
俗话说,工欲善其事,必先利其器。在我看来,如何更好地提升Hive执行效率和理解Hive是与如何转化为MR过程是休戚相关的。过于简单的复用一套参数模板而不去深究具体参数的实现机理和相关适用场景很可能会是舍本逐末,更甚之,无故的增加集群负载,浪费队列资源,最终是负优化结果。因此,本文主要从Hive转MR过程的探索开始,再写一写自己对于优化HQL语句的想法与步骤。如果有一些意见或者补充,欢迎大家在评论区不吝赐教。
by:安辉
"
1
先磨一磨刀
Part 1Hive Architecture
下图是常见的Hive与Hadoop交互的架构:
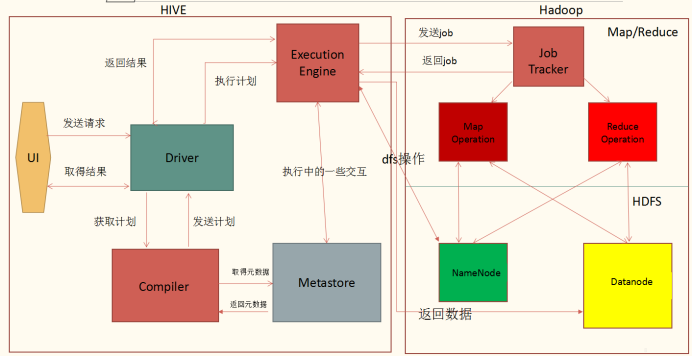
对于日常使用hive工具的分析师而言,看这样的架构我们只需要抓住如下四点:
 1.
hive是client-server模式,我们日常通过脚本beeline、hue连接到服务端(即hiveserver上),在服务端才进行任务的sql解析与编译。
2.
任务在编译的过程中,会不断与HMS(HiveMetastore)交互获取元数据(数据列信息、HDFS地址等),与HDFS交互获取实际数据。
编译完成后会将任务提交到yarn上进行执行,有时候可能会有local模式,会使用hiveserver所在的计算资源(如map join),执行完成后返回给hiveserver,最后返回给调用UI。
3.
基于1,实际上beeline、hue都可以理解为一个连接,只负责提交sql而已。数据提交后出现问题应该从hiveserver所在的机器进行排查,而不是提交任务的机器。
4.
基于2,编译阶段出现问题在hiveserver上进行排查,执行阶段在hdfs、yarn排查,执行完成后在hiveserver或调用UI(即beeline或hue等客户端)进行排查。
1.
hive是client-server模式,我们日常通过脚本beeline、hue连接到服务端(即hiveserver上),在服务端才进行任务的sql解析与编译。
2.
任务在编译的过程中,会不断与HMS(HiveMetastore)交互获取元数据(数据列信息、HDFS地址等),与HDFS交互获取实际数据。
编译完成后会将任务提交到yarn上进行执行,有时候可能会有local模式,会使用hiveserver所在的计算资源(如map join),执行完成后返回给hiveserver,最后返回给调用UI。
3.
基于1,实际上beeline、hue都可以理解为一个连接,只负责提交sql而已。数据提交后出现问题应该从hiveserver所在的机器进行排查,而不是提交任务的机器。
4.
基于2,编译阶段出现问题在hiveserver上进行排查,执行阶段在hdfs、yarn排查,执行完成后在hiveserver或调用UI(即beeline或hue等客户端)进行排查。
架构只是给我们一个基本的概念,让我们在使用的过程中知道问题出现在哪个组件上,提供一个简单的排查思路,而对于更日常的优化,则需要我们对于hql中常用的几个算子如何转化为MR作业有更进一步的了解。

