前言
有人说细节决定成败,或者说别人注重的是结果,我们在意的是过程,roomCompilerProcessing源码读起来感觉好难哦,尤其细节处!!!
下面三浅一深,咳咳咳…由浅入深讲解roomCompilerProcessing源码。
下面每个部分,自己认真写,读者认真看。个人建议,可以在深入一点:在理解大框架的基础上,不要忽略细节部分(提醒自己和读者),否则自己想写出高逼格代码照样很难!!!

APT、KAPT和KSP的理解
简介
- apt:Annotation Processing Tool
- 需要apply相应的android-apt插件,比如apply plugin: ‘com.neenbedankt.android-apt’。android gradle插件版本2.2以下使用,2.2发版时宣布不再维护。只支持 javac编译方式。
- annotationProcessor:已经取代apt
- 无需apply android-apt插件。android gradle插件版本2.2及以上使用。同时支持javac和jack编译方式;
- kapt:Kotlin Annotation Processing Tool
-
kotlin注解处理工具。因kotlin-kapt不是android gradle内置插件,需要额外apply plugin: ‘kotlin-kapt’
-
和annotationProcesor的区别是,kapt处理kotlin文件,当然如果是kotlin或java混合,那么也是必须使用kapt处理的。速度上交apt(或annotationProcessor)肯定要慢的,因为首先会将kotlin解析成Java代码,再通过apt处理;
- ksp:Kotlin Symbol Processing
-
在进行Android利用开发时Kotlin 的编译速度慢,而KAPT 便是拖慢编译的首恶之一。Android的很多库都会应用注解简化模板代码,著名的有 Room、Dagger 等,而默认状况下Kotlin 应用的是 KAPT 来解决注解的。KAPT没有专门的注解处理器,须要借助APT实现的,因而须要先生成 APT 可解析的 stub (Java代码),这拖慢了 Kotlin 的整体编译速度。
-
KSP 正是在这个背景下诞生的,它基于 Kotlin Compiler Plugin(简称KCP) 实现,不须要生成额定的 java代码,编译速度是 KAPT 的 2 倍以上。
以上文字多数抄袭,融入了个人观点,为了让我们简单了解一下各个编译的区别。
demo
AbstractProcessor
kapt和annotationProcessor的使用完全一致。
@AutoService(Processor.class) //自动生成注解处理器路径文件
public class BindingProcessor extends AbstractProcessor {
init(ProcessingEnvironment processingEnv):初始化操作
getSupportedSourceVersion():设置版本
getSupportedAnnotationTypes():设置支持的注解
process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv):主要的注解元素解析方法
}
没有AbstractProcessor基础的,可参考Java学习之注解(五)Android循序渐进实现高逼格自定义ViewBinder。
SymbolProcessor
interface SymbolProcessor {
//处理节点
fun process(resolver: Resolver): List<KSAnnotated>
//处理结束
fun finish() {}
//处理异常
fun onError() {}
}
具体实现如下:
class RoomKspProcessor @JvmOverloads constructor(
symbolProcessorEnvironment: SymbolProcessorEnvironment
) : SymbolProcessor {
//继承SymbolProcessor三个方法,懒得写。。。
//ksp内部会调用当前类的create方法,用于生成RoomKspProcessor对象
class Provider : SymbolProcessorProvider {
override fun create(environment: SymbolProcessorEnvironment): SymbolProcessor {
return RoomKspProcessor(environment)
}
}
}
由上可知,AbstractProcessor和SymbolProcessor还是有所区别的:
-
AbstractProcessor中的处理顺序是:先init,再getSupportedAnnotationTypes当前需要处理的注解;然后调用process处理注解;
-
SymbolProcessor:先直接调用process处理;如果完成调用finish,否则调用onError做异常处理;
-
AbstractProcessor判断是否完成全部处理的办法:在process方法有个参数RoundEnvironment,该参数提供processingOver方法判断当前处理是否完毕;
-
SymbolProcessor如果也想要init初始化,那么可以在process方法中调用;
-
AbstractProcessor的使用时继承当前类并且使用@AutoService(Processor::class)注解修饰该类;SymbolProcessor是继承该类,使用SymbolProcessorProvider的create实例化使用该ksp处理注解的类;
-
SymbolProcessor方法中没有getSupportedAnnotationTypes方法(支持处理的注解),所以可以直接在process方法中定义需要处理的注解;
以上就相当于一个demo的讲解了,由于个人感觉不难,所有没这方面知识的读者可以自行去了解。
roomCompilerProcessing架构循序渐进
引子
如果按照以上demo的用法,我们以AbstractProcessor的使用为例:
如果需要处理的注解非常多,怎么办;而且每个(或者每一类)注解又有自己的意义,我们不可能所有的注解放一起,在getSupportedAnnotationTypes中一次性表达全部需要处理的全部注解,再在process一次性处理;
roomCompilerProcessing的诞生能很好解决这个问题,将不同的注解分类并且对当前分类处理,那么怎么做呢?
