在我的博客上,以前我经常谈到SQL Serverl里的书签查找,还有它们带来的很多问题。在今天的文章里,我想从性能角度进一步谈下书签查找,还有它们如何拉低你整个SQL Server性能。
书签查找——反复循环
如果你的非聚集索引不是个覆盖非聚集索引,SQL Server的查询优化器会引入书签查找。对于从非聚集索引你返回的每一行,SQL Server需要在聚集索引里或堆表里进行额外的查找操作。
例如当你的的聚集索引包含3层,为了返回必要的信息,对于每一行,你需要3页额外的读取。因此,查询优化器再执行计划里选择书签查找操作,仅在有意义的时候发生——基于你查询的选择度。下图展示了有书签查找操作的执行计划。

通常人们不会太关注书签查找,因为它们只执行几次。如果你的查询选择度太低,查询优化器会用聚集索引扫描或表扫描运算符直接扫描整个表。但只在SQL Server重用缓存的执行计划,这个计划是有多次不同运行值,包含书签查找的(基于最初提供的输入值),因此这个情况很容易发生,书签查找反复执行。
为了演示这个性能问题,接下来的查询我指定查询优化器使用特定的非聚集索引。查询本身返回80000行,因为对于每个查询执行,SQL Server需要进行书签查找80000次——反复执行。
CREATE PROCEDURE RetrieveData AS SELECT * FROM Table1 WITH (INDEX(idxTable1_Column2)) WHERE Column3 = 2 GO
下图展示了查询执行后的实际执行计划。
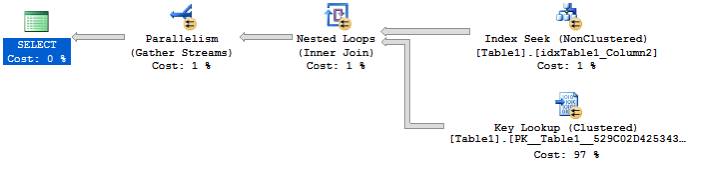
执行计划看起来非常恐怖(查询优化器甚至启用了并行计划!),因为书签查找运算符这里执行了80000次,查询本身产生了超过165000个逻辑读!(逻辑读个数可以从STATISTIC IO里获取)。

接下来向你展示下,当你有很多并行用户执行这个糟糕查询时,SQL Server会发生什么。我会使用ostress.exe(RML工具的一部分)来模拟100个并行用户的查询。
ostress.exe -Q”EXEC BookmarkLookupsPerformance.dbo.RetrieveData” -n100 -q
在我的测试系统上花费了近15秒来完成100个并行查询。在此期间,CPU占用很高,因为SQL Server需要嵌套循环运算符来进行书签查找操作。嵌套循环操作当然很占CPU资源。
现在让我们修改索引设计,为这个查询创建覆盖非聚集索引。有了非聚集索引,查询优化器不需要再执行计划里进行书签查找。一个非聚集索引查找就可以返回同样的结果:
CREATE NONCLUSTERED INDEX idxTable1_Column2 ON Table1(Column3) INCLUDE (Column2) WITH (DROP_EXISTING = ON) GO
这次当我们再次用ostress.exe执行同个查询,我们看到每个查询在5秒内完成。和我们刚才看到的15秒有很大的区别。这就是覆盖非聚集索引的威力:在我们查询里气门请求的数据都可以在非聚集索引里直接找到,因此书签查找就可以避免。
小结
在这个文章里我向你展示了不好的书签查找会伤及性能。因此,对于重要的查询快速完成查询非常重要——而使用并行的书签查找的执行计划并不是好的选择。这里覆盖非聚集索引可以帮到你。下次设计索引时可以考虑下这个方法。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持脚本之家!
最后
以上就是繁荣故事最近收集整理的关于SQL Server里书签查找的性能伤害的全部内容,更多相关SQL内容请搜索靠谱客的其他文章。








发表评论 取消回复