Redis是一种高级key-value数据库。它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富。有字符串,链表,集 合和有序集合。支持在服务器端计算集合的并,交和补集(difference)等,还支持多种排序功能。所以Redis也可以被看成是一个数据结构服务 器。
Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为“半持久化模式”);也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为“全持久化模式”)。
第一种方法filesnapshotting:默认redis是会以快照的形式将数据持久化到磁盘的(一个二进 制文件,dump.rdb,这个文件名字可以指定),在配置文件中的格式是:save N M表示在N秒之内,redis至少发生M次修改则redis抓快照到磁盘。当然我们也可以手动执行save或者bgsave(异步)做快照。
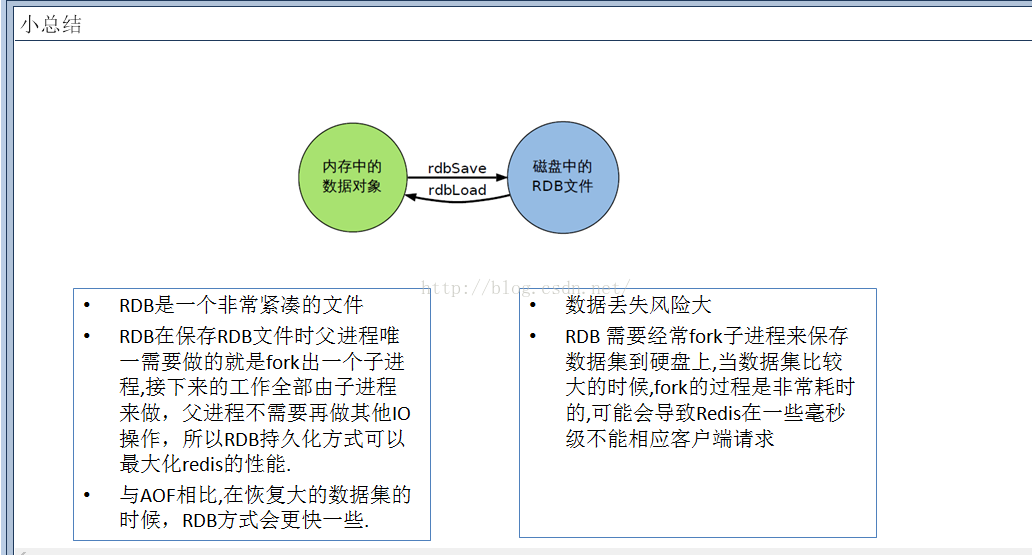
工作原理简单介绍一下:当redis需要做持久化时,redis会fork一个子进程;子进程将数据写到磁盘上一个临时RDB文件中;当子进程完成写临时文件后,将原来的RDB替换掉,这样的好处就是可以copy-on-write。
1.RDB是什么?
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件,待持久化过程结束后,再用这个临时文件替换上次持久化好的文件,整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那么RDB方式要比AOP方式更加的有效。RDB的缺点是最后一次持久化的数据可能丢失。
2.fork
fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量,环境变量,程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
