欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类和汇总,及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
- 本文是《hive学习笔记》系列的第六篇,前面的文章咱们对数据类型、表结构有了基本了解,接下来对常用的查询语句做一次集中式的学习;
- HiveQL与SQL类似, 在语法上与大部分SQL兼容, 但是并非完全兼容,例如更新、事务等都不支持,子查询和join操作也有限, 这和底层依赖Hadoop有关;
准备数据
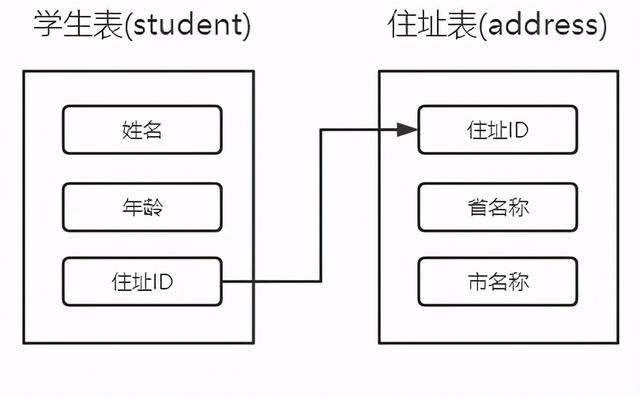
- 本次实战要准备两个表:学生表和住址表,字段都很简单,如下图所示,学生表有个住址ID字段,是住址表里的记录的唯一ID:
- 先创建住址表:
create table address (addressid int, province string, city string) row format delimited fields terminated by ',';- 创建address.txt文件,内容如下:
1,guangdong,guangzhou2,guangdong,shenzhen3,shanxi,xian4,shanxi,hanzhong6,jiangshu,nanjing- 加载数据到address表:
load data local inpath '/home/hadoop/temp/202010/25/address.txt' into table address;- 创建学生表,其addressid字段关联了address表的addressid字段:
create table student (name string, age int, addressid int) row format delimited fields terminated by ',';- 创建student.txt文件,内容如下:
tom,11,1jerry,12,2mike,13,3john,14,4mary,15,5- 加载数据到student表:
load data local inpath '/home/hadoop/temp/202010/25/student.txt' into table student;- 至此,本次操作所需数据已准备完毕,如下所示:
hive> select * from address;OK1guangdongguangzhou2guangdongshenzhen3shanxixian4shanxihanzhong6jiangshunanjingTime taken: 0.043 seconds, Fetched: 5 row(s)hive> select * from student;OKtom111jerry122mike133john144mary155Time taken: 0.068 seconds, Fetched: 5 row(s)- 开始体验HiveQL
select和where
最普通的带条件查询:
hive> select * from address where city like '%a%';OK1guangdongguangzhou3shanxixian4shanxihanzhong6jiangshunanjingTime taken: 0.128 seconds, Fetched: 4 row(s)group by
- 按province字段分组:
select province, count(*) from address group by province;该查询会触发MR计算,结果如下:
...Total MapReduce CPU Time Spent: 1 seconds 910 msecOKguangdong2jiangshu1shanxi2Time taken: 17.847 seconds, Fetched: 3 row(s)- 试试嵌套查询,内部是查出city字段带有a字母的记录,然后将这些记录按照province字段分组:
select t.province, count(*) from ( select * from address where city like '%a%') t group by t.province;结果如下:
Total MapReduce CPU Time Spent: 1 seconds 760 msecOKguangdong1jiangshu1shanxi2Time taken: 18.036 seconds, Fetched: 3 row(s)having
- 前面的嵌套查询,结果有两个省:guangdong和shanxi,如果再加个条件:只显示城市数量大于1的省,首先想到的是再加一层嵌套:
select t1.* from ( select t.province, count(*) as cnt from ( select * from address where city like '%a%' ) t group by t.province) t1 where t1.cnt>1; 结果如下,可见只有shanxi被显示了:
Total MapReduce CPU Time Spent: 2 seconds 250 msecOKshanxi2Time taken: 20.067 seconds, Fetched: 1 row(s)- 对于上述SQL,可以用having语法进行分组筛选,得到同样数据:
select t.province, count(*) as cnt from ( select * from address where city like '%a%' ) t group by t.province having cnt>1;order by
- 对分组结果做排序:
select t.province, count(*) as cnt from ( select * from address where city like '%a%' ) t group by t.province order by cnt;会触发MR,结果如下:
Total MapReduce CPU Time Spent: 3 seconds 50 msecOKjiangshu1guangdong1shanxi2Time taken: 40.315 seconds, Fetched: 3 row(s)- order by对于的实现,是在最后通过一个reducer进行全部排序,该过程可能耗时较长,针对这种情况,hive提供了sort by,功能与order by一样,但是会在每个reducer中进行排序,这样最终做排序的时候效率就会提升;
