LightGBM的意思是轻量级(light)的梯度提升机(GBM),其相对Xgboost具有训练速度快、内存占用低的特点。关于lgb针对xgb做的优化,后面想写一篇文章复习一下。本篇文章主要讲解如何利用lgb建立一张评分卡,不涉及公式推导。关于lgb的基础使用教程,由于和xgb有许多相似之处,这里放一篇基础教程的链接。
LightGBM使用简单介绍:https://mathpretty.com/10649.html
本文是梅子行老师的金融风控实战课程的笔记。
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
import numpy as np
import random
import math
import time
import lightgbm as lgb
data = pd.read_csv('Acard.txt')
df_train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
lst = ['person_info','finance_info','credit_info','act_info','td_score','jxl_score','mj_score','rh_score']
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-61JGuNcc-1587045363117)(https://imgkr.cn-bj.ufileos.com/b7132395-64c1-4068-8b49-7297f24472b2.png)]
变量都是数值型,无需进行处理。由于lgb采用的是cart回归树,所以只能接受数值特征输入,不直接支持类别特征。对于类别特征,可以进行one-hot编码或者label-encoding编码转化成数值型变量。
然后选取跨时间验证集,将2018年11月份的数据选作跨时间验证集,用于评估模型的表现。
一共有8个入模变量,其中info结尾的是无监督系统输出的个人表现,score结尾的是收费的外部征信数据。
df_train = df_train.sort_values(by = 'obs_mth',ascending = False)
rank_lst = []
for i in range(1,len(df_train)+1):
rank_lst.append(i)
df_train['rank'] = rank_lst
df_train['rank'] = df_train['rank']/len(df_train)
pct_lst = []
for x in df_train['rank']:
if x <= 0.2:
x = 1
elif x <= 0.4:
x = 2
elif x <= 0.6:
x = 3
elif x <= 0.8:
x = 4
else:
x = 5
pct_lst.append(x)
df_train['rank'] = pct_lst
#train = train.drop('obs_mth',axis = 1)
df_train.head()
这里将样本均分为5份,并打上相应的标签,目的是为了训练中进行交叉验证。这里有一个注意的地方,在机器学习中,一般数据集可以分为训练集、验证集、测试集,但是在信贷风控领域中验证集和测试集定义正好相反。跨时间验证集其实是测试集,而上面作交叉验证的“测试集”其实才是验证集。总之,验证集是为了模型调参用的,而测试集是为了看模型的泛化效果。
def LGB_test(train_x,train_y,test_x,test_y):
from multiprocessing import cpu_count
clf = lgb.LGBMClassifier(
boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=2, n_estimators=800,max_features = 140, objective='binary',
subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.05, min_child_weight=50,random_state=None,n_jobs=cpu_count()-1,
num_iterations = 800 #迭代次数
)
clf.fit(train_x, train_y,eval_set=[(train_x, train_y),(test_x,test_y)],eval_metric='auc',early_stopping_rounds=100)
print(clf.n_features_)
return clf,clf.best_score_[ 'valid_1']['auc']
定义lightgbm函数,这里用的是sklearn接口的方法。lgb建模和xgb一样,也有两种方法。可以看到,参数也有很多是一样的。解释一下几个参数的含义:
‘num_leaves’:一颗树上的叶子数,默认为31.
