1. 推荐方法: 使用entrySet 遍历Map 类集合KV,而不是keySet 方式进行遍历。
代码示例如下:
// 循环第二种
HashMap<Integer, String> map = new HashMap<Integer, String>();
for (int i = 0; i < 10000000; i++) {
map.put(i, "第" + i + "个");
}
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
for (Map.Entry<Integer, String> entry : entrySet) {
entry.getValue();
}
原因::keySet 其实是遍历了2 次,一次是转为Iterator 对象,另一次是从hashMap 中取出key 所对应的value。而entrySet 只是遍历了一次就把key 和value 都放到了entry 中,效率更高。如果是JDK8,使用Map.foreach 方法。
2. 四种方法对比
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<Integer, String>();
for (int i = 0; i < 10000000; i++) {
map.put(i, "第" + i + "个");
}
//循环第一种
long t1 = System.nanoTime();
Object key[] = map.keySet().toArray();
for (int i = 0; i < map.size(); i++) {
map.get(key[i]);
}
long t2 = System.nanoTime();
// 循环第二种
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
for (Map.Entry<Integer, String> entry : entrySet) {
entry.getValue();
}
long t3 = System.nanoTime();
// 循环第三种
Iterator<Integer> it = map.keySet().iterator();
while (it.hasNext()) {
Integer ii = (Integer) it.next();
map.get(ii);
}
long t4 = System.nanoTime();
// 循环第四种
Set<Integer> keySet = map.keySet();
for (Integer kk : keySet) {
map.get(kk);
}
long t5 = System.nanoTime();
System.out.println("第一种方法耗时:" + (t2 - t1) / 1000 + "微秒");
System.out.println("第二种方法耗时:" + (t3 - t2) / 1000 + "微秒");
System.out.println("第三种方法耗时:" + (t4 - t3) / 1000 + "微秒");
System.out.println("第四种方法耗时:" + (t5 - t4) / 1000 + "微秒");
}
输出结果(1000万条数据):
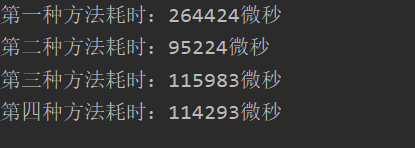
参考:
HASHMAP的四种遍历方法,及效率比较(简单明了)
Java中遍历ConcurrentHashMap的四种方式
最后
以上就是文静鸡最近收集整理的关于java中遍历HashMap的四种方法及效率比较的全部内容,更多相关java中遍历HashMap内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复