本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
前言
大家好,我是小彭。
在上一篇文章里,我们聊到了基于动态数组 ArrayList 线性表,今天我们来讨论一个基于链表的线性表 —— LinkedList。
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~
思维导图:
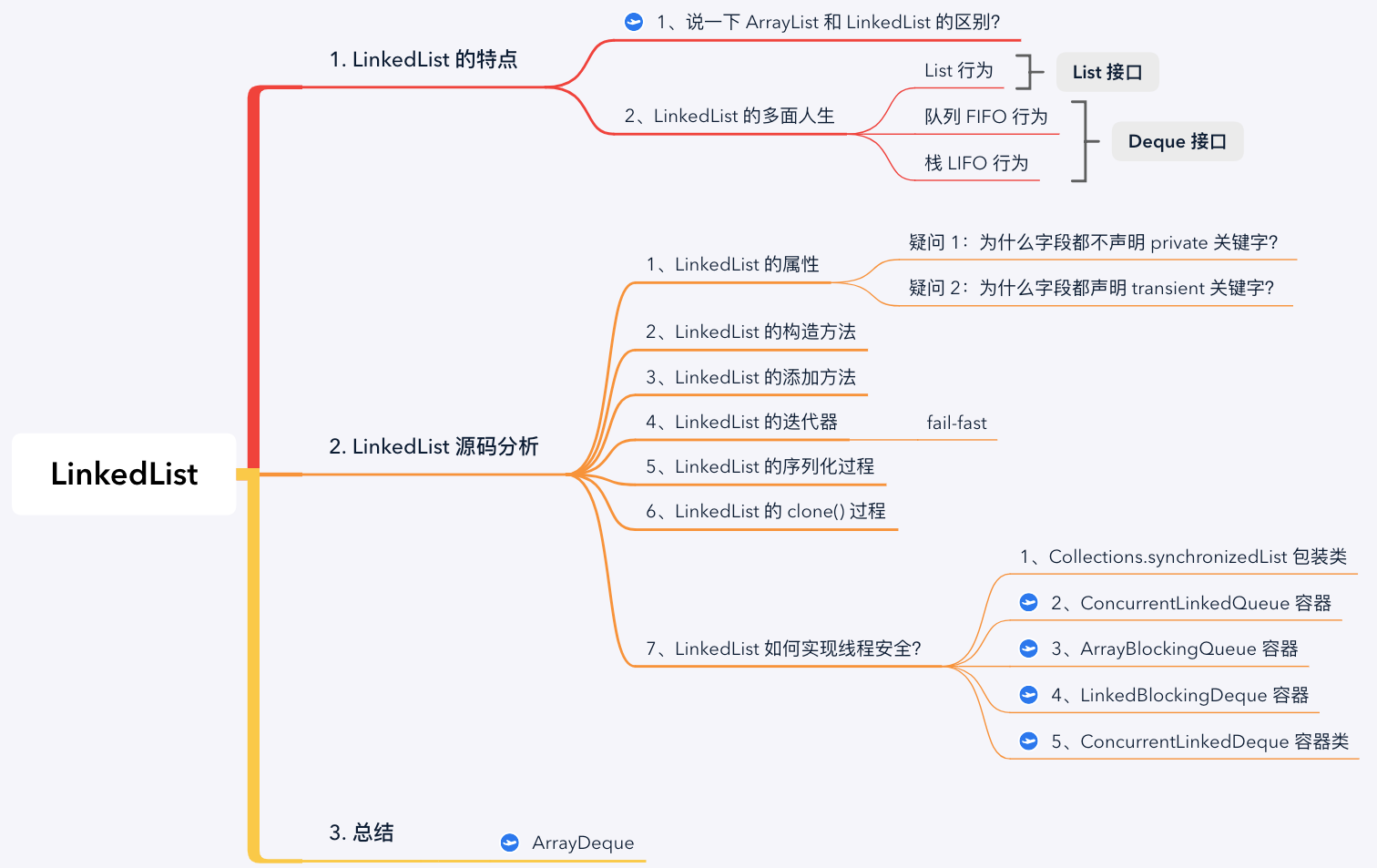
1. LinkedList 的特点
1.1 说一下 ArrayList 和 LinkedList 的区别?