‘reg_alpha’:L1 正则,默认为0,在xgb自带建模中为lambda_l1。
‘objective’:损失函数。默认为regression,即回归问题的均方误差损失函数。这里用的binary是对数损失函数作为目标函数,表示二分类任务。
‘min_child_weight’:子节点上最小的样本权重和。指建立每个模型所需要的最小样本数,可以用来处理过拟合。
‘subsample_freq’:bagging 的频率,默认为1。即多少次迭代之后进行一次bagging。
n_features_为入模特征的个数,这里为8。best_score_表示模型的最佳得分,是一个字典,返回验证集上的AUC值。
feature_lst = {}
ks_train_lst = []
ks_test_lst = []
for rk in set(df_train['rank']):
ttest = df_train[df_train['rank'] == rk]
ttrain = df_train[df_train['rank'] != rk]
train = ttrain[lst]
train_y = ttrain.bad_ind
test = ttest[lst]
test_y = ttest.bad_ind
start = time.time()
model,auc = LGB_test(train,train_y,test,test_y)
end = time.time()
#模型贡献度放在feture中
feature = pd.DataFrame(
{'name' : model.booster_.feature_name(),
'importance' : model.feature_importances_
}).sort_values(by = ['importance'],ascending = False)
#计算训练集、测试集、验证集上的KS和AUC
y_pred_train_lgb = model.predict_proba(train)[:, 1]
y_pred_test_lgb = model.predict_proba(test)[:, 1]
train_fpr_lgb, train_tpr_lgb, _ = roc_curve(train_y, y_pred_train_lgb)
test_fpr_lgb, test_tpr_lgb, _ = roc_curve(test_y, y_pred_test_lgb)
train_ks = abs(train_fpr_lgb - train_tpr_lgb).max()
test_ks = abs(test_fpr_lgb - test_tpr_lgb).max()
train_auc = metrics.auc(train_fpr_lgb, train_tpr_lgb)
test_auc = metrics.auc(test_fpr_lgb, test_tpr_lgb)
ks_train_lst.append(train_ks)
ks_test_lst.append(test_ks)
feature_lst[str(rk)] = feature[feature.importance>=20].name
train_ks = np.mean(ks_train_lst)
test_ks = np.mean(ks_test_lst)
ft_lst = {}
for i in range(1,6):
ft_lst[str(i)] = feature_lst[str(i)]
fn_lst=list(set(ft_lst['1']) & set(ft_lst['2'])
& set(ft_lst['3']) & set(ft_lst['4']) &set(ft_lst['5']))
print('train_ks: ',train_ks)
print('test_ks: ',test_ks)
print('ft_lst: ',fn_lst )
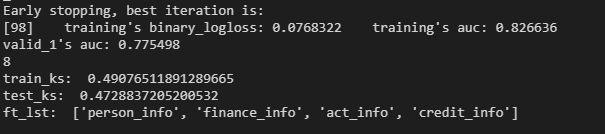
这里的ks值取的是每次交叉验证的ks值的平均值。特征重要性大于20的有4个,是将所有交叉验证过程中特征重要度大于20的特征去重,最后得到4个重要度最高的特征。模型的booster_.feature_name()参数保存特征的名字,feature_importances_保存特征的重要性。
然后用这4个变量入模,看下模型在跨时间验证集(测试集)上的表现。
lst = ['person_info','finance_info','credit_info','act_info']
train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
evl = data[data.obs_mth == '2018-11-30'].reset_index().copy()
x = train[lst]
y = train['bad_ind']
evl_x = evl[lst]
evl_y = evl['bad_ind']
model,auc = LGB_test(x,y,evl_x,evl_y)
