Interview之DS:人工智能领域求职岗位—数据科学家/数据科学工程师的职位简介、薪资介绍、知识结构之详细攻略
目录
数据科学家/数据科学工程师的职位简介
资讯指数
1、各大互联网巨头的薪资介绍
2、各大公司的具体职位简介
腾讯—数据科学工程师
字节跳动—数据科学家
阿里巴巴—数据科学家
拼多多—数据科学家
百度—数据科学家
数据科学工程师的知识结构
1、统计学基础
2、数据处理与分析—python编程能力
Python:Python语言的简介(语言特点/pyc介绍/Python版本语言兼容问题(python2 VS Python3))、安装、学习路线(数据分析/机器学习/网页爬等编程案例分析)之详细攻略
Computer:C语言/C++语言的简介、发展历史、应用领域、编程语言环境IDE安装、学习路线之详细攻略
3、机器学习与深度学习—python编程能力
4、数据可视化与报告
5、数据工程
6、业务理解与沟通
数据科学家/数据科学工程师的职位简介
资讯指数
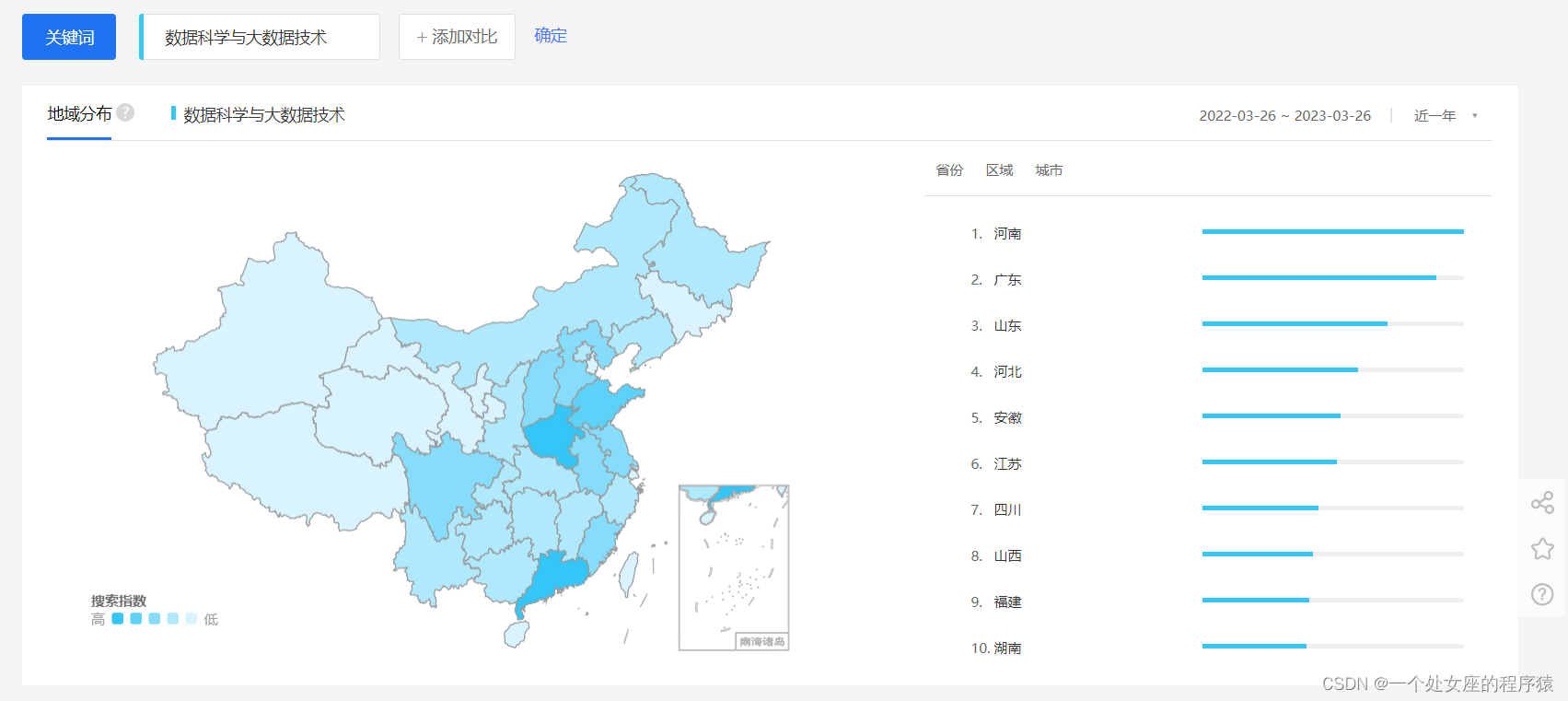
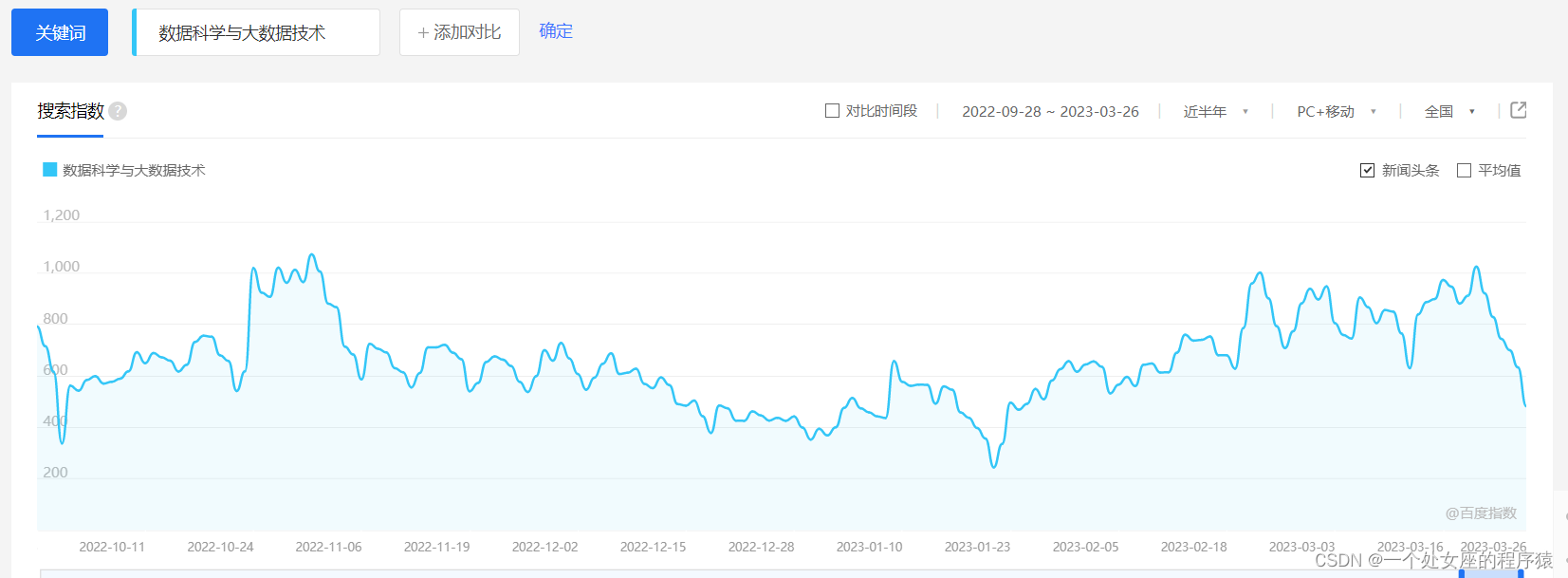
