主要解决具有隐变量的混合模型的参数估计
在高斯模型中,每个聚类都服从某个概率分布,我们要做的就是利用EM算法确定这些分布的参数,对高斯模型来说就是计算均值和方差,对多项式模型那就是概率
个人的理解就是用含有隐变量的含参表达式不断拟合,最终能收敛并拟合出不含隐变量的含参表达式
假如有人告诉你,那一个点属于哪一个模型,你当然能够估计出这些分布的均值和方差。但实际上这些都是未知的,相反假如你已经知道均值和方差,那么你也能推断出哪一点属于哪一个模型,但是均值和方差同样也是未知的,所以你需要用均值和方差来判断从属关系或是用从属关系估计出均值和方差,这就是EM算法的基本原理。EM算法开始执行时,各个高斯模型会被随机分配到N维空间中,就像K-means算法,均值和方差都是随机的,然后根据当前的均值和方差,判断某点X有多大可能性来自蓝色或者黄色模型,然后将这个点分配到蓝色和黄色模型,但不同于K-means算法的是这个分配不是硬性的,K-means要么将这个点分给蓝色要么分给黄色。EM算法将这个点属于蓝色或黄色的概率计算出来,但它不会把概率置0或者1,这个概率属于(0,1),这就是叫它柔性聚类法的原因,它不会直接把某点分配给某个模型,而是告诉我们这个点属于某个模型的概率,然后利用概率来重新估计各个模型的均值和方差,进而改进之前的概率,这就是EM像K-means的原因,但概率又使它们区别开来,就像K-means算法那样,我们讲上面的过程迭代直至收敛。
模型的EM训练过程
直观的来讲是这样:我们通过观察采样的概率值和模型概率值的接近程度,来判断一个模型是否拟合良好。然后我们通过调整模型以让新模型更适配采样的概率值。反复迭代这个过程很多次,直到两个概率值非常接近时,我们停止更新并完成模型训练。现在我们要将这个过程用算法来实现,所使用的方法是模型生成的数据来决定似然值,即通过模型来计算数据的期望值。通过更新参数μ和σ来让期望值最大化。这个过程可以不断迭代直到两次迭代中生成的参数变化非常小为止。该过程和k-means的算法训练过程很相似(k-means不断更新类中心来让结果最大化),只不过在这里的高斯模型中,我们需要同时更新两个参数:分布的均值和标准差.
极大似然估计(MLE)
事情已经发生了,当未知参数等于多少时,能让这个事情发生的概率最大,“模型已定,参数未知”
1.当出现多余参数,数据截尾或缺失时,MLE不适合 —EM
2.概率模型有时即含有观测变量,又含有隐变量或潜在变量,如果概率模型的变量都是观测变量,那么给定的数据,可以直接用极大似然估计法估计模型参数。但是当模型含有隐变量时,就不能简单的使用这些估计方法。
EM两步:
1.E: 求期望
2.M: 求最大值
EM算法就是含有隐变量的概率模型参数的极大似然估计法
看一个极大似然估计的例题
- 一个暗箱里有(1,2,3)3种球,其概率分布如表所示,进行有放回的抽样,得到了 1 2 2 2 1 2 2 3 1 3 ,记为x1,x2…,现在通过极大似然估计的方法求θ

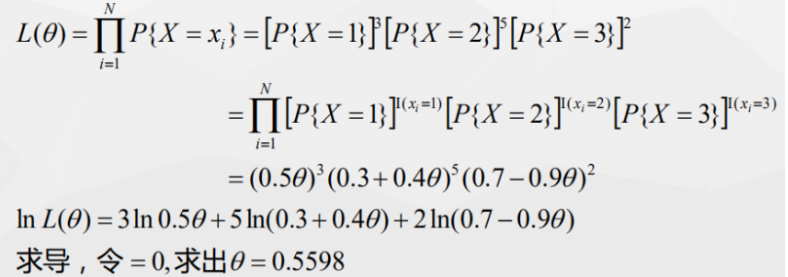
EM算法需要处理样本中含有隐变量的情况,什么意思?
一般我们面临的问题是:对于一个函数f(x; θ),里面x是已知的,但 θ未知,于是使用极大似然估计求 θ,但如果x是由(x, z)两部分组成,其中x已知z未知,也就是说样本中含有隐变量z,对于这种情况极大似然估计就没辙了,而为了解决这样的情况而发明的算法之一就是EM算法。
EM缺点
只能得到局部极值点,不能得到全局极值点。
比如:给出男女身高样本,求男女身高分布。如果男性身高均值是1.80,女性1.65,那用EM算法求得的结果还是很不错的,但如果男性1cm,女性10m,那结果一定会和实际差太远。
K-means与EM
这两个都是能处理含有隐变量情况的样本,因为在给定样本的情况下K-means是可以将未标记的样本分成若干个簇的,但K-means无法给出某个样本属于该簇的后验概率,而EM算法可以给出后验概率。
最后
以上就是碧蓝店员最近收集整理的关于EM算法理论总结的全部内容,更多相关EM算法理论总结内容请搜索靠谱客的其他文章。








发表评论 取消回复