NDSS
You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis
链接:https://www.ndss-symposium.org/wp-content/uploads/2020/02/24167-paper.pdf
第一章 简介
1.文中介绍了现阶段的恶意软件多采用免杀技术来防范安全软件的检测,如进程重命名、文件重命名等,一般的恶意软件会把payload直接存在盘上,而这种经过免杀处理的恶意软件会把恶意逻辑隐藏在受信任进程的内存空间中,或者将存到较少被关注的位置,例如 Windows 注册表或服务器配置中。
2.作者指出解决这一问题的方法是内核级(操作系统层面)的监控,不过需要解决两个问题,其中一个是恶意软件会注入到良性程序中,分类器需要能识别并隔离恶意进程和良性进程,第二个问题是如果对进程构建起源图,那么庞大的数据会变得难以存储和处理,作者解决的办法是只处理图中可疑的部分,其依据是大多数程序实例共享的起源图部分不太可能 是恶意的。
3.文章主要贡献如下:
(1)设计实现了 PROVDETECTOR,通过数据来源分析来检测恶意软件。 为了保证高检测精度和效率,提出了一种路径选择算法来识别进程起源图中的潜在恶意部分。
(2)设计了一种新颖的神经嵌入和机器学习管道,可自动为每个程序构建行为档案并识别异常过程。
第二章
1.列举了恶意软件使用良性程序来隐藏自己的例子,如内存代码注入,在 Microsoft Office 等良性文档中嵌入脚本以运行payload,利用良性软件的漏洞来实现攻击
2.列举了现阶段常用的检测防御方法,如内存扫描,使用白名单,加强对电子邮件的检查
3.展示了通过数据来源来还原恶意软件的攻击手段
良性程序:
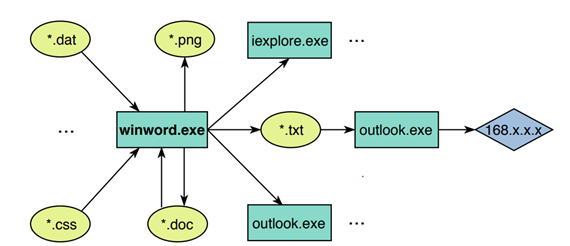
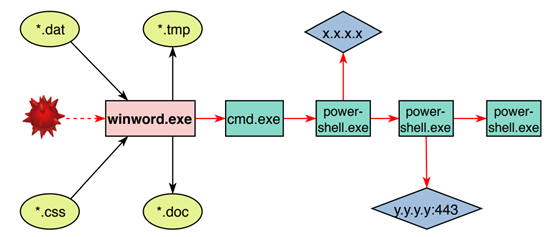
恶意软件:可以看到恶意软件会开多个powershell进程
第三章
1.作者列举了一些比较重要的系统实体以及定义

2.给定了一些实验成立的假设,如假设底层操作系统和出口跟踪器始终可信,假设攻击者无法操纵或删除记录,假设系统具有每个受监控程序的良性来源数据且所有进程的行为都可以被监视器捕获到
第四章
1.正式定义了几个概念
系统实体和系统事件:包括三种类型的系统实体:进程、文件和网络连接(即套接字)
系统事件 e = (src, dst, rel, time) 其中 src 是源实体,dst 是目标实体,rel 是它们之间的关系(例如,进程写入文件) , time 是事件发生时的时间戳。
系统来源图:给定系统中的进程 p(由其进程 ID 和主机标识),p 的系统起源图(或依赖图)是包含所有具有控制依赖(即开始或结束)或数据的系统实体的图对 p 的
依赖(即读或写)。形式上,p 的起源图定义为 G§ =< V, E >,其中 V 和 E 分别是顶点和边的集合。顶点 V 是系统实体,边 E 是系统事件。
第五章
1.为了识别隐藏的恶意软件进程,对分类器进行了如下设计:
仅学习良性进程数据
在起源图中使用因果路径,即把有因果依赖性的系统事件序列作为检测特征
仅学习起源图的因果路径的子集
2.作者设计了一种叫做PROVDETECTOR的软件来识别恶意软件进程,对于每个给定的流程,PROVDETECTOR 首先构建其来源图(图构建)。然后它从起源图中 选择路径的子集(特征提取)并将路径转换为数值向量(embedding)。之后,PROVDETECTOR 使用新颖性/ 异常值检测器来获得对嵌入向量的预测并报告其最终决定(如果进程已被劫持)(异常检测)。
3.来源图构建详细过程:给定一个流程实例 p(由其流程 ID 和主机标识),用存储在数据库中的数据将其来源图 G§ =< V, E > 构建为带标签的时间图。V 是系统实体,其标签是它们的属性,而 E 是边,其标签是关系和时间戳。V 中的每个节点都属于进程、文件或套接字的其中之一,定义E中的每条边为e = {src, dst, rel, time},起源图 G§ 的构建从 v == p 开始。然后将边 e 和它的源节点 src 和目标节点dst加入到图中
4.特征提取过程:因为图的大部分是良性的,所以不能把整个图作为特征,将图 G§ 中的因果路径 λ 定义为系统事件(或边)e1、e2、…的有序序列。其中满足条件
∀ei, ei+1 ∈ λ, ei.dst == ei+1.src,ei.time < ei+1.time.