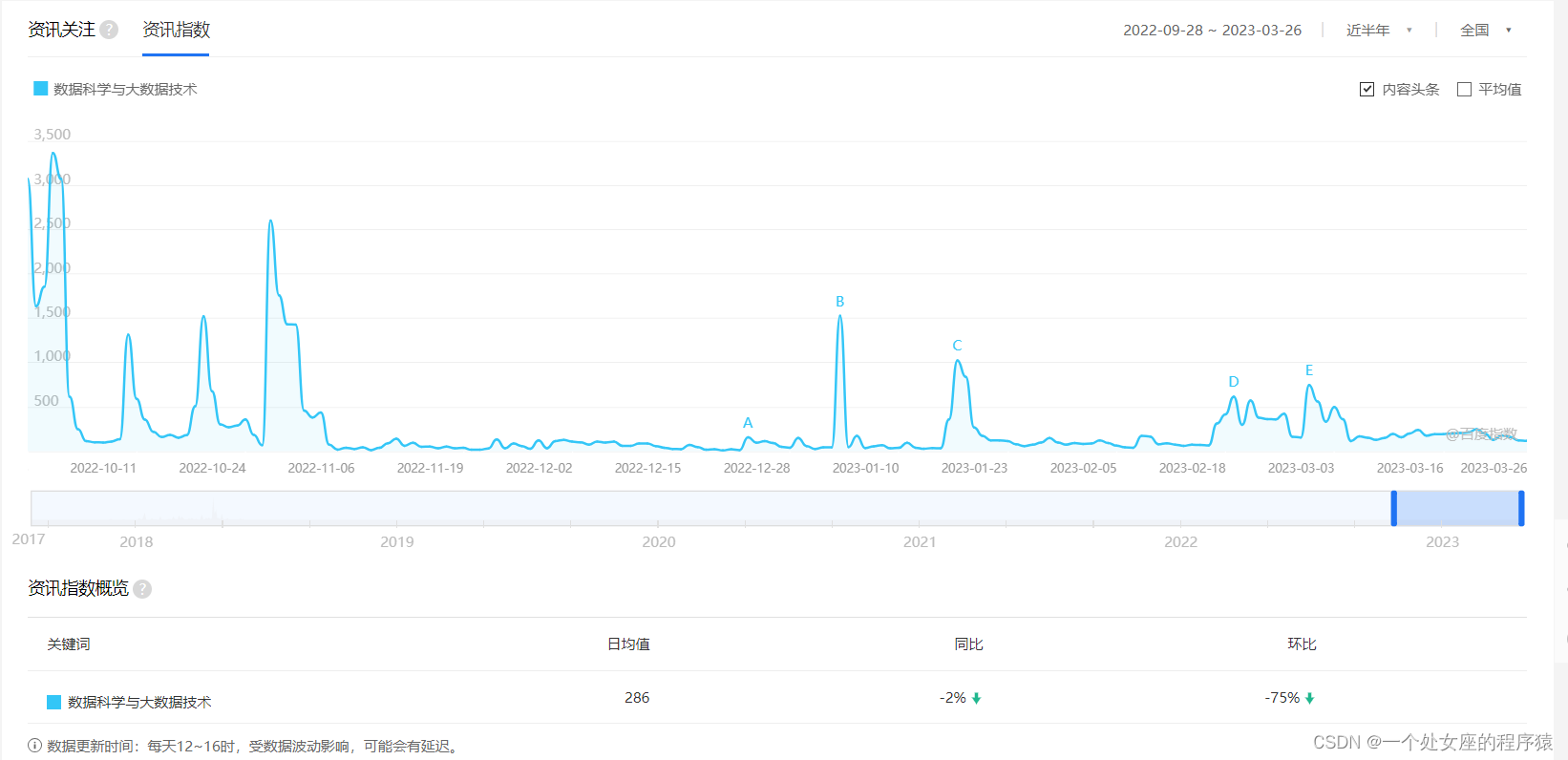
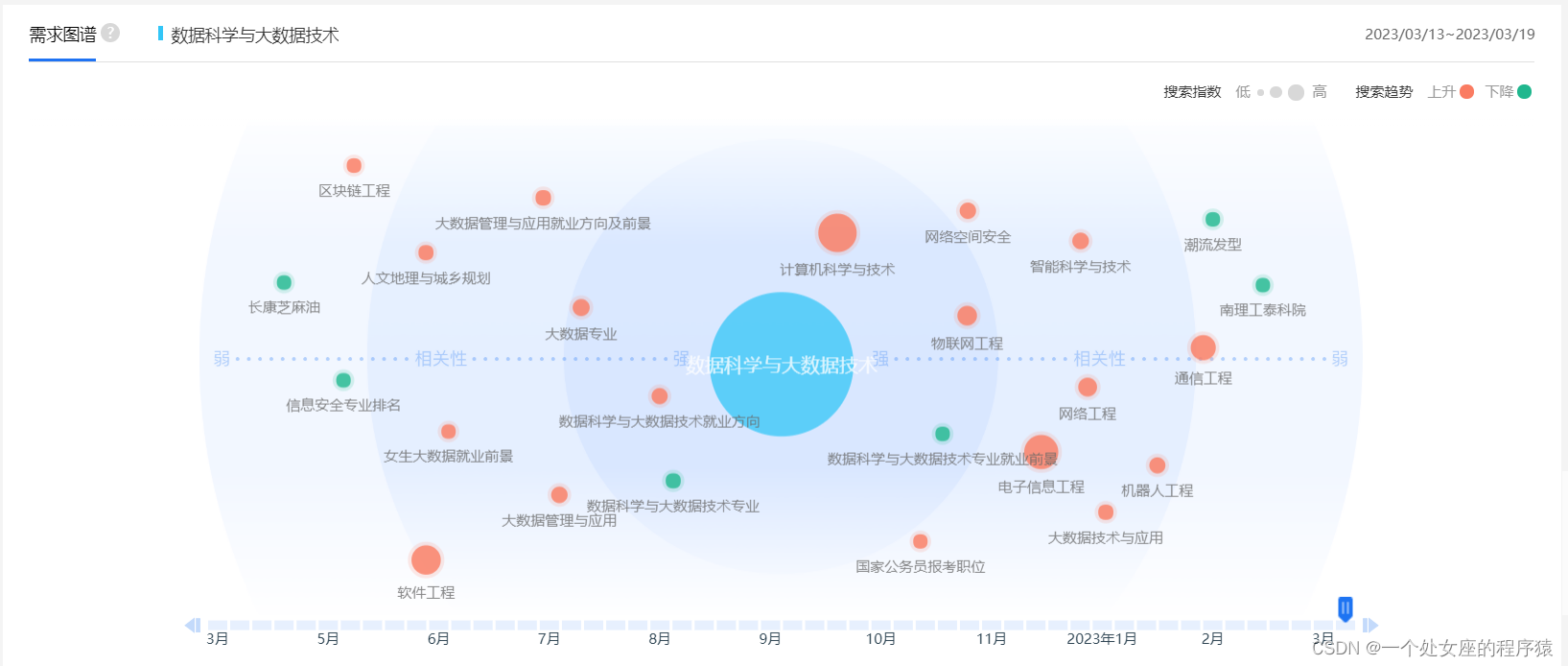
1、各大互联网巨头的薪资介绍
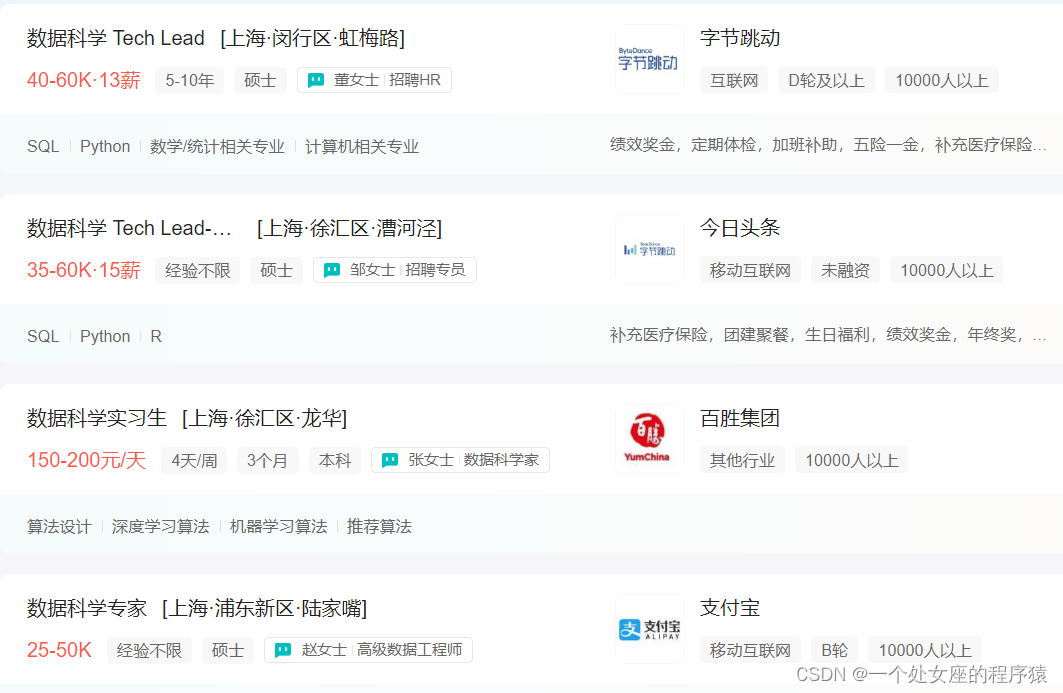
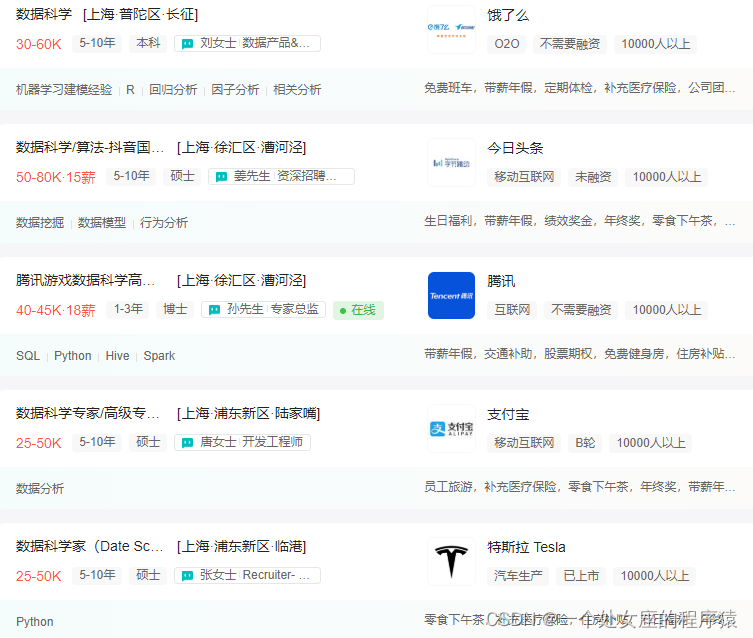
2、各大公司的具体职位简介
腾讯—数据科学工程师
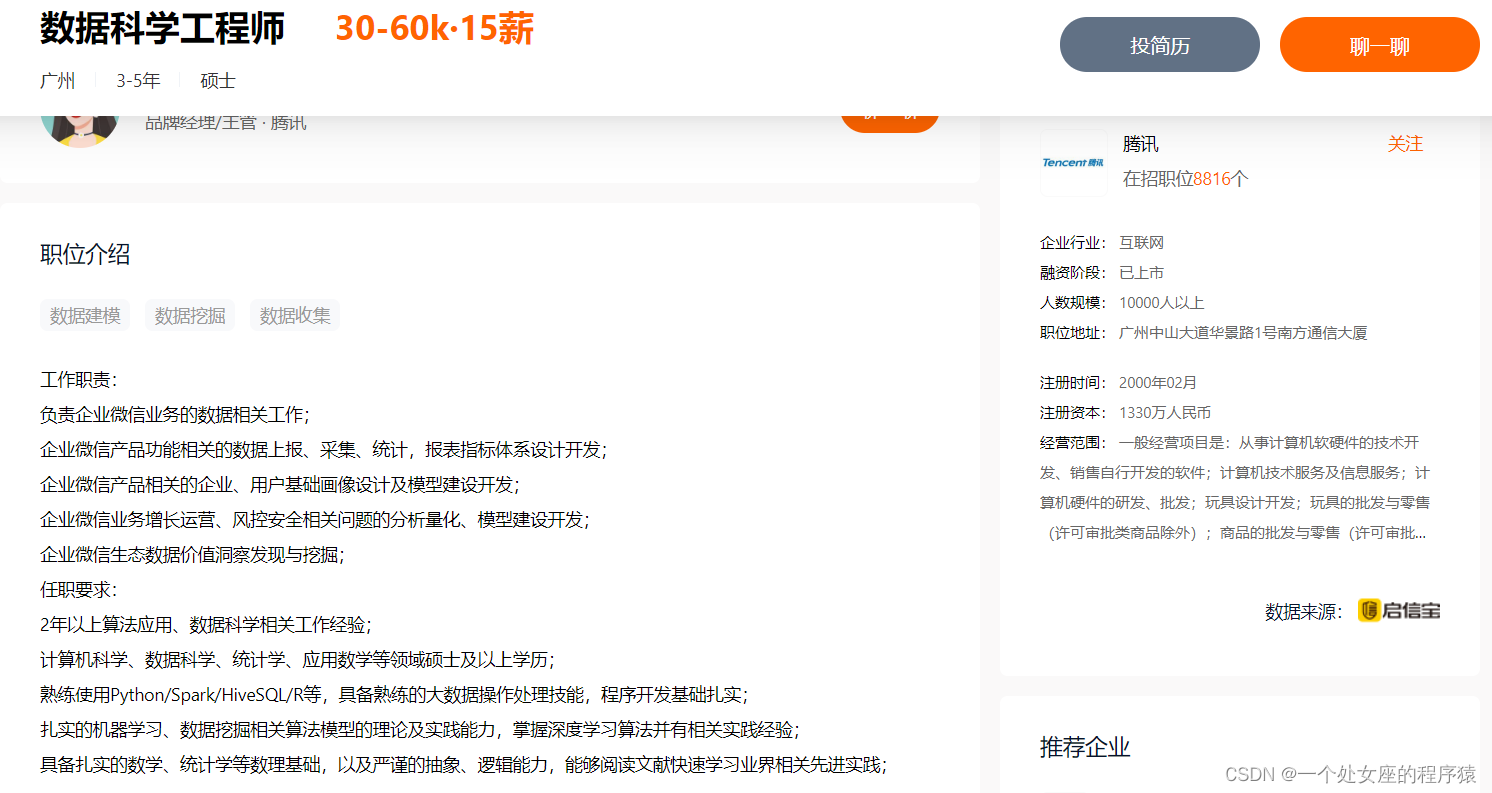
职位介绍:数据建模、数据挖掘、数据收集
工作职责:
负责企业微信业务的数据相关工作;
企业微信产品功能相关的数据上报、采集、统计,报表指标体系设计开发;
企业微信产品相关的企业、用户基础画像设计及模型建设开发;
企业微信业务增长运营、风控安全相关问题的分析量化、模型建设开发;
企业微信生态数据价值洞察发现与挖掘;
任职要求:
2年以上算法应用、数据科学相关工作经验;
计算机科学、数据科学、统计学、应用数学等领域硕士及以上学历;
熟练使用Python/Spark/HiveSQL/R等,具备熟练的大数据操作处理技能,程序开发基础扎实;
