原文链接:https://blog.csdn.net/weixin_40533111/article/details/85678805 作者四月天五月雨_,转载请注明出处,谢谢
前言
本文主要写jdk7和jdk8的内存结构区别和常规操作,后几篇会写调优工具和优化方式.
目录
1.jdk7和jdk8内存结构区别
2.各垃圾回收算法对比
3.各垃圾收集器对比
4.基础jvm命令
正文
1.jdk7和jdk8内存结构区别
在jvm结构中,对内存划分了:
- 程序计数器
- 2.Java虚拟机栈2.Java虚拟机栈
- 本地方法栈
- Java堆
- 方法区
在实际运行中,堆占据操作的大部分内存,常见的OOM和一些调优手段也是针对堆进行的.
1.1 jdk7堆内存分布如下:
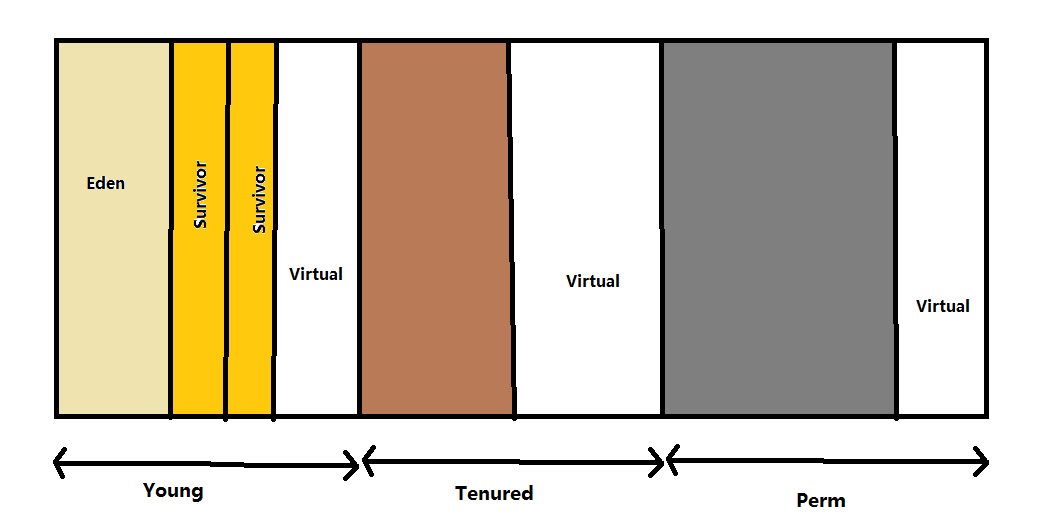
Young(年轻代):
年轻代分为三部分:Eden+Survivor * 2,两个survivor一样大小,刚创建的对象在Eden区,当Eden区放不下新对象时,触发垃圾回收,主流的虚拟机(如hotspot)在年轻代的回收策略默认为复制算法,把Eden区经过一轮仍存活的对象复制到另一个空闲的survivor区,如果放不下,这个对象则直接放到老年代,jvm提供参数:XX:PretenureSizeThreshold来设置大对象阈值,不经过回收,超过阈值的直接进入老年代
Tenured(老年代):
Tenured区主要保存生命周期长的对象,当一些对象在Young复制转移多次(默认15次)以后,对象就会被转移到Tenured区,或者一些系统级对象,也可进入老年代
Perm(永久代):
永久代主要保存class,method,filed对象,随着工程的启动就确定了
Virtual(可调尺度)
virtual就是堆初始大小-Xms 和堆最大大小-Xmx的之间的可调跨度,生产中为了避免堆内存频繁扩大,可以设置-Xms等于-Xmx.
