最近因为要学spark又开始玩linux了,在电脑上安装了VM Player 和 Ubuntu 18.04 - server开始折腾。为了安装spark、hive前需要先安装java,hadoop和scala,安装kafka前需要先安装Zookeeper。这里仅仅只是安装成功,使之能跑起来,不涉及其他配置和性能调优等。
使用的版本如下:
java版本:jdk-8u181-linux-x64.tar.gz
hadoop版本:hadoop-2.7.7.tar.gz
hive版本:apache-hive-2.3.3-bin.tar.gz
scala版本:scala-2.11.12.tgz(spark 2.3.x仅支持scala 2.11.x的版本)
spark版本:spark-2.3.1-bin-without-hadoop.tgz
zookeeper版本:zookeeper-3.4.13.tar.gz
kafka版本:kafka_2.11-2.0.0.tgz
目录
一、下载安装java
二、下载安装和配置hadoop
三、下载安装和配置hive
四、下载安装和配置spark
五、下载安装和配置Zookeeper
六、下载安装Kafka
一、下载安装java
1、从Oracle官网复制java下载地址,wget下载的格式是:
$ wget --no-check-certificate --no-cookies --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz2、解压文件至/opt
$ tar zxf jdk1.8.0-8u181-linux-x64.tar.gz
$ sudo mv jdk1.8.0_181 /opt/jdk1.8.0_1813、java环境变量设置:
(1)编辑 /etc/profile 文件,添加如下代码:
# Java Environment
export JAVA_HOME=/opt/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar(2)使文件生效:
$ source /etc/profile4、验证java是否安装成功:运行如下命令,如果出现java的版本号,则安装成功
$ java -version
$ javac -version
二、下载安装和配置hadoop
1、直接从hadoop官网获取下载地址,
$ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz解压hadoop包,将其移动至/opt:
$ tar zxf hadoop-2.7.7.tar.gz
$ sudo mv hadoop-2.7.7 /opt/hadoop-2.7.72、配置hadoop的环境变量:
$ sudo vim /etc/profile
在文件最后添加:
# Hadoop Environment
export HADOOP_HOME=/opt/hadoop-2.7.7
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export YADR_CONF_DIR=$HADOOP_HOME
export PATH=$PATH:/$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后保存文件,退出,并使之生效:
$ source /etc/profile执行以下命令,若有出现hadoop的版本号,则说明环境变量配置成功
$ hadoop version3、在hadoop配置文件里添加java路径:
$ sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
将:
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/opt/jdk1.8.0_1814、配置hadoop伪分布模式
【注:最好根据自己的hadoop版本去官网找对应的配置方法,以下是官网上2.7.6版本的配置方式】
(1)首先验证系统能否通过免密钥ssh登录:
$ ssh localhost若失败,则需要配置ssh免密钥登录,方法如下:(依次执行这三行命令,如果第一遍没成功就再执行一遍)
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 600 ~/.ssh/authorized_keys(2)接下来修改hadoop的两个配置文件:
首先新建一个tmp目录(这个目录用来存储NameNode的format信息,避免每次启动hdfs时都需重新格式化NameNode):
$ mkdir /opt/hadoop-2.7.7/hadooptmp对 core-site.xml 文件:
$ sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml添加如下配置:(这里增加了tmp目录的配置)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.7/hadooptmp</value>
</property>
</configuration>hdfs-site.xml文件:
$ sudo vim /$HADOOP_HOME/etc/hadoop/hdfs-site.xml
添加如下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>配置完成。
5、运行hadoop
(1)格式化文件系统:
$ $HADOOP_HOME/bin/hdfs namenode -format(2)启动NameNode和DataNode的守护进程:
$ $HADOOP_HOME/sbin/start-dfs.sh(3)执行启动命令之后,稍等1~2分钟,等待hadoop启动完成,即可使用浏览器在Web端看到Hadoop NameNode的信息,默认在: http://localhost:50070/ ;
(4)运行MapReduce job 需要创建HDFS目录:
$ $HADOOP_HOME/bin/hdfs dfs -mkdir /user
$ $HADOOP_HOME/bin/hdfs dfs -mkdir /user/<username>(5)复制输入文件到分布式文件系统:
$ $HADOOP_HOME/bin/hdfs dfs -put etc/hadoop input(6)运行一些 内置的示例程序:
$ $HADOOP_HOME/bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input output 'dfs[a-z.]+'(7)测试输出文件:
从分布式文件系统复制输出文件到本地再测试:
$ $HADOOP_HOME/bin/hdfs dfs -get output output
$ cat output/*或,直接在分布式文件系统查看输出文件:
$ $HADOOP_HOME/bin/hdfs dfs -cat output/*(8)完成后,记得关闭守护进程:
$ $HADOOP_HOME/sbin/stop-dfs.sh6、yarn在hadoop伪分布模式的配置:
在完成了【5、运行hadoop】的(1)~(4)步骤后,可以进行yarn的配置。
(1)mapred-site.xml文件:
$ vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
添加如下代码:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml文件:
$ vim $HADOOP_HOME/etc/hadoop/yarn-site.xml:
添加如下代码:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(2)启动ResourceManager守护进程和NodeManager守护进程:
$ $HADOOP_HOME/sbin/start-yarn.sh(3)Yarn启动完成后,即可从Web端查看ResourceManager,默认地址是:
http://localhost:8088/(4)现在可以执行一个MapReduce任务了;
(5)最后,需要关闭守护进程:
$ $HADOOP_HOME/sbin/stop-yarn.sh
三、下载安装和配置hive
1、下载hive:直接用wget从官网下载即可:
$ wget http://mirror.bit.edu.cn/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz2、解压hive安装包到 /opt
$ tar zxf apache-hive-2.3.3-bin.tar.gz
$ sudo mv apache-hive-2.3.3-bin /opt/hive-2.3.33、配置hive的环境变量
$ sudo vim /etc/profile
添加:
# Hive Environment
export HIVE_HOME=/opt/hive-2.3.3
export PATH=$PATH:$HIVE_HOME/bin4、启动hive
(1)启动hive之前,先确定hadoop安装路径以添加至系统路径(PATH)中;
(2)必须使用下列HDFS命令创建 /tmp 和 /user/hive/warehouse (aka hive.metastore.warehouse.dir)并设置权限g+w:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse(3)运行hive CLI (Hive Commond Line Interface):
$ $HIVE_HOME/bin/hive若能够成功启动则说明配置成功。
Hive的一些服务的启动:
(4)运行HiveServer2 和 Beeline:
从Hive 2.1开始,需使用如下的schematool命令作为初始化的步骤。例如,可以使用“derby”作为db类型:
$ $HIVE_HOME/bin/schematool -dbType <db type> -initSchemaHiveServer2有它自己的CLI,称为Beeline。运行HiveServer2和Beeline:
$ $HIVE_HOME/bin/hiveserver2
$ $HIVE_HOME/bin beeline -u jdbc:hive2://#HS2_HOST:#H2_PORT为了测试,也可以将Beeline和HiveServer2在同一个进程启动:
$ $HIVE_HOME/bin/beeline -u jdbc:hive2://(5)运行HCatalog:
在Hive 0.11.0之后的版本运行HCatalog服务:
$ $HIVE_HOME/hcatalog/sbin/hcat_server.sh在Hive 0.11.0之后的版本运行HCatalog CLI:
$ $HIVE_HOME/hcatalog/bin/hcat(6)运行WebHCat:
在Hive 0.11.0之后的版本运行WebHCat服务:
$HIVE_HOME/hcatalog/sbin/webhcat_server.sh
四、下载安装和配置spark
1、首先需要先下载安装scala。
(1)在浏览器打开如下网址,即可下载:(spark-2.3.1支持 scala 2.11.x的版本)
http://downloads.typesafe.com/scala/2.11.12/scala-2.11.12.tgz(2)解压scalar到 /opt:
$ tar zxf scala-2.11.12.tgz
$ sudo mv scala-2.11.12 /opt/scala-2.11.12(3)配置scala环境变量:
$ sudo vim /etc/profile
添加:
# Scala Environment
export SCALA_HOME=/opt/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
(4)验证,若出现scala的版本号及命令行则说明安装成功:
$ scala(5)退出scala命令行:(输入 :quit)
scala> :quit2、下载spark,我因为已经安装了hadoop,所以使用的是无hadoop的spark
$ wget http://mirror.bit.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-without-hadoop.tgz3、解压安装包至 /opt:
$ tar zxf spark-2.3.1-bin-without-hadoop2.7.tgz
$ sudo mv spark-2.3.1-bin-without-hadoop2.7 /opt/spark-2.3.14、配置spark环境变量:
(1)编辑 /etc/profile文件,添加:
# Spark Environment
export SPARK_HOME=/opt/spark-2.3.1
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
保存,并退出,source使之生效:
$ source /etc/profile(2)编辑$SPARK_HOME/conf/spark-env.sh文件,现将spark-env.sh.tmplate复制为spark-env.sh:
$ cd $SPARK_HOME/conf/
$ cp spark-env.sh.template spark-env.sh然后在 spark-env.sh 文件的最后添加:
export SPARK_DIST_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)保存并退出即可。
接下来验证配置,执行:
$ start-master.sh然后使用浏览器打开网址:http://localhost:8080,如果出现spark监控界面则说明spark已经成功启动。
也可以执行 spark-shell 命令,出现如下图结果则说明spark已经成功启动(这里我也不知道为什么scala版本变成了2.11.8):
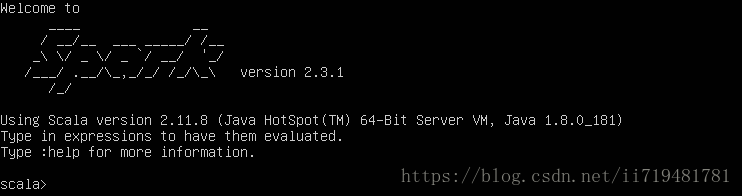
到此为止,spark的安装就全部完成了。
注意:这里只是完成了基本的安装,使用的全部都是默认的配置,之后还可以对spark进行一些高级设置,如设置容量、内存等,将在之后的学习中陆续配置。
五、下载安装和配置Zookeeper
安装Kafka之前应先安装Zookeeper。
1、直接从官网下载Zookeeper:
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz2、解压安装包到 /opt:
$ tar zxf zookeeper-3.4.13.tar.gz
$ sudo mv zookeeper-3.4.13 /opt/zookeeper-3.4.133、设置环境变量
$ sudo vim /etc/profile
添加:
# Zookeeper Environment
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.13
export PATH=$PATH:$ZOOKEEPER_HOME/bin4、配置zoo.cfg文件,使用默认设置即可(直接将zoo_sample.cfg文件复制为zoo.cfg):
$ cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg5、启动zookeeper,验证配置是否成功:
$ $ZOOKEEPER_HOME/bin/zkServer.sh start出现success字样即为启动成功。
这里的Zookeeper运行的是单节点模式,不能复制(文档原文是no replication),所以当Zookeeper运行失败时,服务会挂掉。
六、下载安装Kafka
1、下载Kafka
$ wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz2、解压到 /opt:
$ tar zxf kafka_2.11-2.0.0.tgz
$ sudo mv kafka_2.11-2.0.0 /opt/kafka-2.11-2.0.03、配置环境变量,并使之生效:
$ sudo vim /etc/profile
添加:
export KAFKA_HOME=/opt/kafka-2.11-2.0.0
export PATH=$PATH:$KAFKA_HOME/bin4、启动Kafka进行验证:
$ $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties如果要关闭,可使用Ctrl+C来停掉。
至此,Kafka的安装就完成了。
最后
以上就是刻苦钥匙最近收集整理的关于Ubuntu 18.04安装hive、spark和kafka一、下载安装java二、下载安装和配置hadoop三、下载安装和配置hive四、下载安装和配置spark五、下载安装和配置Zookeeper六、下载安装Kafka的全部内容,更多相关Ubuntu内容请搜索靠谱客的其他文章。








发表评论 取消回复