扎实的机器学习、数据挖掘相关算法模型的理论及实践能力,掌握深度学习算法并有相关实践经验;
具备扎实的数学、统计学等数理基础,以及严谨的抽象、逻辑能力,能够阅读文献快速学习业界相关先进实践;
字节跳动—数据科学家
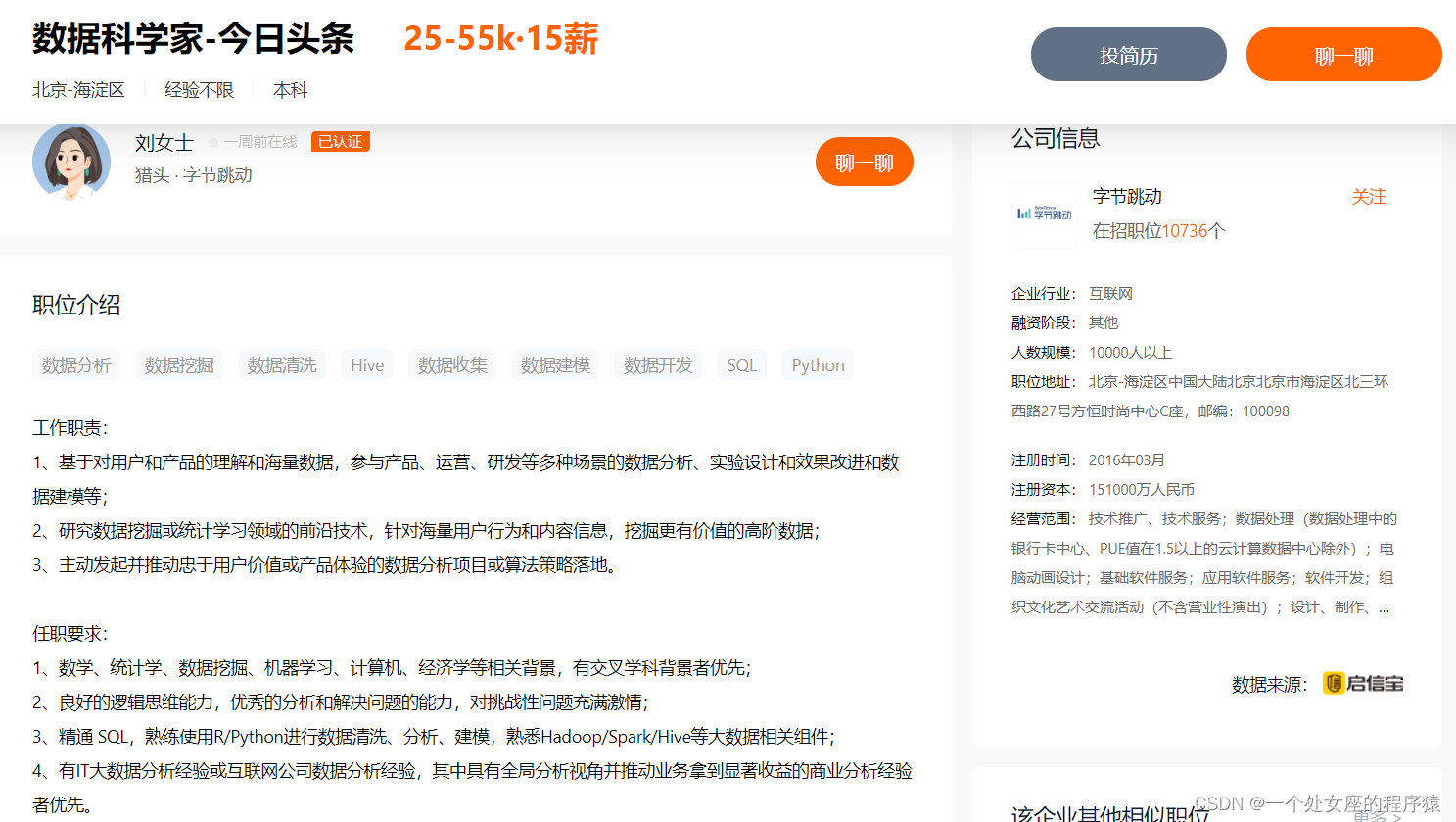
职位介绍:数据分析、数据挖掘、数据清洗、Hive、数据收集、数据建模、数据开发、SQL
Python
工作职责:
1、基于对用户和产品的理解和海量数据,参与产品、运营、研发等多种场景的数据分析、实验设计和效果改进和数据建模等;
2、研究数据挖掘或统计学习领域的前沿技术,针对海量用户行为和内容信息,挖掘更有价值的高阶数据;
3、主动发起并推动忠于用户价值或产品体验的数据分析项目或算法策略落地。
任职要求:
1、数学、统计学、数据挖掘、机器学习、计算机、经济学等相关背景,有交叉学科背景者优先;
2、良好的逻辑思维能力,优秀的分析和解决问题的能力,对挑战性问题充满激情 ;
3、精通 SQL,熟练使用R/Python进行数据清洗、分析、建模,熟悉Hadoop/Spark/Hive等大数据相关组件;
4、有IT大数据分析经验或互联网公司数据分析经验,其中具有全局分析视角并推动业务拿到显著收益的商业分析经验者优先。