1.2 jdk8堆内存分布如下:
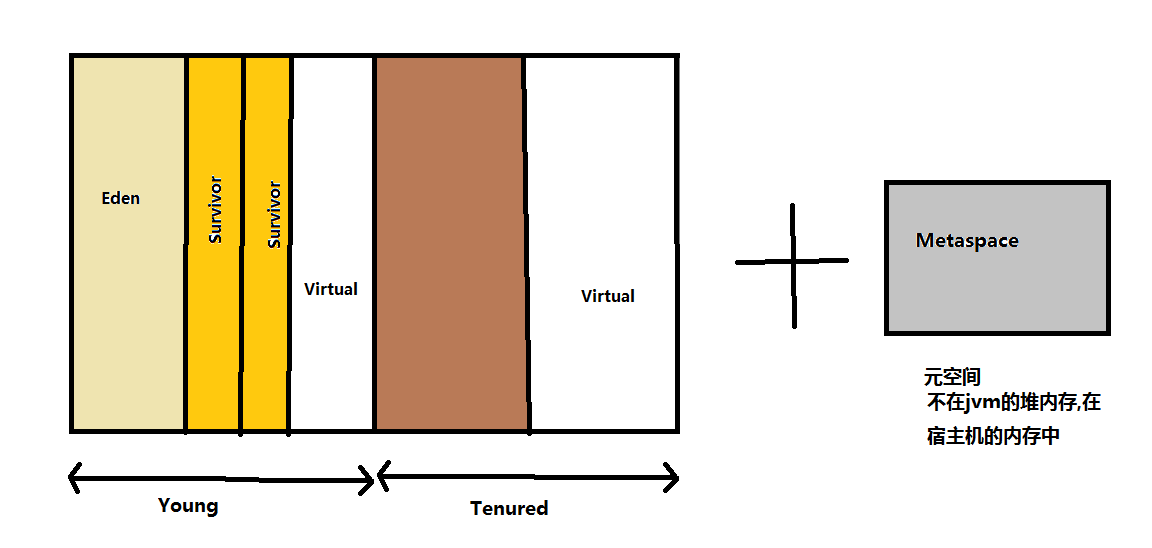
相比jdk1.7,可以明显看出,在jdk1.8中没有了永久代的概念,在之前,永久代是Hotspot虚拟机所属的,后来sun公司被Oracle收购,为了融合另一款优秀的虚拟机JRockit,牺牲了永久代,用元空间代替,因为在其他的虚拟机中没永久代的概念.
1.3 堆中各区域大小对比
默认情况下:
年轻代:老年代=1:2
年轻代=Eden+survivor1+survivor2
Eden:survivor1:survivor2=8:1:1
即新生代的可用极限内存为容量的90%,当然,一般情况下远达不到这个值,就触发gc了
手动设置:
可以通过参数 –XX:NewRatio 来指定
2.各垃圾回收算法对比
简述流程和优缺点.
2.1 标记-清除算法
流程: 顾名思义,执行时分两步,1.先标记需要回收的对象,2.完成标记后开始回收.
优点: 这个算法比较特殊,这是一个基础算法,为后续其他算法提供了方向,它的优点就是它是其他回收算法的垫脚石.
缺点: 作为最基础的算法,两个主要缺点:1.效率不高,先标记,在清除,太笼统,不够细化. 2.空间问题,对象活着的时候分布在堆中各区域,直接清除后,会产生碎片,造成内存空间不连续,导致后来再分配大对象时,连续空间不够,从而放不下,从而触发新的回收动作,性能不足

2.2 复制算法
流程: 将年轻代划分为三个区域:Eden+survivor1+survivor2,其中两个survivor区大小严格一致,比例为8:1:1,即新对象的可用空间为新生代的90%,当空间不够时,触发垃圾回收,将Eden区和survivor1区仍然存货的对象,复制到survivor2(每执行一次回收,就复制到另一块survivor区),如果survivor区放不下,对象直接晋升到老年代.
