简介
RNN( Recurrent Neural Network 循环神经网络) 跟人的大脑记忆差不多。RNN通过反向传播和记忆机制,能够处理任意长度的序列,在架构上比前馈神经网络更符合生物神经网络的结构,它的产生也正是为了解决这类问题而应用而生的。RNN及改进的LSTM等深度学习模型都是基于神经网络而发展的起来的认知计算模型。
RNN的架构有哪些?
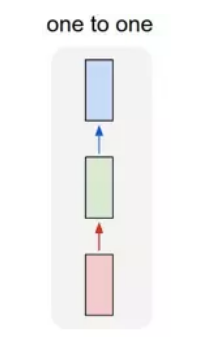
- one to one:
一个输入(单一标签)对应一个输出(单一标签)。
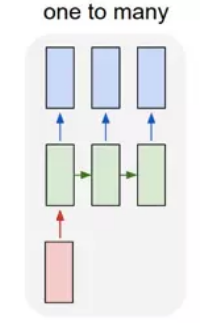
- one to many:
一个输入对应多个输出,即这个架构多用于图片的对象识别,即输入一个图片,输出一个文本序列。
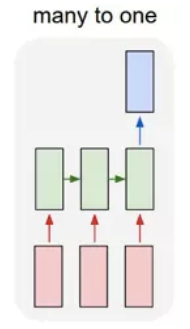
- many to one:
多个输入对应一个输出,多用于文本分类或视频分类,即输入一段文本或视频片段,输出类别。
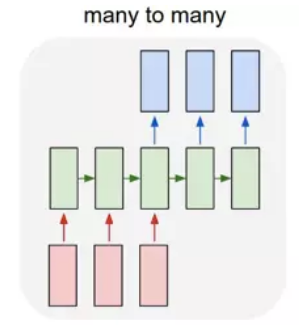
- many to many 1:
这种结构广泛的用于机器翻译,输入一个文本,输出另一种语言的文本。
- many to many 2:
这种广泛的用于序列标注。
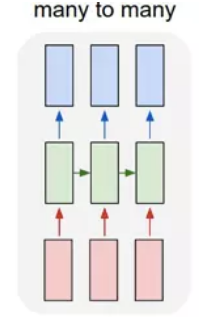
RNN原理:
先介绍RNN最简单的循环神经网络,称为Simple-RNN,它是后面LSTM的基础。从网络架构上,Simple-RNN与BP神经网络一脉相承,两个网络都有前馈层和反馈层,但Simple-RNN引入的基于时间的循环机制,因此而发展了BP网络。下面从整体上考察Simple-RNN的架构和训练运行。
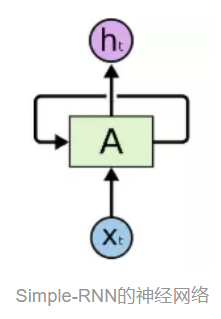
神经网络为A,通过读取某个t时间(状态)的输入Xt,然后输出一个值ht。循环可以使得从当前时间步传递到下一个时间步。这些循环使得RNN可以被看做同一个网络在不同时间步的多次循环,每个神经元会把更新的结果传递到下一个时间步,为了更清楚的说明,将这个循环展开,放大该神经网络A,看一下网络细节:
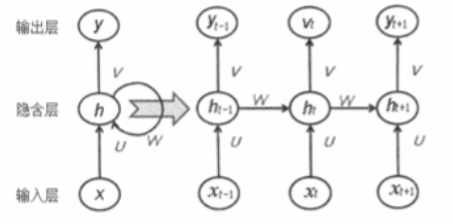
递归网络的输入是一整个序列,也就是X=[ X0, … , Xt-1, Xt, Xt+1, XT ],对于语言模型来说,每一个Xt将代表一个词向量,一整个序列就代表一句话。ht代表时刻t的隐含状态,yt代表时刻t的输出。
其中:U是输入层到隐藏层直接的权重;W是隐藏层到隐藏层的权重;V是隐藏层到输出层的权重。
RNN展开以后,似乎都已经很明白了,正向传播( Forward Propagation ) 依次按照时间的顺序计算一次即可,反向传播( Back Propagation ) 从最后一个时间将累积的残差传递回来即可,跟普通的BP神经网络训练并没有本质上的不同。由于加入了时间顺序,计算的方式有所不同,这称为BPTT ( Back Propagation Through Time ) 算法。
1.正向传播:
首先在t=0的时刻,U、V、W都被随机初始化好了,h0通常初始化为0,然后进行如下计算:
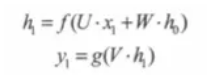
其中,f 、g 是激活函数,g通常是Softmax。
注:RNN有记忆能力,正是因为这个 W,记录了以往的输入状态,作为下次的输出。这个可以简单的理解为:

全局误差为:
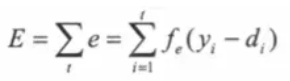
E是全局误差,ei是第i个时间步的误差,y是输出层预测结果,d是实际结果。误差函数fe可以为交叉熵 ,也可以是平方误差项等。
2.反向传播:
就是利用输出层的误差e,求解各个权重ΔV、ΔU、ΔW,然后梯度下降更新各个权重。各个权重的更新的递归公式:
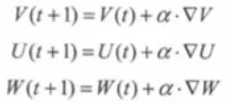
小结:
到这里,Simple-RNN原理也就讲解完了。但是实际应用中并不多,原因为: - 如果出入越长的话,展开的网络就越深,对于“深度”网络训练的困难最常见的是“梯度爆炸” 和 “梯度消失” 的问题。
- Simple-RNN善于基于先前的词预测下一个词,但在一些更加复杂的场景中,例如,“我出生在法国…我能将一口流利的法语。”
“法国”和“法语”则需要更长时间的预测,而随着上下文之间的间隔不断增大时,Simple-RNN会丧失学习到连接如此远的信息的能力。
系列传送门:
序列模型汇总__长短期记忆网络(LSTM)(二)
序列模型汇总__门控循环单元(GRU)(三)
最后
以上就是调皮大雁最近收集整理的关于序列模型汇总__循环神经网络(RNN)(一)的全部内容,更多相关序列模型汇总__循环神经网络(RNN)(一)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复