1. Join 的基本原理
大家都知道,Hive 会将所有的 SQL 查询转化为 Map/Reduce 作业运行于 Hadoop 集群之上。在这里简要介绍 Hive 将 Join 转化为 Map/Reduce 的基本原理。
假定有 user 和 order 两张表,分别如下:
user 表:
| sid | name |
|---|---|
| 1 | apple |
| 2 | orange |
order 表:
| uid | orderid |
|---|---|
| 1 | 1001 |
| 1 | 1002 |
| 2 | 1003 |
现在想做 student 和 sc 两张表上的连接操作:
SELECT
u.name,
o.orderid
FROM user u
JOIN order o ON u.uid = o.uid;
Hive 是利用 hadoop 的 Map/Reduce 计算框架执行上述查询的呢??
Hive 会将出现在连接条件 ON 之后的所有字段作为 Map 输出的 key,将所需的字段作为 value,构建(key, value),同时为每张表打上不同的标记 tag,输出到 Reduce 端。在 Reduce 端,根据 tag 区分参与连接的表,实现连接操作。
我们使用下图来模拟这个过程:
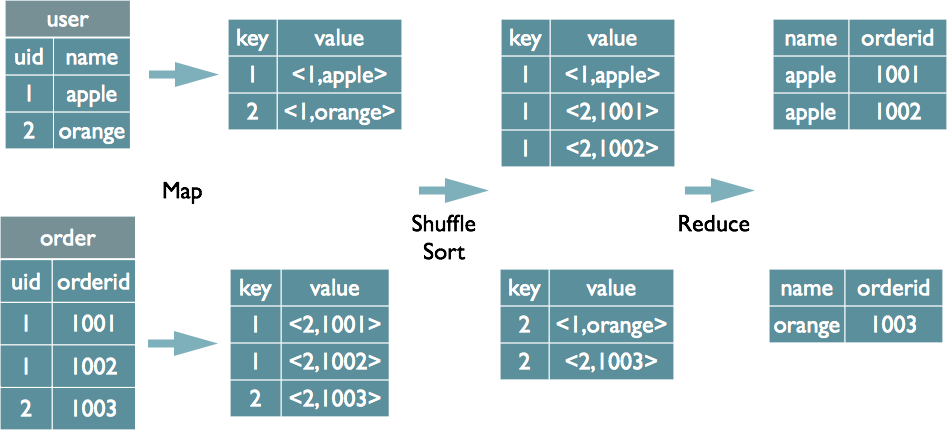
在 Map 端分别扫描 user 和 order 的两张表。对于 user 表,在连接条件 ON 之后的字段为 uid,所以以 uid 作为 Map 输出的 key,在 SELECT 语句中还需要 name 字段,所以 name 字段作为 value 的一部分,同时为 user 表赋予标记 tag=1,这样处理 user 表的 mapper 地输出形式为:(uid, “1” + name)。类似的,处理 order 表的 mapper 地输出形式为:(uid, “2” + orderid),注意,order 表的标记为 2。
具有相同 uid 的地(key, value)字段在 reduce 端“集合”,根据 value 中 tag 字段区分来自不同表的数据,使用两层循环完成连接操作。
上面就是将 Join 操作转换为 Map/Reduce 作业的基本原理: 在 map 端扫描表,在 reduce 端完成连接操作。
2. Hive 中的各种 Join
写在前面的话:”Hive 不支持非等值连接”
我们使用例子讲述各种 Join 的区别。假设 my_user 和 my_order 两张表的数据变为:
my_user 表:
| uid | name |
|---|---|
| 1 | apple |
| 2 | orange |
| 3 | banana |
my_order 表:
| uid | orderid |
|---|---|
| 1 | 1001 |
| 1 | 1002 |
| 2 | 1003 |
| 2 | 1003 |
| 4 | 2001 |
注意,my_order 中有一条重复记录。
“不要考虑例子在现实中的意义,这里这是为了演示各种 JOIN 的区别”
2.1 INNER JOIN
INNER JOIN,又称“内连接”,执行 INNER JOIN 时,只有两个表中都有满足连接条件的记录时才会保留数据。执行以下语句:
SELECT
u.name,
o.orderid
FROM my_user u
JOIN my_order o ON u.uid = o.uid;
结果为:
| name | orderid |
|---|---|
| apple | 1001 |
| apple | 1002 |
| orange | 1003 |
| orange | 1003 |
因为表 my_order 中又重复记录,所以结果中也有重复记录。
2.2 LEFT OUTER JOIN
LEFT OUTER JOIN(左外连接),JOIN 操作符左边表中符合 WHERE 条件的所有记录都会被保留,JOIN 操作符右边表中如果没有符合 ON 后面连接条件的记录,则从右边表中选出的列为 NULL。
执行以下语句:
SELECT
u.name,
o.orderid
FROM my_user u
LEFT OUTER JOIN my_order o ON u.uid = o.uid;
结果为:
| name | orderid |
|---|---|
| apple | 1001 |