优点: 解决了效率问题,内存复制,速度是很可观的,
但是: 当年轻代对象的存活率较高时,一次次的垃圾回收,大量对象在survivor1和survivor2间复制来复制去,内存并内有显著减少,反而浪费了时间,效率不高
缺点: 空间问题,jdk8整个堆分为新生代+老年代,比例为:1:2,上面提到:年轻代最高可用内存为90%,即堆内存整体可用内存为:29/30,有1/30是无用状态,但权衡考虑,这是一种很好的回收策略了

2.3 标记-整理算法
流程: 思路和标记-清除算法基本一致,只是在清除前多了一步整理—垃圾回收时,先标记应回收的对象,把存活的对象移动到内存的一端,此刻再执行清除,清除另一端的内存,可以获取连续空间
优点: 增加了空间利用率
缺点: 动作多了,效率自然低了

2.4 分代收集算法
这并不是一种新算法,是一种组合方式,现在的商用虚拟机,垃圾收集都是采用这种.
流程:根据对象存活周期,将堆内存划分为几块,年轻代(Eden+survivor*2),老年代,然后根据各个年代的对象存活特点,选择相应的算法,比如年轻代,很多对象朝生夕死,显然复制算法更适合,而老年代多是活的时间较长的老对象,用标记-清除,或者标记-整理算法都行
优点:对内存的管理更细化,效率和空间利用率更高,就像中国房地产,现在房价严重虚高,高的吓银,为避免泡沫更大,政府出台限售政策,但并不是全国都限售,而是因地制宜,因城施策.我们的愿景是国.富.民.强,安.居.乐.业,…回归正题–_--
3.各垃圾收集器对比
垃圾收集器就是算法的实现,java虚拟机规范中对垃圾收集器的实现没有任何规定,因此各厂商,不同版本间的虚拟机提供的垃圾收集器可能存在差异,使用者可以根据自身的业务特点,选择不同的垃圾收集器组合,以达到最佳的性能
3.1 serial收集器
这是最基本,历史(JDK1.3.1之前的唯一选择)最长的垃圾收集器,单线程的收集器
流程: 触发垃圾回收时,serial会执行,同时停止虚拟机内其他所有线程,即传说中的"stop-the-world"出现了,直至垃圾回收结束,其他线程恢复
优点: 简单高效
缺点: 由于STW的出现,会让应用暂时不可用,不过对于client模式下的,单核CPU来说,它很适合,一二百M的新生代,回收时间100ms左右,更大的内存配比没试过,(待–)
3.2 parNew收集器
流程: parNew就是多线程版的serial收集器,其余行为包括控制参数都和serial一样,是虚拟机运行在server模式下的默认选择,并且唯一能与CMS搭配使用的收集器.
优点: 略高效,就是多线程的serial
缺点: 同serial
3.3 parallel Scavenge收集器
流程: 常规收集器都在努力缩短STW时间,parallel Scavenge的关注点是提高吞吐量,更大的利用CPU资源
优点: 提高了整体吞吐量
缺点: 单次回收过程,停顿时间长,适合用在后台的计算而不需要太多交互的场景,而常规收集器更适合用在有用户交互的场景中,单次STW时间短,用户体验好
3.4 Serial Old 收集器
它是serial收集器的老年代版本,也是单线程,使用"标记-整理算法",给client模式下的虚拟机使用(32位,过时了),
优点: 可作为CMS的后备收集器使用
缺点: 同年轻代版本serial
3.5Parallel Old 收集器
是Parallel Scavenge的老年代版本,关注吞吐量,在jdk1.6提供,在注重吞吐量优先的场景:可使用Parallel Scavenge收集器加Parallel Old收集器,以达到最高吞吐量
3.6 CMS收集器
CMS(Concurrent Mark-Sweep),是一种一种以获得最短停顿时间为目标的收集器.