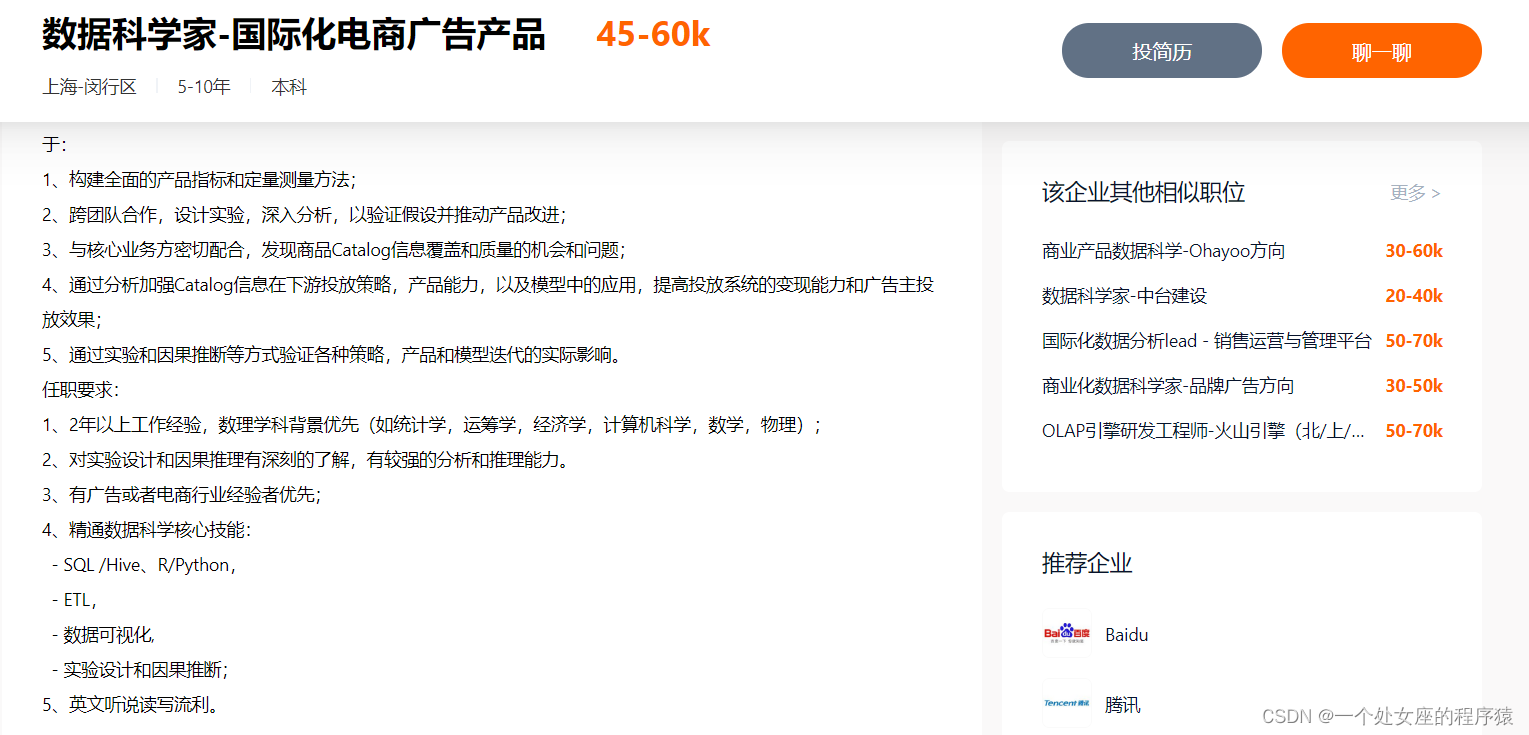
阿里巴巴—数据科学家
• 职位描述:我们将致力于通过数据科学(数据+算法+产品)的手段,帮助业务识别的核心痛点和机会点,设计数据+算法+产品的系统化解决方案,最终帮助业务实现快速增长,给数以亿计的阿里用户带来更好的用户体验,创造更多的用户价值。我们正竭力寻找增长黑客、销售提效、供应链等相关领域有较深沉淀的专家。如果您具备较好的业务理解能力和深厚的算法基础,善于沟通与团队协作,勇于挑战新的问题,请加入我们,并和我们一起通过数据、分析和算法的手段帮助业务实现更好的目标和快速增长。
• 1.与零售通的各大业务方合作, 通过实验的方式或者分析观测数据的方式来支撑业务决策;
• 2.深入理解业务需求和痛点,通过专题分析帮助业务找到产品和业务运营发力的机会点;
• 3.针对实际的业务问题,设计合适的分析和算法解决方案(包括专题分析、统计建模、机器学习和深度学习);
• 4.通过数据+算法+产品的方式赋能业务,从而帮助实现业务目标和业务增长;
• 5.与公司各个角色协同,包括运营、产品、UED、技术、用研等,推动数据科学项目的快速落地和迭代,帮助业务拿到更好的结果;