- 1、数据结构: 在数据结构上,ArrayList 和 LinkedList 都是 “线性表”,都继承于 Java 的
List接口。另外 LinkedList 还实现了 Java 的Deque接口,是基于链表的栈或队列,与之对应的是ArrayDeque基于数组的栈或队列; - 2、线程安全: ArrayList 和 LinkedList 都不考虑线程同步,不保证线程安全;
- 3、底层实现: 在底层实现上,ArrayList 是基于动态数组的,而 LinkedList 是基于双向链表的。事实上,它们很多特性的区别都是因为底层实现不同引起的。比如说:
- 在遍历速度上: 数组是一块连续内存空间,基于局部性原理能够更好地命中 CPU 缓存行,而链表是离散的内存空间对缓存行不友好;
- 在访问速度上: 数组是一块连续内存空间,支持 O(1) 时间复杂度随机访问,而链表需要 O(n) 时间复杂度查找元素;
- 在添加和删除操作上: 如果是在数组的末尾操作只需要 O(1) 时间复杂度,但在数组中间操作需要搬运元素,所以需要 O(n)时间复杂度,而链表的删除操作本身只是修改引用指向,只需要 O(1) 时间复杂度(如果考虑查询被删除节点的时间,复杂度分析上依然是 O(n),在工程分析上还是比数组快);
- 额外内存消耗上: ArrayList 在数组的尾部增加了闲置位置,而 LinkedList 在节点上增加了前驱和后继指针。
1.2 LinkedList 的多面人生
在数据结构上,LinkedList 不仅实现了与 ArrayList 相同的 List 接口,还实现了 Deque 接口(继承于 Queue 接口)。
Deque 接口表示一个双端队列(Double Ended Queue),允许在队列的首尾两端操作,所以既能实现队列行为,也能实现栈行为。
Queue 接口:
| 拒绝策略 | 抛异常 | 返回特殊值 |
|---|---|---|
| 入队(队尾) | add(e) | offer(e) |
| 出队(队头) | remove() | poll() |
| 观察(队头) | element() | peek() |
Queue 的 API 可以分为 2 类,区别在于方法的拒绝策略上:
-
抛异常:
- 向空队列取数据,会抛出 NoSuchElementException 异常;
- 向容量满的队列加数据,会抛出 IllegalStateException 异常。
-
返回特殊值:
- 向空队列取数据,会返回 null;
- 向容量满的队列加数据,会返回 false。
Deque 接口:
Java 没有提供标准的栈接口(很好奇为什么不提供),而是放在 Deque 接口中:
| 拒绝策略 | 抛异常 | 等价于 |
|---|---|---|
| 入栈 | push(e) | addFirst(e) |
| 出栈 | pop() | removeFirst() |
| 观察(栈顶) | peek() | peekFirst() |
除了标准的队列和栈行为,Deque 接口还提供了 12 个在两端操作的方法:
| 拒绝策略 | 抛异常 | 返回值 |
|---|---|---|
| 增加 | addFirst(e)/ addLast(e) | offerFirst(e)/ offerLast(e) |
| 删除 | removeFirst()/ removeLast() | pollFirst()/ pollLast() |
| 观察 | getFirst()/ getLast() | peekFirst()/ peekLast() |
2. LinkedList 源码分析
这一节,我们来分析 LinkedList 中主要流程的源码。
2.1 LinkedList 的属性
- LinkedList 底层是一个 Node 双向链表,Node 节点中会持有数据 E 以及 prev 与next 两个指针;
- LinkedList 用
first和last指针指向链表的头尾指针。
LinkedList 的属性很好理解的,不出意外的话又有小朋友出来举手提问了:
- ????????♀️ 疑问 1:为什么字段都不声明
private关键字?
这个问题直接回答吧。我的理解是:因为内部类在编译后会生成独立的 Class 文件,如果外部类的字段是 private 类型,那么编译器就需要通过方法调用,而 non-private 字段就可以直接访问字段。
- ????????♀️ 疑问 2:为什么字段都声明
transient关键字?
这个问题我们在分析源码的过程中回答。
疑问比 ArrayList 少很多,LinkedList 真香(还是别高兴得太早吧)。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
// 疑问 1:为什么字段都不声明 private 关键字?
// 疑问 2:为什么字段都声明 transient 关键字?