- 要注意的是:sort by解决的问题是最终结果排序的效率,因此数据量不大时,排序不是瓶颈,此时使用sort by也不会加快整体速度;
内连接(inner join)
- 与连接标准匹配的数据在两张表中都存在才会保留:
select s.name, s.age, a.province, a.city from student s inner join address a on s.addressid=a.addressid;结果如下:
Total MapReduce CPU Time Spent: 1 seconds 20 msecOKtom11guangdongguangzhoujerry12guangdongshenzhenmike13shanxixianjohn14shanxihanzhongTime taken: 17.294 seconds, Fetched: 4 row(s)自然连接(natural join)
- 自然连接是在两张表中寻找数据类型和列明都相同的字段,并自动连接起来:
select name, age, province, city from student natural join address;结果如下,可见不会根据student表的addressid字段值去address查找记录,而是将addrerss的记录全部连接一次:
Total MapReduce CPU Time Spent: 940 msecOKtom11guangdongguangzhoujerry12guangdongguangzhoumike13guangdongguangzhoujohn14guangdongguangzhoumary15guangdongguangzhoutom11guangdongshenzhenjerry12guangdongshenzhenmike13guangdongshenzhenjohn14guangdongshenzhenmary15guangdongshenzhentom11shanxixianjerry12shanxixianmike13shanxixianjohn14shanxixianmary15shanxixiantom11shanxihanzhongjerry12shanxihanzhongmike13shanxihanzhongjohn14shanxihanzhongmary15shanxihanzhongtom11jiangshunanjingjerry12jiangshunanjingmike13jiangshunanjingjohn14jiangshunanjingmary15jiangshunanjingTime taken: 18.525 seconds, Fetched: 25 row(s)左外连接(left outer join)
- 以连接中的左表为主:
select s.name, s.age, s.addressid, a.province, a.city from student s left outer join address a on s.addressid=a.addressid;结果如下,可见name=mary的记录,addressid等于5,在address中不存在addressid等于5的记录,因此province和city字段都展示了NULL,而在前面使用inner join时,结果中没有这条记录:
Total MapReduce CPU Time Spent: 950 msecOKtom111guangdongguangzhoujerry122guangdongshenzhenmike133shanxixianjohn144shanxihanzhongmary155NULLNULLTime taken: 18.442 seconds, Fetched: 5 row(s)右外连接(right outer join)
和左连接类似,只不过是以右表为主,语法是right outer join:
select s.name, s.age, s.addressid, a.province, a.city from student s right outer join address a on s.addressid=a.addressid;结果如下,可见city=nanjing的记录,在student表中没有一条记录与之关联,因此结果中展示了address的字段,而student的字段为NULL:
Total MapReduce CPU Time Spent: 970 msecOKtom111guangdongguangzhoujerry122guangdongshenzhenmike133shanxixianjohn144shanxihanzhongNULLNULLNULLjiangshunanjingTime taken: 18.294 seconds, Fetched: 5 row(s)全外连接(full outer join)
查询结果等于左外连接和右外连接之和,语法是full outer join:
select s.name, s.age, s.addressid, a.province, a.city from student s full outer join address a on s.addressid=a.addressid;结果如下:
Total MapReduce CPU Time Spent: 2 seconds 630 msecOKtom111guangdongguangzhoujerry122guangdongshenzhenmike133shanxixianjohn144shanxihanzhongmary155NULLNULLNULLNULLNULLjiangshunanjingTime taken: 22.189 seconds, Fetched: 6 row(s)- 至此,常用HiveQL体验完毕,希望能给您一些参考,接下来的章节会进一步学习HiveQL的特性;
欢迎关注我的公众号:程序员欣宸

最后
以上就是妩媚钥匙最近收集整理的关于hive 两个没有null指定的表左关联的结果有null_hive学习笔记之六:HiveQL基础欢迎访问我的GitHub本篇概览准备数据select和wheregroup byhavingorder by内连接(inner join)自然连接(natural join)左外连接(left outer join)右外连接(right outer join)全外连接(full outer join)欢迎关注我的公众号:程序员欣宸的全部内容,更多相关hive内容请搜索靠谱客的其他文章。








发表评论 取消回复