• 职位要求:
• 1.计算机或数学或统计相关专业本科及以上学历,具有3年以上的工作经验;
• 2.具备机器学习或者数据挖掘的研究背景和项目背景;熟练掌握分类、回归、聚类等机器学习模型;了解算法基本原理,具有数据挖掘和算法应用能力;
• 3.熟练掌握SQL、R、Python以及相关进行分析的工具或Hadoop/Spark/ODPS等大数据分布式平台,熟悉分布式机器学习框架比如Spark MLLib等;
• 4.对数据敏感,具有优秀的分析和解决问题能力,对于把大数据和分析算法的结果能够应用到实际业务场景产生商业价值具有强烈的热情;
• 5.具备较好的自我驱动和抗压能力,良好的沟通能力和团队合作精神,有一定的组织协调能力;
具备以下条件者优先:
在以下一个或多个领域中有丰富的业务和数据技术背景:增长黑客、销售提效、供应链降本提效等。
拼多多—数据科学家
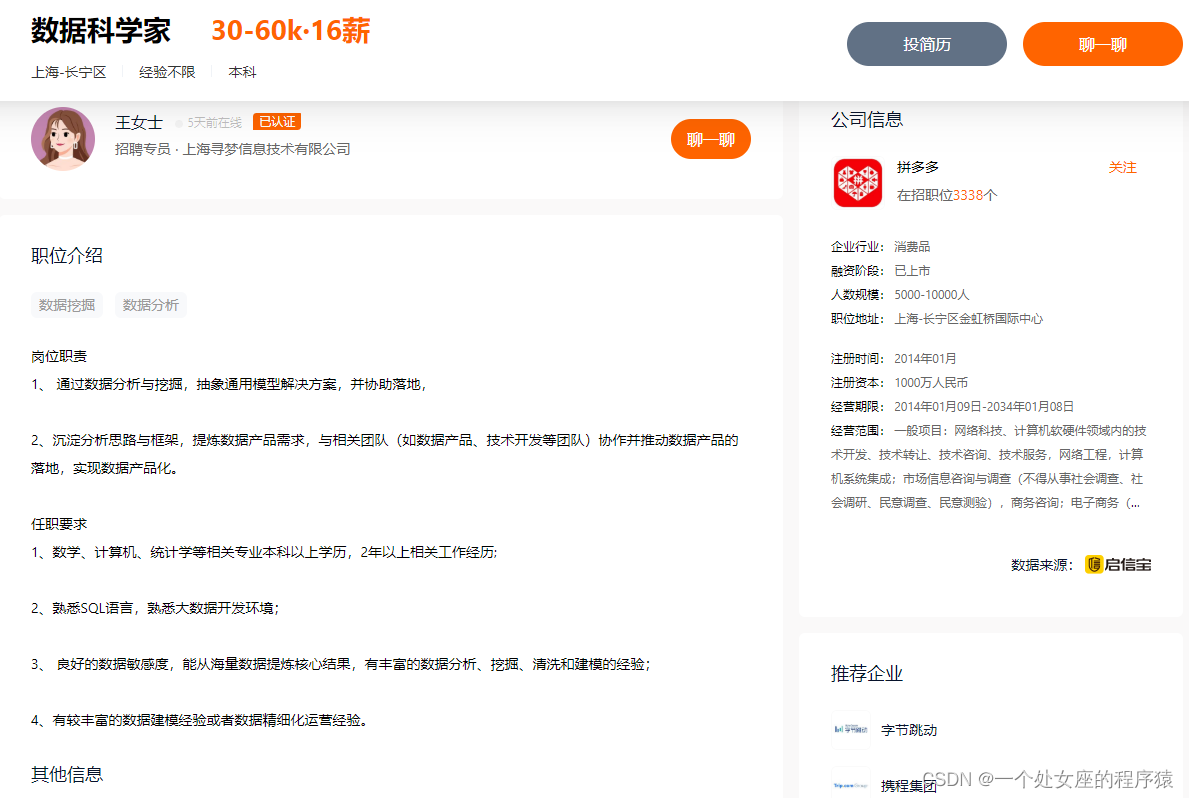
岗位职责
1、 通过数据分析与挖掘,抽象通用模型解决方案,并协助落地,
2、沉淀分析思路与框架,提炼数据产品需求,与相关团队(如数据产品、技术开发等团队)协作并推动数据产品的落地,实现数据产品化。