// 元素个数
transient int size = 0;
// 头指针
transient Node<E> first;
// 尾指针
transient Node<E> last;
// 链表节点
private static class Node<E> {
// 节点数据
// (类型擦除后:Object item;)
E item;
// 前驱指针
Node<E> next;
// 后继指针
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
2.2 LinkedList 的构造方法
LinkedList 有 2 个构造方法:
- 1、无参构造方法: no-op;
- 2、带集合的构造: 在链表末尾添加整个集合,内部调用了 addAll 方法将整个集合添加到数组的末尾。
// 无参构造方法
public LinkedList() {
}
// 带集合的构造方法
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
// 在链表尾部添加集合
public boolean addAll(Collection<? extends E> c) {
// 索引为 size,等于在链表尾部添加
return addAll(size, c);
}
2.3 LinkedList 的添加方法
LinkedList 提供了非常多的 addXXX 方法,内部都是调用一系列 linkFirst、linkLast 或 linkBefore 完成的。如果在链表中间添加节点时,会用到 node(index) 方法查询指定位置的节点。
其实,我们会发现所有添加的逻辑都可以用 6 个步骤概括:
- 步骤 1: 找到插入位置的后继节点(在头部插入就是 first,在尾部插入就是 null);
- 步骤 2: 构造新节点;
- 步骤 3: 将新节点的 prev 指针指向前驱节点(在头部插入就是 null,在尾部插入就是 last);
- 步骤 4: 将新节点的 next 指针指向后继节点(在头部插入就是 first,在尾部插入就是 null);
- 步骤 5: 将前驱节点的 next 指针指向新节点(在头部插入没有这个步骤);
- 步骤 6: 将后继节点的 prev 指针指向新节点(在尾部插入没有这个步骤)。
分析一下添加方法的时间复杂度,区分在链表两端或中间添加元素的情况共:
- 如果是在链表首尾两端添加: 只需要 O(1) 时间复杂度;
- 如果在链表中间添加: 由于需要定位到添加位置的前驱和后继节点,所以需要 O(n) 时间复杂度。如果事先已经获得了添加位置的节点,就只需要 O(1) 时间复杂度。
添加方法
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
// 在尾部添加
linkLast(element);
else
// 在指定位置添加
linkBefore(element, node(index));
}
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
// 在链表头部添加
private void linkFirst(E e) {
// 1. 找到插入位置的后继节点(first)
final Node<E> f = first;
// 2. 构造新节点
// 3. 将新节点的 prev 指针指向前驱节点(null)
// 4. 将新节点的 next 指针指向后继节点(f)
// 5. 将前驱节点的 next 指针指向新节点(前驱节点是 null,所以没有这个步骤)
final Node<E> newNode = new Node<>(null, e, f);
// 修改 first 指针
first = newNode;
if (f == null)
// f 为 null 说明首个添加的元素,需要修改 last 指针
last = newNode;
else
// 6. 将后继节点的 prev 指针指向新节点
f.prev = newNode;
size++;
modCount++;
}
// 在链表尾部添加
void linkLast(E e) {
final Node<E> l = last;
// 1. 找到插入位置的后继节点(null)
// 2. 构造新节点
// 3. 将新节点的 prev 指针指向前驱节点(l)
// 4. 将新节点的 next 指针指向后继节点(null)
final Node<E> newNode = new Node<>(l, e, null);
// 修改 last 指针
last = newNode;
if (l == null)
// l 为 null 说明首个添加的元素,需要修改 first 指针
first = newNode;
else
// 5. 将前驱节点的 next 指针指向新节点
l.next = newNode;
// 6. 将后继节点的 prev 指针指向新节点(后继节点是 null,所以没有这个步骤)
size++;
modCount++;
}
// 在指定节点前添加
// 1. 找到插入位置的后继节点
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
// 2. 构造新节点
// 3. 将新节点的 prev 指针指向前驱节点(pred)
// 4. 将新节点的 next 指针指向后继节点(succ)
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
// 5. 将前驱节点的 next 指针指向新节点
pred.next = newNode;
size++;
modCount++;
}
// 在指定位置添加整个集合元素
// index 为 0:在链表头部添加
// index 为 size:在链表尾部添加
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
// 事实上,c.toArray() 的实际类型不一定是 Object[],有可能是 String[] 等
// 不过,我们是通过 Node中的item 承接的,所以不用担心 ArrayList 中的 ArrayStoreException 问题
Object[] a = c.toArray();
// 添加的数组为空,跳过
int numNew = a.length;
if (numNew == 0)
return false;
// 1. 找到插入位置的后继节点
// pred:插入位置的前驱节点
// succ:插入位置的后继节点
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
// 找到 index 位置原本的节点,插入后变成后继节点
succ = node(index);
pred = succ.prev;
}
// 插入集合元素
for (Object o : a) {
E e = (E) o;
// 2. 构造新节点
// 3. 将新节点的 prev 指针指向前驱节点
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
// pred 为 null 说明是在头部插入,需要修改 first 指针
first = newNode;
else
// 5. 将前驱节点的 next 指针指向新节点
pred.next = newNode;
// 修改前驱指针
pred = newNode;
}
if (succ == null) {
// succ 为 null 说明是在尾部插入,需要修改 last 指针
last = pred;