Part 2
常用算子如何转化为MR
我们日常使用过程中,最常用的操作算子主要有:join、group by、distinct。因此我主要介绍这几种操作算子,其他的算子其实都可以类比出来。每种算子MR转化过程其实都可以总结为三个步骤:数据读入(read)和筛选(filter)、排序(sort)、整合(summary)
1. Join -> MR
我们看这样一个语句: select user.name, rom.version from user join rom > 其转MR过程如下图所示: 由上图我们可以看出,map阶段根据数据做一个初始化标记,并在sort阶段根据这个标记进行筛选排序,最后通过reduce进行整合。
由上图我们可以看出,map阶段根据数据做一个初始化标记,并在sort阶段根据这个标记进行筛选排序,最后通过reduce进行整合。
2. Group by -> MR
同样对应Hql语句如下: select count(*), user.name, user.region from user group by region, name; (这里我们为了更容易理解一般情况,因此group by了两列,一列其实更简单一点,可以类比出来) 其转MR过程如图: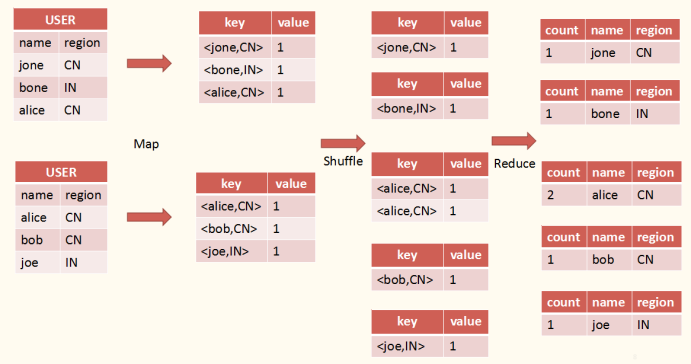 上图看起来貌似比join复杂了许多,但其实还是一个map阶段的初始化标记,只不过这次将两个值作为key值进行标记,然后在sort阶段进行筛选排序,最后在reduce阶段进行整合。
上图看起来貌似比join复杂了许多,但其实还是一个map阶段的初始化标记,只不过这次将两个值作为key值进行标记,然后在sort阶段进行筛选排序,最后在reduce阶段进行整合。
3. Dinstinct -> MR
Hql语句: select user.region, count(distinct user.id) num from user group by region; 其转MR过程如图所示: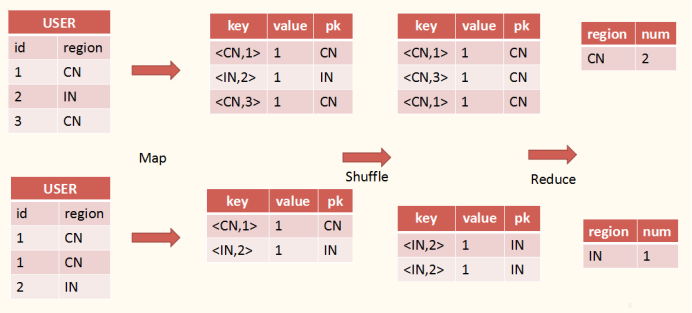 这里的distinct与前边的转化稍有所不同,对id进行distinct操作需要在reduce阶段保留id值,因此这里通过新增一列,pk(partition key)来存储shuffle的key。通过比对key值
(这里比对不需要进行转hash操作,可以抽key值的last key值,比较即可)
来做distinct操作。对于其他的avg等操作都是类似的。
这里的distinct与前边的转化稍有所不同,对id进行distinct操作需要在reduce阶段保留id值,因此这里通过新增一列,pk(partition key)来存储shuffle的key。通过比对key值
(这里比对不需要进行转hash操作,可以抽key值的last key值,比较即可)
来做distinct操作。对于其他的avg等操作都是类似的。
4. Multi Distinct -> MR
我们看这样一个语句: select user.region, count(distinct user.id) id_num, count(distinct user.name) name_num from user group by region; 其转MR可以有两种方法: 第一种还是和单个distinct一样,保留id和name加入到key里,但在reduce阶段比较时,不能通过last key值比较了 (因为有两个) ,只能将key转化为hash值进行比较; 第二种方法实际上是在map阶段做操作,将每列的值根据所属列进行编号组合成key,然后在reduce阶段都是同理操作,如下图所示: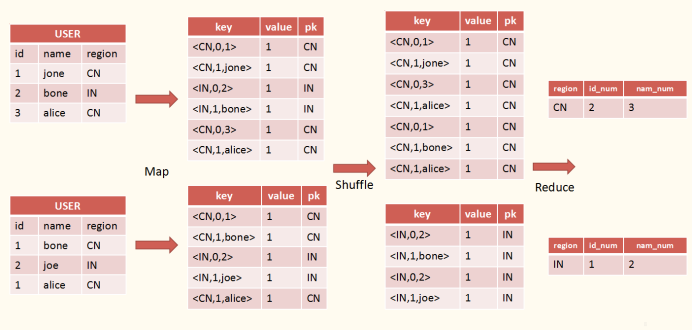 如distinct列中,我们将id列编号为1,name列编号为2。在map阶段将每行映射为的方式。
这样在reduce则仍旧可以按照在只有一个distinct的时候一样比对last key值,免去了转hash值的操作,减少了reduce计算时间,但相应在map阶段生成了m*n行数据(m为初始行数,n为distinct列),增大了shuffle数据量。
如distinct列中,我们将id列编号为1,name列编号为2。在map阶段将每行映射为的方式。
这样在reduce则仍旧可以按照在只有一个distinct的时候一样比对last key值,免去了转hash值的操作,减少了reduce计算时间,但相应在map阶段生成了m*n行数据(m为初始行数,n为distinct列),增大了shuffle数据量。
2
该怎么砍柴?
磨刀的手法说来说去也就一种,但砍柴却不一样,不同的树有不同的砍法,横劈or竖切,多大角度,怎样的姿势,不一而足。