| apple | 1002 |
| orange | 1003 |
| orange | 1003 |
| banana | NULL |
这里由于没有 WHERE 条件,所以左边表 my_user 中的记录都被保留,对于 uid=3 的记录,在右边表 my_order 中没有相应记录,所以 orderid 为 NULL。
2.3 RIGHT OUTER JOIN
RIGHT OUTER JOIN(右外连接),LEFT OUTER JOIN 相对,JOIN 操作符右边表中符合 WHERE 条件的所有记录都会被保留,JOIN 操作符左边表中如果没有符合 ON 后面连接条件的记录,则从左边表中选出的列为 NULL。
SELECT
u.name,
o.orderid
FROM my_user u
RIGHT OUTER JOIN my_order o ON u.uid = o.uid;
执行上面 SQL 语句的结果为:
| name | orderid |
|---|---|
| apple | 1001 |
| apple | 1002 |
| orange | 1003 |
| orange | 1003 |
| NULL | 2001 |
由于左表 my_user 中不存在 uid=4 的记录,所以 orderid=2001 的记录对应的 name 为 NULL。
2.3 FULL OUTER JOIN
结合上面的 LEFT OUTER JOIN 和 RIGHT OUTER JOIN,很容易想到 FULL OUTER JOIN 的运行机制:保留满足 WHERE 条件的两个表的数据,没有符合连接条件的字段使用 NULL 填充。来看一个例子:
SELECT
u.name,
o.orderid
FROM my_user u
FULL OUTER JOIN my_order o ON u.uid = o.uid;
执行结果为:
| name | orderid |
|---|---|
| apple | 1001 |
| apple | 1002 |
| orange | 1003 |
| orange | 1003 |
| banana | NULL |
| NULL | 2001 |
原因不再解释,请自行思考。
2.4 LEFT SMEI JOIN
在早期的 Hive 版本中,不是 IN 关键字,可以使用 LEFT SEMI JOIN 实现类似的功能。
LEFT SEMI JOIN(左半开连接)返回左边表的记录,前提是右边表具有满足 ON 连接条件的记录。
先来看一个例子:
SELECT
*
FROM my_user u
LEFT SEMI JOIN my_order o ON u.uid = o.uid;
执行结果为:
| uid | name |
|---|---|
| 1 | apple |
| 2 | orange |
虽然 SELECT 中使用’*‘,但是只返回了左表 my_user 的列,而且重复的记录没有返回(重复记录在 my_order 表中)
需要强调的是:
- 在 LEFT SEMI JOIN 中,SELECT 中不允许出现右表中的列
- 对于左表中的一条记录,在右表表中一旦找到匹配记录就停止扫描
3. JOIN 优化
现实环境中会进行大量的表连接操作,而且表连接操作通常会耗费很懂时间。因此掌握一些基本的 JOIN 优化方法成为熟练运用 Hive、提高工作效率的基本手段。下面讨论一些常用的 JOIN 优化方法。
3.1 MAP-JOIN
本文一开始介绍了 Hive 中 JOIN 的基本原理,这种 JOIN 没有数据大小的限制,理论上可以用于任何情形。但缺点是:需要 map 端和 reduce 端两个阶段,而且 JOIN 操作是在 reduce 端完成的,称为 reduce side join。
那么,能否省略 reduce 端,直接在 map 端执行的“map side join”操作呢??答案是,可以的。
但有个条件,就是:连接的表中必须有一个小表足以放到每个 mapper 所在的机器的内存中。
下图展示了 map side join 的原理。
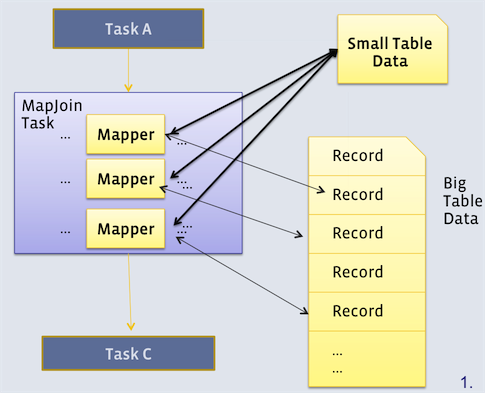
从上图中可以看出,每个 mapper 都会拿到小表的一个副本,然后每个 mapper 扫描大表中的一部分数据,与各自的小表副本完成连接操作,这样就可以在 map 端完成连接操作。
那多大的表才算是“小表”呢??
