机器学习之协同过滤
[睡着的水-hzjs-2016.08.18][求点赞 ]
]
一、协同过滤的基本概念
协同过滤是推荐引擎的一种算法,经常用到的地方像亚马逊、京东、淘宝、今日头条等隐形推荐场景。这些计算旨在补充用户-商品关联矩阵中所缺失的部分。像下面的推荐引擎就是我们的推荐系统:

#MLlib 当前支持基于模型的协同过滤,其中用户和商品通过一小组隐性因子进行表达,并且这些因子也用于预测缺失的元素,MLlib 使用最小二乘法(ALS)来学习这些隐性因子。
在Mllib中实现的有如下参数:
---numBlocks 是用于并行化计算的分块个数(设置为-1 为自动分配);
---rank 是模型中隐语义因子的个数;
---Iterations 是迭代的次数;
---lambda 是ALS 的正则化参数;
---Impllcltprefs 决定了是线性反馈ALS 的版本还是用适用隐性反馈数据集的版本;
---alpha 是一个针对隐性反馈ALS 版本的参数,这个参数决定了偏好行为强度的基准;
推荐系统主流的有三种:
------基于人口统计学的推荐:典型的就是大众点评,当你去外地,比如去北京,大众点评会推荐北京的一些特色美食饭馆,这是根据你的自己手机上网的ip推荐

------基于内容的推荐:比如电影网站,推荐给你看过的相同的类型的电影。同类会打标签,,,

#以上两种在大数据领域存在问题:1)获取信息难度大,不精确 2)当有几万种商品,很多的分类,,打标签就不合适了,内容会出现偏差
------协同过滤:1、基于商品 ;2、基于用户;
#1、基于商品:不需要用户的信息,只需要用户以往的浏览、购买、收藏的商品信息,信息比较客观(以商品为标准),这是基于商品的推荐(一般大型的商城都是基于商品的推荐)。

#2、基于用户:用户增长很快,且容易变化,,,不稳定。

#无论采用哪种方式,核心的问题都是一个:如何计算物品(用户)之间的相似度
算法思想:

#这套算法的适应性不太好(当物品很多,规则很多的时候矛盾就会特别的多),但是还是有很多人用,因为算法简单、速度快!在大数据领域,算法简单,运算快就是很大的优势,尤其是面对海量的数据、精确度要求不是很高的时候。
#很多的时候我们会用这套算法实现初次筛选、快速过滤---》在进行别的算法实现精确过滤。有效提升执行效率。
三、基于相关性的协同过滤
以电影打分为例:
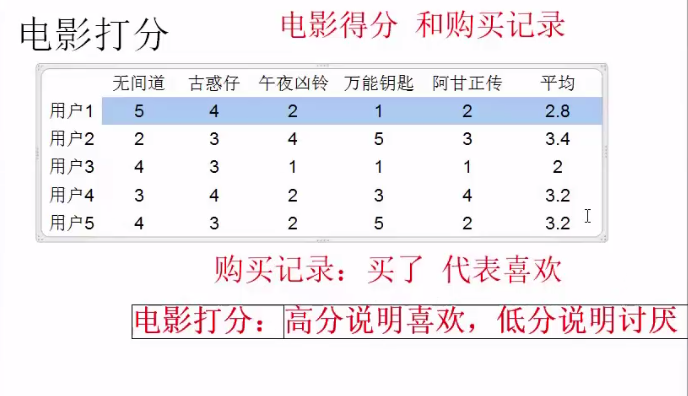
#有的人打分都高,有的人打分都低,我们就需要计算这个人打分的平均分,用每个分数减去平均分得到一个新的喜好表,大于0表示喜欢,小于0的表示不喜欢:
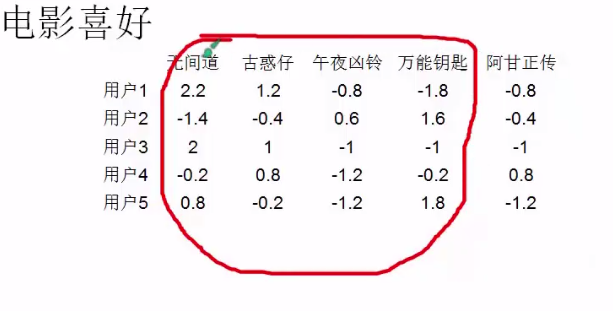
就是说低于自己平均分的电影,就是自己不太喜欢看的电影。
#相似的电影:对于一个人来说,如果两部电影要么都喜欢,要么都讨厌,那么就比较相似。比如对于用户1来说:无间道和古惑仔他都喜欢,就表示这两个电影相似。用户2来说。无间道与古惑仔他都不喜欢,也表明两部电影很相似。用户4呢?喜欢古惑仔,不喜欢无间道,就会出现干扰项。这种情况下我们就需要进行统计信息,把所有用户的观点进行集中,然后得到一个平均的值。
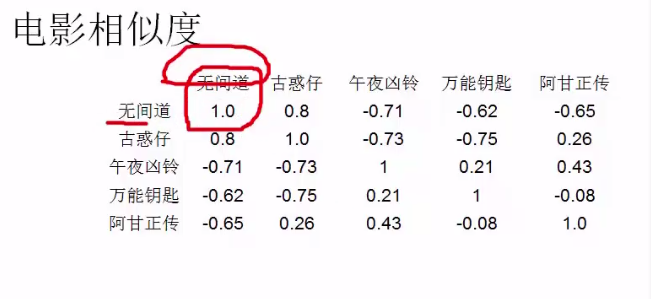
示例:相似程度

