knitr::opts_chunk$set(echo = TRUE)折线图通常用来对两个连续变量之间的相互依存关系进行可视化,其中,x轴对应于自变量,y轴对应于因变量。一般来说,折线图的x轴对应的是时间变量,但也可以用来表示诸如实验对象的药剂量等连续型变量。当然,跟条形图类似,折线图的用法也有例外。有时候,折线图的x轴也可以与离散型变量相对应,但此时只适用于变量为有序离散型变量(比如“小”、“中”、“大”)的情形,而不是用于无序变量(比如“牛”、“鹅”、“猪”等)。
4.1 绘制简单折线图
运行ggplot()和geom_line()函数,并分别指定一个变量映射给x和y。
library(ggplot2)
ggplot(BOD,aes(x=Time, y=demand)) + geom_line()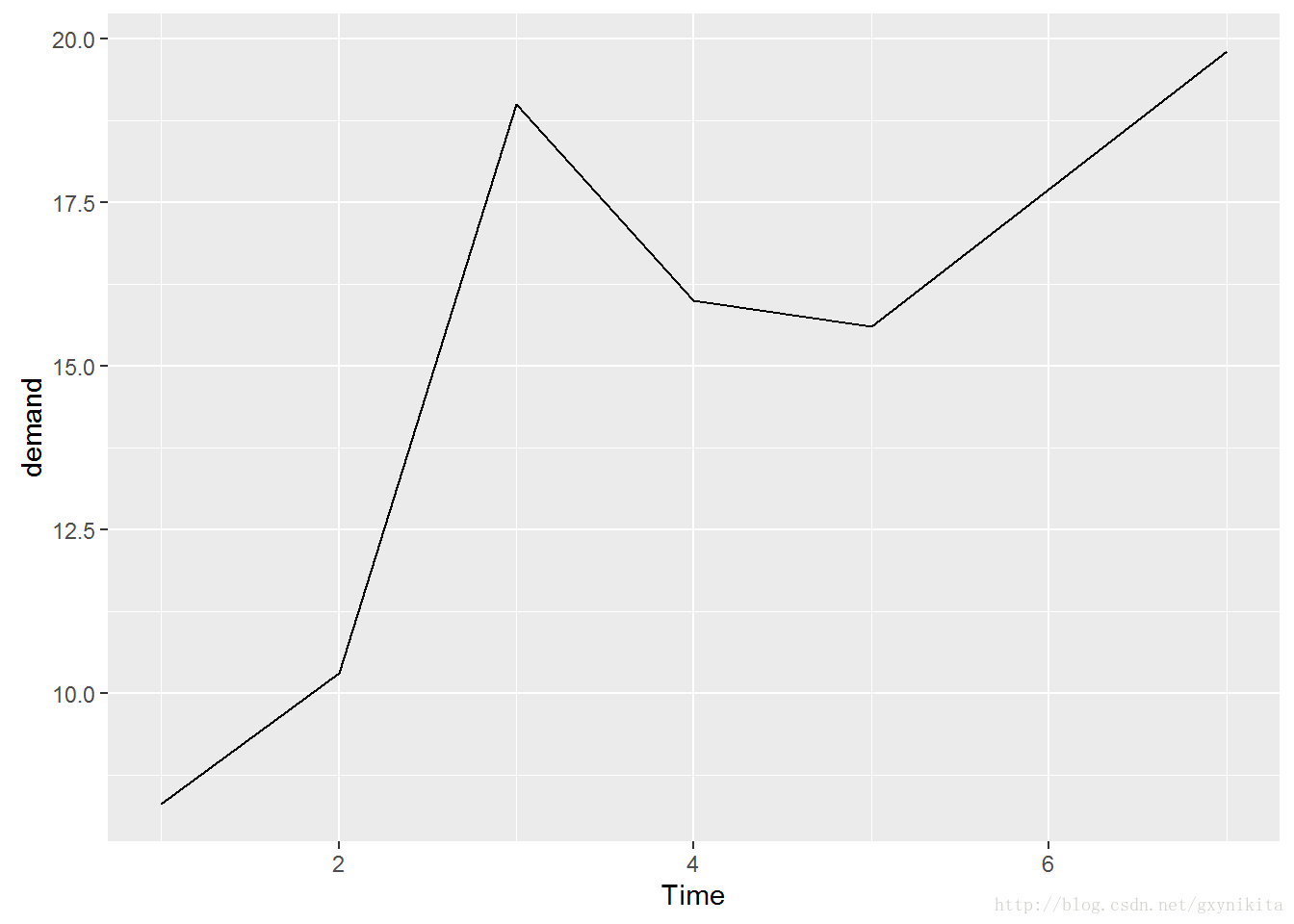
对于这个简单的数据框,x对应的变量Time和y对应的变量demand分别对应于数据框的两列数据:
BOD## Time demand
## 1 1 8.3
## 2 2 10.3
## 3 3 19.0
## 4 4 16.0
## 5 5 15.6
## 6 7 19.8折线图的x轴即可以对应于离散型(分类)变量,也可以对应于连续型(数值型)变量。
本例中Time变量为连续型变量,但可以借助factor()函数将其转化为因子型变量,然后,将其当做分类变量来处理。
当x对应于因子型变量时,必须使用命令aes(group=1)以确保ggplot()知道这些数据点属于同一个分组,从而应该用一条折线连在一起。
BOD1 <- BOD #将数据复制一份
BOD1$Time <- factor(BOD1$Time)
ggplot(BOD1,aes(x=Time, y=demand, group=1)) + geom_line()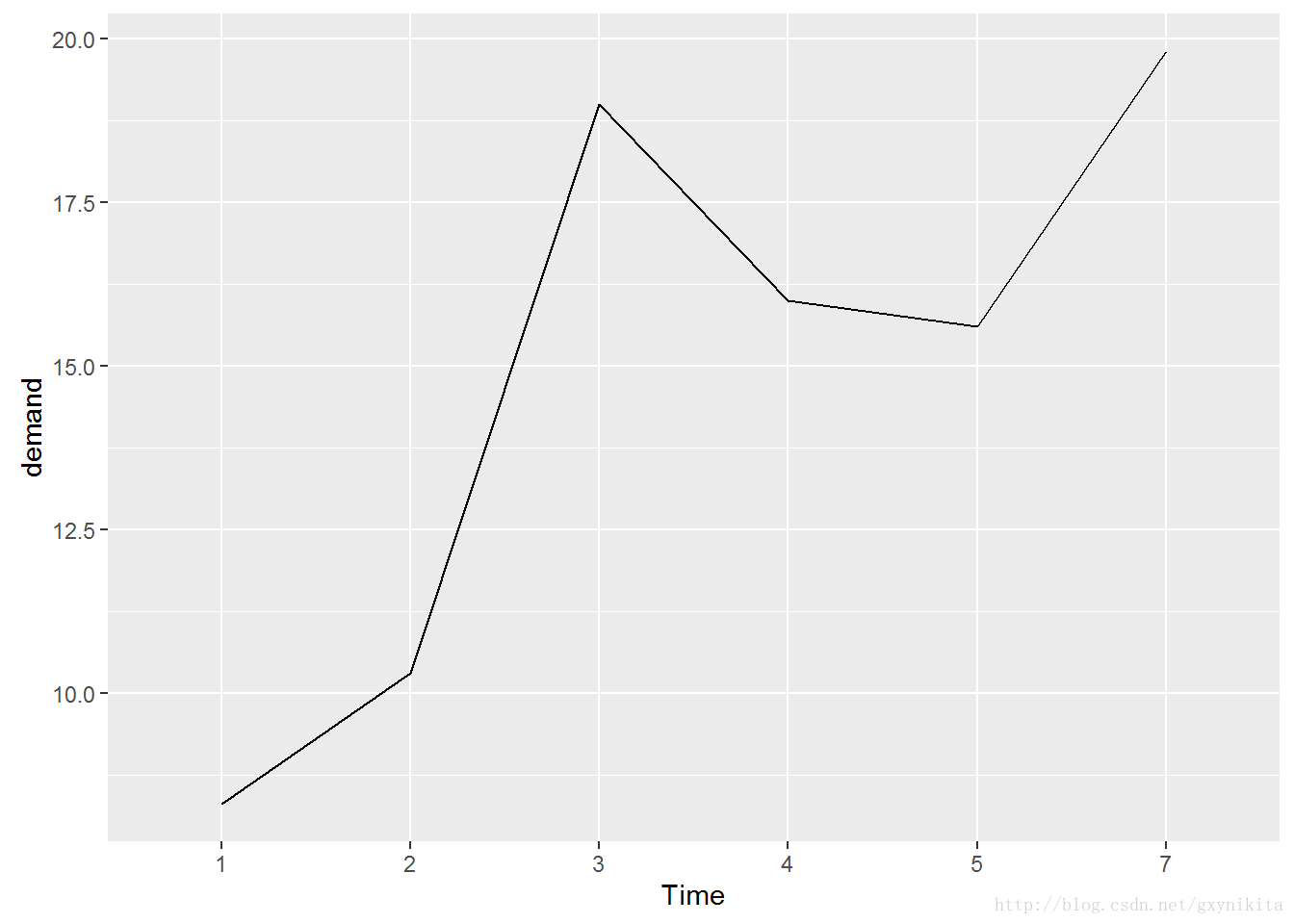
数据集BOD中没有对应于Time=6的数据点,因此当Time被转化为因子型变量时,它并没有6这个水平。因子型变量对应于分类值,这里的6只是其中一个可能的取值。因为数据集中恰好没有对应于该水平的数据点,所以,x轴上没有绘制相应的取值。默认情况下,ggplot2绘制的折线图的y轴范围刚好能容纳数据集中的y值。对于某些数据而言,将y轴的起点设定为0点会更合适。可以运行ylim()设定y轴范围或者运行含一个参数的expand_limit()扩展y轴的范围。
下面的命令将y轴的范围设定为0到BOD中demand变量的最大值。
#运行下面的命令得到的结果是相同的
ggplot(BOD, aes(x=Time, y=demand)) + geom_line() + ylim(0, max(BOD$demand))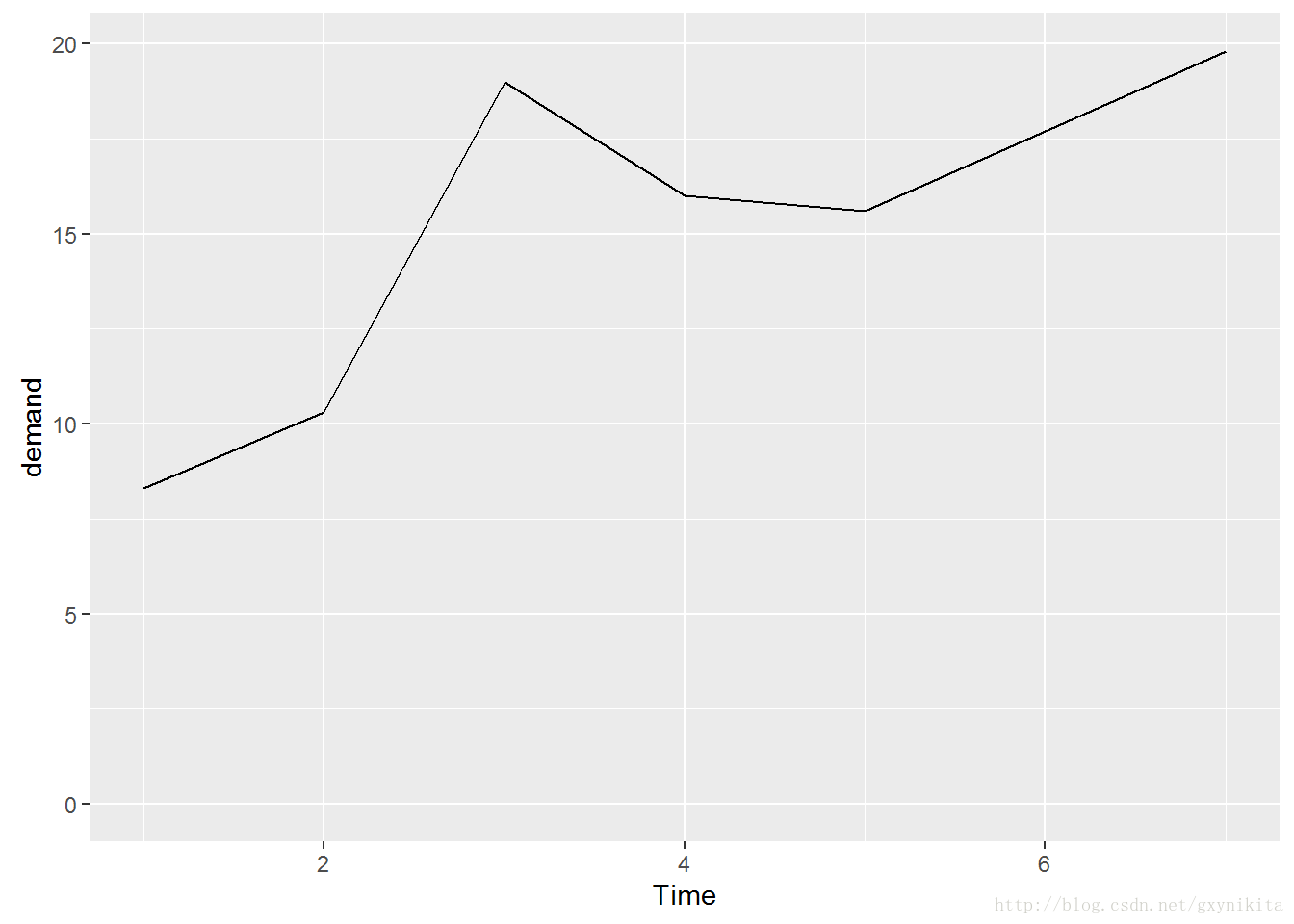
ggplot(BOD, aes(x=Time, y=demand)) + geom_line() + expand_limits(y=0)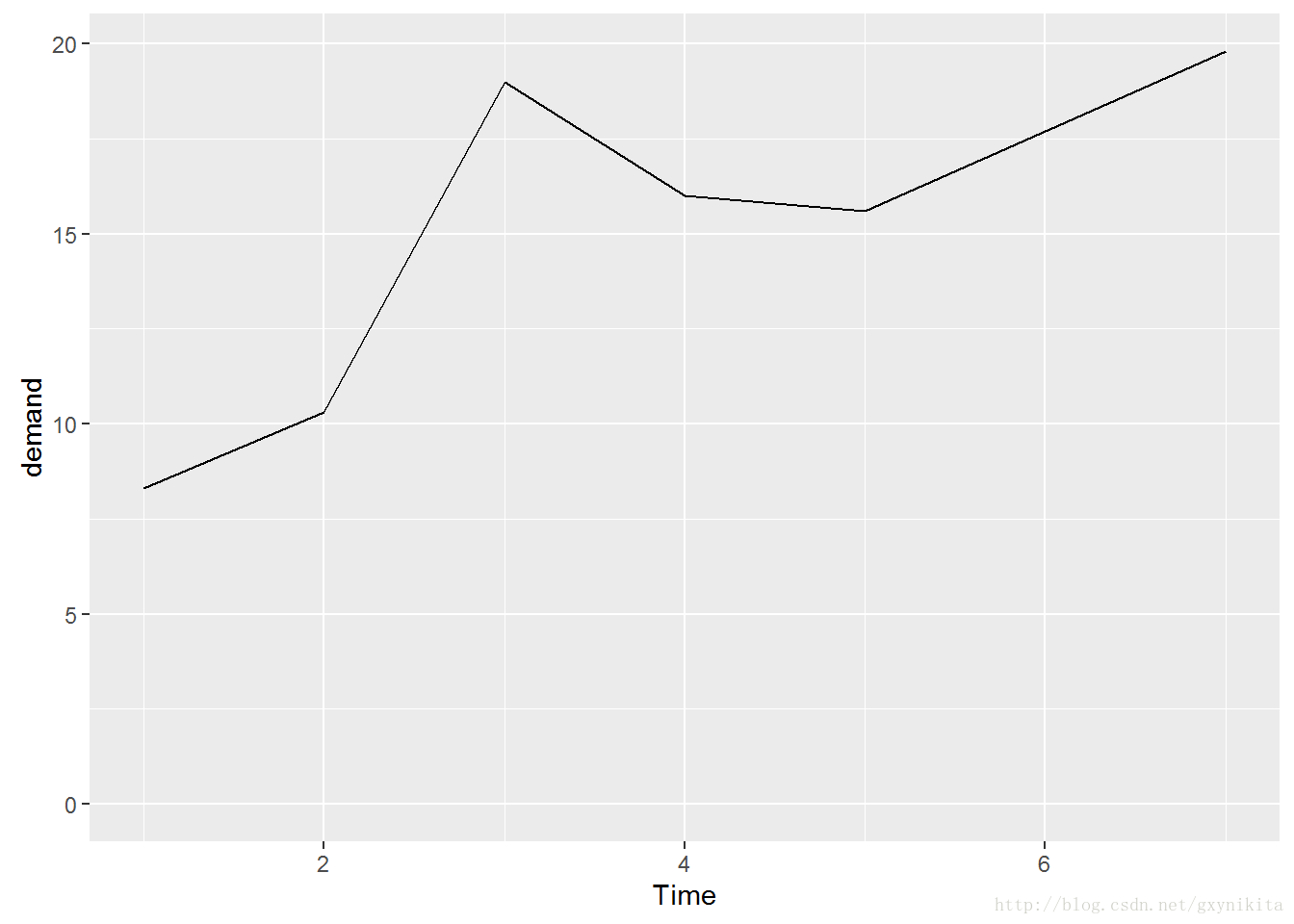
ggplot(BOD, aes(x=Time, y=demand)) + geom_line() + geom_point()有时候,在折线图上添加数据标记很有用。当数据点的密度较低或者数据采集频率不规则时尤其游泳。
比如,BOD数据集中没有与Time=6相对应的输入,然而,这在单独的一张折线图看起来并不明显。