**流程:**初始标记->并发标记->重新标记->并发清除
CMS是基于"标记-清除"算法,初始标记很快,并发标记就是在用户线程运行中时GC Roots跟踪,比较耗时,重新标记就是修正其他线程在这个过程中产生的对象,清除就是清除,因为是基于"标记-清除"算法,就会产生碎片,注意:初始标记和重新标记仍会产生STW
**优点:**并发收集,低停顿
**缺点:**1.CMS收集器对CPU资源敏感,其实所有的面向并发设计的程序,都对CPU敏感,特别是当CPU核数较少时,还得一直保持一部分资源执行垃圾回收,明显拖慢程序,核数越多,越不明显
2.无法处理"浮动垃圾",因为CMS在清理的时候,用户线程还在执行,有可能出现"Concurrent Model Failure"而导致一次新的Full GC,耗费时间,因此需要预留一些空间在老年代,以防在清理垃圾时又产生大量对象,jdk1.6中,CMS启动阈值设置为92%,如上面介绍,当失败时,可用备用的收集器serial Old
3.7 G1收集器
从实现方式来看,CMS和之前的收集器时传统收集器–称为一代收集器,CMS是一代收集器中的最优实现.
而G1收集器是二代收集器,有着完全不同的实现
优点:
1.并行与并发:在多核情况下,充分利用CPU,缩短STW时间
2.分代收集:保留这一定义,能够用不同方式去处理各种生命周期的对象,以达到更好的效果
3.空间整合:G1从整体来看是基于"标记-整理"算法,从局部来看是基于"复制算法",总之不会产生碎片
4.可预测停顿:G1和CMS收集器都专注于降低STW时间,但G1可以通过参数控制最大停顿时间
**缺点:**吞吐量时候弱项,不过对于用户交互的应用,已经很好了
作为二代收集器,
核心特点是:
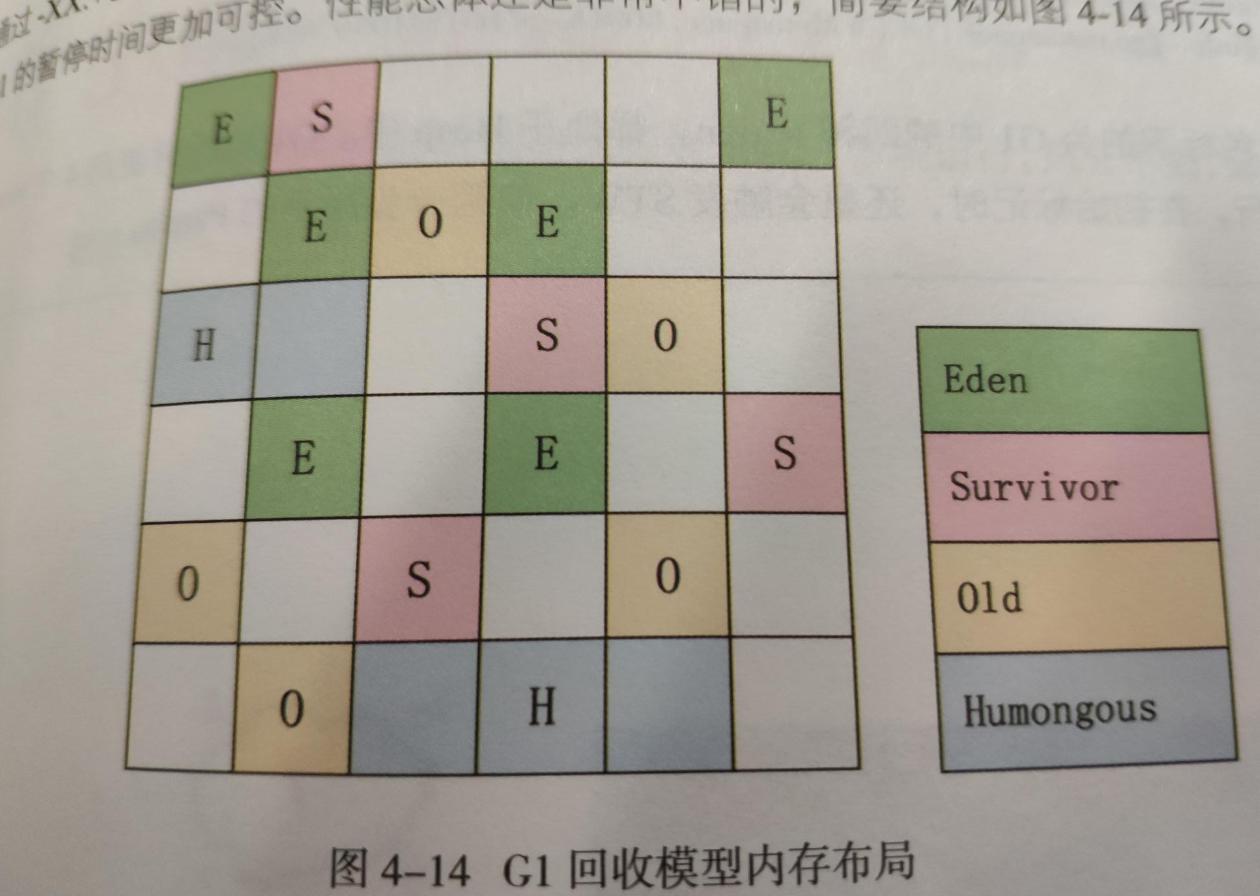
G1将内存化整为零,它将整个堆空间划分为若干个大小相等的独立区域(Region),虽然保留了新生代和老年代概念,但他们在物理上没隔离了,G1之所以支持可预测停顿,就是基于这个拆分内存的设计,G1跟踪每个Region里面的垃圾堆积的价值的大小,在后台维护一张优先列表,每次根据允许的时间停顿,来回收对应的Region,这样可以保证G1收集器在有限的时间获得更好的效率.
这个化整为零的思路,看起来容易,但细节实现很难,世界顶级团队sun实验室从发第一篇论文到第一版G1成型,花了近10年时间.
在jdk11中,G1已经是默认垃圾收集器了
4.基础jvm命令
在使用调优工具之前,先熟悉下jdk本身提供的命令,市场上一些工具也是依赖jdk接口和底层命令.
4.1. jps命令:
JVM Process Status Tool,显示所有的HotSpot虚拟机进程
option:
-l 显示全类名或
-m 输出JVM启动时传递给main()的参数
eg:
[root@localhost ~]# jps -lm 76851 org.apache.rocketmq.namesrv.NamesrvStartup 76898 org.apache.rocketmq.broker.BrokerStartup -c /usr/local/rocketmq/conf/2m-2s-async/broker-a.properties 31256 sun.tools.jps.Jps -lm 89227 org.apache.catalina.startup.Bootstrap start
4.2 jstat命令:
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量。命令的格式如下:
jstat [-命令选项] [vmid] [间隔时间/毫秒] [查询次数]
常用option:
class
compiler
gc
4.2.1 查看class加载统计
[root@localhost ~]# jstat -class 89227
Loaded Bytes Unloaded Bytes Time
3670 7860.6 13 16.6 5.48
说明:
- Loaded:加载class的数量
- Bytes:所占用空间大小
- Unloaded:未加载数量
- Bytes:未加载占用空间
- Time:时间
4.2.3 查看编译统计
[root@localhost ~]# jstat -compiler 89227
Compiled Failed Invalid Time FailedType FailedMethod
2496 0 0 9.66 0
说明:
- Compiled:编译数量。
- Failed:失败数量
- Invalid:不可用数量
- Time:时间
- FailedType:失败类型
- FailedMethod:失败的方法
4.2.4 垃圾回收统计

说明:
- S0C:第一个Survivor区的大小(KB)
- S1C:第二个Survivor区的大小(KB)
- S0U:第一个Survivor区的使用大小(KB)
- S1U:第二个Survivor区的使用大小(KB)
- EC:Eden区的大小(KB)
- EU:Eden区的使用大小(KB)
- OC:Old区大小(KB)
- OU:Old使用大小(KB)
- MC:方法区大小(KB)
- MU:方法区使用大小(KB)
- CCSC:压缩类空间大小(KB)
- CCSU:压缩类空间使用大小(KB)
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
4.3 jmap的使用以及内存溢出分析
jmap(JVM Memory Map)命令用于生成heap dump文件,然后使用工具对这个文件分析,如果不使用这个命令,还阔以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候·自动生成dump文件。 jmap能生成dump文件,Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
命令格式:
jmap [option] LVMID
option:
dump : 生成堆转储快照
finalizerinfo : 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
heap : 显示Java堆详细信息
histo : 显示堆中对象的统计信息
permstat : to print permanent generation statistics
F : 当-dump没有响应时,强制生成dump快照
4.3.1 查看堆信息
jmap -heap 89227
[root@localhost ~]# jmap -heap 89227
Attaching to process ID 28920, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 24.71-b01
using thread-local object allocation.
