ubuntu20.04 hadoop3.1.4安装
- 1、SSH安装
- 2、jdk安装
- 下载jdk
- 3、Hadoop安装
- 4、配置伪分布式环境
1、SSH安装
-
先把软件源更改成阿里巴巴的软件源

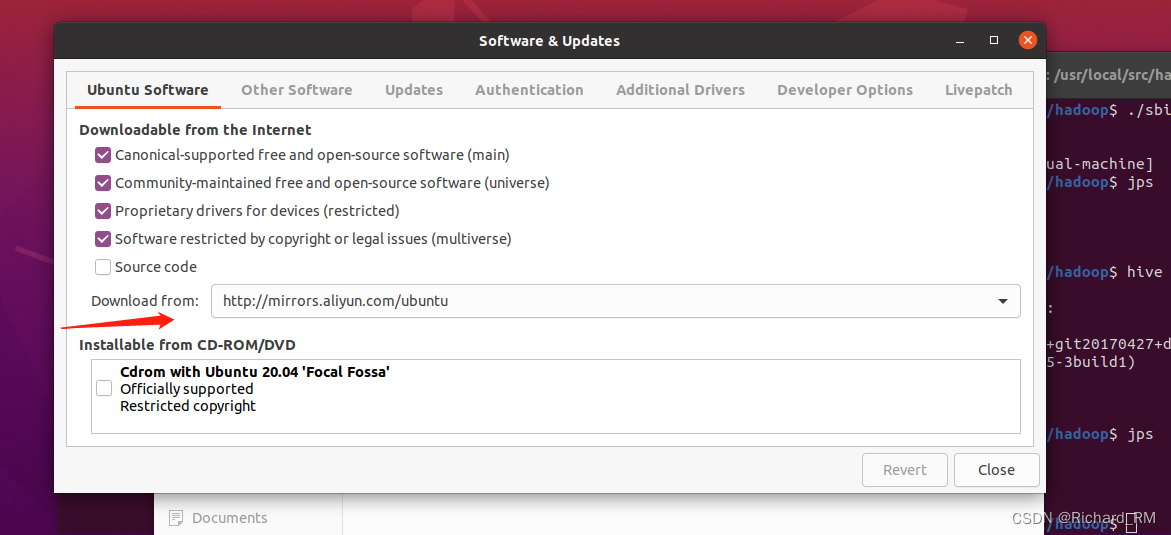
-
更新完之后,打开命令终端,输入命令
sudo apt-get update -
打开终端输入
安装vim
sudo apt-get install vim
- 配置SSH免密,不配置免密,每次启动都要输入密码
sudo apt-get install openssh-server
-
然后在终端输入
ssh localhost,登录主机,要输入yes -
在终端输入exit退出主机
-
在终端输入
cd ~/.ssh/,进入到ssh里面 -
然后在终端输入
ssh-keygen -t rsa,然后无脑按下四次回车 -
终端输入
cat ./id_rsa.pub >> ./authorized_keys,这是加入授权免密
2、jdk安装
下载jdk
- https://www.123pan.com/s/xPY9-YLlvH 密码8899
下载完成后,cd进入下载目录,解压文件,在终端输入
sudo tar -zxvf (后面是你jdk安装包的名字)
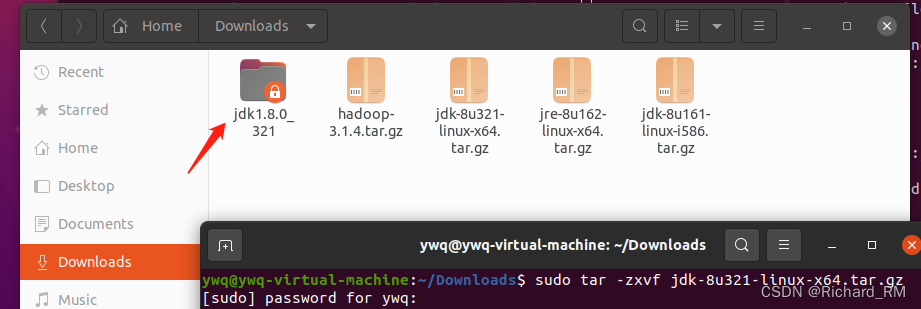 2. 将解压后的文件夹命名为jdk,然后终端输入
2. 将解压后的文件夹命名为jdk,然后终端输入
sudo mv jdk /usr/local/src
移动文件到 /usr/local/src
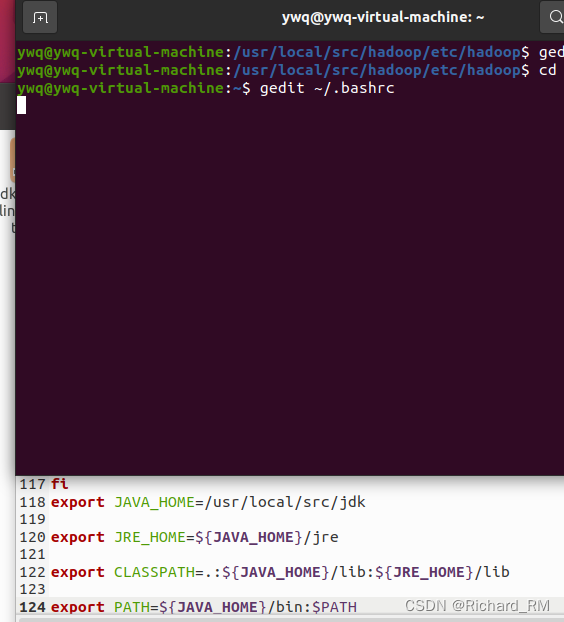
3. 设置jdk的环境变量,先输入cd回到home,然后输入gedit ~/.bashrc
- 在文件最后加入
