1.N-gram 语言模型
一般自然语言处理的传统方法是将句子处理为一个词袋模型(Bag-of-Words,BoW),而不考虑每个词的顺序,比如用朴素贝叶斯算法进行垃圾邮件识别或者文本分类。在中文里有时候这种方式没有问题,因为有些句子即使把词的顺序打乱,还是可以看懂这句话在说什么.但有时候不行,词的顺序打乱,句子意思就变得让人不可思议了。
N-gram 模型是一种语言模型(Language Model,LM),是一个基于概率的判别模型,它的输入是一句话(词的顺序序列),输出是这句话的概率,即这些词的联合概率(Joint Probability)。
使用 N-gram 语言模型思想,一般是需要知道当前词以及前面的词,因为一个句子中每个词的出现并不是独立的。比如,如果第一个词是“空气”,接下来的词是“很”,那么下一个词很大概率会是“新鲜”。类似于我们人的联想,N-gram 模型知道的信息越多,得到的结果也越准确。
N-gram 模型,在自然语言处理中主要应用在如词性标注、垃圾短信分类、分词器、机器翻译和语音识别、语音识别等领域。N-gram 模型并不是完美的,它存在如下优缺点:
- 优点:包含了前 N-1 个词所能提供的全部信息,这些词对于当前词的出现概率具有很强的约束力;
- 缺点:需要很大规模的训练文本来确定模型的参数,当 N 很大时,模型的参数空间过大。所以常见的 N 值一般为1,2,3等。还有因数据稀疏而导致的数据平滑问题,解决方法主要是拉普拉斯平滑和内插与回溯。
2.NNLM语言模型
据 N-gram 的优缺点,它的进化版 NNLM(Neural Network based Language Model)诞生了。
NNLM 由 Bengio 在2003年提出,它是一个很简单的模型,由四层组成,输入层、嵌入层、隐层和输出层,模型结构如下图(来自百度图片):
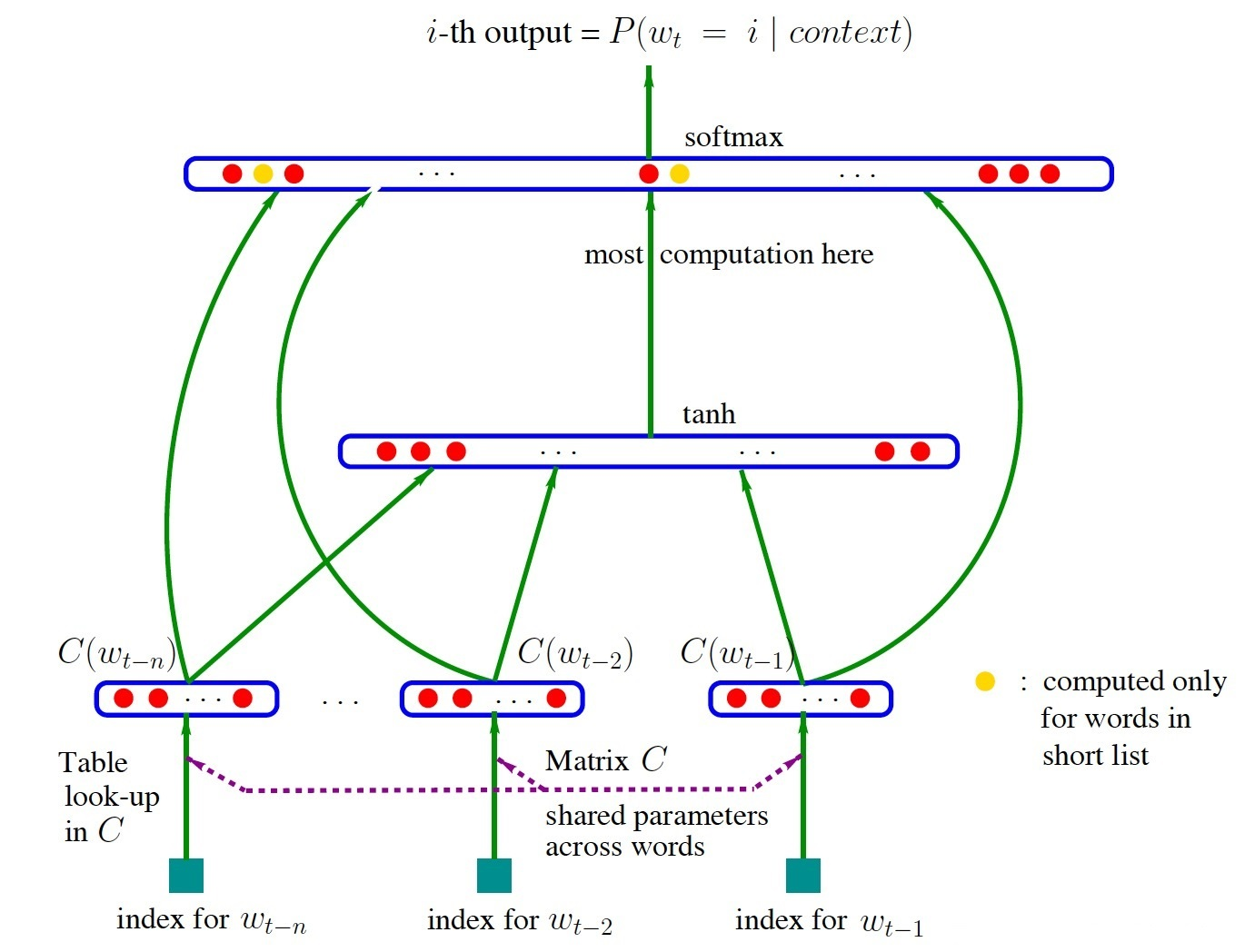
NNLM 接收的输入是长度为 N 的词序列,输出是下一个词的类别。首先,输入是词序列的 index 序列,例如词“我”在字典(大小为|V|)中的 index 是10,词“是”的 index 是23, “小明”的 index 是65,则句子“我是小明”的 index 序列就是 10、 23、65。嵌入层(Embedding)是一个大小为 |V|×K 的矩阵,从中取出第10、23、65行向量拼成 3×K 的矩阵就是 Embedding 层的输出了。隐层接受拼接后的 Embedding 层输出作为输入,以 tanh 为激活函数,最后送入带 softmax 的输出层,输出概率。