因此我们就要从上述原理上总结出来什么阶段最有可能会花费时间,然后针对不同的阶段尽可能找一些通解。本文主要总结出了以下几种可能会消耗时间的阶段。
Part 1map&reduce阶段计算时间
这两个阶段的计算时间主要和数据量、瓶颈节点的计算时间有关系。

如果输入数据量很大,但是map数量、reduce数量很少,那么节点平均执行时间就会拉长,进而导致任务总执行时间变长,甚至会出现节点因为过大的数据量OOM。在这样的情况下,我们就应该尝试通过参数设置增大map数量和reduce数量来提高任务并行度,减少执行时间。
map数量如:
mapreduce.input.fileinputformat.split.maxsize
reduce数量如:
hive.exec.reducers.max、hive.exec.reducers.bytes.per.reducer
而对于瓶颈节点的计算时间,其实就是我们常说的数据倾斜问题。数据倾斜问题常见于reduce阶段。
Q为什么见于reduce阶段而不是map阶段?

reduce阶段出现数据倾斜,就是因为通过partition key不均匀,分发到不同reduce节点执行的数据量差异很大。
那么我们要解决数据倾斜,就只能通过拆分不均匀partition key值来解决。hive自带了skew优化参数,其先会遍历表,取出skew值;接着将skew值通过map join的方式计算(map join没有reduce阶段,所以不会有倾斜)
skew优化参数:
hive.optimize.skewjoin/hive.skewjoin.key/hive.skewjoin.mapjoin.map.tasks/hive.skewjoin.mapjoin.min.split
最后将原来的计算和map join结果通过union的操作整合。但hive自带的参数在很多情况下会失效。如果参数失效的话,我们可能需要通过其他方式来解决:如将任务转化为map join,取消reduce执行步骤;倾斜值单独拿出来进行计算;设置随机数算法、通过distribute by操作分拆不均匀partition key等。
Part 2shuffle阶段数据量聚合与传输
shuffle阶段需要访问所有map落盘的中间结果,并将中间结果根据partition key值分发给不同的reduce进行执行。
因此要减少shuffle阶段的时间消耗,我们需要从减少需要访问的map数量、减少shuffle数据量大小的角度入手。减少访问的map数量可以通过参数(mapreduce.input.fileinputformat.split.maxsize)来解决。但这里就会和上边的计算时间需要整合起来进行考虑,怎样的参数值设置会是最优的结果。