默认情况下,25M 以下的表是“小表”,该属性由hive.smalltable.filesize决定。
有两种方法使用 map side join:
- 直接在 SELECT 语句中指定“小表”,语法是/+MAPJOIN (tbl)/,其中 tbl 就是要复制到每个 mapper 中去的小表。例如:
SELECT
/*+ MAPJOIN(my_order)*/
u.name,
o.orderid
FROM my_user u
LEFT OUTER JOIN my_order o ON u.uid = o.uid;
- 设置
hive.auto.convert.join = true,这样 hive 会自动判断当前的 join 操作是否合适做 map join,主要是找 join 的两个表中有没有小表。
但 JOIN 的两个表都不是“小表”的时候该怎么办呢??这就需要 BUCKET MAP JOIN 上场了。
3.2 BUCKET MAP JOIN
Map side join 固然得人心,但终会有“小表”条件不满足的时候。这就需要 bucket map join 了。
Bucket map join 需要待连接的两个表在连接字段上进行分桶(每个分桶对应 hdfs 上的一个文件),而且小表的桶数需要时大表桶数的倍数。建立分桶表的例子:
CREATE TABLE my_user
(
uid INT,
name STRING
)
CLUSTERED BY (uid) into 32 buckets
STORED AS TEXTFILE;
这样,my_user 表就对应 32 个桶,数据根据 uid 的 hash value 与 32 取余,然后被分发导不同的桶中。
如果两个表在连接字段上分桶,则可以执行 bucket map join 了。具体的:
- 设置属性
hive.optimize.bucketmapjoin= true控制 hive 执行 bucket map join; - 对小表的每个分桶文件建立一个 hashtable,并分发到所有做连接的 map 端;
- map 端接受了 N(N 为小表分桶的个数) 个小表的 hashtable,做连接 操作的时候,只需要将小表的一个 hashtable 放入内存即可,然后将大表的对应的 split 拿出来进行连接,所以其内存限制为小表中最大的那个 hashtable 的大小
3.3 SORT MERGE BUCKET MAP JOIN
对于 bucket map join 中的两个表,如果每个桶内分区字段也是有序的,则还可以进行 sort merge bucket map join。对于那个的建表语句为:
CREATE TABLE my_user
(
uid INT,
name STRING
)
CLUSTERED BY (uid) SORTED BY (uid) into 32 buckets
STORED AS TEXTFILE;
这样一来当两边 bucket 要做局部 join 的时候,只需要用类似 merge sort 算法中的 merge 操作一样把两个 bucket 顺序遍历一遍即可完成,这样甚至都不用把一个 bucket 完整的加载成 hashtable,而且可以做全连接操作。
进行 sort merge bucket map join 时,需要设置的属性为:
1. `set hive.optimize.bucketmapjoin= true;`
2. `set hive.optimize.bucketmapjoin.sortedmerge = true;`
3. `set hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;`
4.各种 JOIN 对比
| JOIN类型 | 优点 | 缺点 |
|---|---|---|
| COMMON JOIN | 可以完成各种 JOIN 操作,不受表大小和表格式的限制 | 无法只在 map 端完成 JOIN 操作,耗时长,占用更多地网络资源 |
| MAP JOIN | 可以在 map 端完成 JOIN 操作,执行时间短 | 待连接的两个表必须有一个“小表”,“小表”必须加载内存中 |
| BUCKET MAP JOIN | 可以完成 MAP JOIN,不受“小表”限制 | 表必须分桶,做连接时小表分桶对应 hashtable 需要加载到内存 |
| SORT MERGE BUCKET MAP JOIN | 执行时间短,可以做全连接,几乎不受内存限制 | 表必须分桶,而且桶内数据有序 |
参考
本文转载自:http://datavalley.github.io/2015/10/25/Hive%E4%B9%8BJOIN%E5%8F%8AJOIN%E4%BC%98%E5%8C%96
最后
以上就是外向冬瓜最近收集整理的关于Hive学习笔记(五)—Hive连接优化1. Join 的基本原理2. Hive 中的各种 Join3. JOIN 优化3.1 MAP-JOIN3.2 BUCKET MAP JOIN4.各种 JOIN 对比的全部内容,更多相关Hive学习笔记(五)—Hive连接优化1.内容请搜索靠谱客的其他文章。








发表评论 取消回复