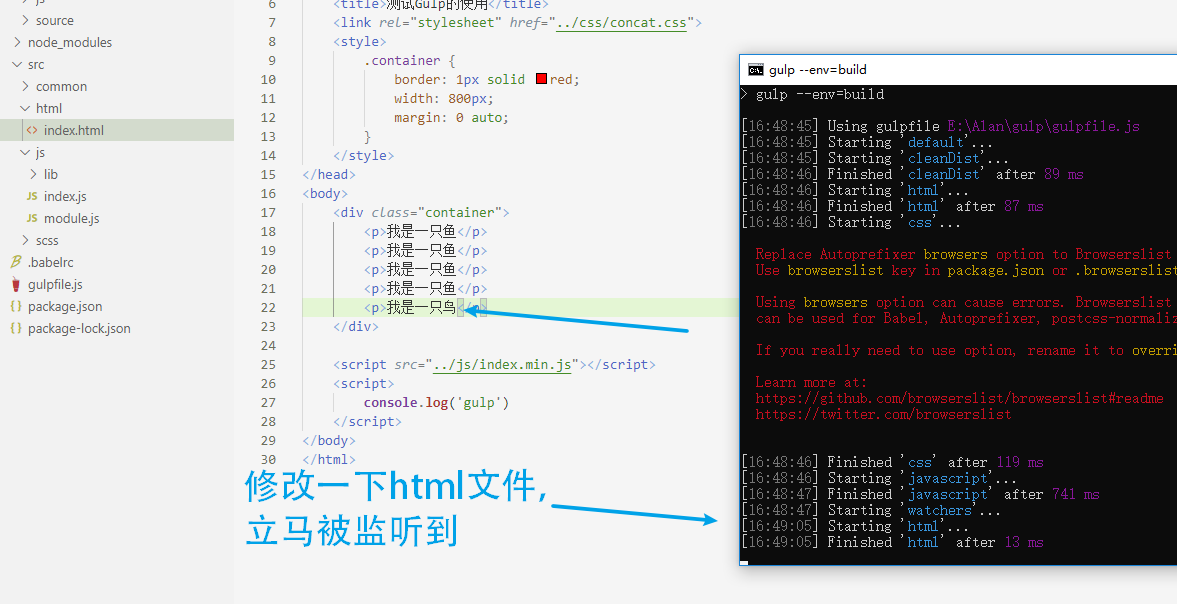
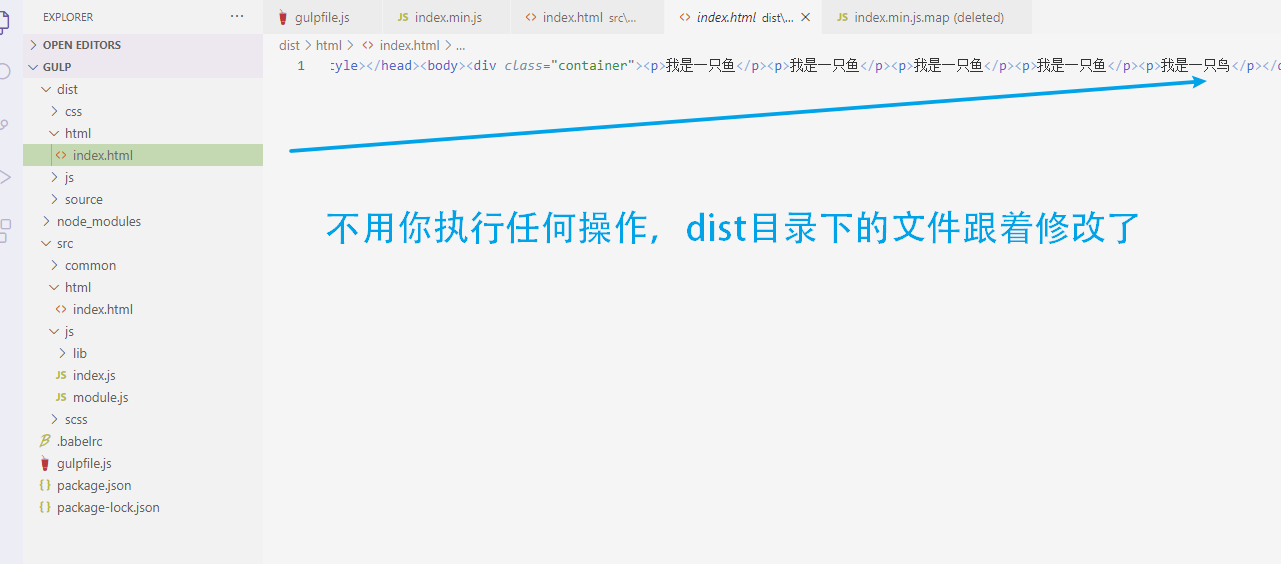
这个功能简直太方便了,有了监听功能,以后我们就不需要一直不停运行gulp指令了。
再介绍另一个功能,利用gulp插件开启本地服务器。可以看起本地服务器的gulp插件很多,有 gulp-connect、gulp-webserver和browser-sync,现在用得比较多的似乎是第三个,因为它的功能比较齐全,但各有各的好处。我们首先来看一下第一个插件怎么使用:


一般开启服务器的插件都配有浏览器自动刷新——也就是热更新功能。使用 gulp-connect 开启服务器,它的特点是热更新速度比较快。但是没法自动打开浏览器,得手动打开。我们现在来尝试运行一下上面的代码:
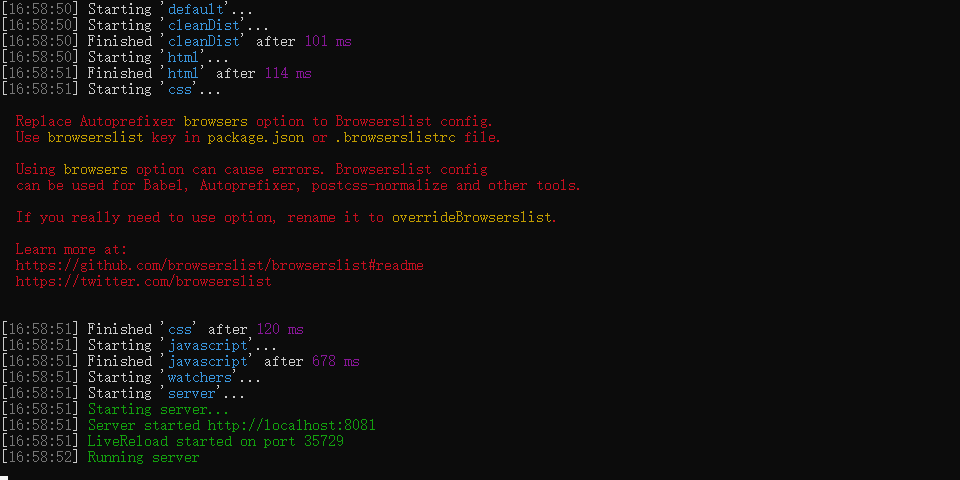
打开浏览器,我们输入其中的路径 http://localhost:8081 到浏览器,可以看到这样一个页面:
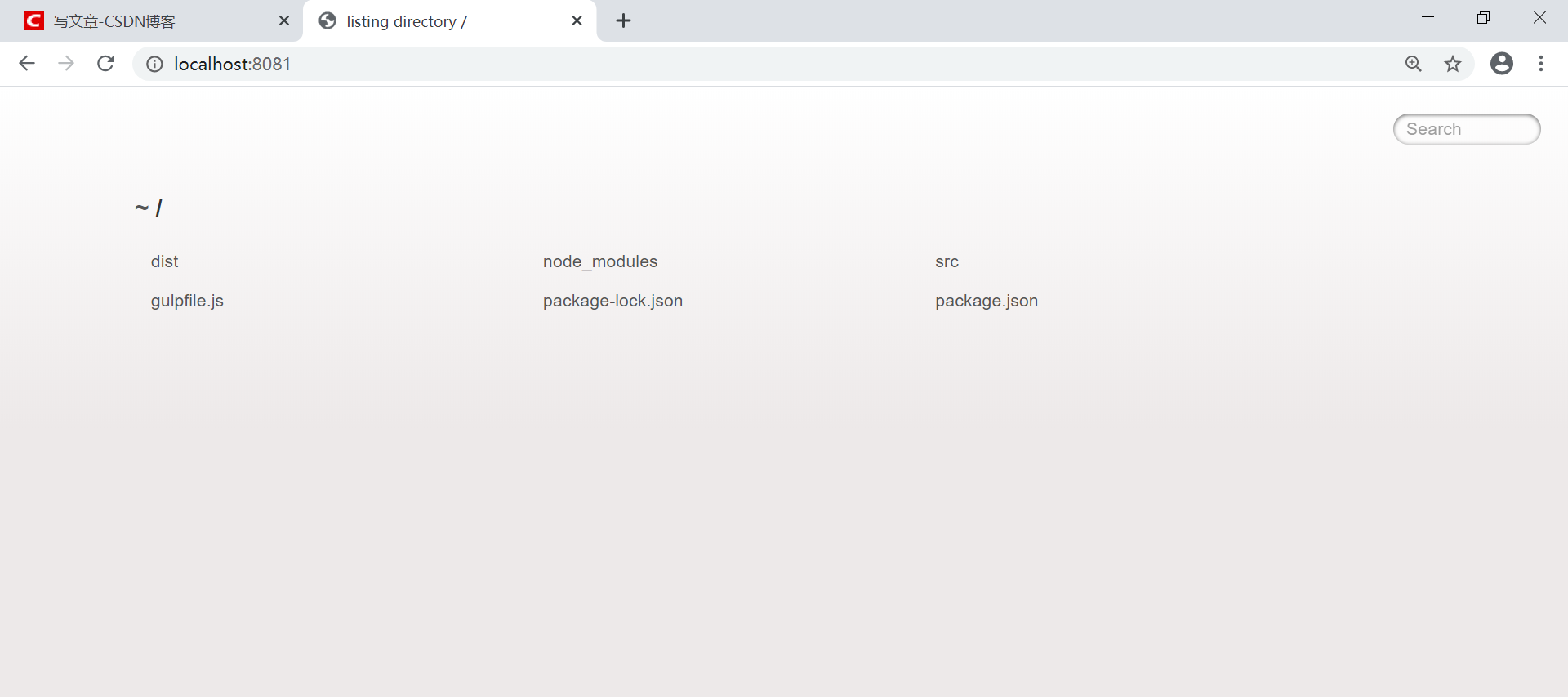
我们点进dist目录下的html文件,它会自动帮我们跳转到命名为index.html的页面:
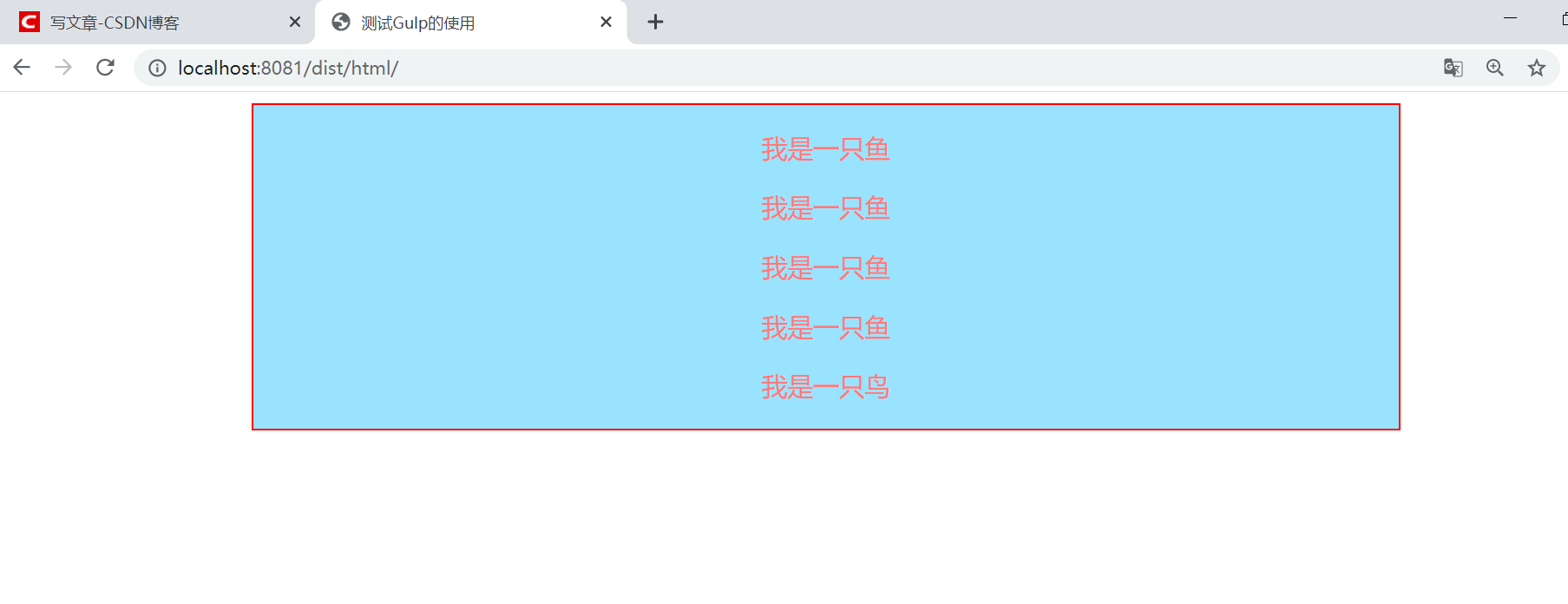
刚才在这个插件使用的配置中我已经启动了热更新功能,但你现在哪怕去修改src路径下的文件,浏览器也不会刷新。这就是这个插件第二个缺点,它需要我们在函数中写上一段代码才能实现热更新功能:
加上这句话后,我们按 Ctrl + c 结束并重启 gulp,然后现在去修改src目录下的html文件,你就会发现浏览器自己刷新了。所以我们要给每个函数都加上这段代码。

介绍第二个开启服务器的方式,使用gulp-webserver,像下面这样配置文件,然后运行:


运行gulp,你会发现页面报错:
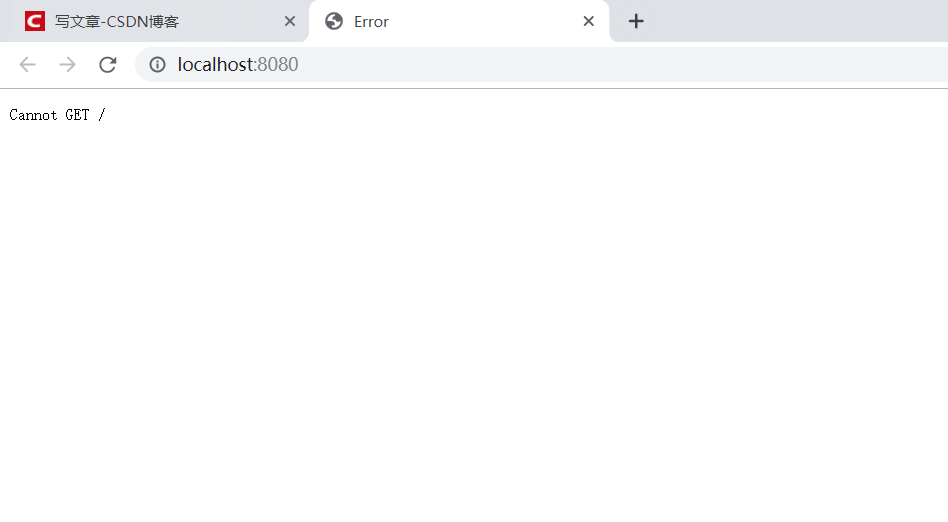
因为我们src路径设为根路径,而这个插件默认会查找我们设置的src路径下的index.html文件,找不到就报错。这个问题我们可以自己给路径补上dist/html,它就会去找html文件夹下的index.html文件:
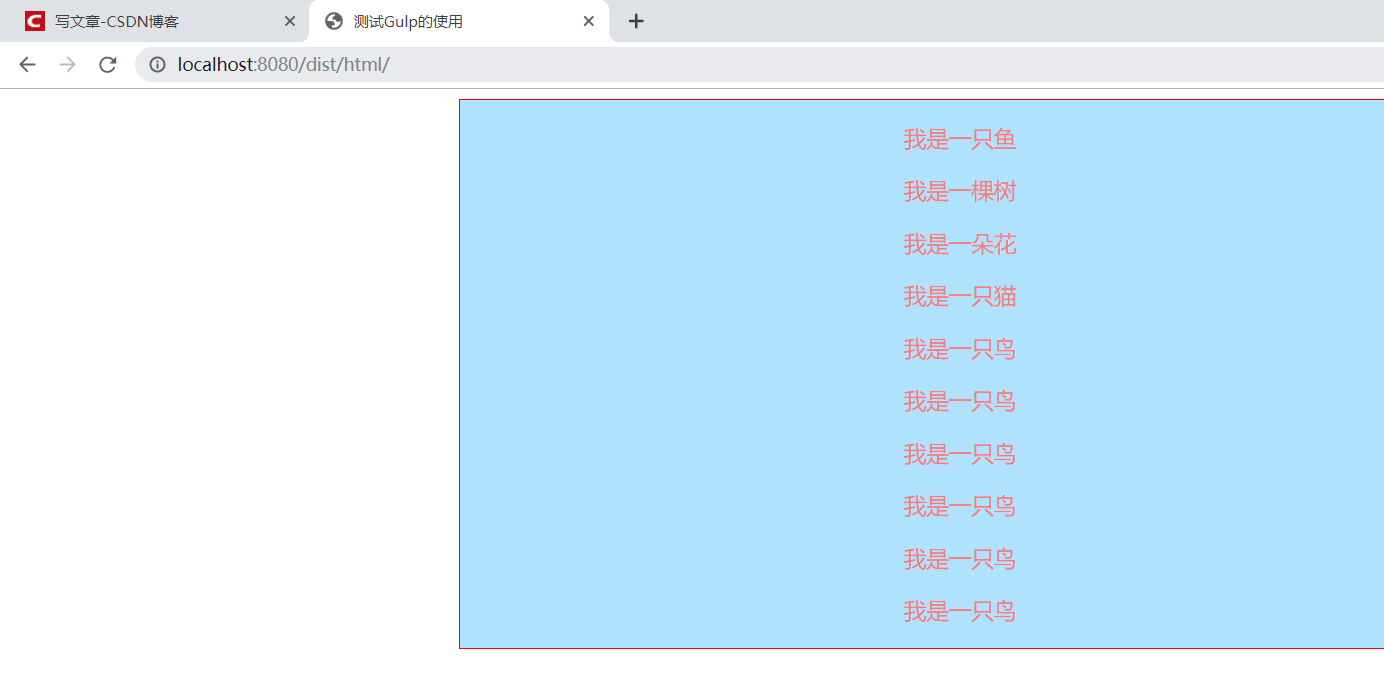