export JAVA_HOME=/usr/local/src/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
5. 终端输入source ~/.bashrc,作用是让刚刚的环境代码生效
6. 终端输入java -version,查看是否安装成功
3、Hadoop安装
1.下载Hadoop
下载地址3.1.4
2. cd 到下载目录,输入 tar -zxvf (hadoop安装包的名字)解压,重命名为hadoop 步骤和安装jdk一样
3. 终端输入sudo mv hadoop /usr/local/src 然后输入cd /usr/local/src ,再然后ls查看
4. 输入cd hadoop 进入hadoop里面,然后再输入./bin/hadoop version即可查看版本号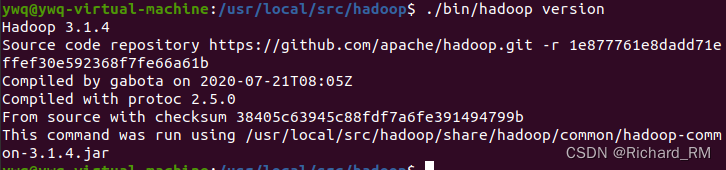
4、配置伪分布式环境
- 配置伪分布式环境,在/usr/local/src/hadoop这个路径里面,输入
gedit ./etc/hadoop/core-site.xml命令直接修改文件
将框内替换为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
保存退出
2. 同样再次输入gedit ./etc/hadoop/hdfs-site.xml命令直接修改文件
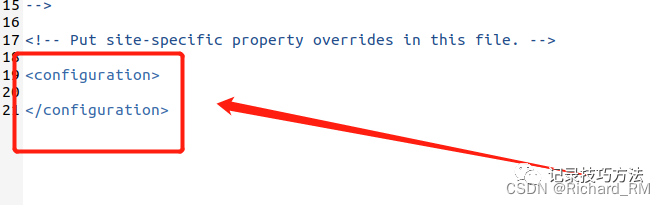
替换为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/tmp/dfs/data</value>
</property>
</configuration>
保存退出
3. 终端输入格式化命令./bin/hdfs namenode -format
这里如果出现错误 ERROR: JAVA_HOME is not set and could not be found.