任职要求
1、数学、计算机、统计学等相关专业本科以上学历,2年以上相关工作经历;
2、熟悉SQL语言,熟悉大数据开发环境;
3、 良好的数据敏感度,能从海量数据提炼核心结果,有丰富的数据分析、挖掘、清洗和建模的经验;
4、有较丰富的数据建模经验或者数据精细化运营经验。
百度—数据科学家
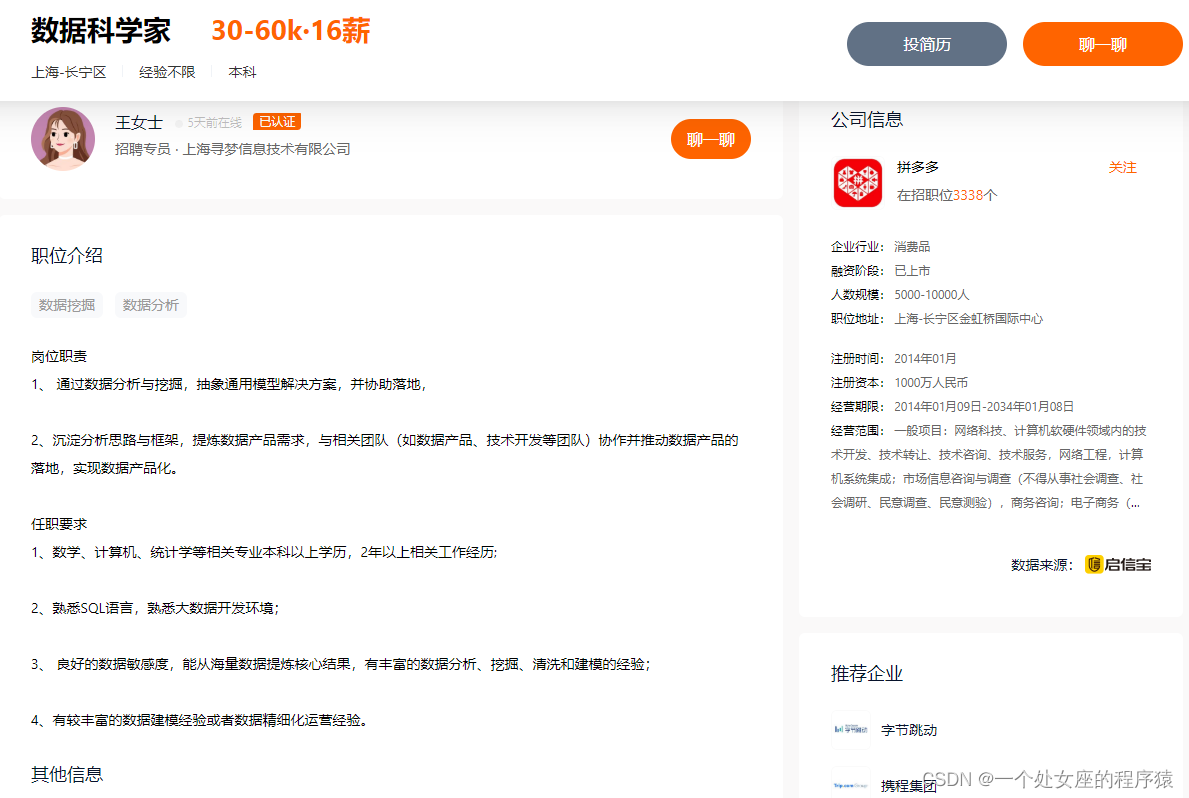
职位介绍:数据挖掘、数据分析、Python
岗位职责
- 负责百度搜索业务的宏微观数据分析,以便在其中发现趋势、提供洞察、支撑决策
- 设计和实现数据挖掘算法和模型,以便从数据中提取有价值的信息
- 利用因果推断技术,进行归因拆解,找到业务增长点,并进行落地
岗位要求
- 计算机、统计、数据科学或者相关专业本科以上学历, 硕士、博士优先
- 至少3年数据挖掘或数据科学方面的工作经验,具有优秀的数学、统计学和逻辑思维能力
- 掌握扎实的机器学习和统计学模型,熟练使用数据分析/建模语言(Python/R等),有T/P级别数据处理经验及Top互联网公司经验者优先
- 善于沟通,工作积极主动,有主人翁意识,责任心强,具备良好的团队协作能力与承压能力
