Attention机制在NLP上最早是被用于seq2seq的翻译类任务中,如Neural Machine Translation by Jointly Learning to Align and Translate这篇文章所说。
之后在文本分类的任务中也用上Attention机制,这篇博客主要介绍Attention机制在文本分类任务上的作用,与seq2seq中使用的可能会略有不同, 主要参考的论文是Hierarchical Attention Networks for Document Classification。这里的层次Attention网络并不是只含有Attention机制的网络,而是在双向RNN的输出后加了Attention机制,层次表现在对于较长文本的分类,先将词向量通过RNN+Attention表示为句子向量,再将句子向量通过RNN+Attention表示为文档向量。两部分的Attention机制是一样的,这篇博客就不重复说明了。
一、Attention 的作用
在RNN的文本分类模型中,可以把RNN看成一个encoder,将需要被分类的文本表示为一个dense vector,再使用全连接层与softmax输出各类别的概率。
在具体的文本的表示上,可以将RNN最后一个时刻的输出作为文本的表示,也可以综合考虑每个时刻的的输出,将它们合并为一个向量。在tagging与classication的任务中常用双向RNN(下文写作BIRNN),每个时刻的输出向量可以理解为这个时刻的输入词在上下文的语境中对当前任务的一个贡献。BIRNN如下图所示
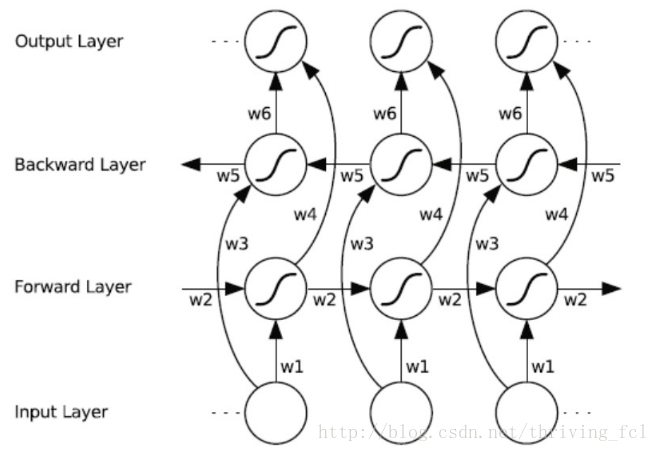
根据人类的阅读习惯进行思考,我们在阅读的时候,注意力通常不会平均分配在文本中的每个词。再回到上面的文本表示,如果直接将每个时刻的输出向量相加再平均,就等于认为每个输入词对于文本表示的贡献是相等的,但实际情况往往不是这样,比如在情感分析中,文本中地名、人名这些词应该占有更小的权重,而情感类词汇应该享有更大的权重。
所以在合并这些输出向量时,希望可以将注意力集中在那些对当前任务更重要的向量上。也就是给他们都分配一个权值,将所有的输出向量加权平均。假设输出向量为 ht ,权值为 αt ,则合并后的表示为
上文所说的为BIRNN的每个输出向量分配不同权值,使得模型可以将注意力集中在重点几个词,降低其他无关词的作用的机制就是Attention机制。使用了Attention机制可以使得文本表示的结果在当前的任务中更合理。
使用Attention的两个好处:
- 可以更好的表征文本,使训练出的模型具有更好的表现(更高的精度)。
- 为模型提供了更好的解释性,如直观的看出在文本分类中哪些词或句子更重要, 如果训练出的模型不理想,根据这些权值分析badcase也非常方便。

Hierarchical Attention Networks for Document Classification 这篇论文中提到他们的模型可以学习到词的上下文信息,并且分配与上下文相关的词的权重。我觉得这并不是由于Attention这个机制的作用,而是RNN本身就具有这个能力。
二、Attention 原理
上文说到需要给BIRNN的每个输出分配权重,如何分配就是Attention的原理,用一张结构图加三个公式应该就可以解释清楚了。
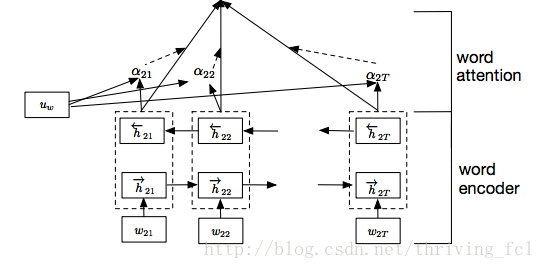
公式(1)中的 Ww 与 bw 为Attention的权重与bias,在实现的时候也要设置attention的size,不过也可以简单的令它们等于BIRNN的输出向量的size。
公式(2)中的 uw 也是需要设置的权重,公式(2)其实也就是对所有 uTtuw 结果的softmax。
公式(3)即是将计算出的 αt 作为各时刻输出的权值,对它们加权求和表示为一个向量。
三、代码实现
代码中的BIRNN使用的是LSTM(层次Attention网络那篇论文使用的是GRU)
代码放在github了,里面注释写了很多,这里就不重复了。代码是使用tensorflow 1.0.0实现的。
model.py
最后
以上就是娇气红酒最近收集整理的关于用于文本分类的RNN-Attention网络的全部内容,更多相关用于文本分类内容请搜索靠谱客的其他文章。








发表评论 取消回复