1. Recurrent neural network
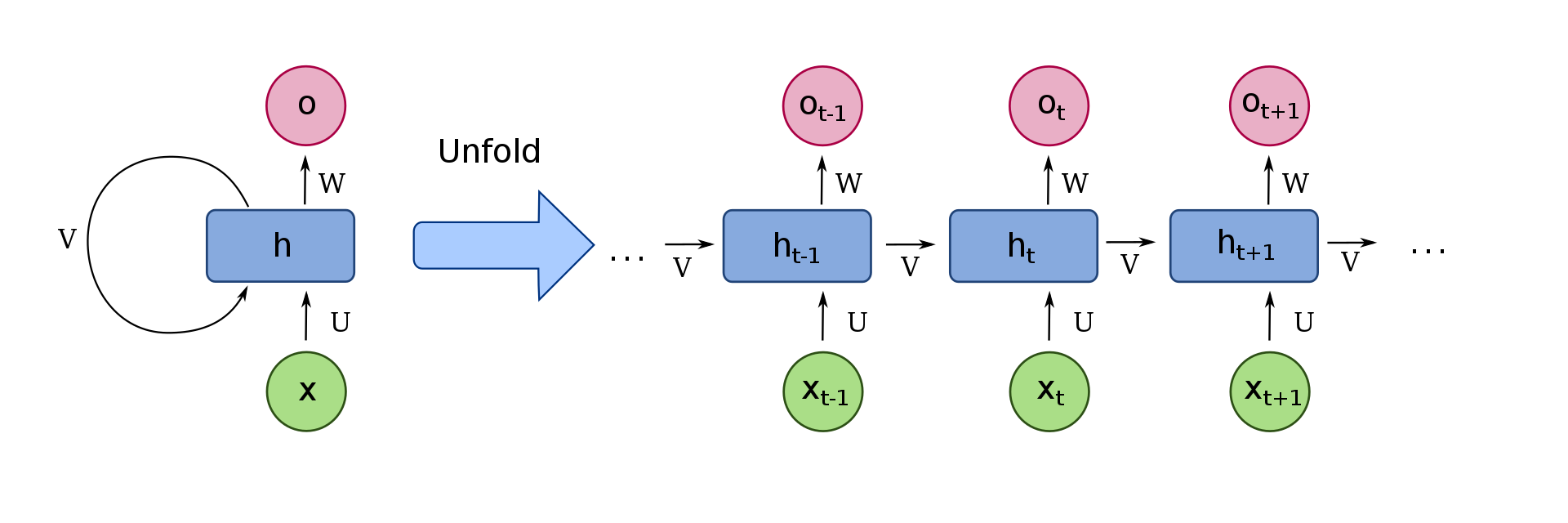
1.1 Elman network
h t = σ h ( W h x t + U h h t − 1 + b h ) h_{t}=sigma_{h}left(W_{h} x_{t}+U_{h} h_{t-1}+b_{h}right) ht=σh(Whxt+Uhht−1+bh)
y t = σ y ( W y h t + b y ) y_{t}=sigma_{y}left(W_{y} h_{t}+b_{y}right) yt=σy(Wyht+by)
1.2 Jordan network
h t = σ h ( W h x t + U h y t − 1 + b h ) h_{t}=sigma_{h}left(W_{h} x_{t}+U_{h} y_{t-1}+b_{h}right) ht=σh(Whxt+Uhyt−1+bh)
y t = σ y ( W y h t + b y ) y_{t}=sigma_{y}left(W_{y} h_{t}+b_{y}right) yt=σy(Wyht+by)
Variables and functions
- x t x_{t} xt : input vector
- h t h_{t} ht : hidden layer vector
- y t y_{t} yt : output vector
- W , U W, U W,U and b b b : parameter matrices and vector
- σ h sigma_{h} σh and σ y sigma_{y} σy : Activation functions
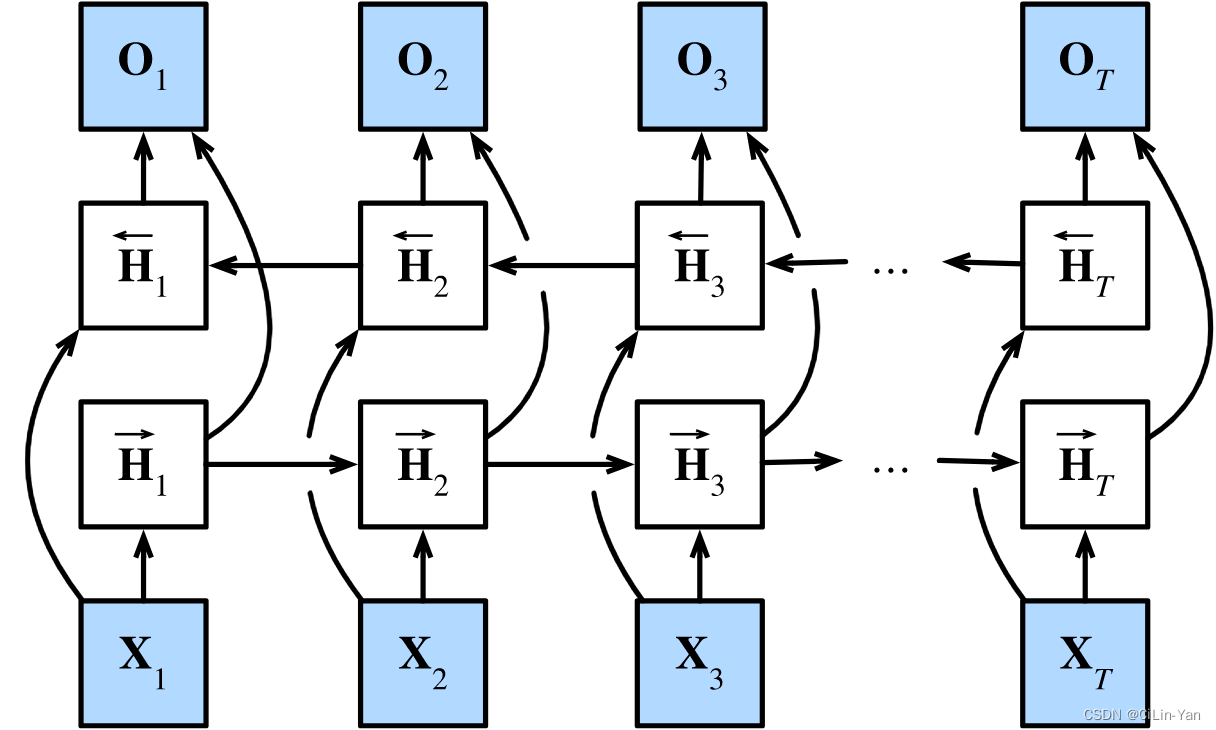
1.3 Bidirectional RNN
2. Long short-term memory
2.1 LSTM with a forget gate
The compact forms of the equations for the forward pass of an LSTM cell with a forget gate are:
f
t
=
σ
g
(
W
f
x
t
+
U
f
h
t
−
1
+
b
f
)
i
t
=
σ
g
(
W
i
x
t
+
U
i
h
t
−
1
+
b
i
)
o
t
=
σ
g
(
W
o
x
t
+
U
o
h
t
−
1
+
b
o
)
c
~
t
=
σ
c
(
W
c
x
t
+
U
c
h
t
−
1
+
b
c
)
c
t
=
f
t
∘
c
t
−
1
+
i
t
∘
c
~
t
h
t
=
o
t
∘
σ
h
(
c
t
)
begin{aligned} f_{t} &=sigma_{g}left(W_{f} x_{t}+U_{f} h_{t-1}+b_{f}right) \ i_{t} &=sigma_{g}left(W_{i} x_{t}+U_{i} h_{t-1}+b_{i}right) \ o_{t} &=sigma_{g}left(W_{o} x_{t}+U_{o} h_{t-1}+b_{o}right) \ tilde{c}_{t} &=sigma_{c}left(W_{c} x_{t}+U_{c} h_{t-1}+b_{c}right) \ c_{t} &=f_{t} circ c_{t-1}+i_{t} circ tilde{c}_{t} \ h_{t} &=o_{t} circ sigma_{h}left(c_{t}right) end{aligned}