worldpop数据集对应的采集时间间隔不是常数。
时间距今较久远的数据采集频率比新近不久的数据采集频率低。
折线图中的数据标记表明了数据的采集时间。
ggplot(BOD, aes(x=Time, y=demand)) + geom_line() + geom_point()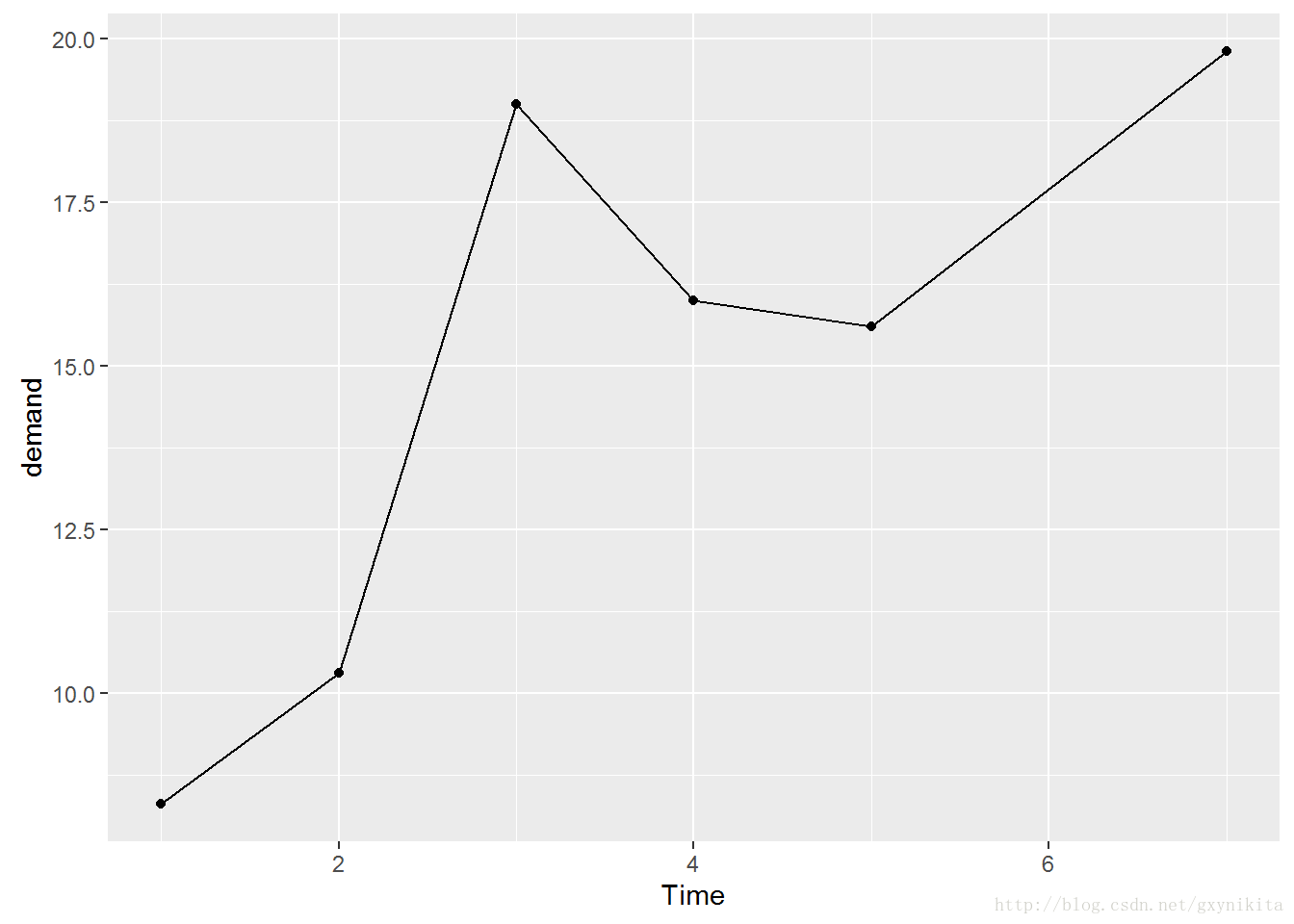
有时候,在折线图上添加数据标记很有用。当数据点的密度较低或者数据采集频率不规则时尤其游泳。
比如,BOD数据集中没有与Time=6相对应的输入,然而,这在单独的一张折线图看起来并不明显。
worldpop数据集对应的采集时间间隔不是常数。
时间距今较久远的数据采集频率比新近不久的数据采集频率低。
折线图中的数据标记表明了数据的采集时间。
library(gcookbook) #为了使用数据
ggplot(worldpop, aes(x=Year, y=Population)) + geom_line() + geom_point()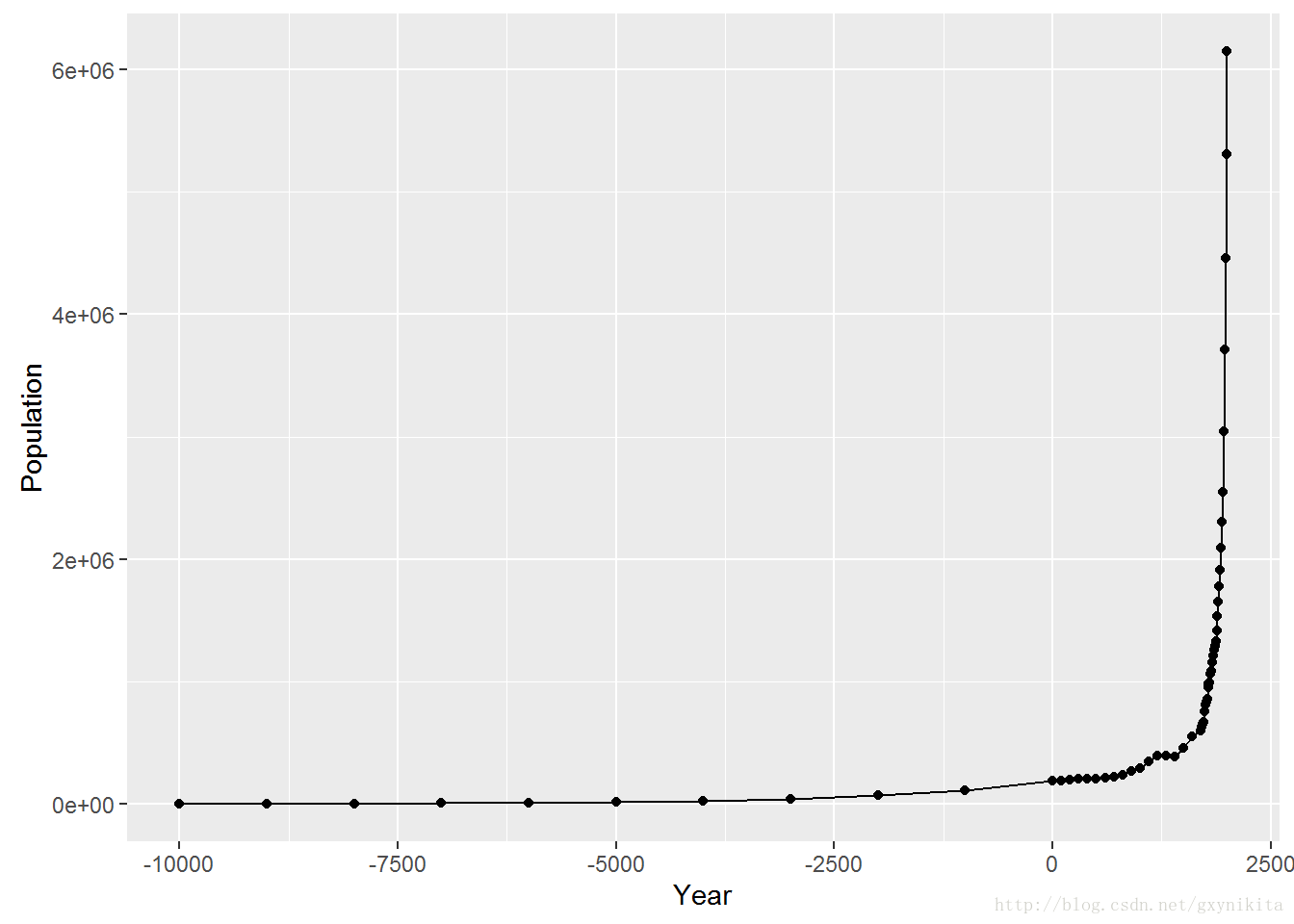
#当y轴取对数时也一样
ggplot(worldpop, aes(x=Year, y=Population)) + geom_line() + geom_point() + scale_y_log10()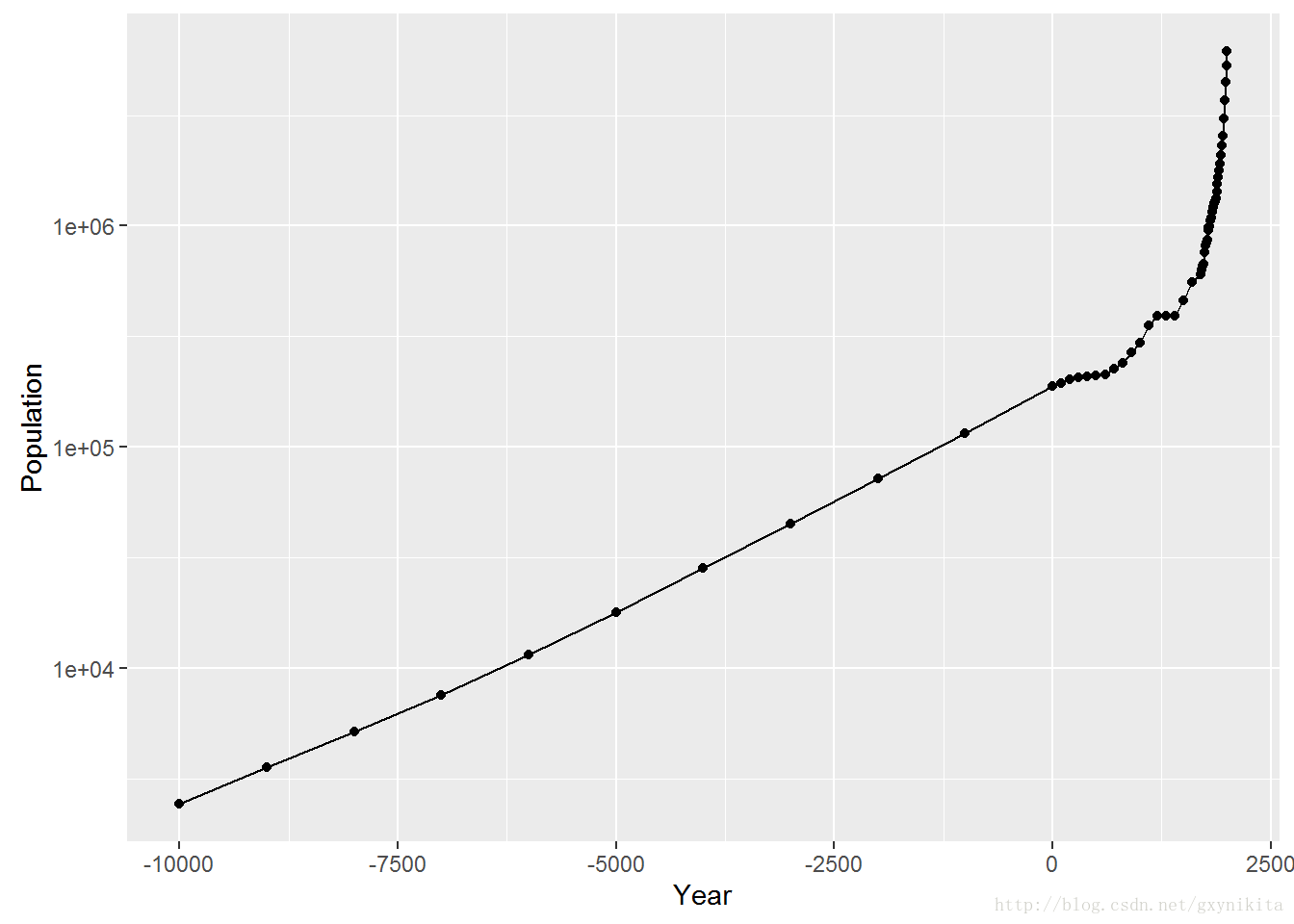
从对y轴取对数的折线图上可以看出:在过去数千年中人口增长率有所增加。公元元年之前的人口增长率接近常数,约每5000年增加10倍。从图中也可以看出,近年来的人口普查频率比以往更为频繁,数据也更为准确。
#载入plyr包,便于我们使用ddply()函数创建样本数据集
library(plyr)
#对ToothGroth数据集进行汇总
tg <- ddply(ToothGrowth, c("supp","dose"), summarise, length=mean(len))
#将supp映射给颜色(colour)
ggplot(tg, aes(x=dose, y=length, colour=supp)) + geom_line()
#将supp映射给线型(linetype)
ggplot(tg, aes(x=dose, y=length, linetype=supp)) + geom_line()tg数据集共有三列,其中一列是映射给颜色(colour)和线型(linetype)的supp变量:
#载入plyr包,便于我们使用ddply()函数创建样本数据集
library(plyr)
#对ToothGroth数据集进行汇总
tg <- ddply(ToothGrowth, c("supp","dose"), summarise, length=mean(len))
#将supp映射给颜色(colour)
ggplot(tg, aes(x=dose, y=length, colour=supp)) + geom_line()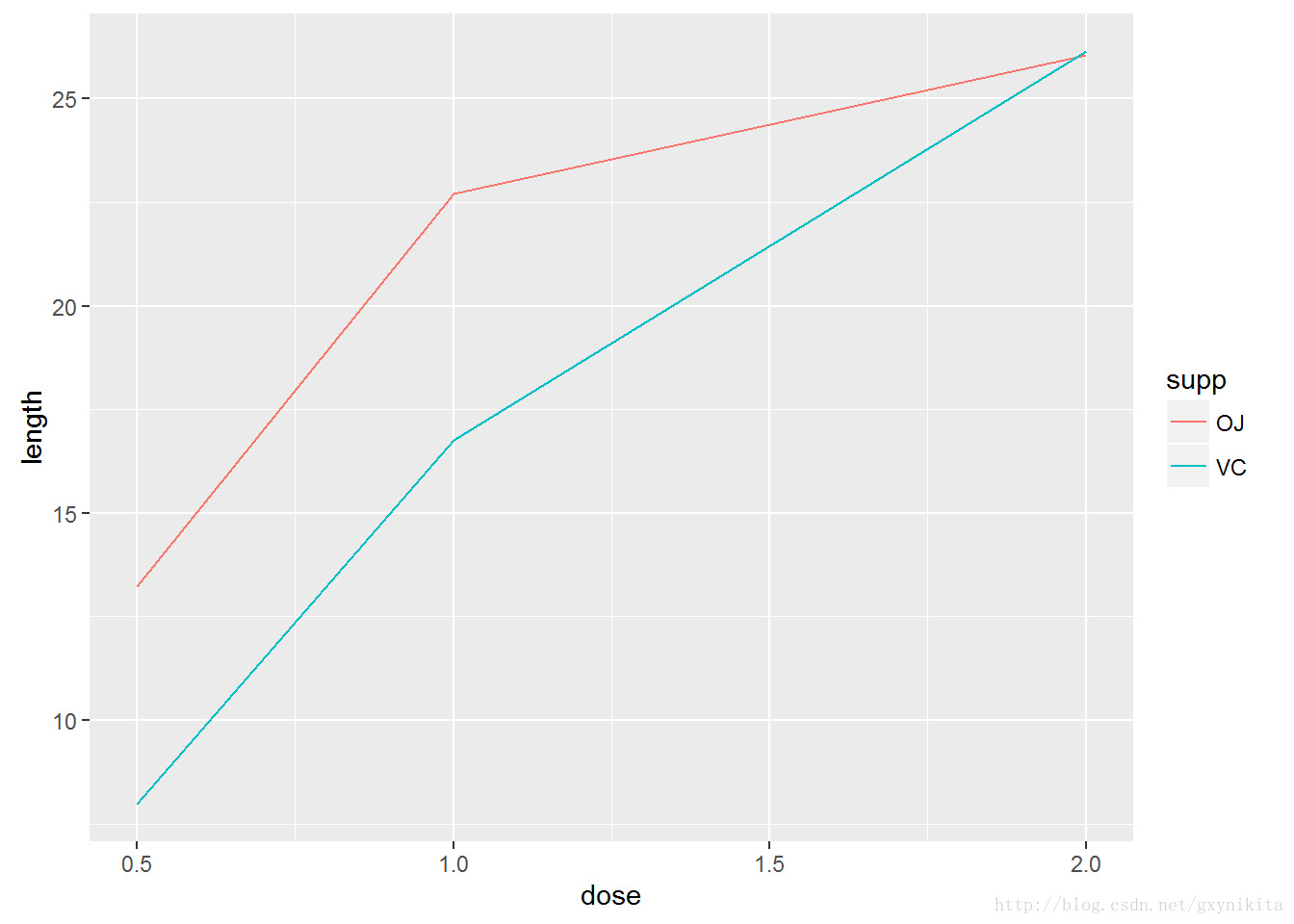
#将supp映射给线型(linetype)
ggplot(tg, aes(x=dose, y=length, linetype=supp)) + geom_line()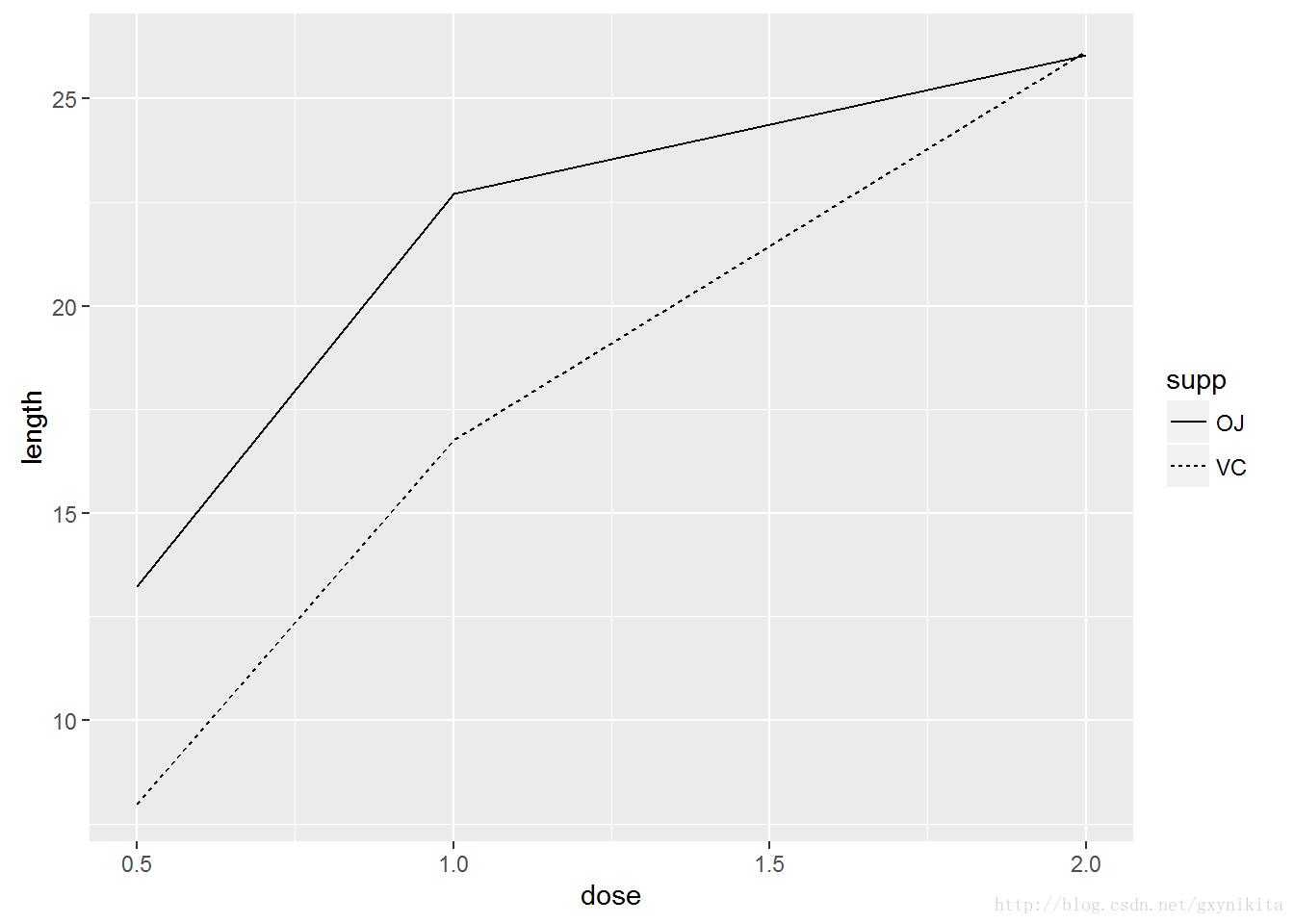
tg数据集共有三列,其中一列是映射给颜色(colour)和线型(linetype)的supp变量:
tg## supp dose length
## 1 OJ 0.5 13.23
## 2 OJ 1.0 22.70
## 3 OJ 2.0 26.06
## 4 VC 0.5 7.98
## 5 VC 1.0 16.77
## 6 VC 2.0 26.14str(tg)## 'data.frame': 6 obs. of 3 variables:
## $ supp : Factor w/ 2 levels "OJ","VC": 1 1 1 2 2 2
## $ dose : num 0.5 1 2 0.5 1 2
## $ length: num 13.23 22.7 26.06 7.98 16.77 ...如果x变量是因子,必须同时告诉ggplot()用来分组的变量,正如接下来要介绍的那样。折线图的x轴既可以对应于连续型变量也可以对应于离散型变量。有时候,映射给x的变量虽然被存储为数值型变量,但被看作分类变量来处理。在本例中,dose变量有三个取值:0.5、1.0和2.或许你更想将其当作分类变量而不是连续型变量来处理,那么运行factor()函数将其转化为因子。
ggplot(tg, aes(x=factor(dose), y=length, colour=supp, group=supp)) + geom_line()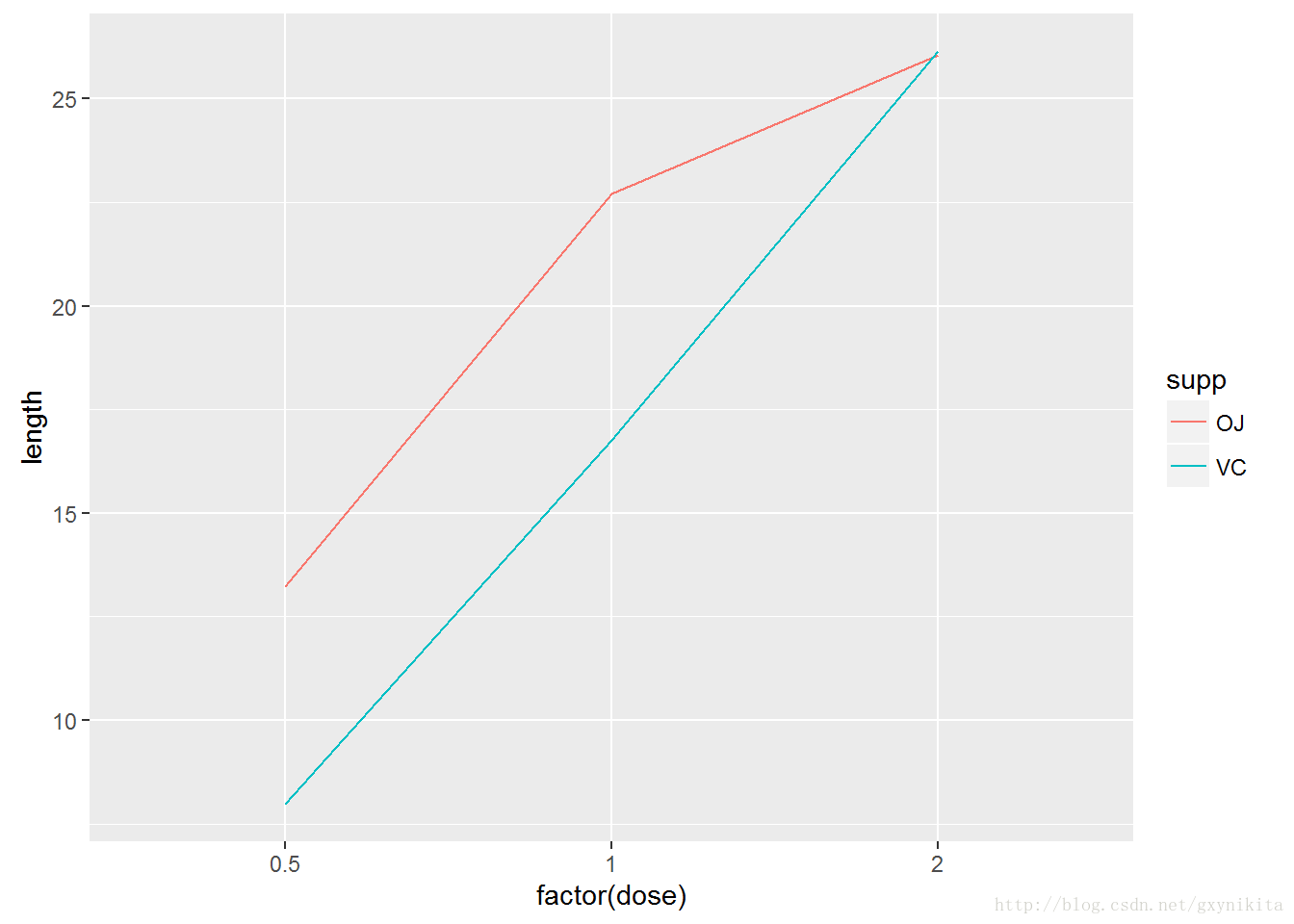
注意,不可缺少group=supp语句,否则,ggplot()会不知如何将数据组合在一起绘制折线图,从而会报错:
#ggplot(tg, aes(x=factor(dose), y=length, colour=supp)) + geom_line()
#geom_path: Each group consists of only one observation. Do you need to adjust the group aesthetic?
当分组不正确时会遇见的另一种问题是,折线图会变成锯齿状,如图所示。
ggplot(tg, aes(x=dose, y=length)) + geom_line()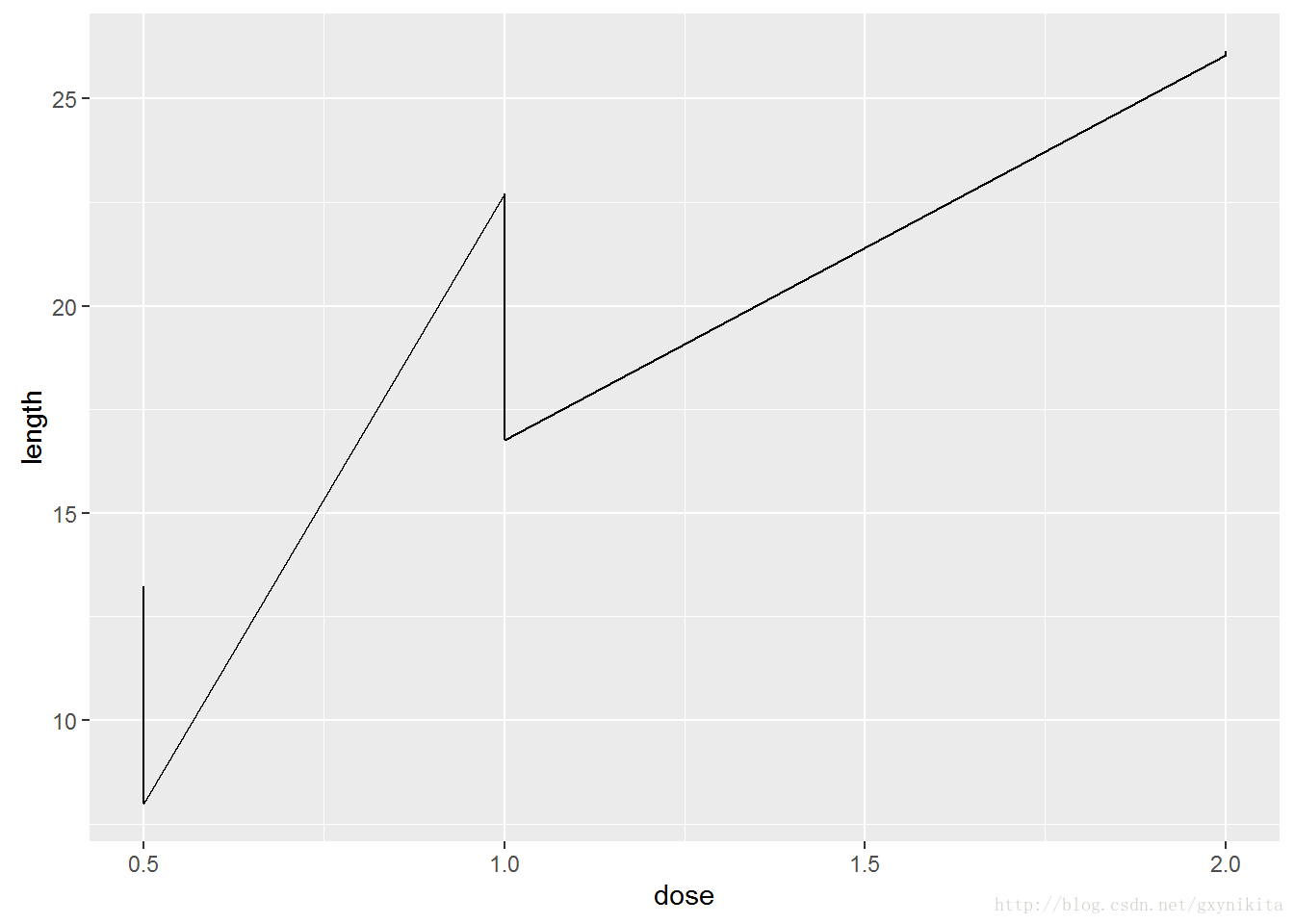
导致这种情况的原因在于x在每个位置都对应于多个点,ggplot()误以为这些点属于同一组数据而将其用一根折线相连,结果形成了锯齿状折线图。如果将任意离散型变量映射给colour或者linetype,ggplot()会以其为分组变量对数据进行分组。如果你想借助其他变量对数据进行分组(未映射给图形属性)则需使用group。有疑问时,或者如果你的折线图看起来不太合理,可以试着用group明确指定分组变量。这种问题十分常见,因为ggplot()不知道如何对折线图数据进行分组。如果折线图上有数据标记,你也可以将分组变量映射给数据标记的属性,诸如shape和fill等。
ggplot(tg, aes(x=dose, y=length, shape=supp)) + geom_line() + geom_point(size=4) #更大的点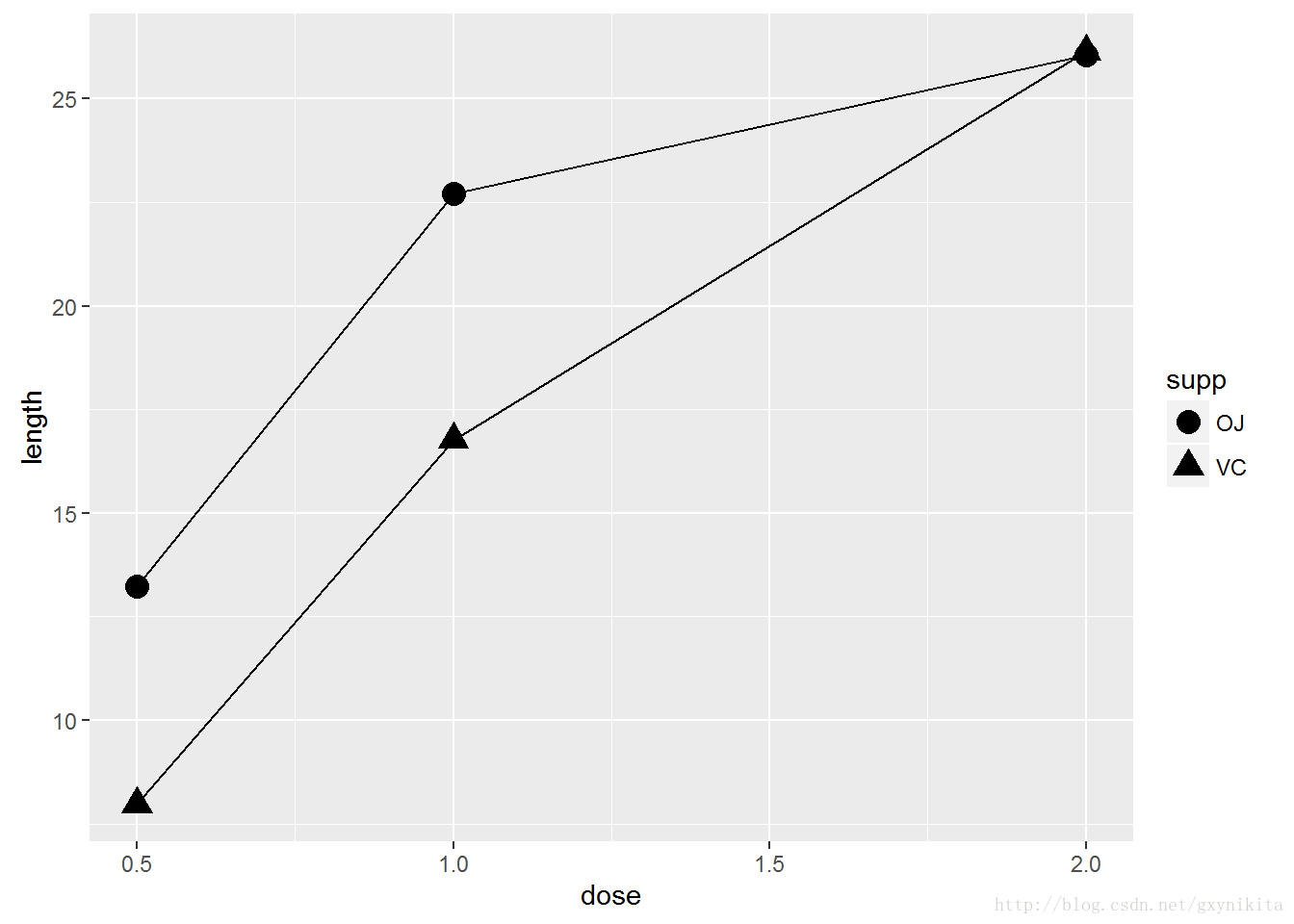
ggplot(tg, aes(x=dose, y=length, fill=supp)) + geom_line() + geom_point(size=4, shape=21) #使用有填充色的点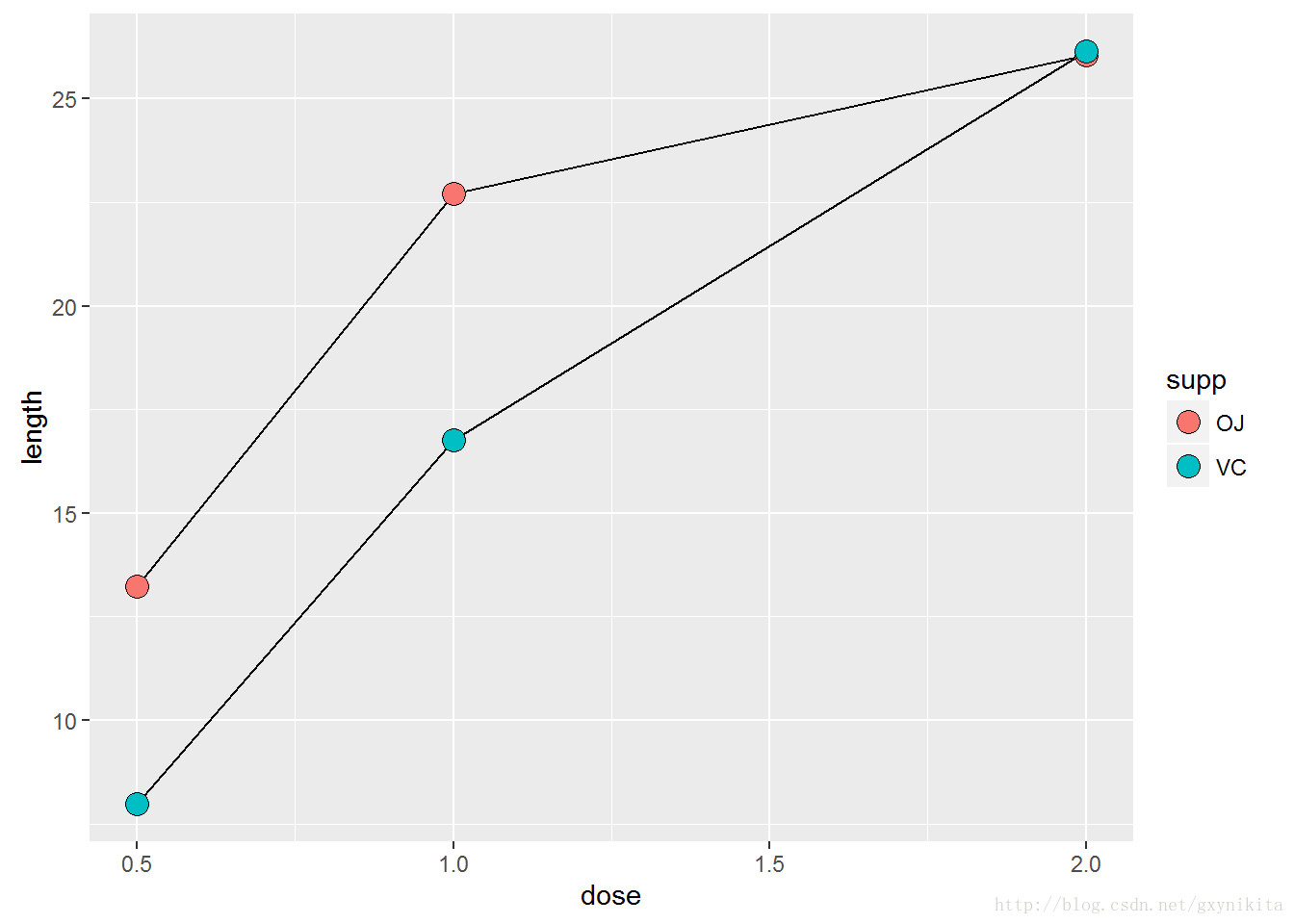
