github链接
和其他代码比起来,这个代码的结构很不科学,只有一个主文件,model和train没有分开……
参考链接:
tensorflow笔记:多层LSTM代码分析
代码分析:
- num_steps是什么?
下图左边是rolled版本,这种结构的反向传播计算很困难。因此采用右边这种结构,有num_step个x输入。每次训练数据输入格式为[batch_size, num_steps](类比seq2seq中的encoder_input的shape[batch_size, encoder_size])。如下图: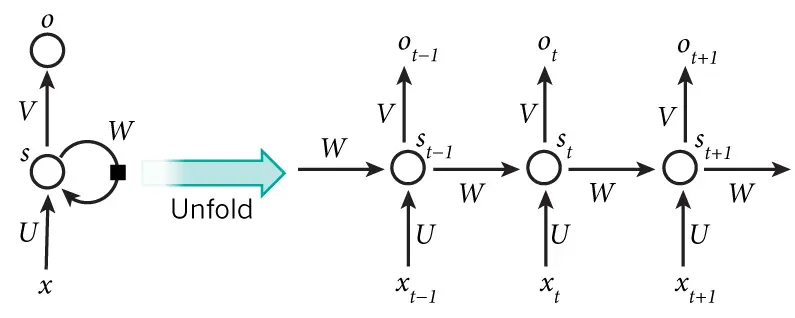
- 和seq2seq的区别?
seq2seq是分为了两个部分,encoder和decoder部分。在RNN中,只有encode,即输入x,输出o,不需要decoder_input部分。在本例中,输入是[batch_size, num_steps]个的单词预测概率(one-hot形式)。和[batch_size, num_steps]个target(数字形式)作比较。计算loss的函数是tf.contrib.seq2seq.sequence_loss - graph是怎么run起来的?
定义了模型之后,第二个graph负责给model feed并统计结果。
要fetch的内容有:model.cost,model.final_state, model.eval_op(train_op)vals = session.run(fetches, feed_dict)
代码结构:
reader.py中的两个主要函数:
ptb_raw_data把三个txt中的单词都转化成唯一的id,只保留最常见的10000个单词。ptb_producer定义了input和target。格式为:batch_size*num_steps的二维矩阵。target是input右移1位后的结果。即通过前一个单词预测后一个单词。
ptb_word_lm.py中
首先定义了PTBModel结构,__init__函数定义了self.config, inputs, output, state, self.logits, self.cost, self.final_state, (self.learning_rate, self._train_op, self._new_lr, self._lr_update)这些是train才有的。
最后在main函数里
- 第一个graph里,分别构建learnvalidtest PTBmodel,保存在metagraph中。
- 第二个graph里,导入metagraph,对于三个模型分别run_epoch。
转载于:https://www.cnblogs.com/yingtaomj/p/7777222.html
最后
以上就是任性黄蜂最近收集整理的关于TensorFlow RNN tutorial解读的全部内容,更多相关TensorFlow内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复