甄别注解,并且对不同类型注解处理
以下手敲版,不要过于在意代码,主要是代码中溢出的杀气…咳咳咳,思想才是最重要的。
-
定义step接口用于收集某一类注解并且对该类注解处理:
public interface Step{ //收集当前step处理的注解 public Set<String> getAnnotations(); //处理当前收集到的注解集合的具体业务逻辑,返回当前被拒绝处理的节点 public List<TypeElement> process(ProcessingEnv env,Set<Element>); } -
定义一个抽象类BasicProcessor继承AbstractProcessor,收集Step:
public abstract BasicProcessor extends AbstractProcessor{ List<Step> processingSteps(); //预留一个注解处理完成的方法,继承者用就用,不用就算了 void postOverRound(MultableSet<TypeElement> annotations,RoundEnvironment rounEnv){} List<Step> steps; final override void init(ProcessingEnvironment processingEnv){ super.init(processingEnv); steps = processingSteps(); } override Set<String> getSupportedAnnotationTypes(){ steps.flatMap { it.annotations() }.toSet(); } override boolean process(MultableSet<TypeElement> annotations,RoundEnvironment rounEnv){ if (roundEnv.processingOver()) { postOverRound(annotations,rounEnv); } steps.stream().forEach(step ->{ step.process(); }); } } -
Step实例StepInstall:
public StepInstall interface Step { override Set<String> getAnnotations{ //表示当前收集的是Database注解 mutableSetOf(Database.qualifiedName) } override Set<TypeElement> process(ProcessingEnv env,Set<Element>){ //当前处理的就是Database注解的业务场景 ... //当前被拒绝处理的节点 return rejectedElements; } } -
AbsractProcessor实例:
public RoomProcessor extends BasicProcessor { override List<Step> processingSteps(){ listof(StepInstall()); } override SourceVersion getSupportedSourceVersion(){ return SourceVersion.latest(); } }
写的不是很好,但是那种高逼格意境表达出来了!!!
扩展:延迟或拒绝处理的节点
什么情况下注解处理的节点需要延迟处理或拒绝处理呢?
-
节点尚没有生成,又称为无效节点,需要延时处理;
-
在Step处理过程中,根据业务需求,被拒绝处理的节点;
揍一顿比方给大家看下:
-
@Annotation1注解修饰的类,经过Step1处理生成了@Annotation2修饰的类。Step2刚好可以处理@Annotation2注解(如果这个@Annotation2修饰的节点是一个特定类,很重要,比如就叫SpecialCoolMan,在未生成这个SpecialCoolMan的情况下就属于无效节点)。
-
而又由于每个原因(Step2的process里有个业务场景,可能感觉这个@Annotation2修饰的当前类存在private修饰的变量,感觉它太特么小气,搞的我没面子,那我就不给他处理了,这个@Annotation2修饰的类就被叫做拒绝节点),当前Step2拒绝处理这个@Annotation2修饰的类。
对以上场景理解一番:
-
奔着尊重代码原则(那如果不尊重Step2在Step1前执行是否完全没问题呢,往下看有答案):Step1还是先一步执行,再去执行Step2;
-
BasicProcessor类中有两个变量:(1)收集所有Step中被拒绝处理的节点;(2)收集所有Step中的无效节点;
-
BasicProcessor process方法会依次执行Step process方法:(1)处理当前注解的业务逻辑;(2)之前积累的被Step拒绝的节点和无效节点是否使用了当前Step的注解,如果是则处理;再收集当前Step被拒绝的节点和无效节点。直到所有Step都处理完毕!
-
我们在BasicProcessor的process方法中根据RoundEnvironment.processingOver判断是否执行完毕,如果执行完毕,那么将所有无效节点和被Step拒绝处理的节点再次在所有Step中处理一遍,会产生两种情况:(1)全部处理完毕,万事大吉;(2)还存在无效节点和被拒绝处理节点那么只能报错了;
- 这个步骤我们知道,其实Step的顺序是无所谓的,但是我们还是应该尊重一下次序,这样在处理过程中可能会快点!
