从前面一系列的基础部署教程中,可以看到大数据集群的部署中,为了保证集群的高可用性,一般都会配置 Zookeeper,比如 Kafka 集群的搭建中,就添加了 Zookeeper 配置。所以这篇补充一下 Zookeeper 集群的搭建,简单写写 Zookeeper 3.x 的安装配置、启动和测试。
一、所需环境
参考《大数据学习初级入门教程(一) —— Hadoop 2.x 完全分布式集群的安装、启动和测试》中准备的资源环境,这里将不再细述。
集群部署规划为:node19、node18 和 node11 为 leader(领导者节点)/follower(跟随者节点),node12 和 node13 为 observer(观察者节点)。
二、上传部署包
为了简单期间,包直接放在机器的 /home 目录下,上传后解压包即可,这里先直接操作 node19 机器。
三、解压部署包
# tar -zxvf zookeeper-3.4.6.tar.gz
四、创建配置文件
刚解压的部署包,可以看到路径 /home/zookeeper-3.4.6/conf 下没有 zoo.cfg 文件,但有一个 zoo_sample.cfg 文件,可以重命名该文件,直接修改配置。这里直接新建一个 zoo.cfg。
# vi zoo.cfg
内容详细如下:
tickTime=2000
dataDir=/opt/zookeeper/zookeeper-3.4.6
clientPort=2181
initLimit=5
syncLimit=2
server.19=node19:2888:3888
server.18=node18:2888:3888
server.11=node11:2888:3888
server.12=node12:2888:3888:observer
server.13=node13:2888:3888:observer备注:
tickTime(心跳周期毫秒数)、dataDir(数据目录)、clientPort(供客户端连接的端口号)、initLimit(集群中的 follower 与 leader 之间的初始连接)、syncLimit(集群中的 follower 与 leader 之间的通信连接)、server.n=host:port1:port2
server.n=host:port1:port2,数字 n 必须是 myid 中的值
port1 为 leader 端口,作为 leader 时,供 follower 连接的端口
port2 为 选举端口,选举 leader 时,供其它 follower 连接的端口
五、创建目录及文件
由于在上一步中,配置了 dataDir 的路径,所以需要提前在指定位置创建目录。
# cd /opt
# mkdir -p zookeeper/zookeeper-3.4.6
# cd zookeeper/zookeeper-3.4.6
# vi myid
分别写入19、18 、11、12 和 13。注意这几个值,和上一步中的 server.n 中的 n 值要保持一致。
六、部署其它机器节点
# scp -r zookeeper-3.4.6/ root@node18:/home/
# scp -r zookeeper-3.4.6/ root@node11:/home/
# scp -r zookeeper-3.4.6/ root@node12:/home/
# scp -r zookeeper-3.4.6/ root@node13:/home/
七、配置机器环境变量
# vi ~/.bash_profile
在原配置后面追加:
export ZK_HOME=/home/zookeeper-3.4.6
export PATH=$PATH:$ZK_HOME/bin
执行命令 source ~/.bash_profile 使得配置立刻生效。
八、启动集群
使用下面命令,启动每个 zk 节点:
# zkServer.sh start
如果看到下面的日志信息,说明节点启动成功:
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
使用下面命令,可以看看每个节点都是什么角色:
# zkServer.sh status
[root@node19 conf]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader[root@node18 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower[root@node11 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower[root@node12 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: observer[root@node13 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: observer
九、查看集群进程
输入 jps 可以查看 zk 的进程信息,输出如下:
1624 QuorumPeerMain
十、测试集群
访问其内存数据库,是一个内存文件系统,输入以下命令访问:
# zkCli.sh
可以看到如下输出:
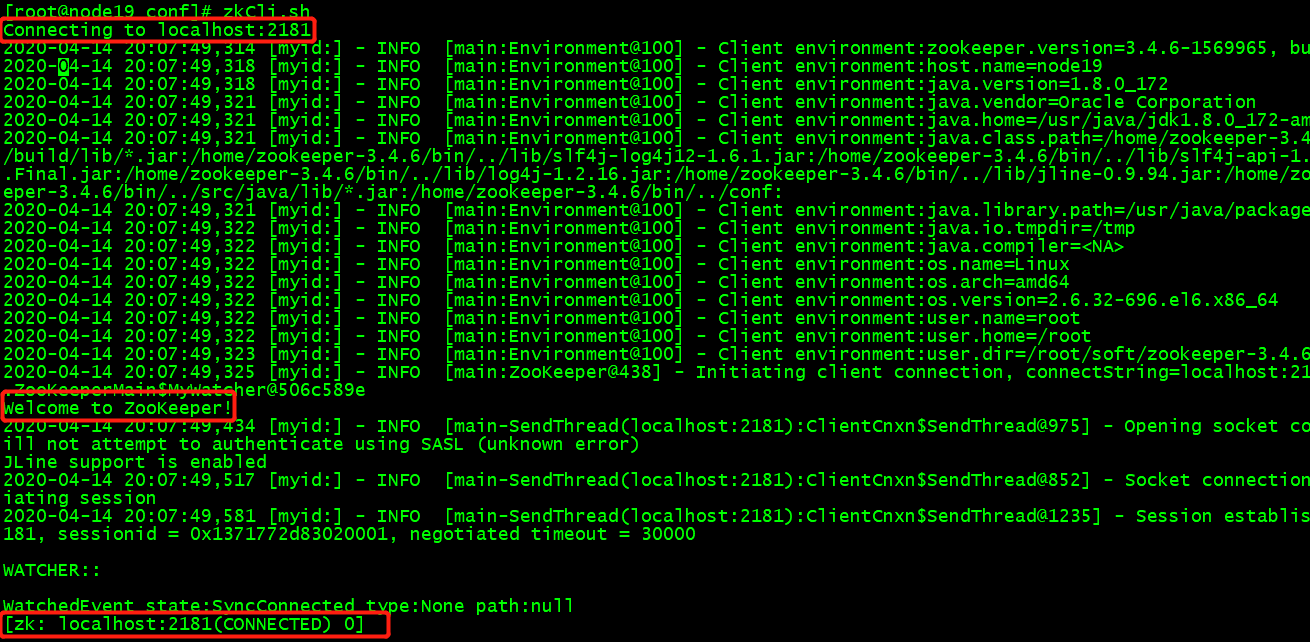
ls 命令可以查看根目录:

get 命令查看 zookeeper 目录:
-h 命令 查看帮助:
退出用 quit:

十一、测试高可用
如果 master 节点挂掉,则集群内部会通过选举,产生新的 master 节点,比如停掉 node19 的 zk 服务,在 node19 机器上执行停止服务命令:
# zkServer.sh stop
再次查看各个节点状态,信息如下:
[root@node19 conf]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.[root@node18 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader[root@node11 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower[root@node12 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: observer[root@node13 ~]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: observer
可以看到 node18 被选举为 leader 节点。
如果再次启动 node19 上的 zk 服务,可以看到 node19 上的状态为 follower:
Starting zookeeper ... STARTED
[root@node19 conf]# zkServer.sh status
JMX enabled by default
Using config: /home/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
十二、停止集群
依次停用各个机器上的 zk 服务即可,命令还是 zkServer.sh stop。
到此,Zookeeper 集群的安装、配置、启停,以及简单的内存库访问等基本搞定,后续可以在搭建其它集群时,配置 zk,让其保证其它集群的高可用性。
最后
以上就是外向老鼠最近收集整理的关于大数据学习初级入门教程(十一) —— Zookeeper 3.4.6 完全分布式集群的安装、配置、启动和测试的全部内容,更多相关大数据学习初级入门教程(十一)内容请搜索靠谱客的其他文章。








发表评论 取消回复