5.路径选择,因为直接提取依赖路径会导致数量爆炸的问题,且之前提到的图中大部分内容是没有问题的,因此只需要找出图中不常见的几个路径就行,作者指出大多数程序都引用的数据或文件不太可能是恶意的,因此只需要查找稀有罕见的路径来确定生成自特定程序的数据文件。其中就需要计算因果路径 λ上不同事件e的分数R(e)
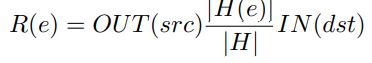
H(e) 是发生事件 e 的主机集合的数量,而 H 所有主机的集合的数量,把数据分为n个时间窗口T = {t1, t2, . . . , tn},其中如果在ti时间内如果没有新的入边加到v里则称时间ti是入稳定的,如果ti时间内没有新的出边加到v里则称时间ti是出稳定的,|T from| 是出边稳定的时间窗口数量,|T to|是入边稳定的时间窗口数量,|T|是时间窗口的总数量
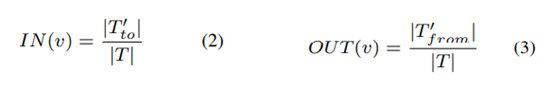
对于来源图 G,向所有入度为零的节点添加一个伪源节点 vsource,向所有出度为零的节点添加一个伪汇聚节点 vsink。 此过程将 G 转换为单源单汇流图 Gt。之后对每条边可以定义一个距离w(e)
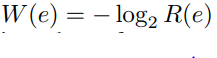
之后λ的长度可以通过公式计算
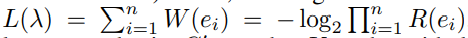
这样,G中的K个最长路径即是K个常规得分最低的路径(k个最不常见的路径)
6.embedding
1.作者提出存在以下问题,因果路径的长度不同,节点和边的标签是非结构化数据,如文件名或可执行路径。
2.作者提出的解决方案如下:将每个节点视为“名词”,将每条 边视为“动词”,并使用它们的标签形成表示路径的句子:Process:winword.exe write File:t1.txt read by Process:outlook.exe write Socket:168.x.x.x
3. 为了学习因果路径的嵌入向量,可以将路径作为句子的文档嵌入模型,形式上, 因果路径 λ 可以转换为一系列单词
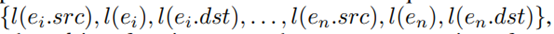
其中 l 是获取节点或边的文本表示的函数, 作者用可执行路径表示进程节点,用文件路径表示文件节点,用源或目标 IP 和端口表示套接字节点;用它的关系来表示一条边。作者使用了PV-DM 模型中的doc2vec 来学习路径的嵌入
4.异常检测使用局部异常因子(LOF)作为检测模型。 LOF 是一种基于 密度的方法。如果一个点的局部密度低于其邻居,则该点 被视为异常值。 LOF 不对数据的概率分布做任何假设, 也不用单一曲线将数据分开。
5.检测:使用基于阈值的方法来判断恶意程序,即如果超过 t 个嵌入向量被预测为恶意,则将来源图视为恶意,以最终决定来源图是良性还是恶意。
6.其他数据处理,如将C:/USERS/USER_NAME/DESKTOP/PAPER.DOC抽象为*:/USERS/*/DESKTOP/PAPER.DOC,对于套接字,删除了传出连接的源部分和传入连接的目标部分
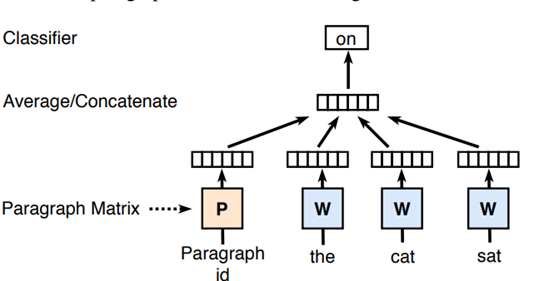
附:PV-DM (Distributed Memory Model of Paragraph Vectors) 是 doc2vec 的一个版本。 PV-DM 的核心思想是段落 p 可以表 示为另一个向量(即段落向量),有助于预测句子中的下一个单 词。在 PV-DM 模型中如图所示,每个段落都映射到一个段落向量,由段落矩阵中的一列表示,每个词都映射到一个词向量,由词矩阵中的一列表示。然后对段落向量和词向量进行平均或连接以预测上下文中的下一个词。上下文是固定长度的,并从段落 上的滑动窗口中采样。段落向量在从同一段落生成的所有上下文 中共享,但不跨段落共享。 PV-DM 模型使用随机梯度下降来训 练段落向量和词向量。经过训练的段落向量可以作为段落的特征。 在预测时,模型还使用梯度下降来计算新段落的段落向量。
总结:
1.图化是常用的建模手段,文中提出的图中的大部分都是良性的,因此不用把整张图作为特征,而是通过算法来筛选图中的指定部分。此外,被多次引用的数据文件可以判断为良性,也是一个实用的结论
2. 文中使用的embedding方法将图转化为向量输入到神经网络中,也有可取之处
3. 在训练模型时只使用了良性数据,结合了LOF指标,因为恶意样本较多且难以预测,因此只判断是否为良性,即采用类似白名单的方法来处理恶意样本的多变性
4. 对数据进行了预处理,将普通数据转化为抽象数据
最后
以上就是无语宝贝最近收集整理的关于论文阅读笔记-You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis的全部内容,更多相关论文阅读笔记-You内容请搜索靠谱客的其他文章。








发表评论 取消回复