Parallel GC with 4 thread(s)//GC 方式
Heap Configuration: //堆内存初始化配置
MinHeapFreeRatio = 0 //对应jvm启动参数-XX:MinHeapFreeRatio设置JVM堆最小空闲比率(default 40)
MaxHeapFreeRatio = 100 //对应jvm启动参数 -XX:MaxHeapFreeRatio设置JVM堆最大空闲比率(default 70)
MaxHeapSize = 2082471936 (1986.0MB) //对应jvm启动参数-XX:MaxHeapSize=设置JVM堆的最大大小
NewSize = 1310720 (1.25MB)//对应jvm启动参数-XX:NewSize=设置JVM堆的‘新生代’的默认大小
MaxNewSize = 17592186044415 MB//对应jvm启动参数-XX:MaxNewSize=设置JVM堆的‘新生代’的最大大小
OldSize = 5439488 (5.1875MB)//对应jvm启动参数-XX:OldSize=<value>:设置JVM堆的‘老生代’的大小
NewRatio = 2 //对应jvm启动参数-XX:NewRatio=:‘新生代’和‘老生代’的大小比率
SurvivorRatio = 8 //对应jvm启动参数-XX:SurvivorRatio=设置年轻代中Eden区与Survivor区的大小比值
PermSize = 21757952 (20.75MB) //对应jvm启动参数-XX:PermSize=<value>:设置JVM堆的‘永生代’的初始大小
MaxPermSize = 85983232 (82.0MB)//对应jvm启动参数-XX:MaxPermSize=<value>:设置JVM堆的‘永生代’的最大大小
G1HeapRegionSize = 0 (0.0MB)
Heap Usage://堆内存使用情况
PS Young Generation
Eden Space://Eden区内存分布
capacity = 33030144 (31.5MB)//Eden区总容量
used = 1524040 (1.4534378051757812MB) //Eden区已使用
free = 31506104 (30.04656219482422MB) //Eden区剩余容量
4.614088270399305% used //Eden区使用比率
From Space: //其中一个Survivor区的内存分布
capacity = 5242880 (5.0MB)
used = 0 (0.0MB)
free = 5242880 (5.0MB)
0.0% used
To Space: //另一个Survivor区的内存分布
capacity = 5242880 (5.0MB)
used = 0 (0.0MB)
free = 5242880 (5.0MB)
0.0% used
PS Old Generation //当前的Old区内存分布
capacity = 86507520 (82.5MB)
used = 0 (0.0MB)
free = 86507520 (82.5MB)
0.0% used
PS Perm Generation//当前的 “永生代” 内存分布
capacity = 22020096 (21.0MB)
used = 2496528 (2.3808746337890625MB)
free = 19523568 (18.619125366210938MB)
11.337498256138392% used
670 interned Strings occupying 43720 bytes.