ftitotc~tctht=σg(Wfxt+Ufht−1+bf)=σg(Wixt+Uiht−1+bi)=σg(Woxt+Uoht−1+bo)=σc(Wcxt+Ucht−1+bc)=ft∘ct−1+it∘c~t=ot∘σh(ct)
where the initial values are
c
0
=
0
c_{0}=0
c0=0 and
h
0
=
0
h_{0}=0
h0=0 and the operator o denotes the Hadamard product (element-wise product). The subscript
t
t
t indexes the time step.
Variables
- x t ∈ R d x_{t} in mathbb{R}^{d} xt∈Rd : input vector to the LSTM unit
- f t ∈ ( 0 , 1 ) h f_{t} in(0,1)^{h} ft∈(0,1)h : forget gate’s activation vector
- i t ∈ ( 0 , 1 ) h : i_{t} in(0,1)^{h}: it∈(0,1)h: input/update gate’s activation vector
- o t ∈ ( 0 , 1 ) h o_{t} in(0,1)^{h} ot∈(0,1)h : output gate’s activation vector
- h t ∈ ( − 1 , 1 ) h h_{t} in(-1,1)^{h} ht∈(−1,1)h : hidden state vector also known as output vector of the LSTM unit
- c ~ t ∈ ( − 1 , 1 ) h : tilde{c}_{t} in(-1,1)^{h}: c~t∈(−1,1)h: cell input activation vector
- c t ∈ R h c_{t} in mathbb{R}^{h} ct∈Rh : cell state vector
- W ∈ R h × d , U ∈ R h × h W in mathbb{R}^{h times d}, U in mathbb{R}^{h times h} W∈Rh×d,U∈Rh×h and b ∈ R h b in mathbb{R}^{h} b∈Rh : weight matrices and bias vector parameters which need to be learned during training where the superscripts d d d and h h h refer to the number of input features and number of hidden units, respectively.
