数据挖掘 – 分类的模型评估度量
混淆矩阵 CM(Confusion Matrix)
| actual/precide | Yes | No | 合计 |
|---|---|---|---|
| Yes | TP | FN | P |
| No | FP | TN | N |
| 合计 | P^ | N^ | P+N 或者 P^ + N^ |
| 术语 | 含义 | 例子 |
|---|---|---|
| TP(True Postive) : | 正确 分类的 正元组 | buy_computer = yes 的元组,被分类器预测为 buy_computer = yes |
| TN(True Negative) : | 正确 分类的 负元组 | buy_computer = no 的元组,被分类器预测为 buy_computer = no |
| FP(False Postive) : | 错误 标记为 正元组 的负元组 | buy_computer = no 的元组,被分类器预测为 buy_computer = yes |
| FN(False Negative) : | 错误 标记为 负元组 的正元组 | buy_computer = yes 的元组,被分类器预测为 buy_computer = no |
度量
| 度量 | 公式 | 含义 |
|---|---|---|
| 准确率、识别率(accuracy) | T P + T N P + N frac{TP+TN}{P+N} P+NTP+TN | 正确分类元组 的占比 |
| 错误率、误分类率 (error rate / 1-accuracy) | F P + F N P + N frac{FP+FN}{P+N} P+NFP+FN | 错误分类元组 的占比 |
| 敏感度、真正例率、召回率( recall / sensitivity) | T P P frac{TP}{P} PTP | 正确识别的正元组 的占比 |
| 特效性、真负例率( specificity) | T N N frac{TN}{N} NTN | 正确识别的负元组 的占比 |
| 精度 (precision) | T P T P + F P frac{TP}{TP+FP} TP+FPTP | 标记为正类的元组实际为正类所占 的百分比 |
| F、F1、F分数 | 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l frac{2 * precision * recall}{precision+ recall} precision+recall2∗precision∗recall | 精度和召回率的调和均值(另一种使用precision和recall的方法) |
| F β F_β Fβ : β是非负实数 | ( 1 + β 2 ) ∗ p r e c i s i o n + r e c a l l β 2 ∗ p r e c i s i o n + r e c a l l frac{(1+β^2) *precision+ recall}{β^2*precision+ recall} β2∗precision+recall(1+β2)∗precision+recall | 也是 另一种使用precision和recall的方法 |
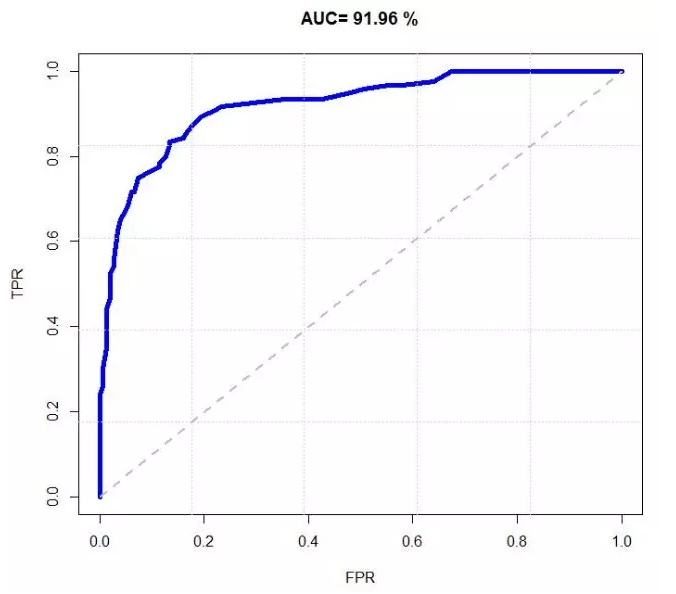
ROC
| 轴 | 含义 | 公式 |
|---|---|---|
| Y轴(TPR) | sensitivity / recall | T P P frac{TP}{P} PTP |
| X轴(FPR) | 1-specificity | F P N frac{FP}{N} NFP |
相关文章:
https://jingyan.baidu.com/article/63acb44acf685161fcc17ec9.html
https://www.plob.org/article/12476.html
相关图像

最后
以上就是粗犷热狗最近收集整理的关于数据挖掘 -- 分类的模型评估度量数据挖掘 – 分类的模型评估度量的全部内容,更多相关数据挖掘内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。



![[JavaScript] 解决JS小数相加、减、乘、除计算精度丢失的问题](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)




发表评论 取消回复