4.3.2 查看活跃对象
jmap -histo:live 89227 | more
[root@localhost ~]# jmap -histo:live 76851 | more
num #instances #bytes class name
----------------------------------------------
1: 3412 1964056 [Ljava.lang.Object;
2: 13770 1097136 [C
3: 3114 633880 [B
4: 858 562848 io.netty.util.internal.shaded.org.jctools.queues.MpscArrayQueue
5: 3265 374208 java.lang.Class
6: 13654 327696 java.lang.String
7: 2121 124920 [I
8: 2553 81696 java.util.HashMap$Node
9: 2383 76256 java.util.concurrent.ConcurrentHashMap$Node
10: 2 65568 [Lcom.alibaba.fastjson.util.IdentityHashMap$Entry;
11: 71 52720 [Lio.netty.util.Recycler$DefaultHandle;
12: 1300 52000 java.util.LinkedHashMap$Entry
13: 296 49248 [Ljava.util.HashMap$Node;
14: 1143 36576 java.util.Hashtable$Entry
15: 403 33072 [Ljava.lang.String;
16: 10 32960 [Ljava.nio.channels.SelectionKey;
17: 767 30680 java.math.BigInteger
18: 904 28928 sun.security.util.DerInputBuffer
19: 904 28928 sun.security.util.DerValue
20: 1791 28656 java.lang.Object
21: 46 25424 [Ljava.util.concurrent.ConcurrentHashMap$Node;
22: 792 25344 io.netty.buffer.PoolThreadCache$SubPageMemoryRegionCache
23: 629 25160 java.lang.ref.SoftReference
24: 547 21880 java.util.TreeMap$Entry
25: 904 21696 sun.security.util.DerInputStream
26: 891 21384 [Lsun.security.x509.AVA;
27: 891 21384 sun.security.x509.AVA
28: 891 21384 sun.security.x509.RDN
4.3.3 生成dump文件
有些时候我们需要将jvm当前内存中的情况dump到文件中,然后对它进行分析,jmap支持dump到文件。
#用法:
jmap -dump:format=b,file=dumpFileName
[root@localhost bin]# jmap -dump:live,format=b,file=tomcatTest1.hprof 103345
Dumping heap to /var/local/demo1/apache-tomcat-8.5.37/bin/tomcatTest1.hprof ...
Heap dump file created
位置如果,当然不应该存这里,仅仅是demo示例
4.3.4 使用jhat对dump文件查看
dump文件本身是二进制文件,借助工具查看,jhat实际上也是用jvm运行,可以配置启动参数,
语法:
jhat file
option:
-port port-number 设置 jhat HTTP server 的端口号. 默认值 7000.>
-J< flag > 因为 jhat 命令实际上会启动一个JVM来执行, 通过 -J 可以在启动JVM时传入一些启动参数. 例如, -J-Xmx512m 则指定运行 jhat 的Java虚拟机使用的最大堆内存为 512 MB. 如果需要使用多个JVM启动参数,则传入多个 -Jxxxxxx.
更多参数可jhat -help 查看
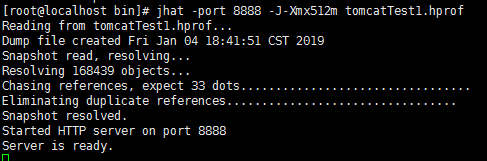
页面可访问查看:
后面几篇持续介绍.
参考:
1.深入理解java虚拟机-周志明
2.码出高效-java开发手册
最后
以上就是痴情香烟最近收集整理的关于jvm 优化(一):内存结构前言目录正文1.jdk7和jdk8内存结构区别2.各垃圾回收算法对比3.各垃圾收集器对比4.基础jvm命令参考:的全部内容,更多相关jvm内容请搜索靠谱客的其他文章。








发表评论 取消回复