3.rdb保存的是dump.rdb文件
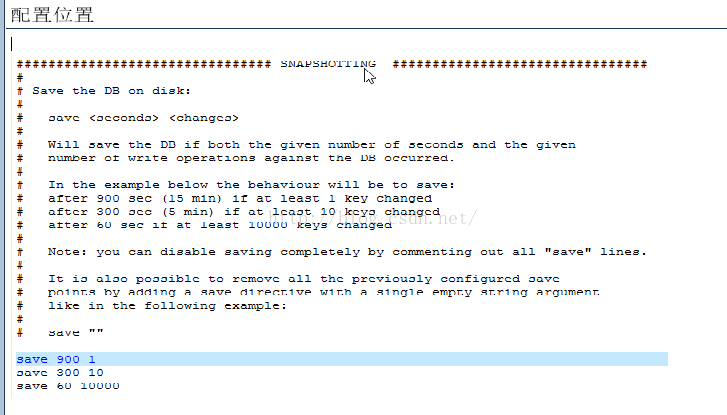
4.配置的位置
5.如何触发RDB快照
①配置文件中默认的快照配置
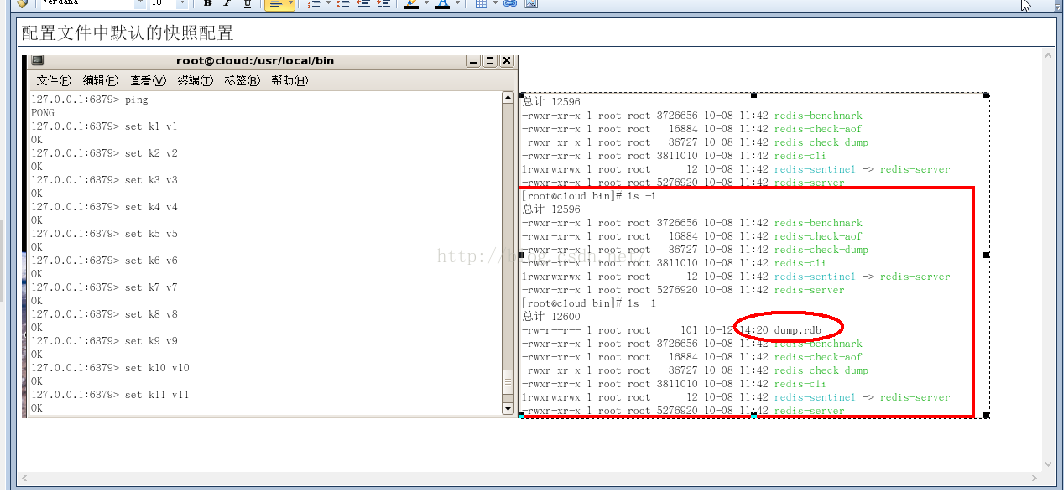
冷拷贝后重新使用,所谓冷拷贝,就是从这台机器拷贝到另外一台机器,以免发生硬件故障时,数据恢复受阻。
可以 cp dump.rdb dump_new.rdb
② 命令是save或者是bgsave
save:save时只管保存,其他的不管,全部阻塞
bgsave:redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave命令获取最后一次成功执行快照的时间
③执行flushall命令,也会产生dump.rdb文件,但里面是空的,也就是重启启动数据没有回复,所以无意义。
6.如何恢复?
将备份文件(dump.rdb或者是dump_new.rdb)移动到redis的安装目录并启动服务即可
config get dir 获取目录的路径
7.优势?
①适合大规模的数据恢复
②对数据的完整性和一致性要求不高
8.劣势?
在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改
fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
9.如何停止?
动态所有停止RDB保存规则的方法:redis-cli config set save ""
10.小总结
Snapshotting快照
①save
save 秒钟 写操作次数
RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件,默认是1分钟内改了1万次,或5分钟内改了10次,或15分钟内改了1次。
如何禁用?
