hive部署是在基于hadoop环境下实现的,为了节省资源,这里部署伪分布式版hadoop
一、hadoop部署
1、hadoop软件包下载路径:https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
2、创建hadoop用户useradd hadoop
3、jdk环境准备
①jdk下载:https://github.com/alibaba/dragonwell8/releases
https://cn.azul.com/downloads/zulu-community/?&architecture=x86-64-bit&package=jdk
https://developers.redhat.com/products/openjdk/download
https://www.cnblogs.com/xifengxiaoma/category/1262706.html
②解压jdk包:tar -xf jdk-8u181-linux-x64.tar.gz
③修改配置文件.bash_profile: vim .bash_profile
export PATH
export JAVA_HOME=/home/hadoop/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
④执行命令:source .bash_profile
⑤查看是否生效:

4、解压hadoop软件包:
![]()
5、配置文件修改:
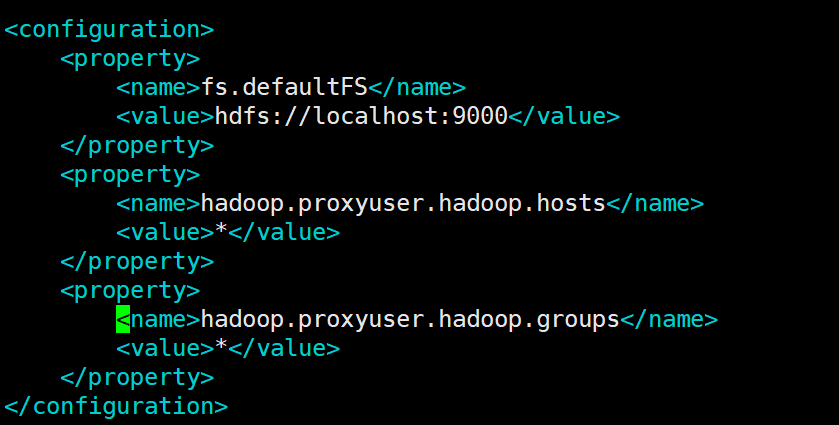
①修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
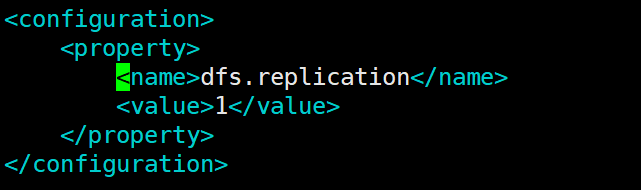
②修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
③新增slaves文件

6、初次启动需进行初始化
./bin/hdfs namenode -format
7、伪分布式需对自己免密登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
8、启动namenode和datanode:
./sbin/start-dfs.sh
9、查看hadoop运行情况
http://localhost:50070/
二、hive部署
1、hive软件包下载:http://mirror.bit.edu.cn/apache/hive/hive-2.3.6/
2、解压包:tar -xf apache-hive-2.3.6-bin.tar.gz
3、配置环境变量:vim .bash_profile
export HIVE_HOME=/home/hadoop/apache-hive-2.3.6-bin
export PATH=$HIVE_HOME/bin:$PATH

4、需要下载mysql数据库连接包:mysql-connector-java-5.1.46.jar 放入lib目录中
5、修改配置文件
①执行cp hive-default.xml.template hive-site.xml 并修改hive-site.xml文件
替换变量${system:java.io.tmpdir} 替换为tmp目录的路径,tmp没有则手动创建
:%s${system:java.io.tmpdir}//home/hadoop/apache-hive-2.3.6-bin/tmp/g
替换变量${system:user.name} 替换为tmp目录下的一个自定义目录,手动创建hive目录
:%s${system:user.name}/hive/g
修改mysql连接信息
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.0.1:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
修改mysql连接方式
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
修改mysql连接用户名
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
修改mysql连接密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456789</value>
<description>password to use against metastore database</description>
</property>
②执行命令:cp hive-env.sh.template hive-env.sh 并修改配置文件hive-env.sh
添加一行配置,指明hadoop路径
export HADOOP_HOME=/home/hadoop/hadoop-2.7.6
6、初始化hive
①在bin目录下执行 hive --service metastore&
②执行schematool -dbType mysql -initSchema初始化
7、启动hive
在bin目录下执行 hive --service hiveserver2 &
8、开启hive客户端
在bin目录下执行 hive 命令
最后
以上就是优秀小鸭子最近收集整理的关于hadoop,hive部署过程详解的全部内容,更多相关hadoop内容请搜索靠谱客的其他文章。








发表评论 取消回复