需要cd 进入hadoop目录下输入 gedit etc/hadoop/hdoop-env.sh
输入 JAVA_HOME的路径
export JAVA_HOME=/usr/local/src/jdk
4.输入启动命令 ./sbin/start-dfs.sh
5. 启动后,输入jps查询是否有进程
6.浏览器输入 http://localhost:9870 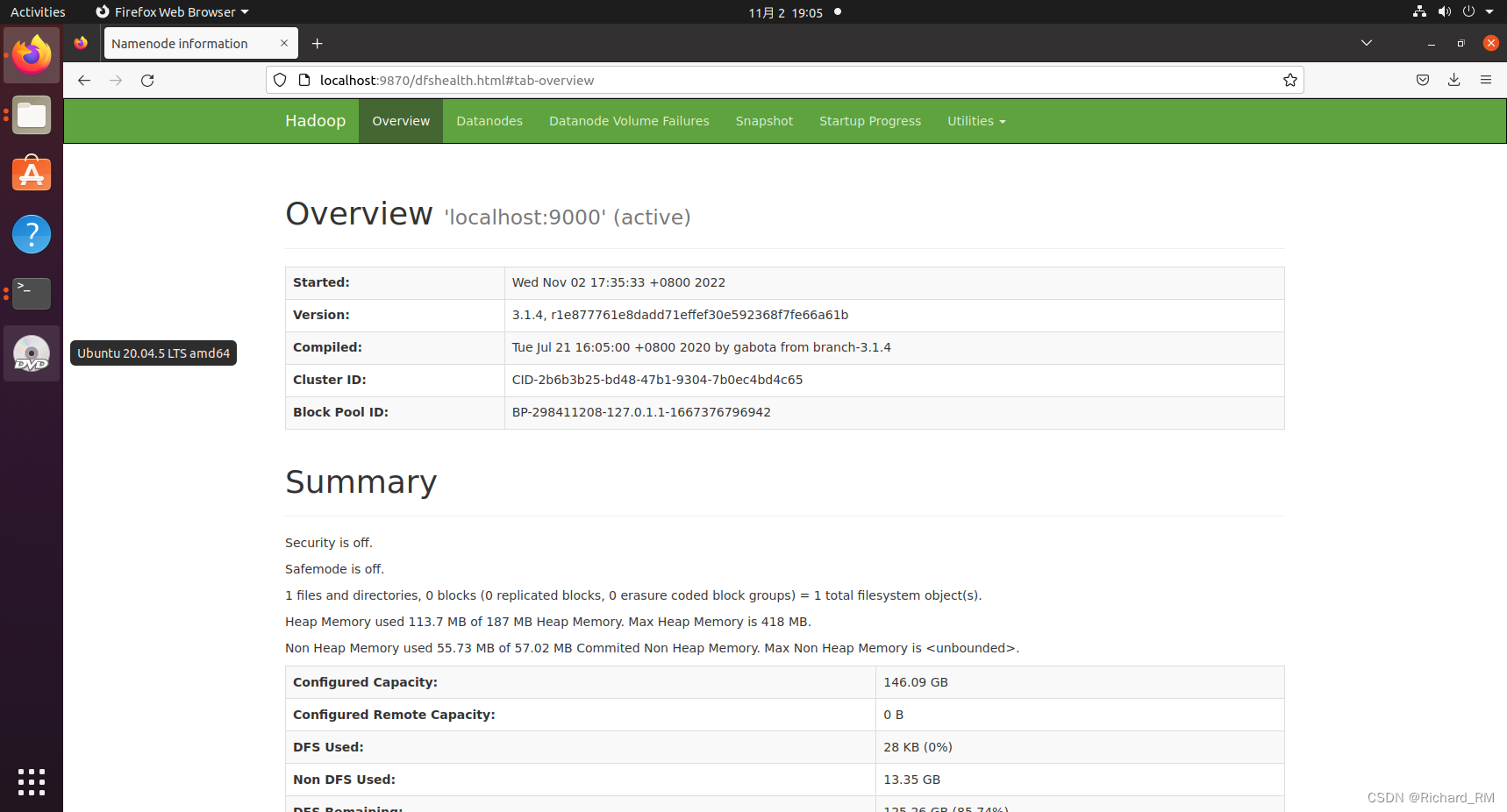
欧克欧克装完了
7.结束进程
输入 stop-all.sh
参考
https://blog.csdn.net/Mr_M1/article/details/119635447
https://blog.csdn.net/zqq_2016/article/details/105864177
最后
以上就是激昂煎蛋最近收集整理的关于【ubuntu20.04 hadoop3.1.4安装】1、SSH安装2、jdk安装3、Hadoop安装4、配置伪分布式环境的全部内容,更多相关【ubuntu20.04内容请搜索靠谱客的其他文章。








发表评论 取消回复