RNN:
循环神经网络(下面简称RNNs)可以通过不停的将信息循环操作,保证信息持续存在
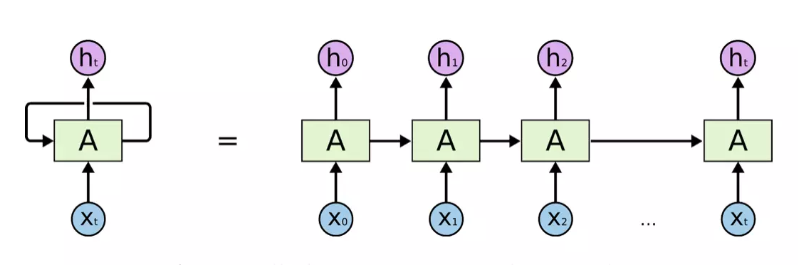
长依赖存在的问题:
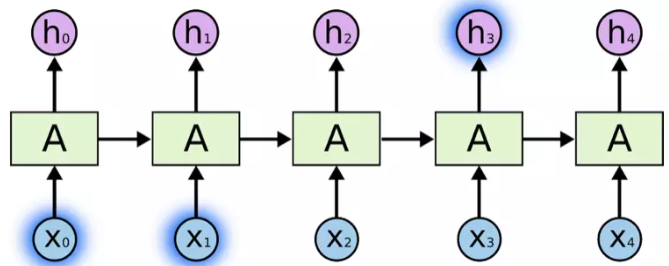
当有用信息与需要该信息的位置距离较近时,RNNs能够学习利用以前的信息来对当前任务进行相应的操作
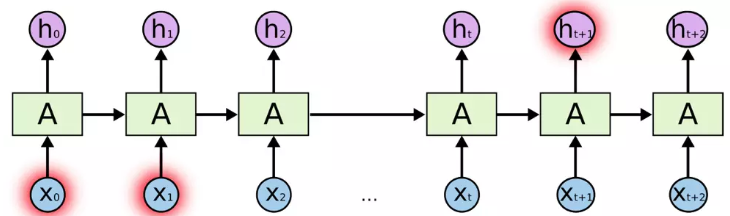
当有用信息与需要该信息的位置距离较远时,这样容易导致RNNs不能学习到有用的信息,最终推导的任务可能失败
LSTM:
Long Short Term Memory networks,一种特殊的RNN网络,为了解决长依赖问题
普通的RNN模块内部只有一个tanh层
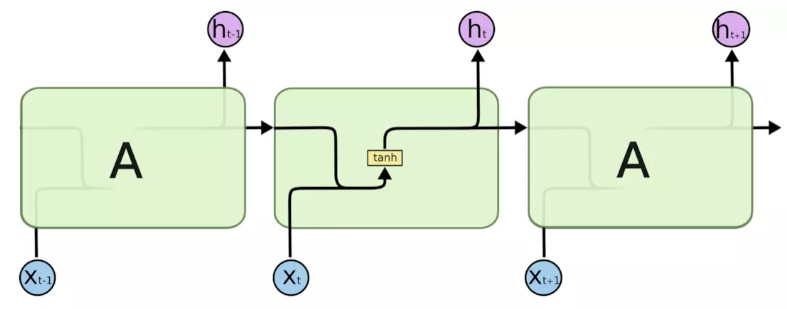
而LSTM模块内部更加复杂
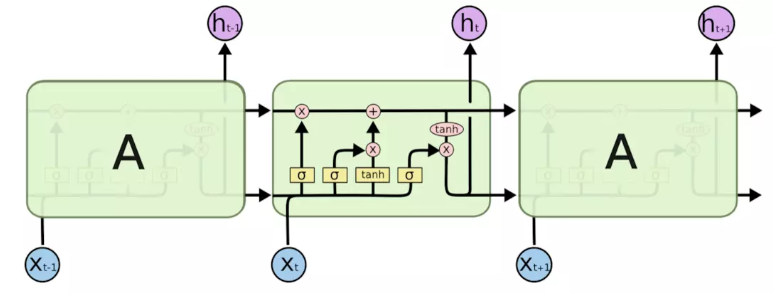
LSTM原理结构:
LSTMs的核心是细胞状态,用贯穿细胞的水平线表示。
细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。通过一种被称为门的结构对细胞状态进行删除或者添加信息,门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合,sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层
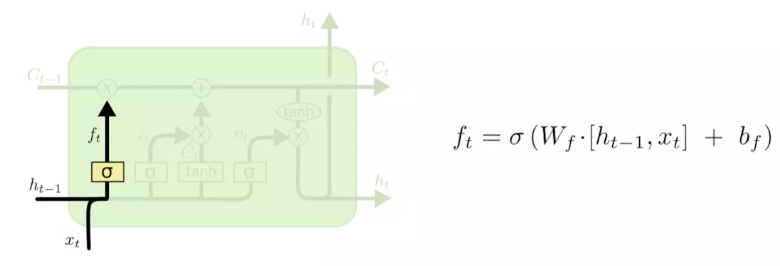
遗忘门:(forget gate)
通过查看h_{t-1}和x_{t}信息来输出一个0-1之间的向量,该向量里面的0-1值表示细胞状态C_{t-1}中的哪些信息保留或丢弃多少
输入门:(input gate)
决定给细胞状态添加哪些新的信息
首先,利用h_{t-1}和x_{t}通过一个称为输入门的操作来决定更新哪些信息。然后利用h_{t-1}和x_{t}通过一个tanh层得到新的候选细胞信息tilde C_{t},这些信息可能会被更新到细胞信息中
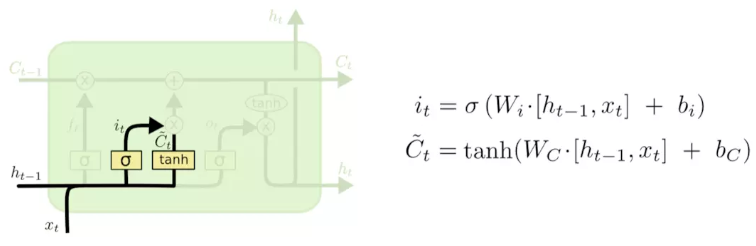
