刚学这本书,记录一下Linux系统一些操作,方便以后自己回顾学习。
1、首先启动hadoop

2、启动spark shell
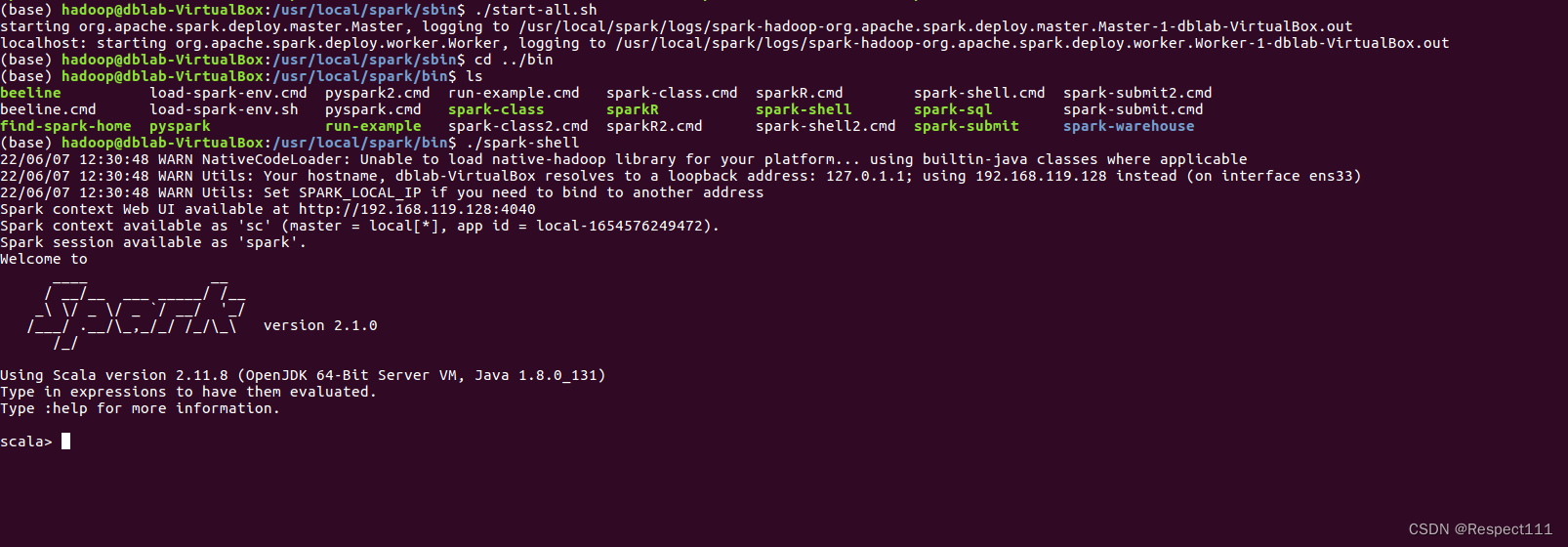
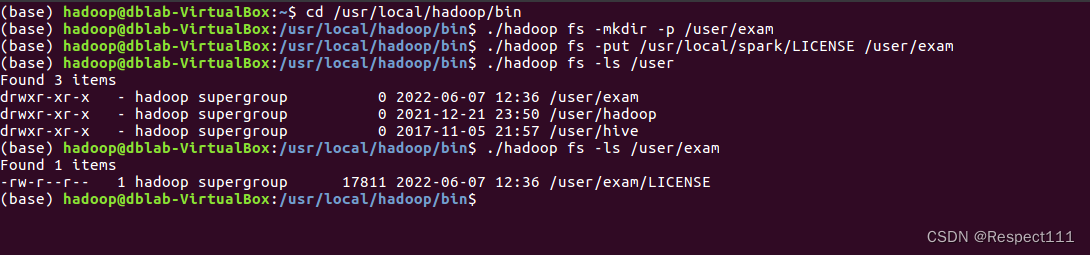
3、 在hdfs中创建多级目录/user/exam
并将/usr/local/spark中的LICENSE上传到hdfs中的user/exam中并检查是否已上传
4、然后继续在spark-shell界面操作
用spark-shell命令读取hdfs中user/exam/LICENSE文件并读取行数(这里网上有一些版本,最后运行了(“hdfs:///)需要三个斜线的是正确的。)
299行

5、 筛选出只包含(BSD)的行并输出行数

33行
6、对LICENSE进行词频统计

7、降序排列

8、保存到hdfs中的/user/exam/result中(代码打快了,result打成rseult了,但问题不大)