有时,数据标记会相互重叠。需要令其彼此错开。这意味着要将它们的位置左移或者右移。同时,需要相应地左移或者右移连接线以避免电线偏离。在这一过程中,必须指定数据标记的移动距离。
ggplot(tg, aes(x=dose, y=length, shape=supp)) +
geom_line(position=position_dodge(0.2)) + #将连接线左右移动0.2 geom_point(position=position_dodge(0.2), size=4) #将点的位置左右移动0.2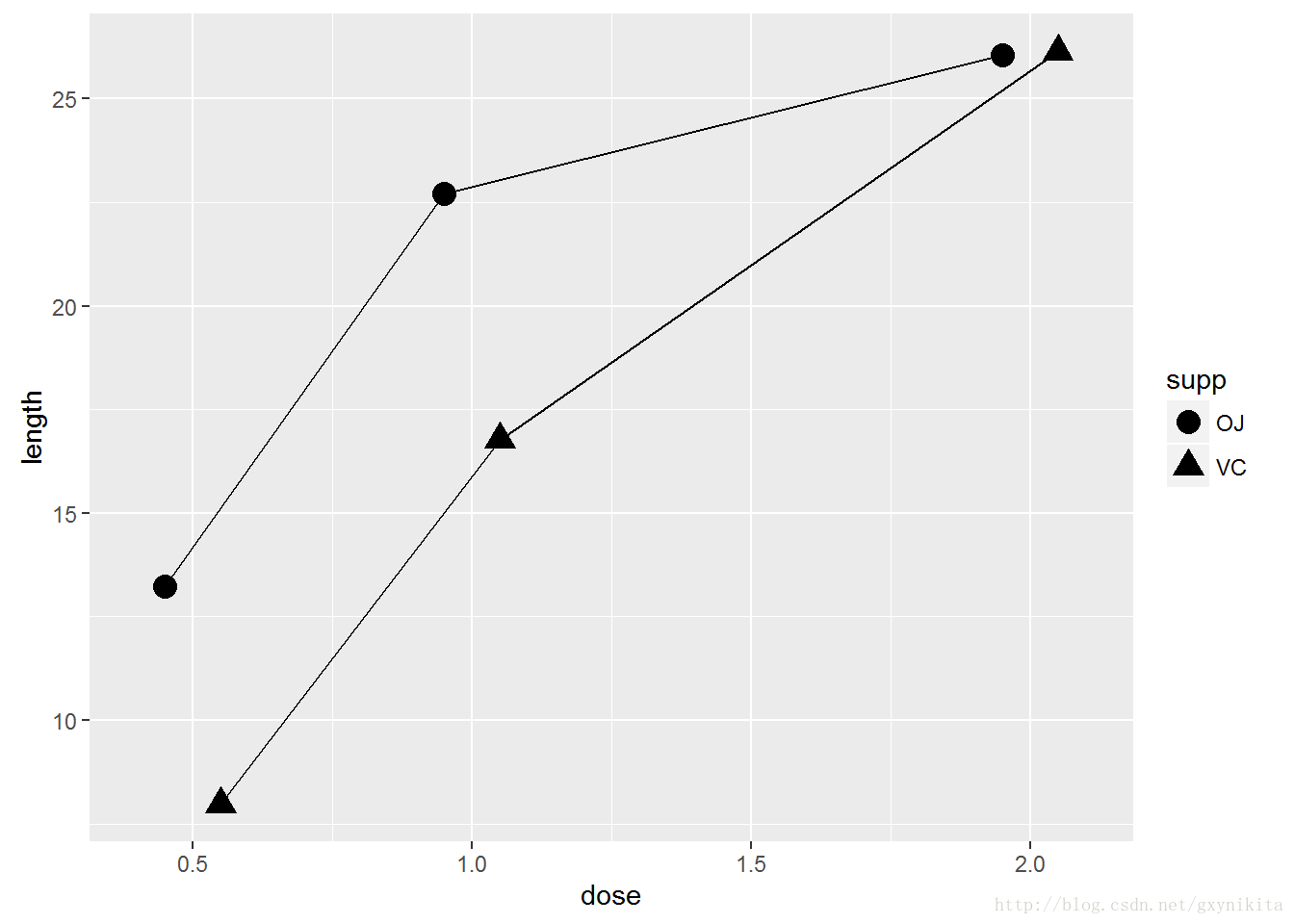
4.4修改线条样式
通过设置线型(linetpye)、线宽(size)和颜色(colour)参数可以分别修改折线的线型、线宽和颜色。通过将这些参数的值传递给geom_line()函数可以设置折线图的对应属性,如图所示。
ggplot(BOD, aes(x=Time, y=demand)) +
geom_line(linetype="dashed", size=1, colour="blue")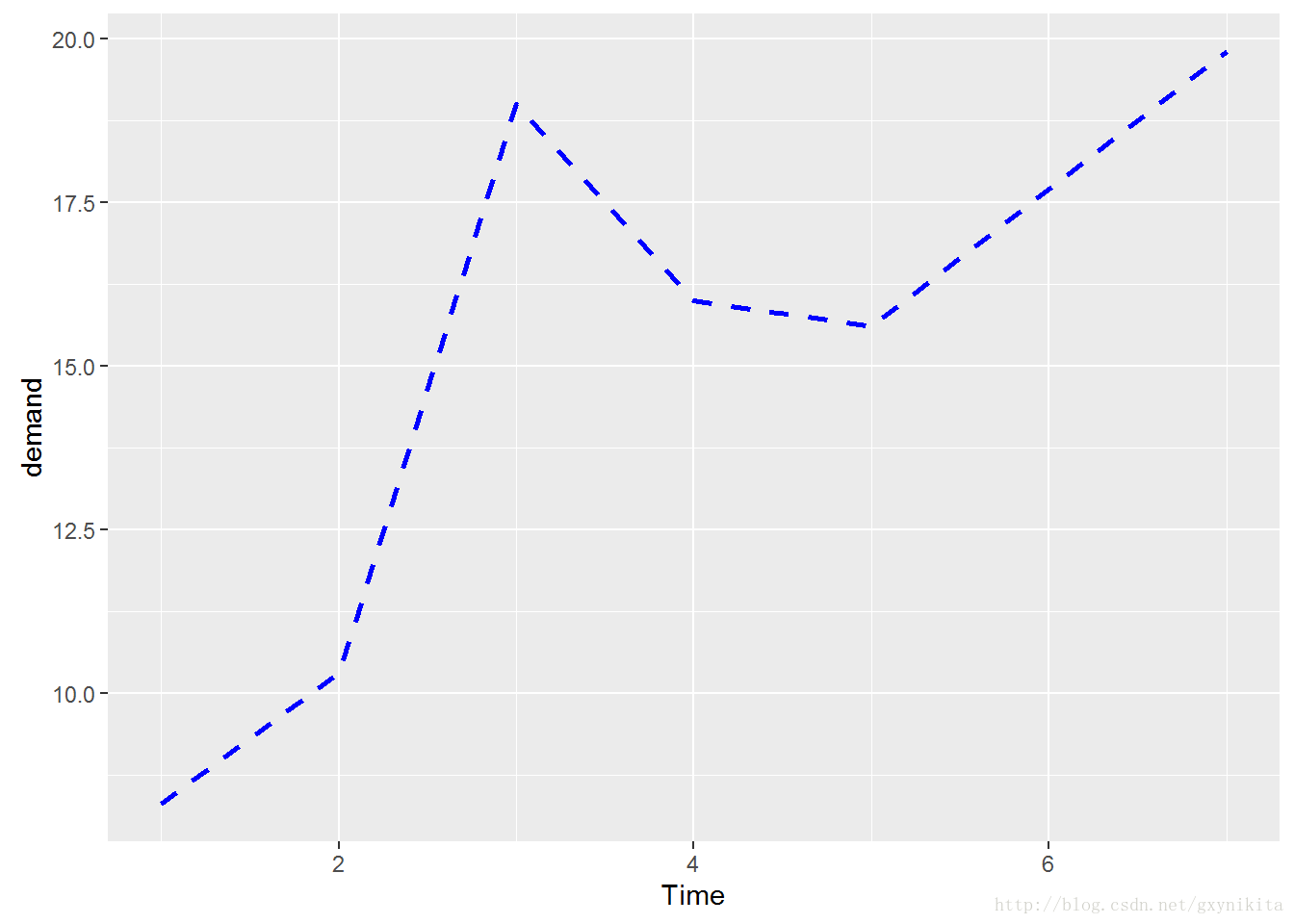
对于多重折线图而言,设定图形属性会对图上的所有折线产生影响。而将变量映射给图形属性则会使图上的折线具有不同的外观。折线图的默认颜色并不是很吸引眼球,所以,我们可能希望使用其他调色板为图形着色,可以调用scale_colour_brewer()和scale_colour_manual()函数完成上述操作,如图所示。
#加载plyr包,便于调用ddply()函数创建例子所需的数据集
library(plyr)
#对ToothGrowth数据集进行汇总
tg <- ddply(ToothGrowth, c("supp","dose"), summarise, length=mean(len))
ggplot(tg, aes(x=dose, y=length, colour=supp)) +
geom_line()+
scale_color_brewer(palette="Set1")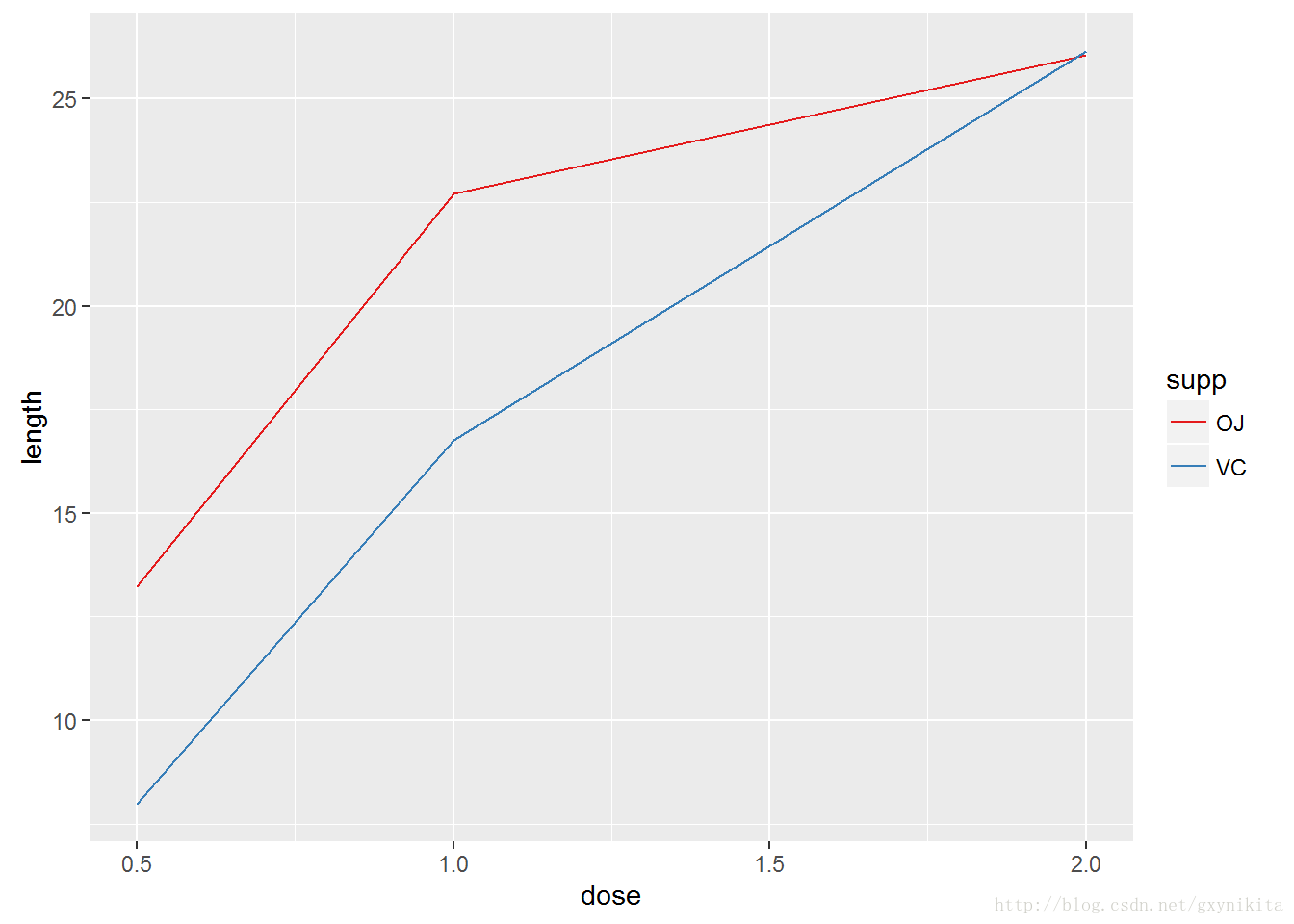
在aes()函数外部设定颜色(colour)会将所有折线设定为同样的颜色。其他图形属性诸如线宽(size)、线型(linetype)和点形(shape)与此类似,如图所示。操作过程中可能需要指定分组变量。
#如果两条折线的图形属性相同,需要指定一个分组变量
ggplot(tg, aes(x=dose, y=length, group=supp)) +
geom_line(colour="darkgreen", size=1.5)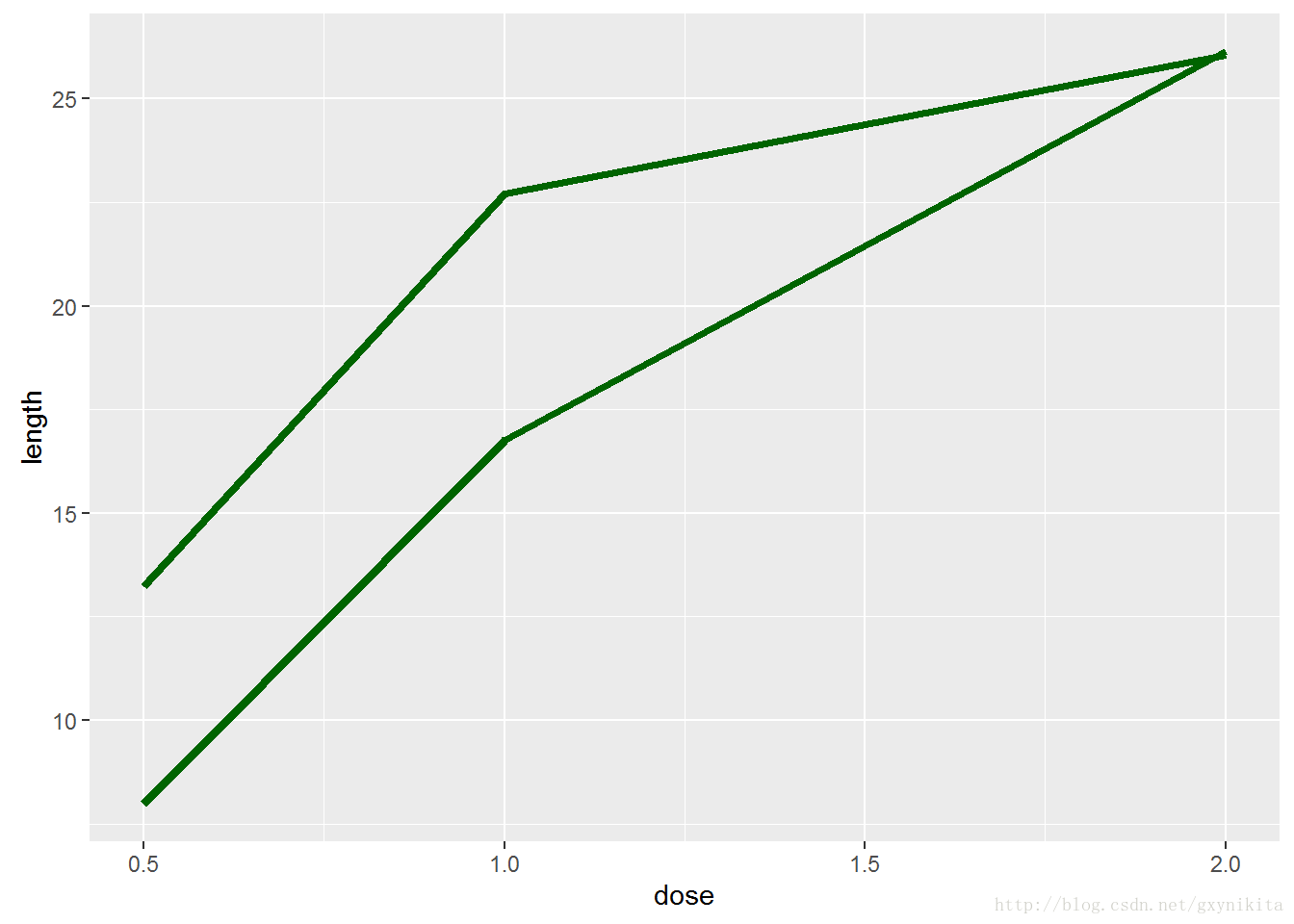
#因为变量supp被映射给了颜色(colour)属性,所以,它自动作为分组变量
ggplot(tg, aes(x=dose, y=length, colour=supp)) +
geom_line(linetype="dashed") +
geom_point(shape=22, size=3, fill="white")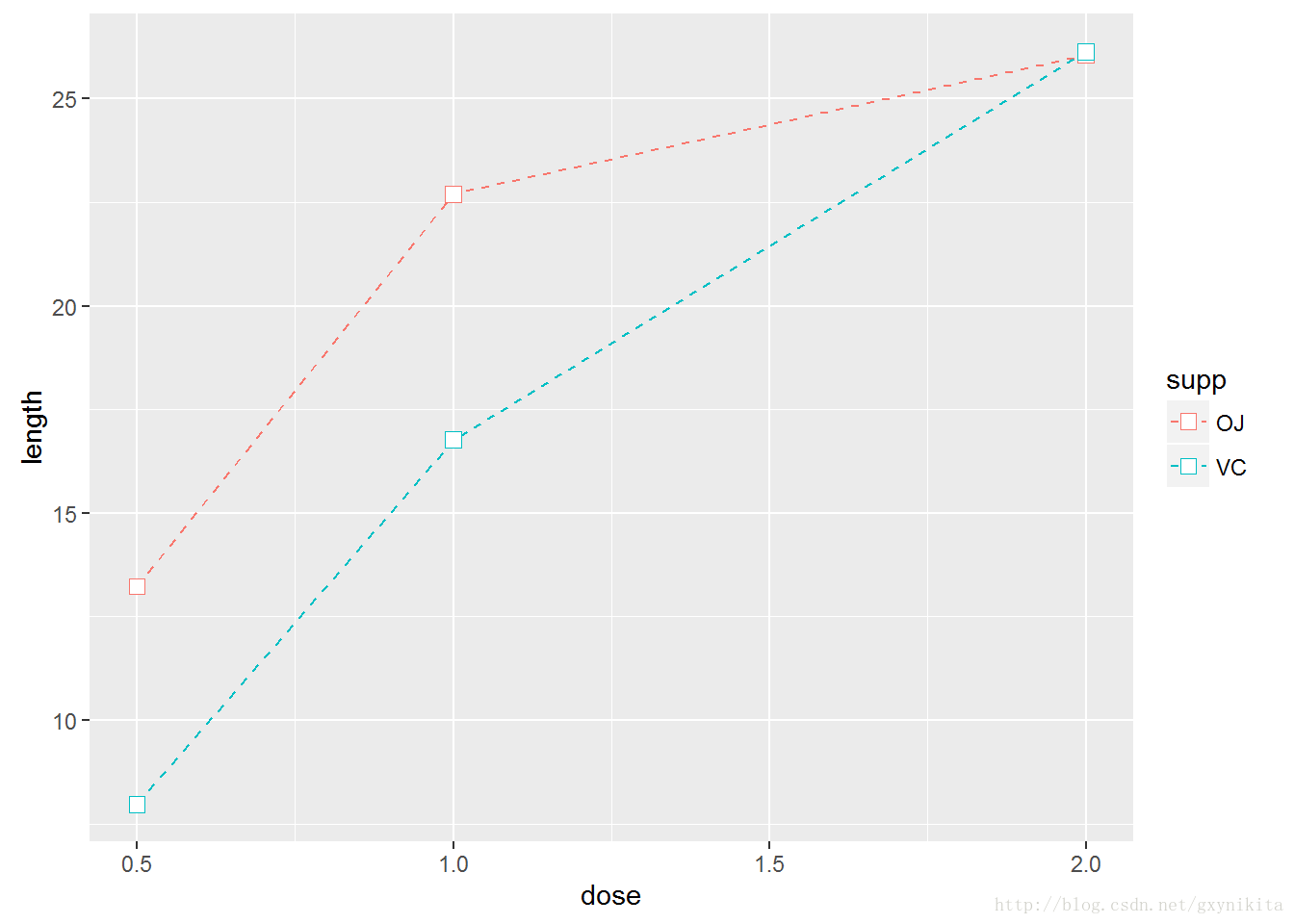
4.5 修改数据标记样式
在函数aes()外部设定函数geom_point()的大小(size)、颜色(colour)和填充色(fill)即可,如图所示。