} else {
// 4. 将新节点的 next 指针指向后继节点
pred.next = succ;
// 6. 将后继节点的 prev 指针指向新节点
succ.prev = pred;
}
// 数量增加 numNew
size += numNew;
modCount++;
return true;
}
// 将 LinkedList 转化为 Object 数组
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
在链表中间添加节点时,会用到 node(index) 方法查询指定位置的节点。可以看到维持 first 和 last 头尾节点的作用又发挥出来了:
- 如果索引位置小于 size/2,则从头节点开始找;
- 如果索引位置大于 size/2,则从尾节点开始找。
虽然,我们从复杂度分析的角度看,从哪个方向查询是没有区别的,时间复杂度都是 O(n)。但从工程分析的角度看还是有区别的,从更靠近目标节点的位置开始查询,实际执行的时间会更短。
查询指定位置节点
// 寻找指定位置的节点,时间复杂度:O(n)
Node<E> node(int index) {
if (index < (size >> 1)) {
// 如果索引位置小于 size/2,则从头节点开始找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 如果索引位置大于 size/2,则从尾节点开始找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
LinkedList 的删除方法其实就是添加方法的逆运算,我们就不重复分析了。
// 删除头部元素
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// 删除尾部元素
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
// 删除指定元素
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
2.4 LinkedList 的迭代器
Java 的 foreach 是语法糖,本质上也是采用 iterator 的方式。由于 LinkedList 本身就是双向的,所以 LinkedList 只提供了 1 个迭代器:
- ListIterator listIterator(): 双向迭代器
与其他容器类一样,LinkedList 的迭代器中都有 fail-fast 机制。如果在迭代的过程中发现 expectedModCount 变化,说明数据被修改,此时就会提前抛出 ConcurrentModificationException 异常(当然也不一定是被其他线程修改)。
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
// 非静态内部类
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
// 创建迭代器时会记录外部类的 modCount
private int expectedModCount = modCount;
ListItr(int index) {
next = (index == size) ? null : node(index);
nextIndex = index;
}
public E next() {
// 更新 expectedModCount
checkForComodification();
...
}
...
}
2.5 LinkedList 的序列化过程
- ????????♀️ 疑问 2:为什么字段都声明
transient关键字?
LinkedList 重写了 JDK 序列化的逻辑,不序列化链表节点,而只是序列化链表节点中的有效数据,这样序列化产物的大小就有所降低。在反序列时,只需要按照对象顺序依次添加到链表的末尾,就能恢复链表的顺序。
// 序列化和反序列化只考虑有效数据
// 序列化过程
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// 写入链表长度
s.writeInt(size);
// 写入节点上的有效数据
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
// 反序列化过程
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// 读取链表长度
int size = s.readInt();
// 读取有效元素并用 linkLast 添加到链表尾部
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}
2.6 LinkedList 的 clone() 过程
LinkedList 中的 first 和 last 指针是引用类型,因此在 clone() 中需要实现深拷贝。否则,克隆后两个 LinkedList 对象会相互影响:
private LinkedList<E> superClone() {
try {
return (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
public Object clone() {
LinkedList<E> clone = superClone();
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// 将原链表中的数据依次添加到新立案表中
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
2.7 LinkedList 如何实现线程安全?
有 5 种方式:
- 方法 1 - 使用 Collections.synchronizedList 包装类: 原理也是在所有方法上增加 synchronized 关键字;
- 方法 2 - 使用 ConcurrentLinkedQueue 容器类: 基于 CAS 无锁实现的线程安全队列;
- 方法 3 - 使用 LinkedBlockingQueue 容器: 基于加锁的阻塞队列,适合于带阻塞操作的生产者消费者模型;
- 方法 4 - 使用 LinkedBlockingDeque 容器: 基于加锁的阻塞双端队列,适合于带阻塞操作的生产者消费者模型;
- 方法 5 - 使用 ConcurrentLinkedDeque 容器类: 基于 CAS 无锁实现的线程安全双端队列。
3. 总结
-
1、LinkedList 是基于链表的线性表,同时具备 List、Queue 和 Stack 的行为;
-
2、在查询指定位置的节点时,如果索引位置小于 size/2,则从头节点开始找,否则从尾节点开始找;
-
3、LinkedList 重写了序列化过程,只处理链表节点中有效的元素;
-
4、LinkedList 和 ArrayList 都不考虑线程同步,不保证线程安全。
在上一篇文章里,我们提到了 List 的数组实现 ArrayList,而 LinkedList 不仅是 List 的链表实现,同时还是 Queue 和 Stack 的链表实现。那么,在 Java 中的 Queue 和 Stack 的数组实现是什么呢,这个我们在下篇文章讨论,请关注。
小彭的 Android 交流群 02 群

最后
以上就是忐忑海燕最近收集整理的关于说一下 ArrayList 和 LinkedList 的区别?的全部内容,更多相关说一下内容请搜索靠谱客的其他文章。








发表评论 取消回复