y_pred = model.predict_proba(x)[:,1]
fpr_lgb_train,tpr_lgb_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lgb_train - tpr_lgb_train).max()
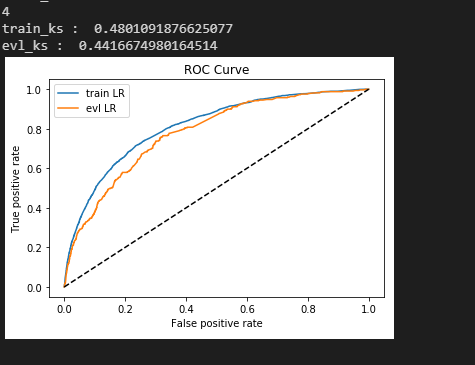
print('train_ks : ',train_ks)
y_pred = model.predict_proba(evl_x)[:,1]
fpr_lgb,tpr_lgb,_ = roc_curve(evl_y,y_pred)
evl_ks = abs(fpr_lgb - tpr_lgb).max()
print('evl_ks : ',evl_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lgb_train,tpr_lgb_train,label = 'train LR')
plt.plot(fpr_lgb,tpr_lgb,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
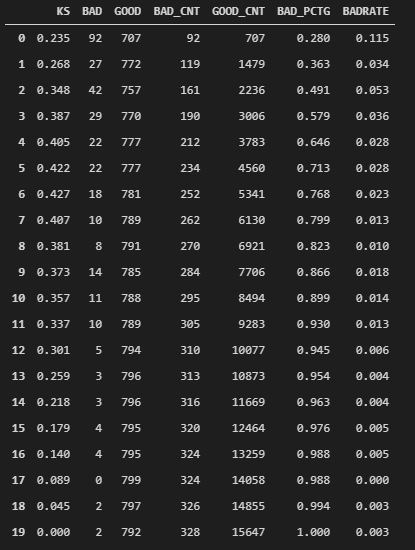
最后将概率映射成得分,并生成得分报告。
def score(xbeta):
score = 1000-500*(math.log2(1-xbeta)/xbeta) #好人的概率/坏人的概率
return score
evl['xbeta'] = model.predict_proba(evl_x)[:,1]
evl['score'] = evl.apply(lambda x : score(x.xbeta) ,axis=1)
#生成报告
row_num, col_num = 0, 0
bins = 20
Y_predict = evl['score']
Y = evl_y
nrows = Y.shape[0]
lis = [(Y_predict[i], Y[i]) for i in range(nrows)]
ks_lis = sorted(lis, key=lambda x: x[0], reverse=True)
bin_num = int(nrows/bins+1)
bad = sum([1 for (p, y) in ks_lis if y > 0.5])
good = sum([1 for (p, y) in ks_lis if y <= 0.5])
bad_cnt, good_cnt = 0, 0
KS = []
BAD = []
GOOD = []
BAD_CNT = []
GOOD_CNT = []
BAD_PCTG = []
BADRATE = []
dct_report = {}
for j in range(bins):
ds = ks_lis[j*bin_num: min((j+1)*bin_num, nrows)]
bad1 = sum([1 for (p, y) in ds if y > 0.5])
good1 = sum([1 for (p, y) in ds if y <= 0.5])
bad_cnt += bad1
good_cnt += good1
bad_pctg = round(bad_cnt/sum(evl_y),3)
badrate = round(bad1/(bad1+good1),3)
ks = round(math.fabs((bad_cnt / bad) - (good_cnt / good)),3)
KS.append(ks)
BAD.append(bad1)
GOOD.append(good1)
BAD_CNT.append(bad_cnt)
GOOD_CNT.append(good_cnt)
BAD_PCTG.append(bad_pctg)
BADRATE.append(badrate)
dct_report['KS'] = KS
dct_report['BAD'] = BAD
dct_report['GOOD'] = GOOD
dct_report['BAD_CNT'] = BAD_CNT
dct_report['GOOD_CNT'] = GOOD_CNT
dct_report['BAD_PCTG'] = BAD_PCTG
dct_report['BADRATE'] = BADRATE
val_repot = pd.DataFrame(dct_report)
【作者】:Labryant
【原创公众号】:风控猎人
【简介】:某创业公司策略分析师,积极上进,努力提升。乾坤未定,你我都是黑马。
【转载说明】:转载请说明出处,谢谢合作!~
最后
以上就是魁梧黑裤最近收集整理的关于lightgbm简易评分卡制作的全部内容,更多相关lightgbm简易评分卡制作内容请搜索靠谱客的其他文章。






![[视频]2022最牛编程语言排行榜!Python、JAVA意外落榜](https://www.shuijiaxian.com/files_image/reation/bcimg3.png)

发表评论 取消回复