代码实现
public abstract BasicProcessor extends AbstractProcessor{
//收集无效节点
private List<Element> deferredElement = new ArrayList();
//收集被Step拒绝处理的节点
private Map<Step,List<String>> rejectedElementBySteps = new Map();
List<Step> processingSteps();
//预留一个注解处理完成的方法,继承者用就用,不用就算了
void postOverRound(MultableSet<TypeElement> annotations,RoundEnvironment rounEnv){}
List<Step> steps;
final override void init(ProcessingEnvironment processingEnv){
super.init(processingEnv);
steps = processingSteps();
}
override Set<String> getSupportedAnnotationTypes(){
steps.flatMap { it.annotations() }.toSet();
}
override boolean process(MultableSet<TypeElement> annotations,RoundEnvironment rounEnv){
//注解处理完毕
if (roundEnv.processingOver()) {
postOverRound(annotations,rounEnv);
//处理完成后,对剩下的无效节点和拒绝节点再次在所有Step中处理一遍
steps.forEach { step ->
//和下面的雷同
...
}
}
steps.forEach(step ->{
//前面无效节点,是否使用了当前step的注解,使用了,则返回这些节点信息
Map<String,Set<Element>> previousRoundDeferredElemens = getSetpElementsByAnnotation(step,deferredElement);
//所有前面step拒绝处理的节点
Map<String,Set<Element>> stepDeferredElementsByAnnotation = getSetpElementsByAnnotation(step,rejectedElementBySteps被step拒绝处理的所有节点);
//添加被Step拒绝节点
rejectedElementBySteps.add(step,step.process(当前step注解使用的节点 + 前面拒绝节点(该节点使用当前step注解) + 前面无效节点(该节点使用了当前step注解)));
});
}
//根据传递进来的节点集合,查找当前节点是否使用了当前step的注解,筛选当前注解修饰的节点集合
private Map<String,Set<Element>> getSetpElementsByAnnotation(Step step,Set<String> typeElementNames){
if (typeElementNames.isEmpty()) {
return emptyMap()//空
}
Map<String,List<String>> elementsByAnnotation = new HashMap();
List<String> stepAnnotations = step.annotations();
typeElementNames.forEach { typeElement ->
typeElement.getAllAnnotations().map { it.qualifiedName }
.forEach { annotationName
if(stepAnnotations.contains(annotationName)){
List<Element> elements = elementsByAnnotation.getKey(annotationName) ;
if(elements == null){