2.2 Peephole LSTM
f t = σ g ( W f x t + U f c t − 1 + b f ) i t = σ g ( W i x t + U i c t − 1 + b i ) o t = σ g ( W o x t + U o c t − 1 + b o ) c t = f t ∘ c t − 1 + i t ∘ σ c ( W c x t + b c ) h t = o t ∘ σ h ( c t ) begin{aligned} f_{t} &=sigma_{g}left(W_{f} x_{t}+U_{f} c_{t-1}+b_{f}right) \ i_{t} &=sigma_{g}left(W_{i} x_{t}+U_{i} c_{t-1}+b_{i}right) \ o_{t} &=sigma_{g}left(W_{o} x_{t}+U_{o} c_{t-1}+b_{o}right) \ c_{t} &=f_{t} circ c_{t-1}+i_{t} circ sigma_{c}left(W_{c} x_{t}+b_{c}right) \ h_{t} &=o_{t} circ sigma_{h}left(c_{t}right) end{aligned} ftitotctht=σg(Wfxt+Ufct−1+bf)=σg(Wixt+Uict−1+bi)=σg(Woxt+Uoct−1+bo)=ft∘ct−1+it∘σc(Wcxt+bc)=ot∘σh(ct)

3. training RNN
3.1 Problem
RNN: The error surface is either very flat or very steep → 梯度消失/爆炸 Gradient Vanishing/Exploding
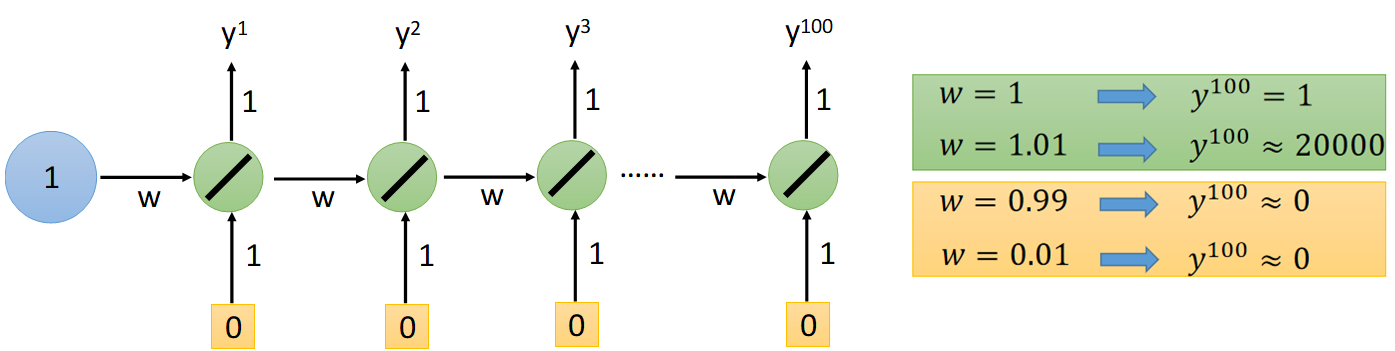
3.2 Techniques
- Clipping the gradients
- Advanced optimization technology
- NAG
- RMSprop
- Try LSTM (or other simpler variants)
- Can deal with gradient vanishing (not gradient explode)
- Memory and input are added (在RNN中,对于每一个输入,memory会重置)
- The influence never disappears unless forget gate is closed (No Gradient vanishing, if forget gate is opened.)
- Better initialization
- Vanilla RNN Initialized with Identity matrix + ReLU activation function [Quoc V. Le, arXiv’15]
参考资料
[1] Recurrent neural network - Wikipedia
[2] Long short-term memory - Wikipedia
[3] Bidirectional Recurrent Neural Networks - Dive into Deep …
[4] 机器学习 李宏毅
最后
以上就是无辜香水最近收集整理的关于学习笔记 NLP里的RNN和LSTM的全部内容,更多相关学习笔记内容请搜索靠谱客的其他文章。





![[深度学习-原理篇]什么是循环神经网络RNN与LSTM1. 什么是 RNN2. RNN 的结构3. 标准RNN的前向输出流程4. RNN的训练方法——BPTT5. LSTM6. 长期依赖(Long-Term Dependencies)问题- RNN缺陷7. LSTM 网络8. LSTM 的核心思想9. 逐步理解 LSTM10. LSTM 的变体11. 双向LSTM(Bi-directional LSTM)循环神经网络系列](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)


发表评论 取消回复