ggplot(BOD, aes(x=Time, y=demand)) +
geom_line() +
geom_point(size=4, shape=22, colour="darkred", fill="pink")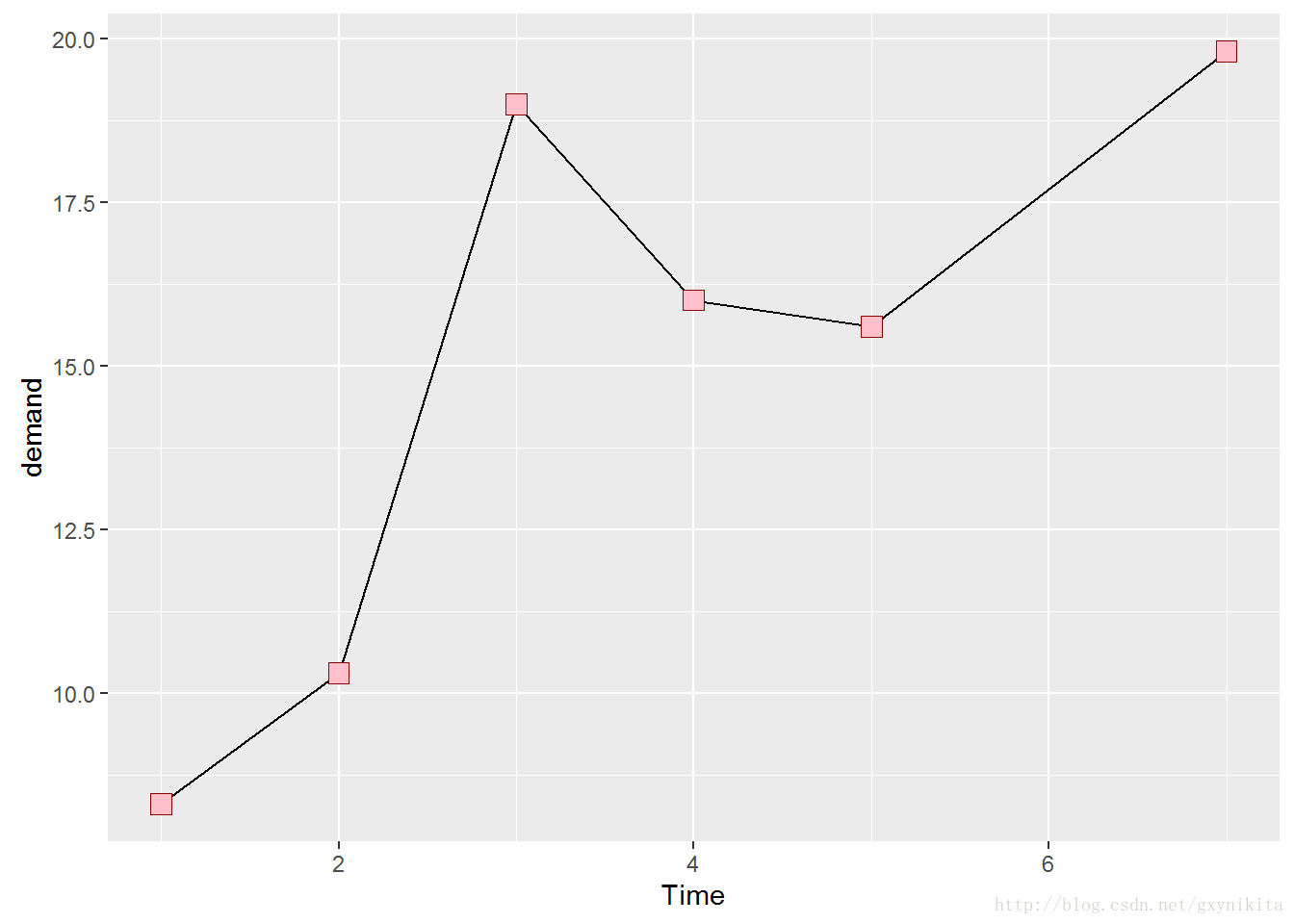
数据标记默认的形状(shape)是实线圆圈,默认的大小(size)是2,默认的颜色(colour)是黑色(black)。填充色(fill)属性只适用于某些(标号21-25)具有独立边框线和填充色的点形。fill一般取空值或者NA。将填充色设定为白色可以得到一个空心圆,如图所示。
ggplot(BOD, aes(x=Time, y=demand)) +
geom_line() +
geom_point(size=4, shape=21, fill="white")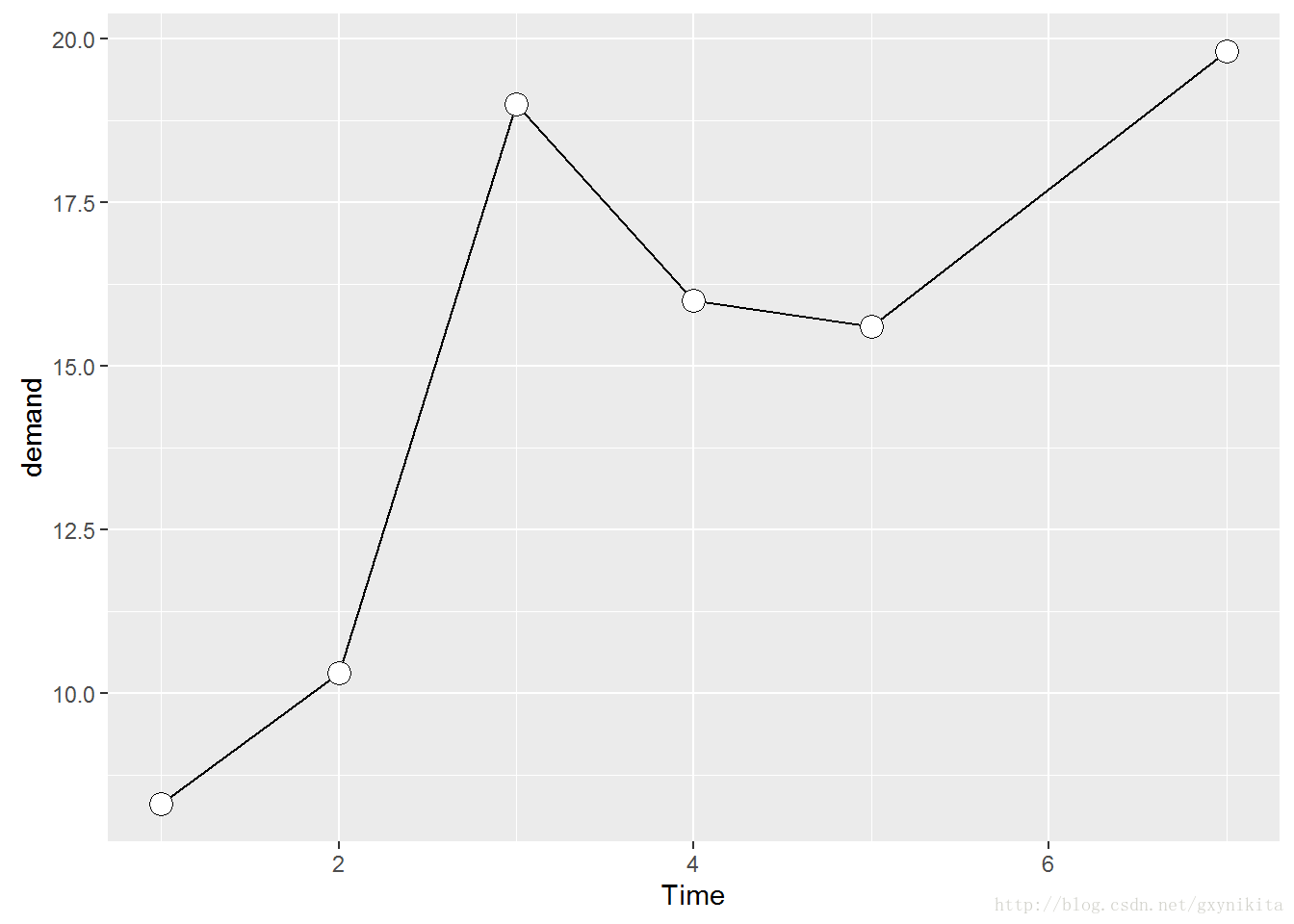
如果要将数据标记和折线设定为不同的颜色,必须在折线绘制完毕后再设定数据标记的颜色,此时,数据标记被绘制在更上面的图层,从而,避免被折线遮盖。通过在aes()函数内部将分组变量映射给数据标记的图形属性可以将多条折线设定为不同的颜色。数据标记的默认颜色并不吸引眼球,因而,你可能想要调用别的调色板,scale_colour_brewer()函数和scale_colour_manual()函数可以完成上述操作。在aes()函数外部设定shape和size可以将数据标记设定为统一的形状和颜色,如图所示。
#载入plyr包,以使用ddply()函数创建例子所需数据集
library(plyr)
#对ToothGrowth数据集进行汇总
tg <-ddply(ToothGrowth, c("supp","dose"), summarise, length=mean(len))
#保存错开(dodge)设置,接下来会多次用到
pd <- position_dodge(0.2)
ggplot(tg, aes(x=dose, y=length, fill=supp)) +
geom_line(position = pd) +
geom_point(shape=21, size=3, position = pd) + scale_fill_manual(values=c("black","white"))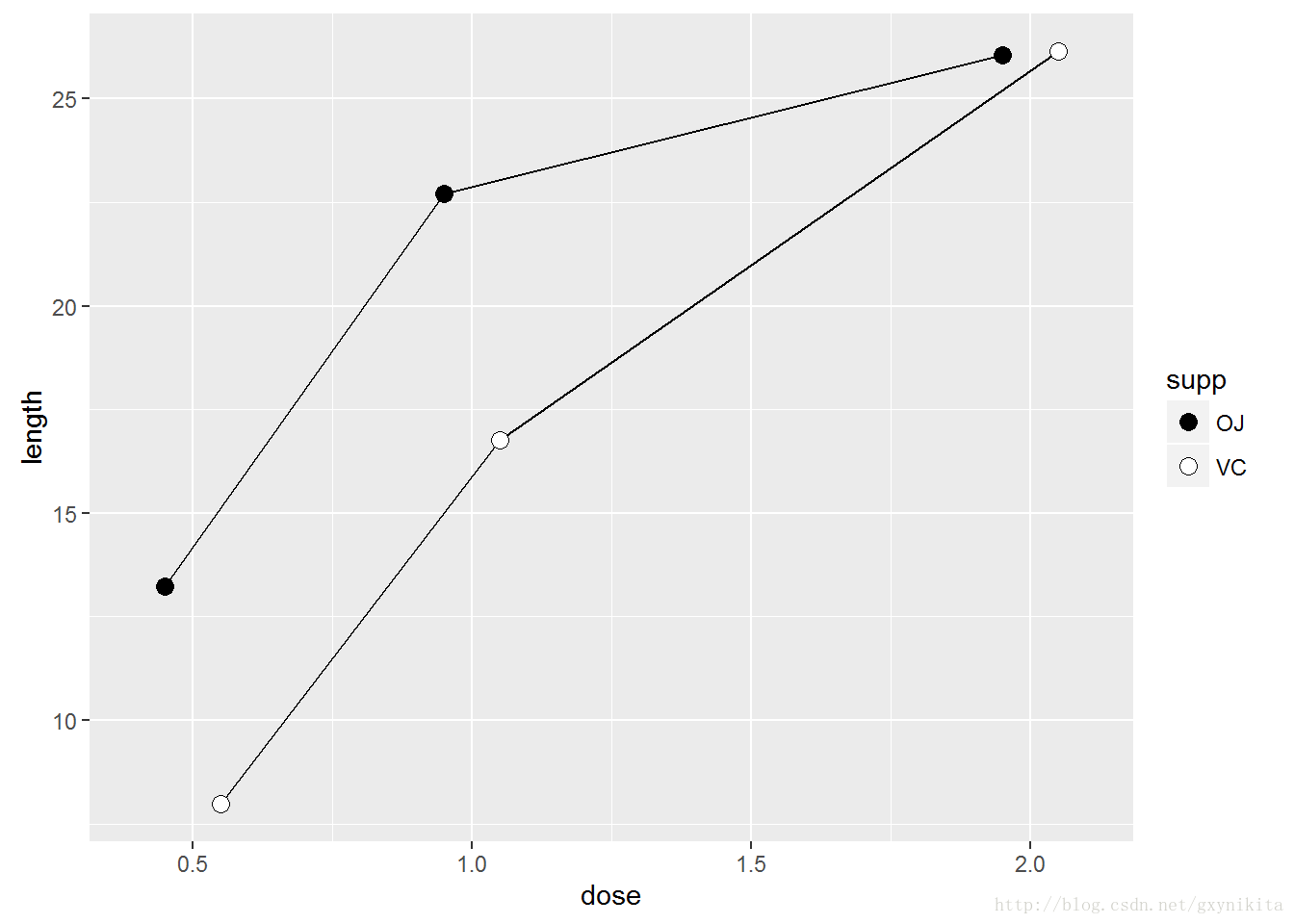
4.6绘制面积图
运行geom_area()函数即可绘制面积图,如图所示。
#将sunspot.year数据集转化为数据框,便于本例使用
sunspotyear <- data.frame(
Year = as.numeric(time(sunspot.year)),
Sunspots = as.numeric(sunspot.year)
)
ggplot(sunspotyear, aes(x=Year, y=Sunspots)) + geom_area()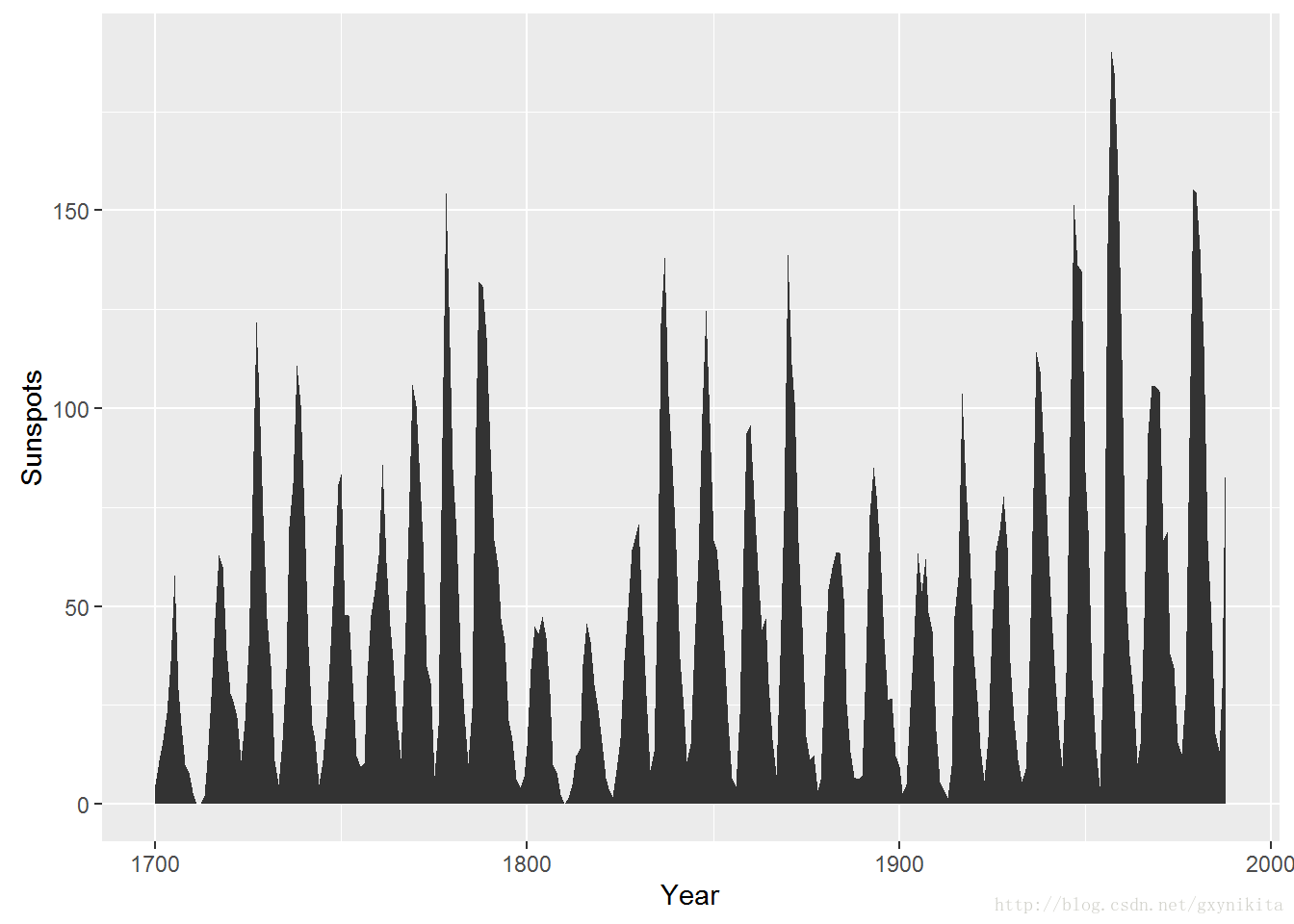
默认情况下,面积图的填充色为黑色且没有边框线,通过设定填充色(fill)可以修改面积图的填充色。接下来的例子将填充色设定为蓝色,并通过设定alpha=0.2将面积图的透明度设定为80%,此时,可以看到面积图的网格线,如图所示。
通过设置颜色(colour)可以为面积图添加边框下:
ggplot(sunspotyear, aes(x=Year, y=Sunspots)) +
geom_area(colour="black", fill="blue", alpha=.2)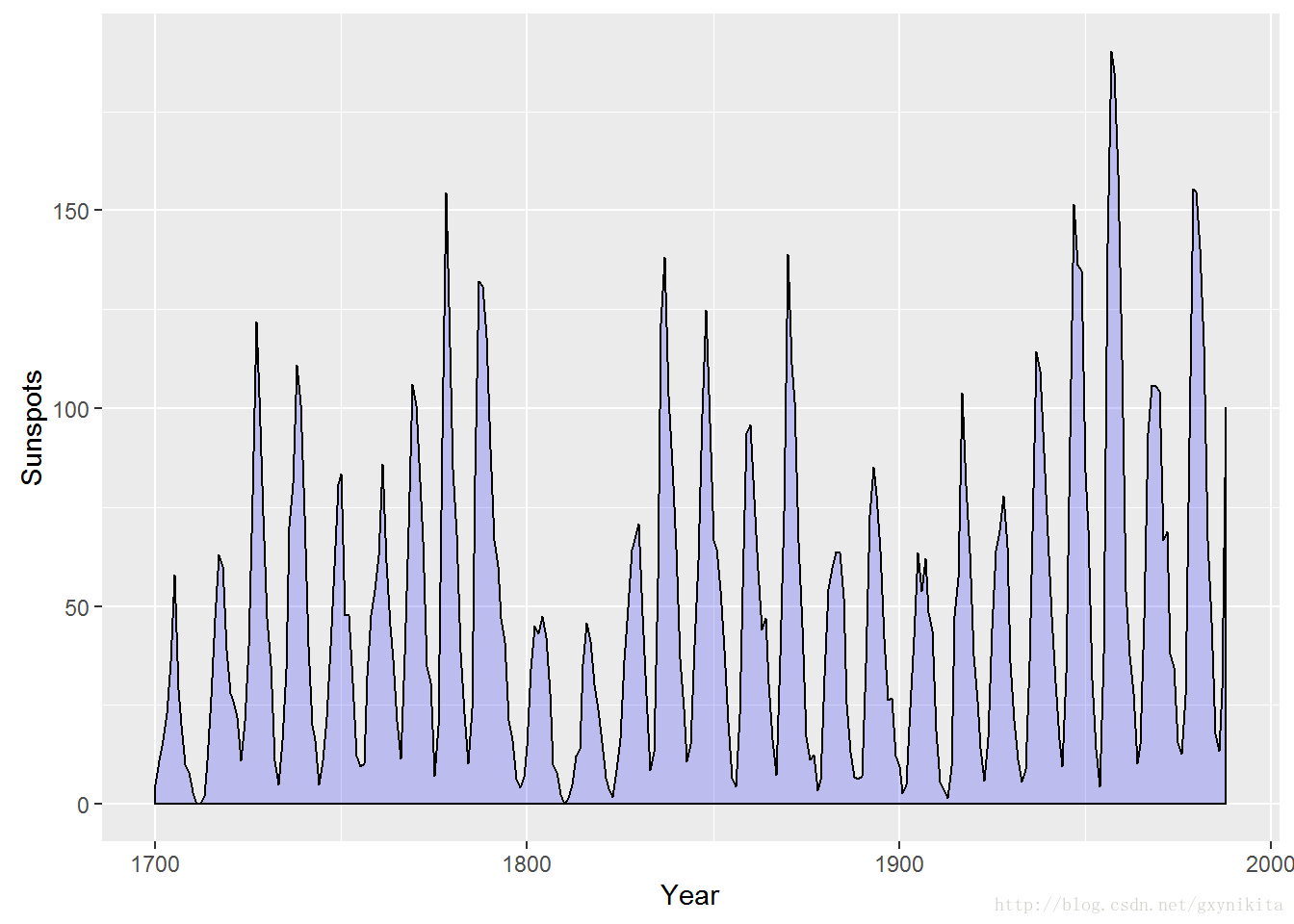
给整个面积图添加边框线之后的效果可能并不十分令人满意,因为此时系统会在面积图的起点和终点位置分别绘制一条垂直线,并在底部绘制了一条横线。为了修正上述情况,可以先绘制不带边框线的面积图(不设定colour),然偶胡,添加新图层,并用geom_line()函数绘制轨迹线,如图所示。
ggplot(sunspotyear, aes(x=Year, y=Sunspots)) +
geom_area(fill="blue", alpha=.2) +
geom_line()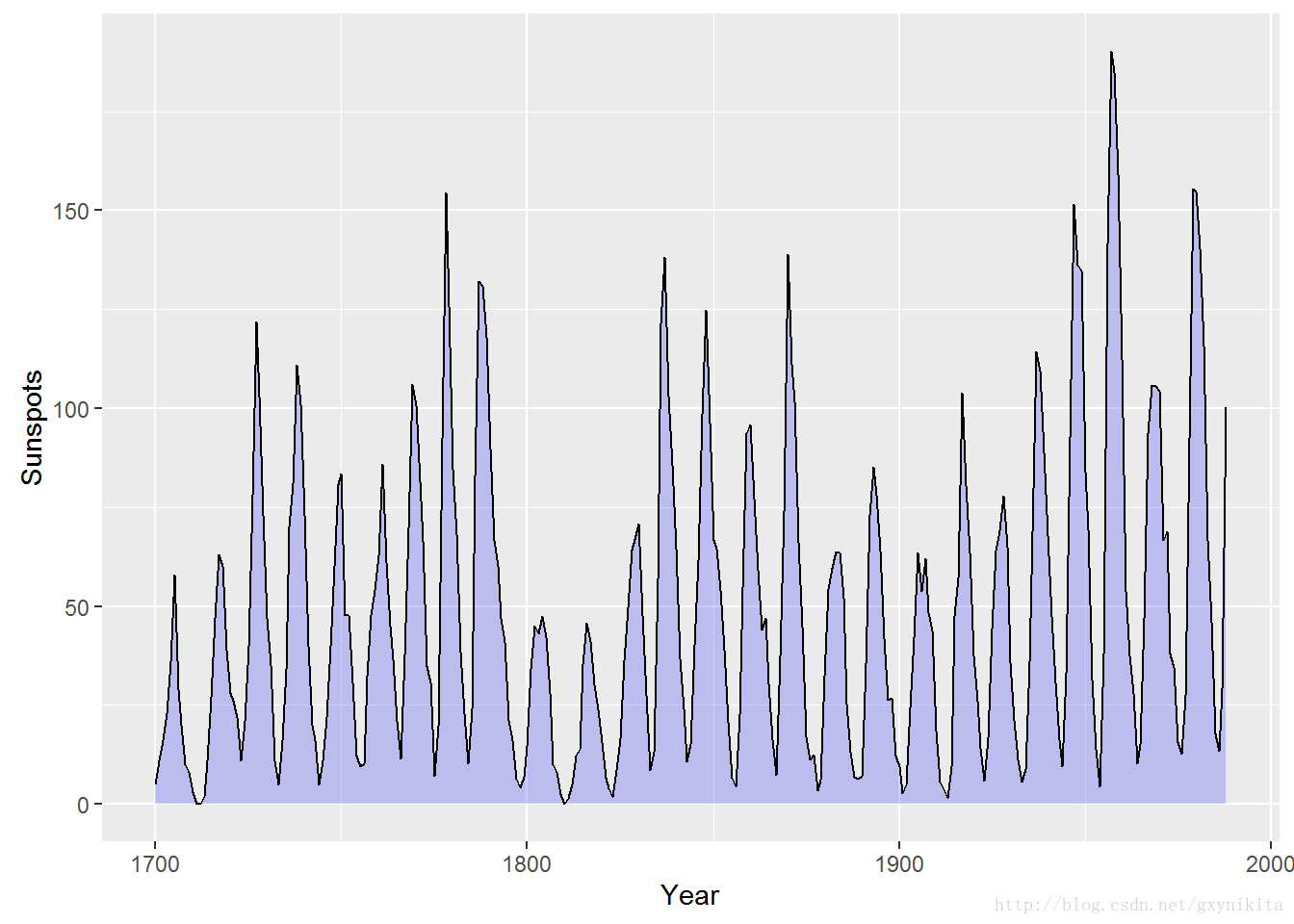
4.7 绘制堆积面积图
运行geom_area()函数,并映射一个因子型变量给填充色(fill)即可,如图所示。
library(gcookbook) #为了使用数据
ggplot(uspopage, aes(x=Year, y=Thousands, fill=AgeGroup)) +geom_area()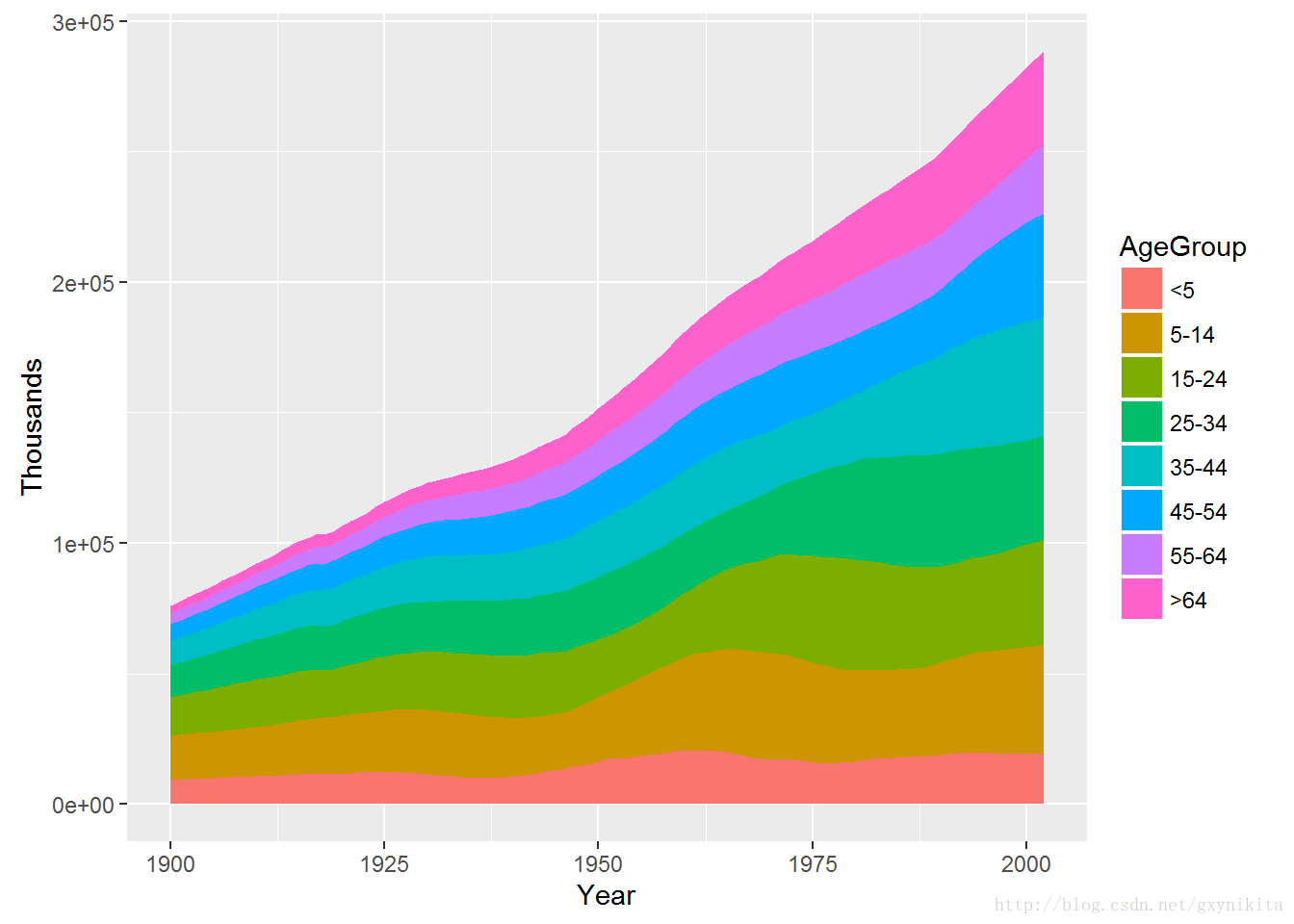
堆积面积图对应的基础数据通常为宽格式(wide format),但ggplot2要求数据必须是长格式(long format)。
下面以uspopage数据集为例:
uspopage## Year AgeGroup Thousands
## 1 1900 <5 9181
## 2 1900 5-14 16966
## 3 1900 15-24 14951
## 4 1900 25-34 12161
## 5 1900 35-44 9273
……
## 820 2002 25-34 39928
## 821 2002 35-44 44917
## 822 2002 45-54 40084
## 823 2002 55-64 26602
## 824 2002 >64 35602默认情况下图例的堆积顺序与面积图的堆积顺序是相反的。通过设定标度中的切分(breaks)参数可以翻转堆积顺序。下图中的堆积面积图对图例的堆积顺序进行了反转,将调色板设定为蓝色渐变色,并在各个区域之间添加细线(size=.2)。同时将填充区域设定为半透明(alpha=.4),这样可以透过填充区域看见网格线。
ggplot(uspopage, aes(x=Year, y=Thousands, fill=AgeGroup)) +
geom_area(colour="black", size=.2, alpha=.4) +
scale_fill_brewer(palette="Blues", breaks=rev(levels(uspopage$AgeGroup)))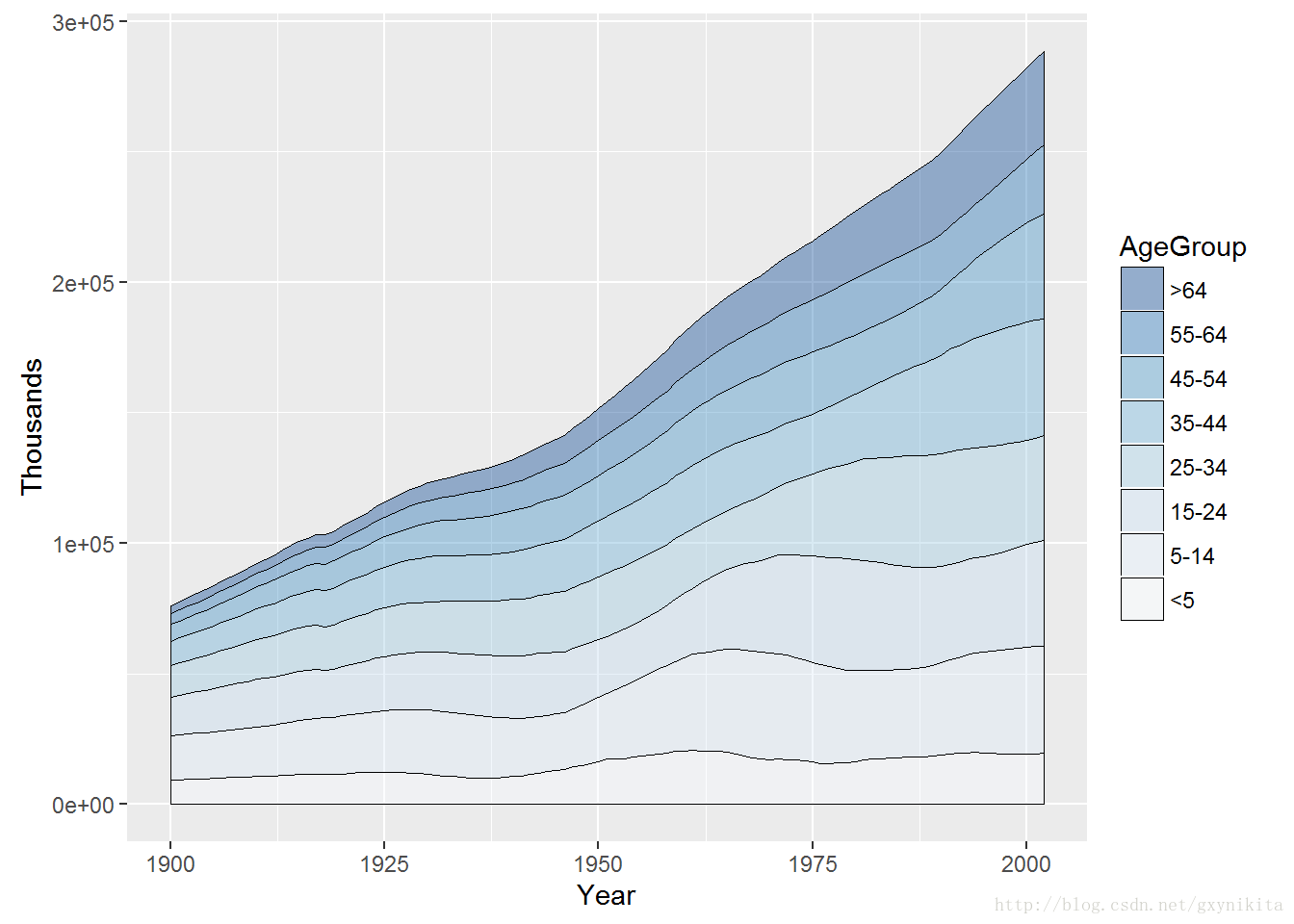
在aes()函数内部设定order=desc(AgeGroup)可以对堆积面积图的堆积顺序进行反转,如图所示。
library(plyr) #为了使用desc()函数
ggplot(uspopage, aes(x=Year, y=Thousands, fill=AgeGroup, order=desc(AgeGroup))) +
geom_area(colour="black", size=.2, alpha=.4) +
