
Spark的 bin目录下的spark-submit可被用于在集群上执行应用,他可被用于所有类型的cluster manager。
绑定Application的依赖
如果代码依赖其他工程,连同Application一起打包,使用maven或sbt。
并将Spark和Hadoop相关的依赖设置为provided:
...
...
...
provided
因为这些依赖在运行时由cluster manager提供。
使用spark-submit
./bin/spark-submit
--class
--master
--deploy-mode
--conf =
... # other options
[application-arguments]
常用选项:
--class:应用入口。
--master:master URL
--deploy-mode:部署驱动到worker node(cluster)或本地执行(client)。默认是client。
--conf:任意的Spark configuration键值对(key=value)形式的属性。
application-jar:打包的jar路径。这个URL必须对于集群是全局可见的。例如:hdfs:// path 或每个节点都有file://路径。
application-arguments:传给main函数的参数。
常用部署策略
1)从一台网关服务器提交应用,这台机器与集群中的机器处于同一位置,即为集群中的一台机器。这种部署方式适合client模式,driver程序作为集群的客户端在spark-submit线程内启动,应用程序的输入输出附加到控制台。这种模式特别适合REPL(Read-eval-print-loop,交互式解析器),例如Spark shell。
2)如果在远离集群的机器上提交应用(比如自己的笔记本电脑),使用cluster模式比较合适,这样可以使driver和executor间的网络延迟最小化。
Master URLs
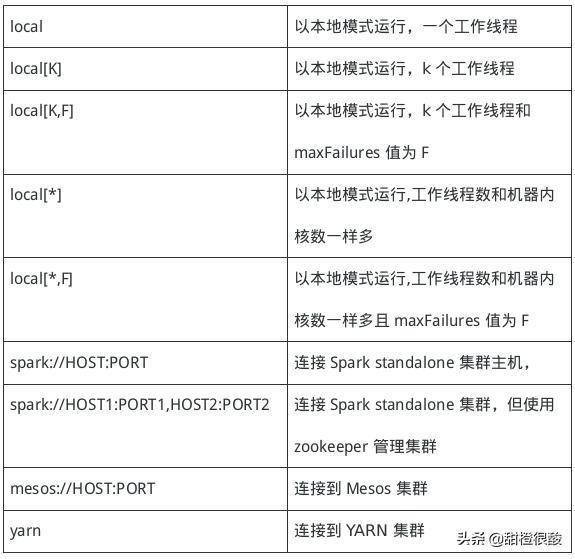
从一个文件加载配置
spark-submit脚本默认从配置文件加载配置值并传递给你的应用。默认读取spark目录下的conf/spark-defaults.conf。
加载默认配置可以免除通过spark-submit指定部分选项。例如配置文件中设置了spark.master,那么--master就不用指定了。一般,使用SparkConf设置的配置具有最高优先级,之后是spark-submit,最后才是默认配置。
如果不知道配置来自于哪,可以使用spark-submit到的--verbose选项打印调试信息。
高级依赖管理
使用spark-submit提交命令时,application jar连同--jars选项列表中的jar会自动传送到集群上,--jars后的多个url必须要用逗号分隔,这个列表会被包含到driver和executor路径中。--jars不支持目录形式。
Spark使用下面的URL模式:
1)file:--绝对路径,file:/URI通过driver的HTTP file server提供服务,每个executor都从driver的HTTP file server拉取文件
2)hdfs:, http:, https:, ftp:--每个executor都从指定的URL拉取文件
3)local:--存在于每个worker node上的本地文件,这意味着没有网络IO的影响,对于胖jar而言是一种理想的方式。
Jar和文件会被拷贝到executor节点(可能多个)的每个SparkContext的工作目录。这可能会占用大量的硬盘空间。YARN能够自动清理这些不再使用的文件。Spark standalone模式下可以通过配置spark.worker.cleanup.appDataTtl属性开启自动清理特性。
用户也能使用--packages,包含一个以逗号分隔的Maven坐标列表。坐标的格式为:groupId:artifactId:version。还可以使用--repositories添加依赖,多个依赖以逗号分隔。例如https://user:password@host/....,https://user:password@host/....
最后
以上就是魁梧大地最近收集整理的关于spark 显示hdfs 路径_大数据计算框架Spark之提交Application绑定Application的依赖的全部内容,更多相关spark内容请搜索靠谱客的其他文章。








发表评论 取消回复