如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以
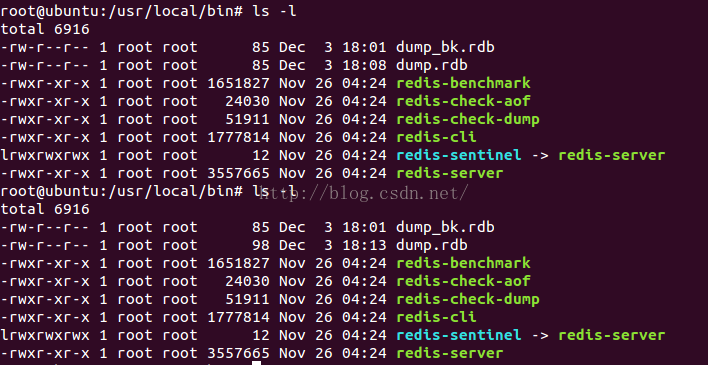
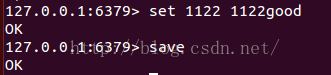
也就是说,当我们插入数据,立即执行save命令,会直接把数据写入到dump.rdb文件,上图显示了dump.rdb的时间变化
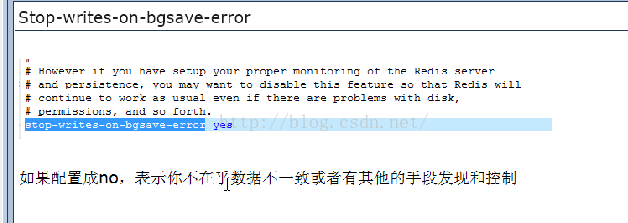
②stop-writes-on-bgsave-error
③ rdbcompression
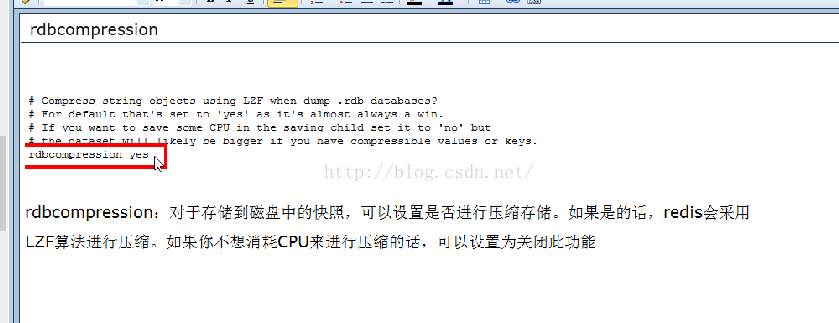
rdbcompression:对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能
④ rdbchecksum
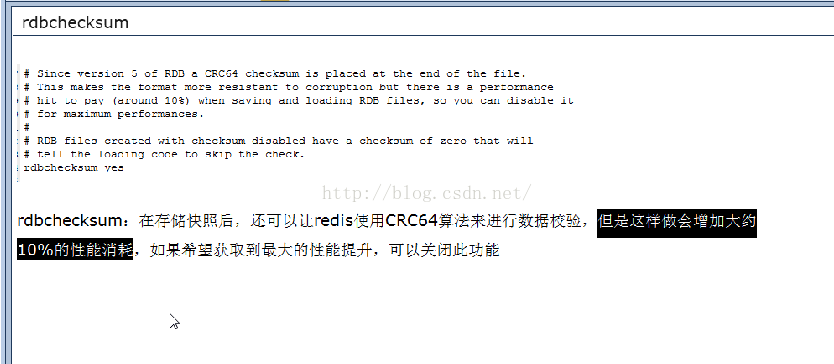
rdbchecksum:在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
⑤dbfilename
⑥dir
RDB的持久化的过程?
首先我们到指定的文件目录下,清除dump.rdb这里用的指令是:rm -f dump.rdb,然后用vim /myredis/redis.conf
进入配置文件,按i进行修改,由于时间关系,我们设置了2分钟内10次对数据的修改,此时需要再开启一个new terminal对数据进行插入,如下:
root@ubuntu:/home/kyl# cd /usr/local/bin
root@ubuntu:/usr/local/bin# redis-server /myredis/redis.conf
root@ubuntu:/usr/local/bin# redis-cli -p 6379
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> set k3 v3
OK
127.0.0.1:6379> set k4 v4
OK
127.0.0.1:6379> set k5 v5
OK
127.0.0.1:6379> set k5 v5
OK
127.0.0.1:6379> set k6 v6
OK
127.0.0.1:6379> set k7 v7
OK
127.0.0.1:6379> set k8 v8
OK
127.0.0.1:6379> set k9 v9
OK
127.0.0.1:6379> set k10 v10
OK
127.0.0.1:6379> keys *
1) "k9"
2) "k5"
3) "k8"
4) "k3"
5) "k4"
6) "k10"
7) "k2"
8) "k6"
9) "k7"
最后
以上就是高挑紫菜最近收集整理的关于redis持久化之----RDB(Redis DataBase )的全部内容,更多相关redis持久化之----RDB(Redis内容请搜索靠谱客的其他文章。








发表评论 取消回复