HDFS基本操作
HDFS基本操作
1、运行HDFS看有什么东西。
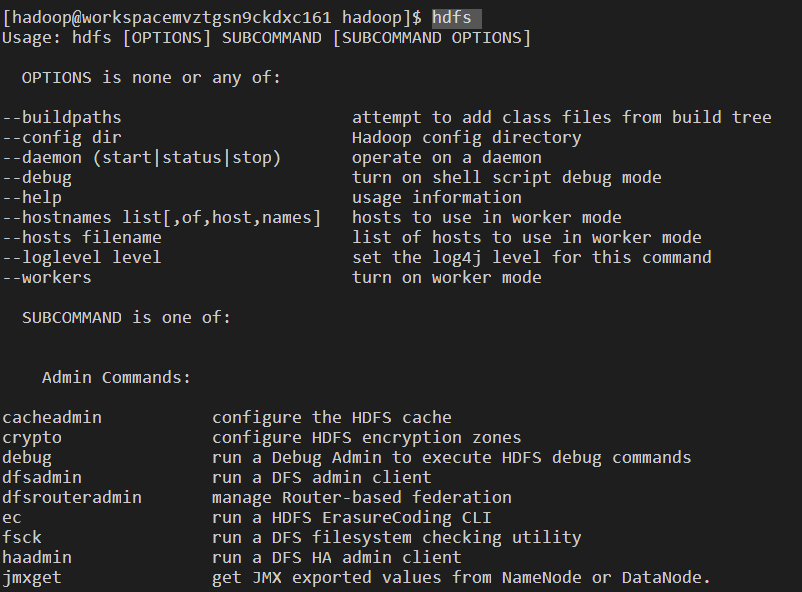
命令:hdfs
注:主要打印出三类命令,管理命令、客户端命令、管理守护进程命令。
2、命令:hdfs version
注:打印了Hadoop信息、源码信息、编译信息等。

3、命令:hdfs classpath
注:打印classpath

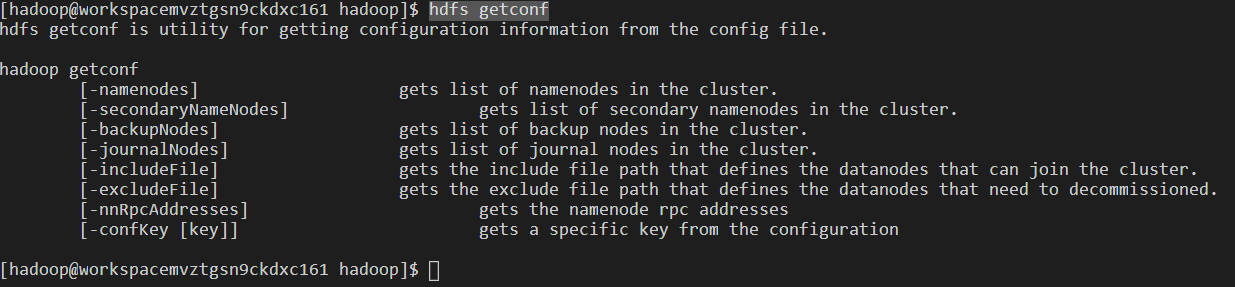
4、命令:hdfs getconf
注:打印getconf下的命令
5、打印namenode。
命令:hdfs getconf -namenodes
注:当前app-12为active.所以将app-12放前面。

6、命令:hdfs getconf -secondaryNameNodes
注:因为我们没有设置secondaryNameNodes,所以现在没有。

7、命令:hdfs getconf -journalNodes

8、命令:hdfs getconf -includeFile

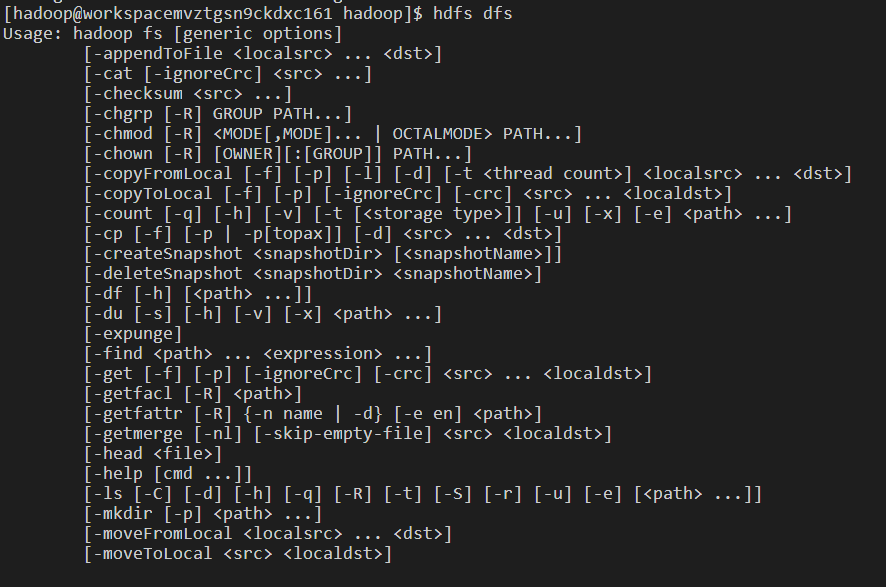
9、命令:hdfs dfs
注:对Linux系统文件的操作。
HDFS文件操作
10、在根目录下创建一个文件。
命令:hdfs dfs -mkdir /test2

11、将test/output/part-r-00000文件拷贝到test2下。
命令:hdfs dfs -cp /test/output/part-r-00000 /test2

12、查看是否拷贝成功。
命令:hdfs dfs -ls /test2

13、先查看本地目录和文件。
命令:pwd、ls

14、下载到本地目录下。
命令:hdfs dfs -get /test2/part-r-00000 ./、 ls

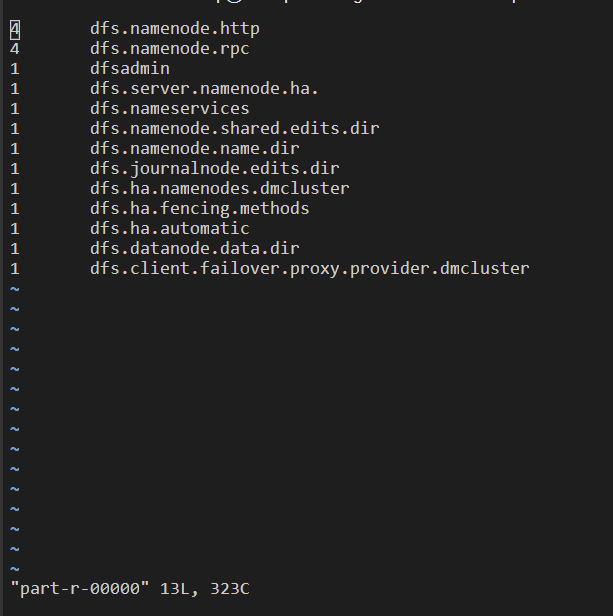
15、可以使用Linux命令查看改文件。
命令:vi part-r-00000

友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
最后
以上就是爱笑小馒头最近收集整理的关于余老师带你学习大数据-Spark快速大数据处理第三章第三节HDFS基本操作HDFS基本操作的全部内容,更多相关余老师带你学习大数据-Spark快速大数据处理第三章第三节HDFS基本操作HDFS基本操作内容请搜索靠谱客的其他文章。








发表评论 取消回复