#计算两个变量(古惑仔,无间道)的线性相关性。相似度为正数时表示相关性很大,当出现A的时候就推荐B. 当相似度为负数的时候,相关性也很大(反相关性),当出现A的时候,一定不能推荐B.
#相除是消除电影自身对相似度的影响(相当于归一化的作用,消除数据大小的影响)
#正相关性:当吃羊肉串的时候==》推荐喝啤酒
#负相关性:当喝啤酒的时候一定不会推荐可乐
结果是这样的:
预测电影:
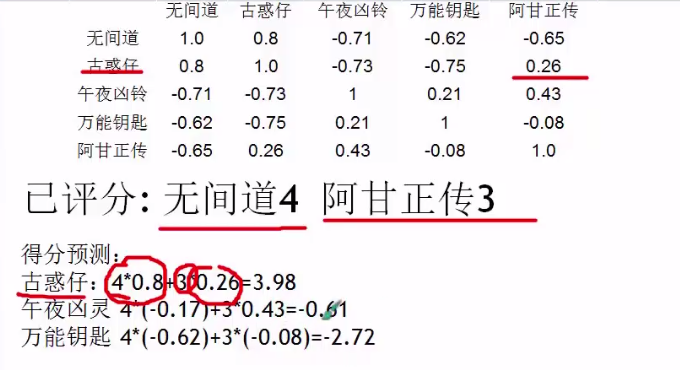
我们知道一个人对无间道的打分是4分,对阿甘正传的打分都是3分,那么我们可以根据上表电影的相关度计算古惑仔的得分预测:
古惑仔: 无间道的得分 * 无间道与古惑仔的相关度 + 阿甘的得分 * 阿甘与古惑仔的相关度=?
后面的类似,结果是正数表示喜欢,负数表示不喜欢,0表示无所谓,这样情况下肯定要推荐正数的,其次是0,这样就过滤掉了负数的电影--------》实现了协同过滤。
四、基于矩阵分解的协同过滤
方式
五、基于SVD的协同过滤
最后
以上就是追寻豆芽最近收集整理的关于机器学习之协同过滤机器学习之协同过滤的全部内容,更多相关机器学习之协同过滤机器学习之协同过滤内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复