scale_fill_brewer(palette="Blues")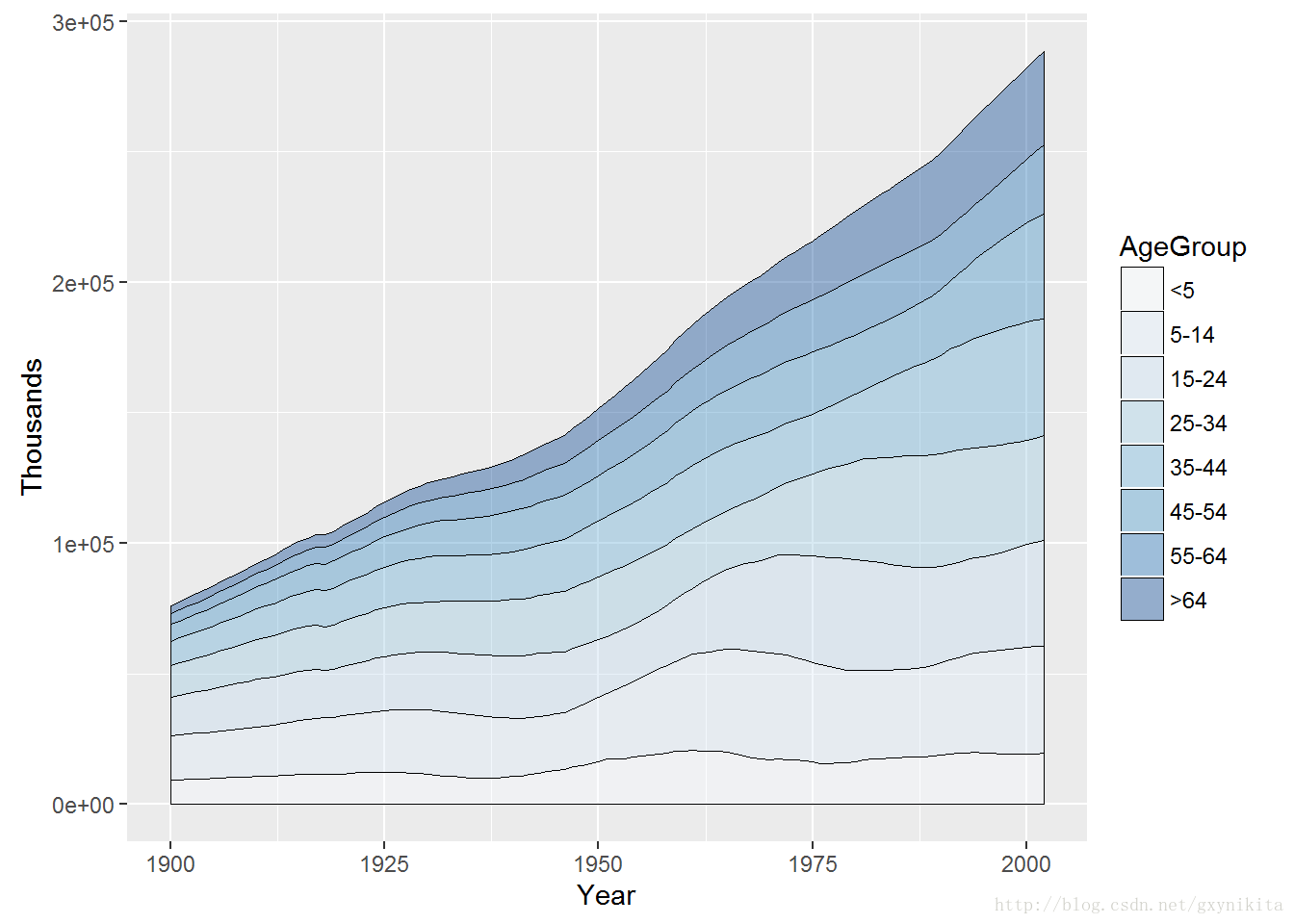
因为堆积面积图中的各个部分是由多边形构成的,因此其具有左、右边框线。这样的绘图效果差强人意且可能产生误导效果。为了对此进行修正,可以先绘制一个不带边框线的堆积面积图(将colour设定为默认的NA值),然后,在其顶部添加geom_line():
ggplot(uspopage, aes(x=Year, y=Thousands, fill=AgeGroup, order=desc(AgeGroup))) +
geom_area(colour=NA, alpha=.4) +
scale_fill_brewer(palette="Blues") +
geom_line(position="stack", size=.2)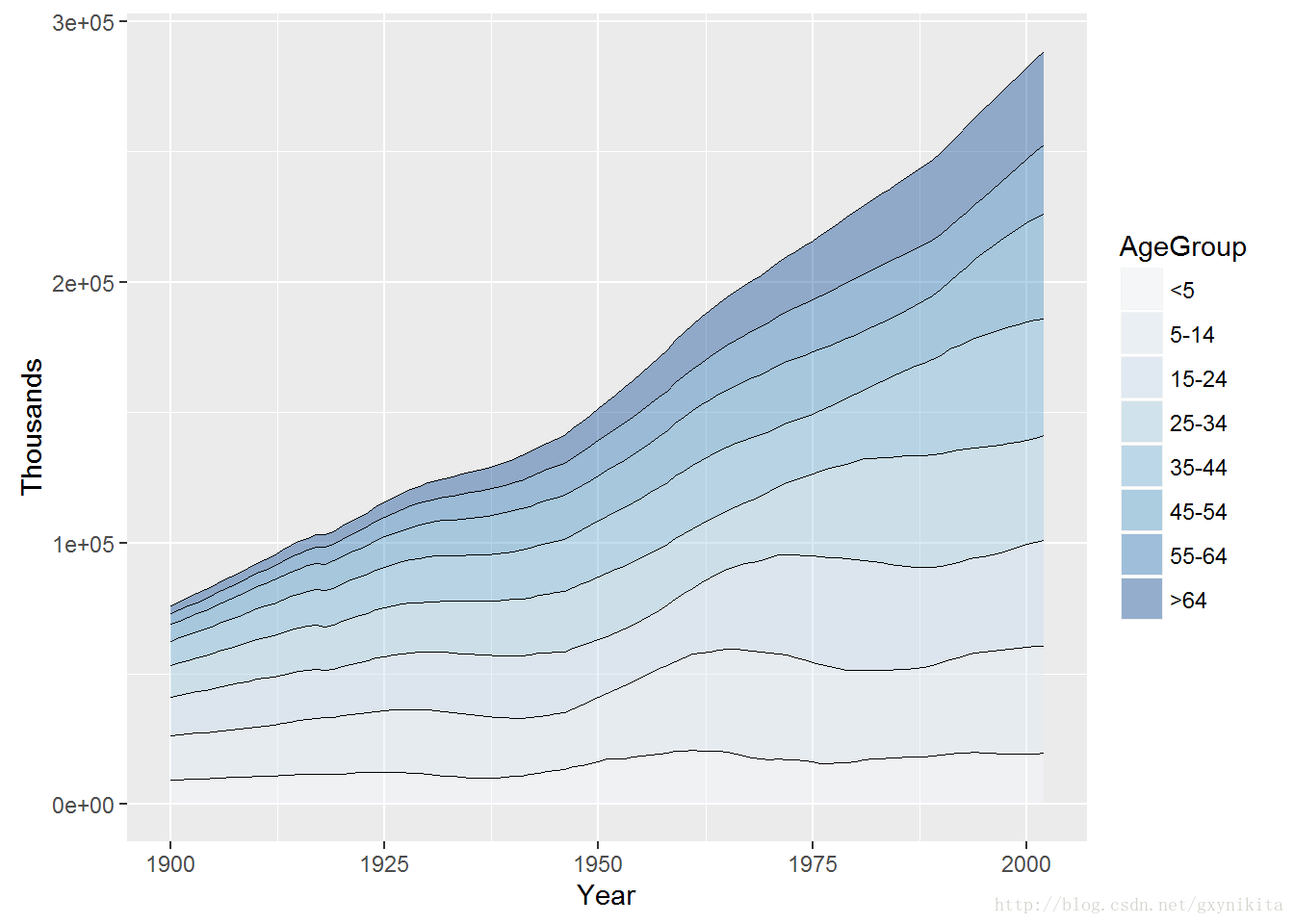
4.8 绘制面积百分比堆积面积图
首先,计算各组对应的百分比。本例中,调用ddply()函数按照变量Year对uspopage进行分组,然后计算一个新的列,命名为Percent。该列每一行的值等于对应的Thousands值除以变量Year对应的各个组内的Thousands之和再乘以100%。
library(gcookbook) #为了使用数据
library(plyr) #为了使用ddply()函数
#将Thousands转化为Percent
uspopage_prop <- ddply(uspopage, "Year", transform, Percent=Thousands/sum(Thousands)*100)计算得出百分比之后,剩余的绘图步骤与绘制普通堆积面积图的步骤一样,如图所示。
ggplot(uspopage_prop, aes(x=Year, y=Percent, fill=AgeGroup)) +
geom_area(colour="black", size=.2, alpha=.4) +
scale_fill_brewer(palette="Blues", breaks=rev(levels(uspopage$AgeGroup)))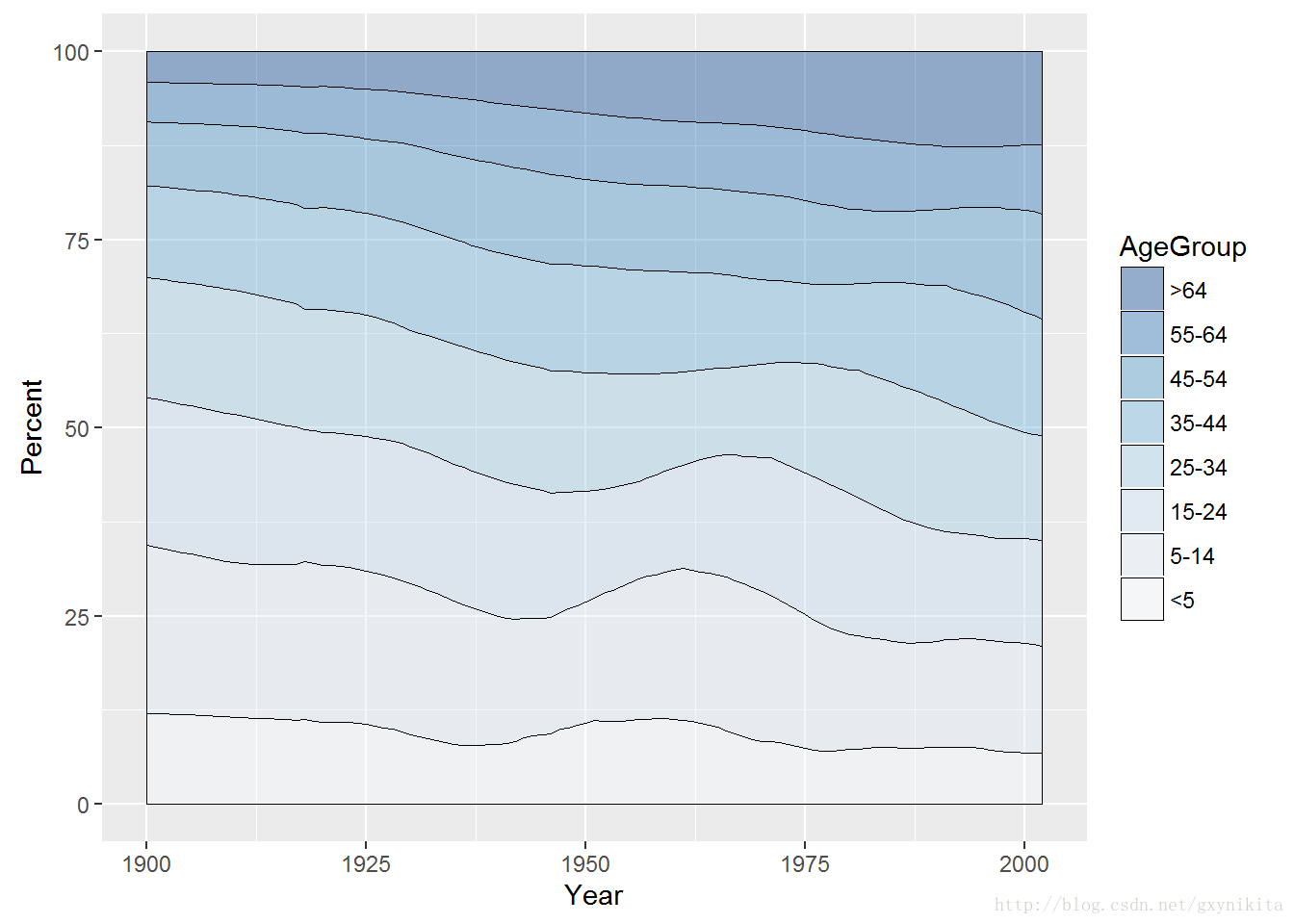
更深入查看上面的数据,并探究一下数据的计算过程:
uspopage## Year AgeGroup Thousands
## 1 1900 <5 9181
## 2 1900 5-14 16966
## 3 1900 15-24 14951
## 4 1900 25-34 12161
## 5 1900 35-44 9273
……
## 820 2002 25-34 39928
## 821 2002 35-44 44917
## 822 2002 45-54 40084
## 823 2002 55-64 26602
## 824 2002 >64 35602调用ddply()函数,按照变量Year将数据集拆分成多个独立的数据框,对所有数据框执行transform()函数并计算每个数据框对应的Percent。最后,调用ddply()函数将所有数据框重组在一起:
uspopage_prop <- ddply(uspopage, "Year", transform, Percent=Thousands/sum(Thousands)*100)4.9添加置信域