虽然这样正常显示了,但每次要去补充路径也很麻烦。我们不用这个插件,试试第三个插件browser-sync:

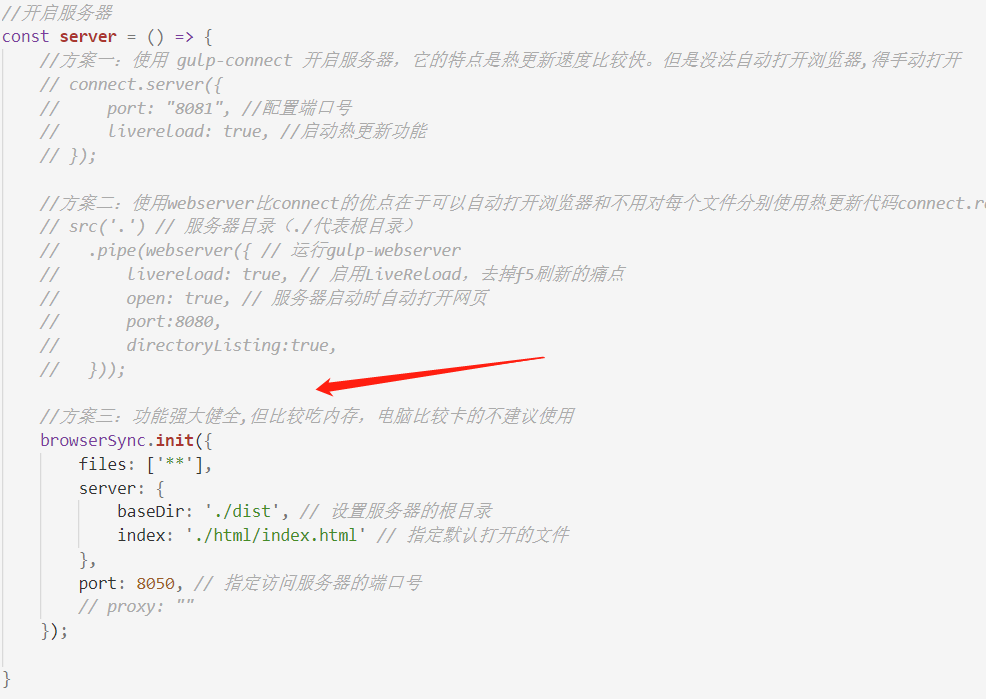
这个插件就比较方便了,不仅能帮我们自动打开浏览器,也能指定要打开的页面路径,我们只要运行gulp它就会帮我们直接打开我们想操作的页面。它也默认支持热更新功能,唯一的缺点就是比较吃电脑内存,电脑不行的人使用这个插件,热更新可能会等很久。所以我在这里还是推荐使用 gulp-connect 这个插件,虽然要手动打开页面,热更新功能实现起来也比较麻烦,但是速度却很快。
最后简单演示一下插件 stream-combiner2 的用法。stream-combiner2 插件可以帮助我们把不同函数里相同的功能操作一次性写完,然后需要用到的时候直接调用,减少代码量。这里直接上代码:
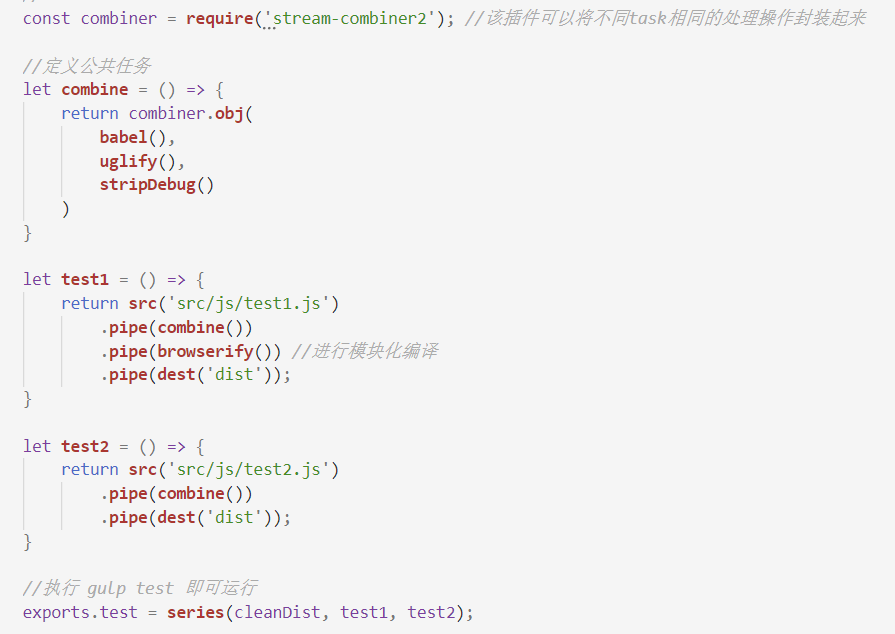
自己新建两个js文件进行测试,运行过后你会发现输出的 test1.js 和 test2.js 都进行了babel编译、压缩和去除调试代码,但只有test1.js 进行了模块化编译。
处理图片文件
突然想起来忘记写图片压缩任务了,直接上代码。这里顺便介绍一下 Gulp 自带的 lastRun 方法,它会返回当前函数上次成功运行时的时间戳。和 src 方法的 since 配置搭配使用,在下次运行的时候它会进行对比跳过自上次成功完成任务以来没有更改的文件,使增量构建的速度加快。压缩图片我用的是 gulp-imagemin 插件,写法依然比较简单,直接上代码:




运行过后你会发现,原本313kb的图片被压缩成了290kb。
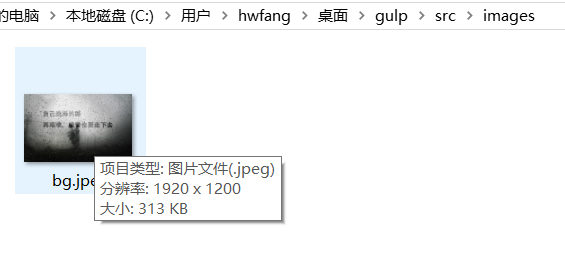
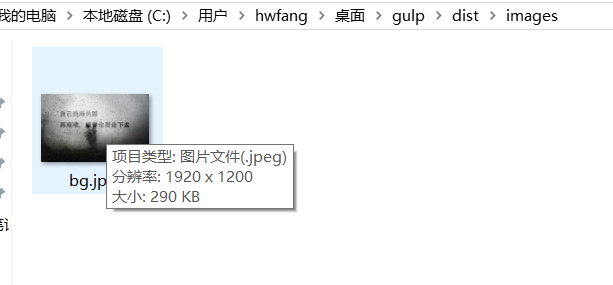
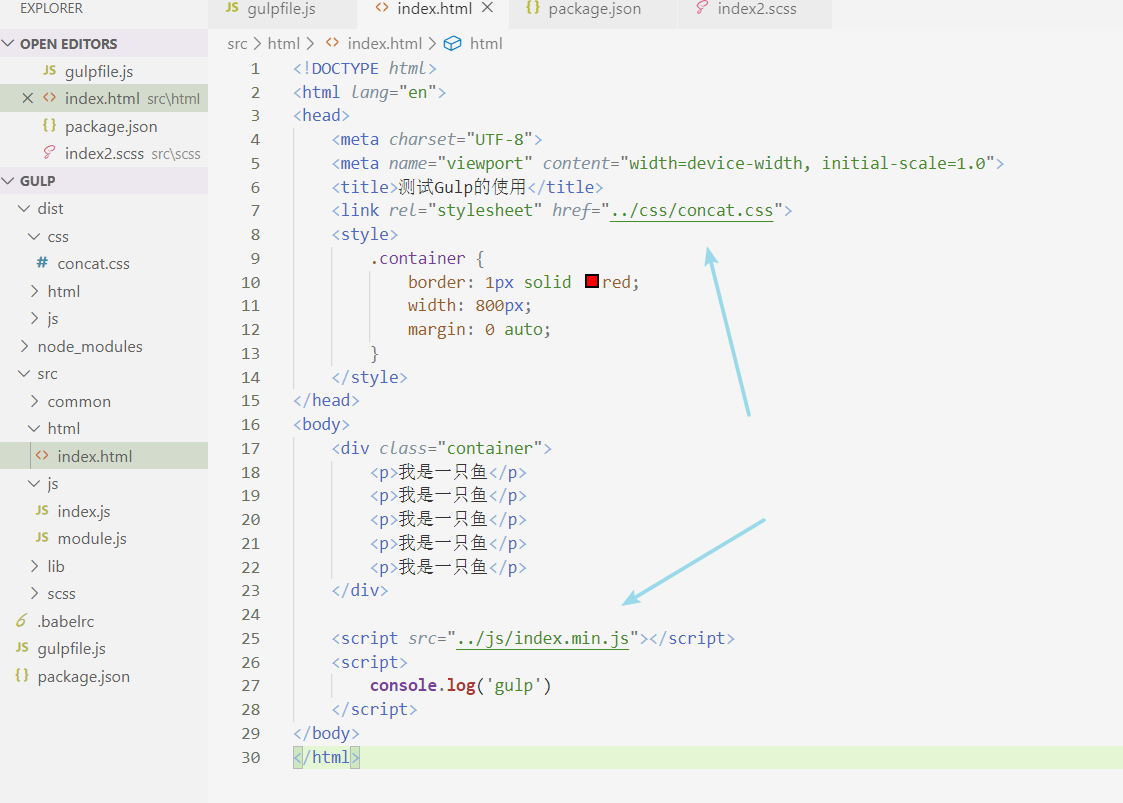
最后再补充一下 html 引入公共头部和尾部的方法,我们需要依赖一个叫 gulp-file-include 的插件。 我们先把 src 目录下的 index.html 文件的公共头部抽离出来,放入 header.html文件中:
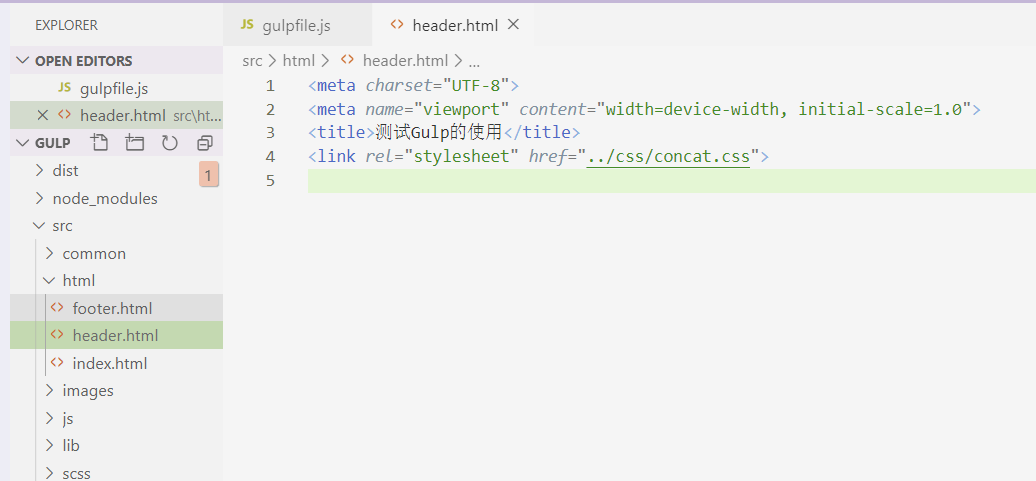