elements = new ArrayList();
}
elements.add(typeElement);
elementsByAnnotation.put(annotationName,elements);
}
}
}
return elementsByAnnotation;
}
}
扩展:节点树状图
注解修饰的节点,该节点包含其他节点,节点又包含另外节点,形成一个树状结构。demo:一个注解修饰的类中包含包含变量和方法,变量又是一个类,方法可能包含泛型,另外还有方法使用了新的注解等等。如何体现这种树状结构。
如下所示,可以根据这个图自行往下深入了解:难度不大,花点心思即可。
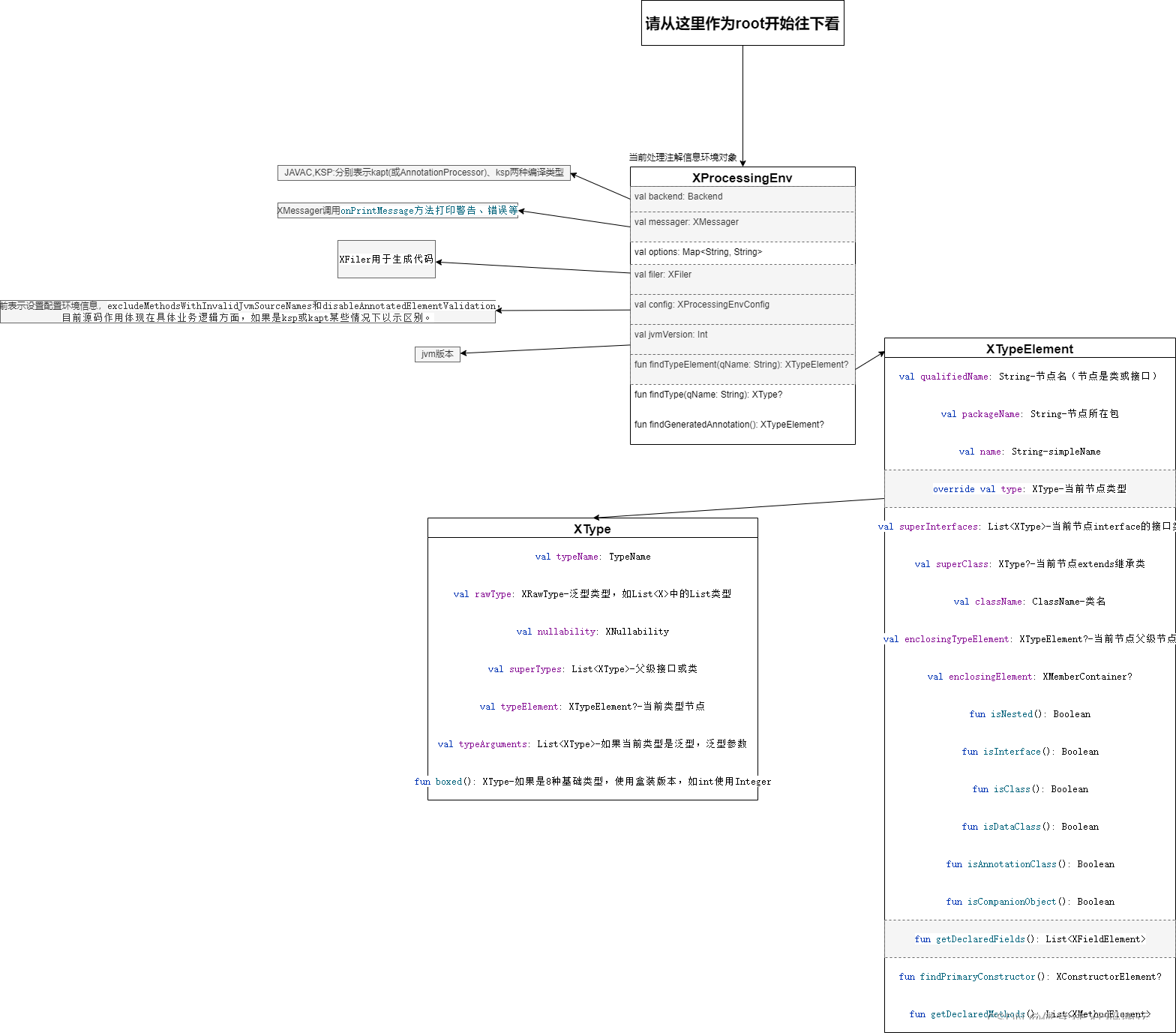
上图不做解释,有几点有必要说明:
当前必须在理解如Message、Filer、Type、Element等类的基础上,即这里相当于基础类的X系列;
-
为什么使用X系列,个人理解:(1)RoomCompilerProcessing处理Kapt和ksp两种编译方式,X系列相当于一个接口模式,kapt和ksp对接口的实现只需要继承X系列接口即可,具体实现根据自身kapt和ksp实际也无需求;(2)Message、Filter、Type基本类型可能后续会改成X系列(XMessage、XFiler);
kapt和ksp
ksp使用的是KspBasicAnnotationProcessor类;kapt使用的是KotlinBasicAnnotationProcessor。
KspBasicAnnotationProcessor类继承SymbolProcessor;KotlinBasicAnnotationProcessor继承了AbstractProcessor;
代码方面存在细微差别,但是业务逻辑是一致的,我们这里仅仅针对KotlinBasicAnnotationProcessor做简单讲解。
另:当前源码体积主要还是体现在节点树状图上面,其他代码体量不大。
KotlinBasicAnnotationProcessor源码简介:
- init:生成JavacProcessingEnv对象,该对象中存在大量操作节点和类型代码,节点和类型通过缓存处理,方便二次处理可直接获取(下面会简单介绍缓存用法);
- XMessage的具体实现类是JavacProcessingEnvMessager,XFile的具体实现类是JavacFiler。使用了非常典型的模式:代理模式。
-
getSupportedAnnotationTypes:通过processingSteps方法收集所有待处理的注解;
-
process:使用CommonProcessorDelegate对象处理注解信息:
- (1)对steps收集的注解(还有上个步骤拒绝处理节点和无效节点判断是否使用了当前注解,如果使用了则一并处理)步骤遍历处理;
- (2)收集steps注解步骤中拒绝处理节点;
- (3)收集steps注解步骤中的无效节点;
- (4)根据RoundEnvironment的processingOver方法判断是否执行完毕,如果执行完毕,再对steps剩余的拒绝节点和无效节点再次遍历steps去处理;
扩展: 缓存
每次处理的节点都会根据节点名称去XTypeElementStore对象中查找,如果存在直接烦,否则根据当前节点名存储在XTypeElementStore对象中。
当前对象单独列出来,原因之一就是这里kotlin的写法,值得我们借鉴(kotlin我不是太熟悉,这个写法我感觉很酷)。当然原因之二是节点存取都绕不开当前存储对象。
总结
这里对源码的解说非常酸爽。因为结构性非常明显,代码也非常值得我们去揣摩。
相对注解有进一步了解的,可以去看Dagger源码系列解析
这里github源码地址,别忘了是room标签。
最后
以上就是笑点低星星最近收集整理的关于13.从架构设计角度分析AAC源码-Room源码解析第2篇:RoomCompilerProcessing源码解析前言APT、KAPT和KSP的理解roomCompilerProcessing架构循序渐进总结的全部内容,更多相关13.从架构设计角度分析AAC源码-Room源码解析第2篇:RoomCompilerProcessing源码解析前言APT、KAPT和KSP内容请搜索靠谱客的其他文章。








发表评论 取消回复