数据科学工程师的知识结构
1、统计学基础
掌握基本的概率论和统计学知识,包括随机变量、概率分布、假设检验、方差分析等,能够应用统计学方法进行数据分析和解释结果。
2、数据处理与分析—python编程能力
掌握数据采集、清洗、转换、整合、存储等技能,能够使用Python、R、SQL等工具进行数据分析,以及常见的数据分析算法和模型,如回归、分类、聚类、关联规则挖掘等。
Python:Python语言的简介(语言特点/pyc介绍/Python版本语言兼容问题(python2 VS Python3))、安装、学习路线(数据分析/机器学习/网页爬等编程案例分析)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/126844360
Computer:C语言/C++语言的简介、发展历史、应用领域、编程语言环境IDE安装、学习路线之详细攻略
https://yunyaniu.blog.csdn.net/article/details/126694327
3、机器学习与深度学习—python编程能力
熟悉各种机器学习算法和技术,如决策树、支持向量机、朴素贝叶斯、神经网络等,掌握深度学习框架,如TensorFlow、Keras等,了解计算机视觉、自然语言处理等领域的深度学习应用。
4、数据可视化与报告
具备数据可视化的能力,能够使用Tableau、matplotlib等工具将分析结果可视化呈现,能够编写清晰、简洁、易懂的分析报告,以及通过数据故事让数据更具说服力。
5、数据工程
掌握数据工程领域的基础知识,如数据仓库、ETL、数据流、数据管道等,熟悉云计算、大数据技术,如Hadoop、Spark等,能够设计和构建可扩展、高可靠的数据处理系统。
6、业务理解与沟通
能够理解业务需求,对数据分析结果进行解释,为业务决策提供支持,并具备良好的沟通能力,能够与业务人员、数据科学家、数据工程师等进行有效的沟通和协作。
综上所述,数据科学家或数据科学工程师需要具备的知识结构十分广泛,需要具备一定的数学基础、编程能力、统计学知识以及业务理解能力。
最后
以上就是鳗鱼八宝粥最近收集整理的关于DataScience:数据生成之在原始数据上添加小量噪声(可自定义噪声)进而实现构造新数据(dataframe格式数据存储案例)daiding的全部内容,更多相关DataScience内容请搜索靠谱客的其他文章。








发表评论 取消回复