在 gulpfile.js 文件下进行如下修改:

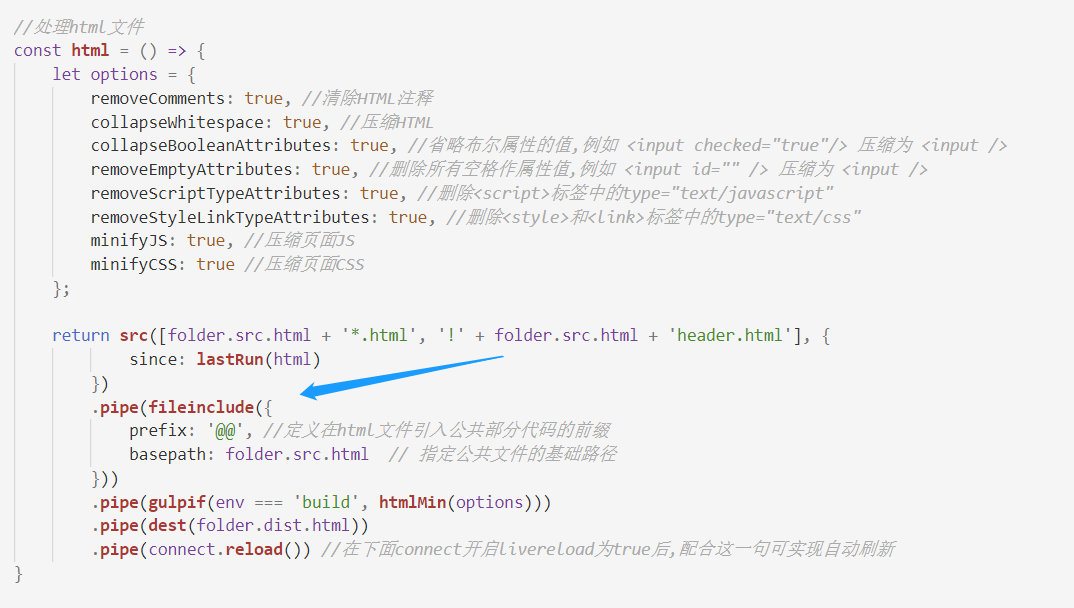
然后在我们刚才的 index.html 文件这样去引入:
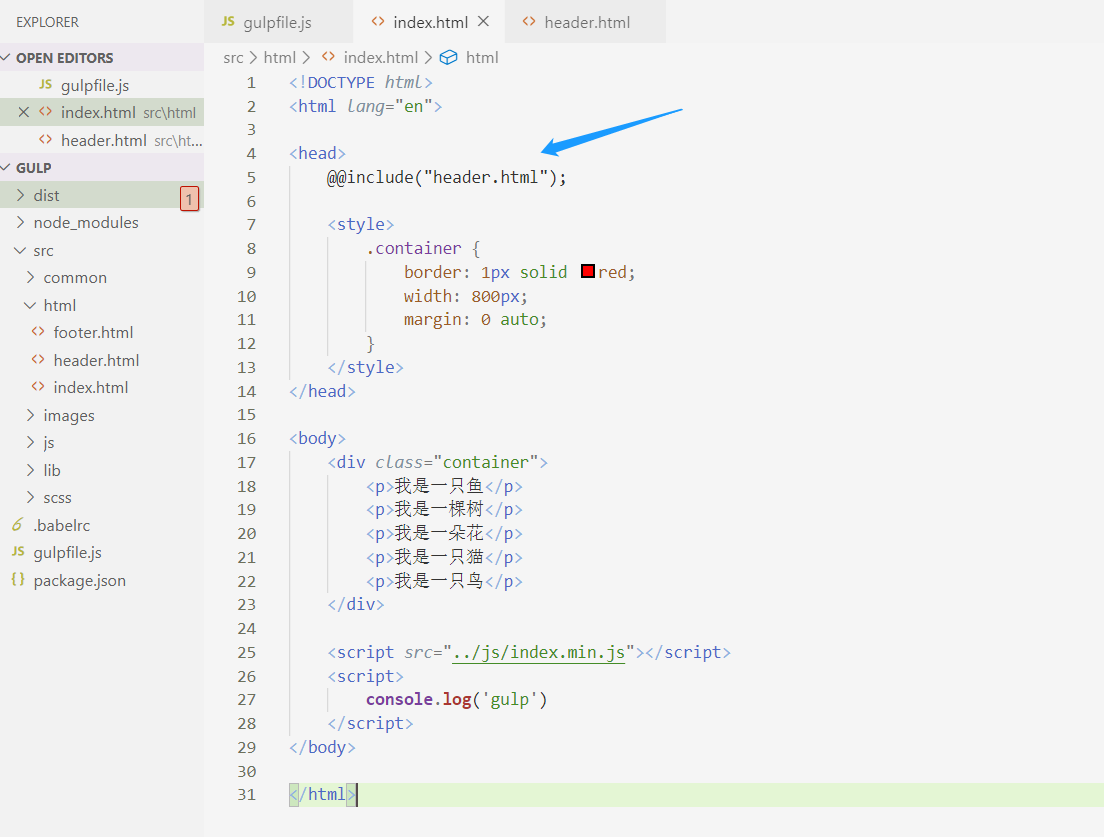
注意,这里引入路径取决于你 gulpfile.js 定义的基础路径, 如果你 gulpfile 的基础路径定义为 src ,那么你这里就要写成 @@include("html/header.html") 。运行一下 gulp,你会发现编译出来的 index.html 文件就包含了刚才的公共头部了:
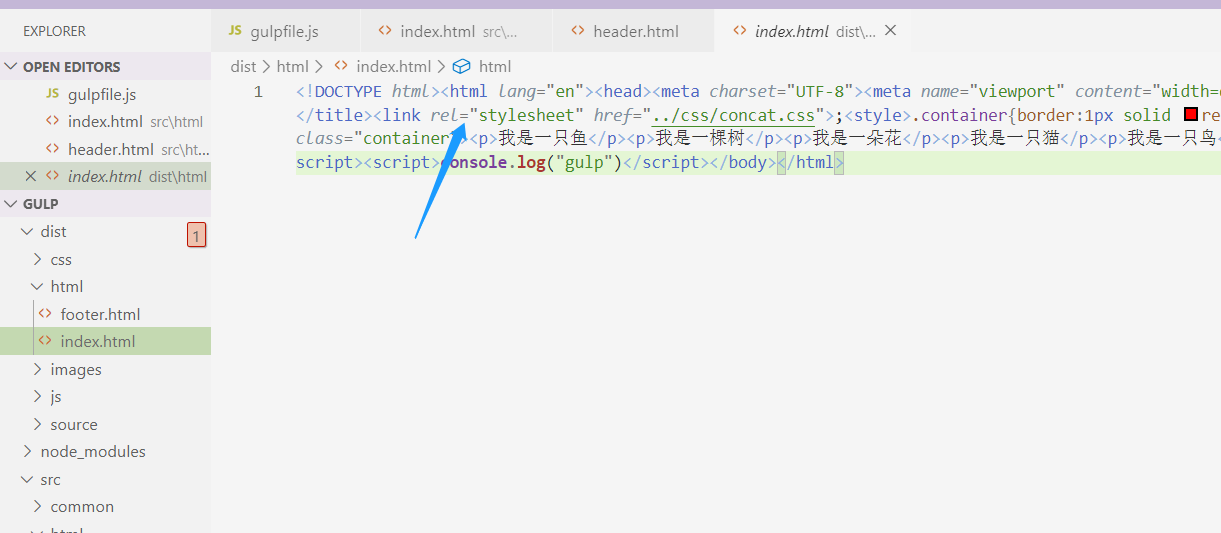
公共尾部引入的方法也是一样,至于更详细的使用方式,这里就不展开了,需要的朋友可以阅读 gulp-file-include插件的官方教程。
写到这里,我已经把Gulp在日常工作中的常用工具以及需要注意的细节问题大致介绍完了,我会将代码上传到 github 上,有需要的朋友可以自行下载。如果在配置过程中遇到什么问题,也欢迎随时来向我咨询。如果想更多的了解Gulp自动化构建工具的细节,在这里就安利一本名叫《Web前端自动化构建:Gulp、Bower和Yeoman开发指南》的书吧,感兴趣的朋友可以去阅读一下。
最后
以上就是标致烧鹅最近收集整理的关于前端自动化构建工具:用Gulp4.0搭建一个基本的前端开发环境的全部内容,更多相关前端自动化构建工具:用Gulp4.0搭建一个基本内容请搜索靠谱客的其他文章。








发表评论 取消回复