运行geom_ribbon(),然后分别映射一个变量给ymin和ymax。climate数据集中的Anomaly10y变量表明了各年温度相对于1950-1980平均水平变异(以摄氏度衡量)的10年移动平均。变量Unc10y表示其95%置信水平下的置信区间。令ymax和ymin分别设定为Anomaly10y加减Unc10y:
library(gcookbook) #为了使用数据
#抓取climate数据集的一个子集
clim <- subset(climate, Source=="Berkeley", select=c("Year","Anomaly10y","Unc10y"))
clim## Year Anomaly10y Unc10y
## 1 1800 -0.435 0.505
## 2 1801 -0.453 0.493
## 3 1802 -0.460 0.486
## 4 1803 -0.493 0.489
## 5 1804 -0.536 0.483
……
## 200 1999 0.734 0.025
## 201 2000 0.748 0.026
## 202 2001 0.793 0.027
## 203 2002 0.856 0.028
## 204 2003 0.869 0.028
## 205 2004 0.884 0.029#将置信域绘制为阴影
ggplot(clim, aes(x=Year,y=Anomaly10y)) +
geom_ribbon(aes(ymin=Anomaly10y-Unc10y, ymax=Anomaly10y+Unc10y), alpha=0.2) +
geom_line()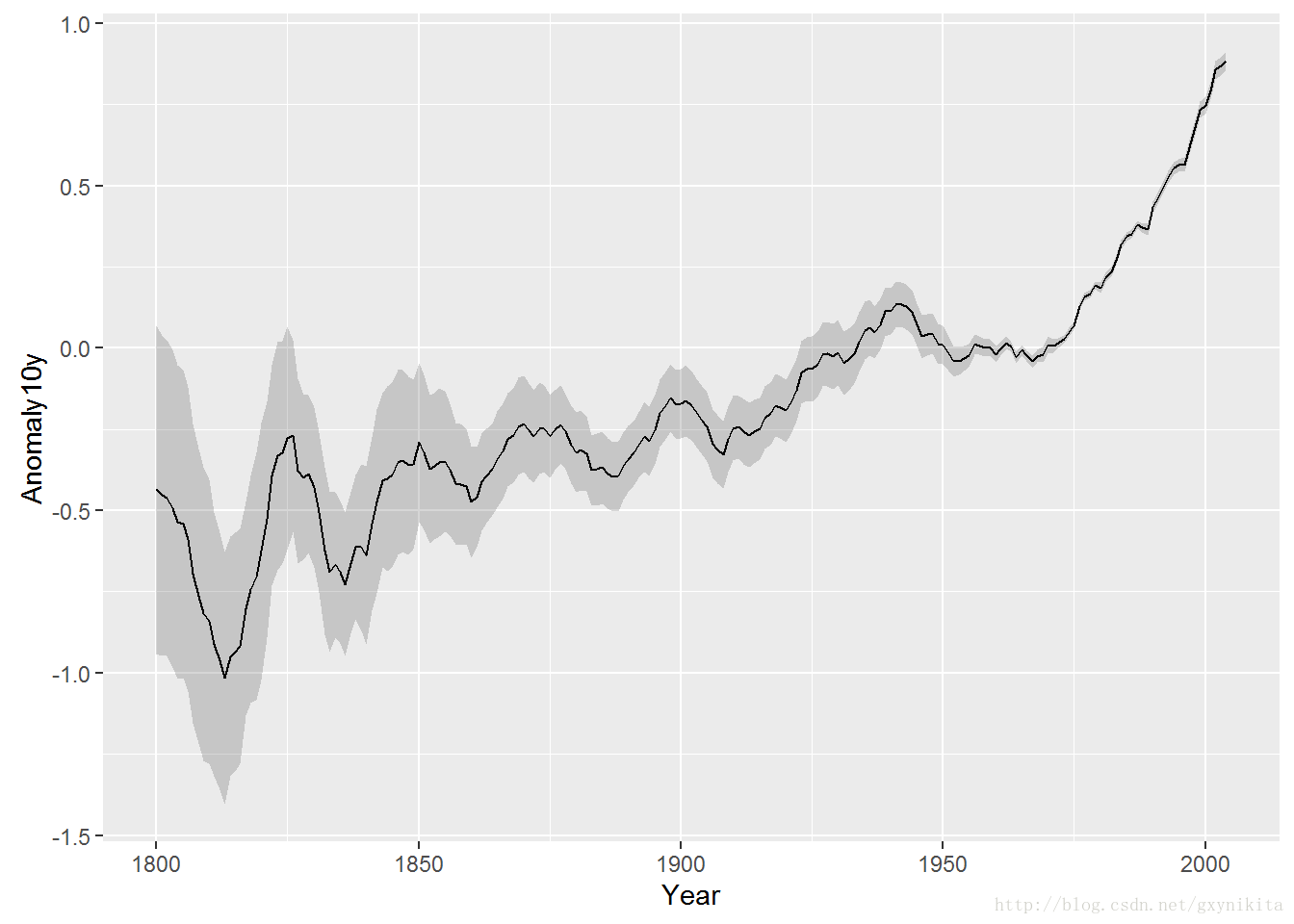
阴影部分的颜色实际上是黑灰色,但看起来几乎是透明的。这是因为通过设定alpha=0.2将阴影部分的透明度设定为80%。注意,上面的绘图命令中geom_ribbon()函数的调用顺序在geom_line()函数之前,因而,折线被绘制在阴影区域上面的图层上。如果颠倒调用顺序的话,阴影区域的颜色有可能使折线模糊不清。在本例中,似乎这不成问题,这是因为本例中的阴影区域几乎是全透明的,但当阴影区域部分不透明时这个问题就很严重。除了使用阴影区域,还可以使用虚线来表示置信域的上下边界:
#使用虚线表示置信域的上下边界
ggplot(clim, aes(x=Year, y=Anomaly10y)) +
geom_line(aes(y=Anomaly10y-Unc10y), colour="grey50", linetype="dotted") + geom_line(aes(y=Anomaly10y+Unc10y), colour="grey50", linetype="dotted") +
geom_line()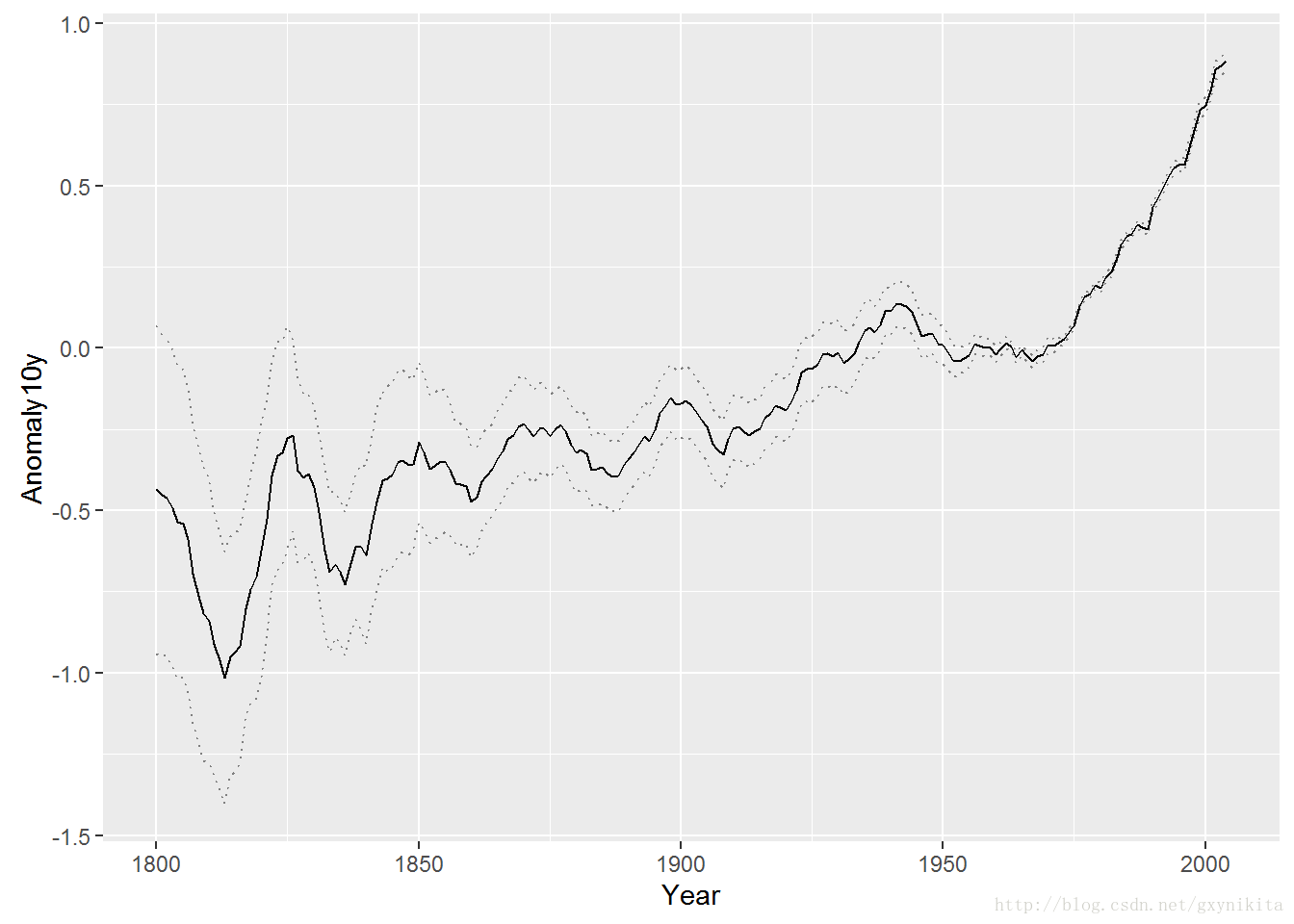
除了表示置信域之外,阴影区域还可以用来表示其他内容,比如两个变量之间的差值等。
在4.7节中的面积图中,阴影区域的y轴范围是0到y,而上图中y轴的范围是ymin到ymax。
本系列笔记所涉及的知识、数据等信息的版权归原书作者所有,请购买正版图书。O(∩_∩)O谢谢~
参考资料:R数据可视化手册
最后
以上就是心灵美硬币最近收集整理的关于R数据可视化手册笔记-Chapter4:折线图的全部内容,更多相关R数据可视化手册笔记-Chapter4内容请搜索靠谱客的其他文章。








发表评论 取消回复