9、接下来在hdfs中操作。
对统计结果part-00000与part-00001合并到part-00002中

10、将合并结果part-00002下载到本地local中,但是这里下载会提示权限不够,因此需要给权限

777是最高权限,成功后就可以下载到本地了
11、下载到本地usr/local中

12、最后给倒叙合并结果显示一下
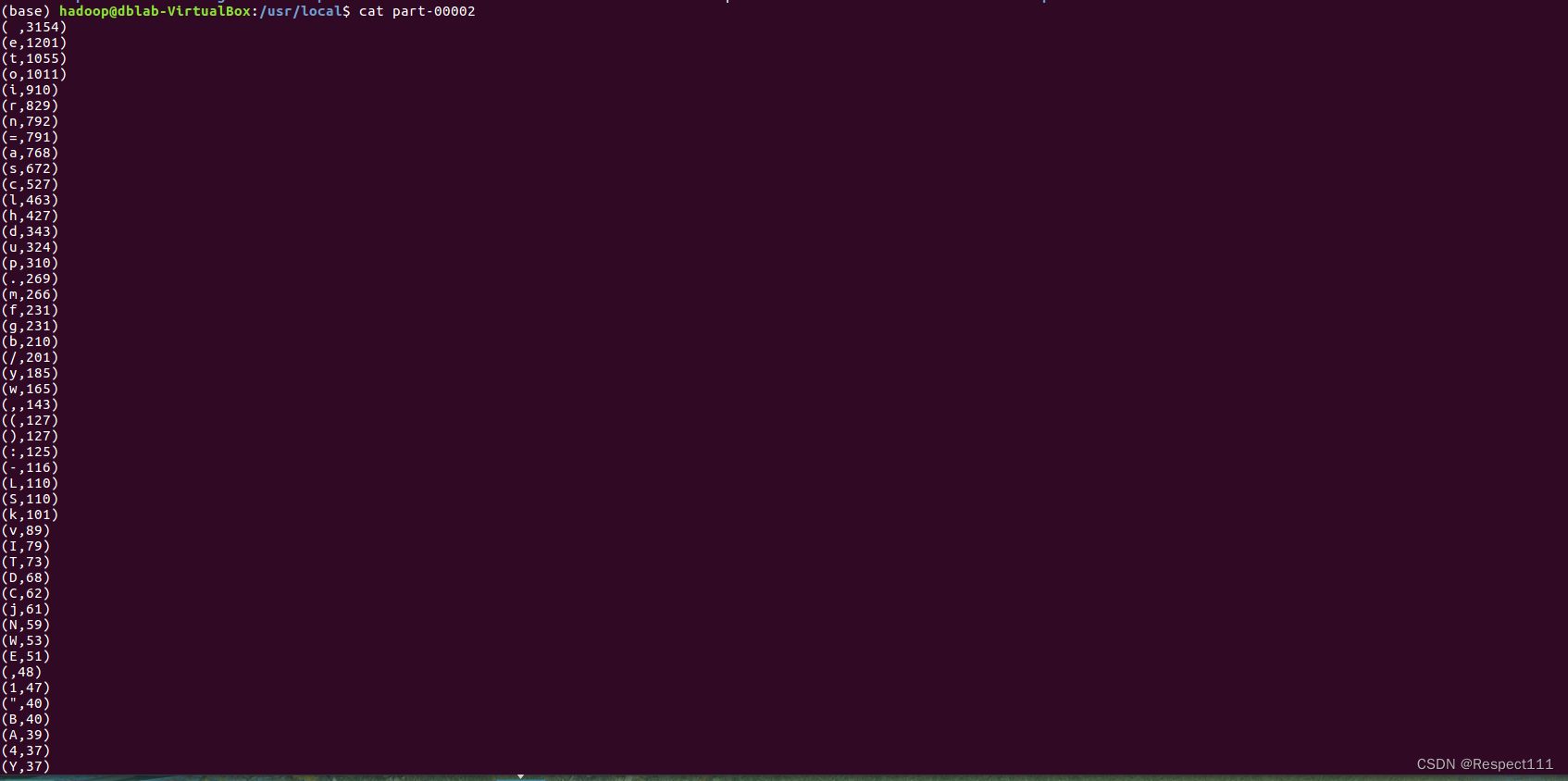

结束。。。。
最后
以上就是香蕉小松鼠最近收集整理的关于《大数据基础》关于hdfs与spark-shell的一些操作的全部内容,更多相关《大数据基础》关于hdfs与spark-shell内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复