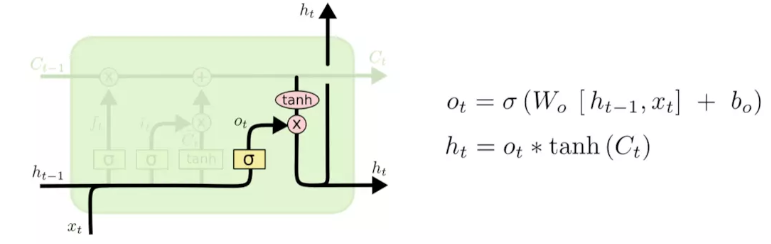
输出门:(output gate)
更新完细胞状态后需要根据输入的h_{t-1}和x_{t}来判断输出细胞的哪些状态特征
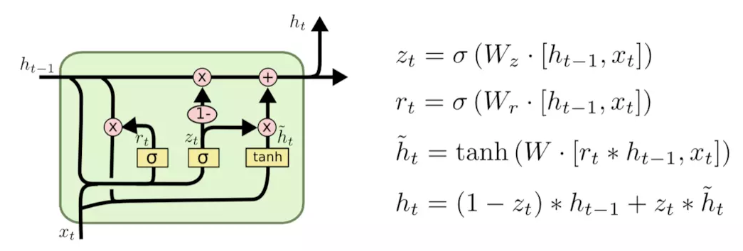
GRU
将忘记门和输入门合并成一个新的门,称为更新门,另外还有一个重置门
为什么LSTM可以防止梯度消失
RNN 中的梯度消失/梯度爆炸和普通的 MLP 或者深层 CNN 中梯度消失/梯度爆炸的含义不一,RNN 中同样的权重在各个时间步共享,最终的梯度 g = 各个时间步的梯度 g_t 的和。
RNN 中总的梯度是不会消失的。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和便不会消失
RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系
LSTM 中梯度的传播有很多条路径,细胞流动这条路径上只有逐元素相乘和相加的操作,梯度流最稳定;但是其他路径(例如输入门路径 )上梯度流与普通 RNN 类似,照样会发生相同的权重矩阵反复连乘,依然会爆炸或者消失
由于总的远距离梯度 = 各条路径的远距离梯度之和,即便其他远距离路径梯度消失了,只要保证有一条远距离路径梯度不消失,总的远距离梯度就不会消失(正常梯度 + 消失梯度 = 正常梯度)。因此 LSTM 通过改善一条路径上的梯度问题拯救了总体的远距离梯度。
当遗忘门接近 1(例如模型初始化时会把 forget bias 设置成较大的正数,让遗忘门饱和),这时候远距离梯度不消失;
当遗忘门接近 0,但这时模型是故意阻断梯度流的,这不是 bug 而是 feature
但其他路径上梯度有可能爆炸,此时总的远距离梯度 = 正常梯度 + 爆炸梯度 = 爆炸梯度,因此 LSTM 仍然有可能发生梯度爆炸,但LSTM 发生梯度爆炸的频率要低得多
最后
以上就是温婉汽车最近收集整理的关于LSTM原理及其如何处理梯度弥散问题RNN:长依赖存在的问题:LSTM:的全部内容,更多相关LSTM原理及其如何处理梯度弥散问题RNN:长依赖存在内容请搜索靠谱客的其他文章。








发表评论 取消回复