减少数据生成量大小可以通过尽可能在sql编写的过程中不要引入不必要的列,启用中间结果压缩(mapreduce.map.output.compress、mapreduce.map.output.compress.codec)等来进行解决。
这里需要注意的是,启用了中间结果压缩,会减少磁盘IO和网络IO时间,但相应会增长reduce端的计算时间,最终是否启用还需要在实际中反复尝试。
Part 3job的生成与调起
yarn调度机器进行MR任务计算时间消耗也是一大可以进行优化的地方。

我们知道,一个Hive SQL在编译完成后可能生成多个MR任务(一般任务生成个数和这几个算子有关系:join、group by、order by),而我们要减少多个MR任务,就首先需要看看我们的hql语句是否可以减少一些算子,从而减少MR任务数量。
如果hql语句无法再进行优化的话,看看是否符合correlation关系,通过设置参数hive.optimize.correlation来进行优化
(correlation也是一块比较大的内容,这里边写篇幅太多,大家如需了解,可以查看参考链接)
3
日常运维规则
上述虽然讲了一些优化时可以考虑的方面,但大家也许会觉得没有一个具体的数据,没有一个普遍的参数模板来使用。
但确实就是这样,没有办法归纳出一个通解的模板,不同的任务根据本身包含的数据、数据量的大小、sql的书写,都有不同的优化模式。我们要进行任务的优化,也只能是对该任务依据上述几个可以考虑的方面:反复对任务进行调试、执行、调试、执行,进而进行优化。
另外上述只罗列了常用的一些参数,但实际上还有很多参数的设置基本都离不开上述几个方面,更多的参数可能还需要大家的日常积累。下边几点主要是根据我日常运维的问题想的一些规则:
Part 1 map join优先性能用map join的,尽量用map join。这里主要需要注意的是map join的小表一定是数据量不能太大,不然可能会导致hiveserver OOM,影响其他人的任务。
另外join的key的数量也不能过多,因为通过map join,一个map会根据key的值生成多个文件,如果一次map join有1w个map,join的key值有10个,那么在计算过程中总共会在hdfs生成1w*10=10w个文件,这对hdfs的影响是很大的。
Part 2 默认参数的基础上调整尽量先试用默认参数提交任务,当默认参数有问题时,在默认参数的基础上通过逐步调整的方式(比如放大一倍或者缩小一倍,再到两倍)进行优化。
Part 3 参数调整是相互影响的参数调整是相互影响的,比如减少map数量会减少并行度,但相应减少数据聚合时间。
因此在优化过程中讲究抓大去小,查看当前任务执行到底是map阶段、shuffle阶段还是reduce阶段消耗时间长,优先优化时间占比高的部分,例如如果shuffle时间很短,那么就可以适当放大map数量。
Part 4 OOM操作任务OOM后,先查看是map阶段OOM还是reduce阶段OOM,然后进行相应调整,切忌两个都增大这种操作:在调整过程中,先通过增加map或reduce的数量来看问题是否得到解决,如果大幅增加了数量仍旧无法解决时再尝试增大内存。
Part 5 长远的考虑表在一开始设计阶段就要有长远的考虑,这一点其实很重要。比如如果一开始就知道倾斜值会是什么,那么就应该通过skew by来指定。这样下游任务在使用这张表作为输入时,就很大概率不会出现数据倾斜问题。
partition设置层级也要合理,按照访问频次(尽量就是日期),更不能太深(如超3层,甚至到5层是严厉禁止的);还有bucket、表尽量用orc格式(在hiveserver编译过程中,orc格式的文件可以提供很多很好的统计数据给hiveserver进行物理计划优化)等多种操作来对表优化。
Part 6 任务执行切勿过多任务执行设置压缩、文件生成数量不要过多(hive.merge.mapredfiles)来缓解集群压力。

参考文献:
【1】美团技术团队:Hive SQL的编译过程
http://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
【2】correlation optimization
https://cwiki.apache.org/confluence/display/Hive/Correlation+Optimizer
来源 | 安辉
编辑 | sea
排版 | sea
▼
往期精彩回顾
▼
大数据时代,列式优化或许能给我们新的思考




最后
以上就是无聊心情最近收集整理的关于hive 如何计算百分比_Hive转MR过程初窥&优化探索的全部内容,更多相关hive内容请搜索靠谱客的其他文章。








发表评论 取消回复