NNLM 最大的缺点就是参数多,训练慢,要求输入定长 N 这一点很不灵活,同时不能利用完整的历史信息。
3.RNNLM 语言模型
针对 NNLM 存在的问题,Mikolov 在2010年提出了 RNNLM,有兴趣可以阅读相关论文,其结构实际上是用 RNN 代替 NNLM 里的隐层,这样做的好处,包括减少模型参数、提高训练速度、接受任意长度输入、利用完整的历史信息。同时,RNN 的引入意味着可以使用 RNN 的其他变体,像 LSTM、BLSTM、GRU 等等,从而在序列建模上进行更多更丰富的优化。
4.RNN
RNN 的知识还有很多,比如双向 RNN 等。
RNN为序列数据而生;RNN 称为循环神经网路,因为这种网络有“记忆性”,主要应用在自然语言处理(NLP)和语音领域。RNN 具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN 能够对任何长度的序列数据进行处理,但由于该网络结构存在“梯度消失”问题,所以在实际应用中,解决梯度消失的方法有:梯度裁剪(Clipping Gradient)和 LSTM(Long Short-Term Memory)。
RNN的经典结构【最初】:
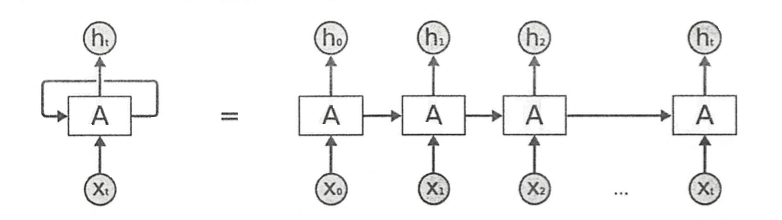
RNN 包含输入单元(Input Units),输入集标记为 {x_0,x_1,…,x_t,x_t…};输出单元(Output Units)的输出集则被标记为 {y_0,y_1,…,y_t,…};RNN 还包含隐藏单元(Hidden Units),我们将其输出集标记为 {h_0,h_1,…,h_t,…},这些隐藏单元完成了最为主要的工作。
5.LSTM结构
LSTM 在1997年由“Hochreiter & Schmidhuber”提出,目前已经成为 RNN 中的标准形式,用来解决上面提到的 RNN 模型存在“长期依赖”的问题。
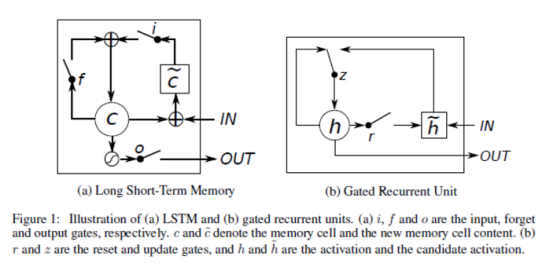
LSTM 通过三个“门”结构来控制不同时刻的状态和输出。所谓的“门”结构就是使用了 Sigmoid 激活函数的全连接神经网络和一个按位做乘法的操作,Sigmoid 激活函数会输出一个0~1之间的数值,这个数值代表当前有多少信息能通过“门”,0表示任何信息都无法通过,1表示全部信息都可以通过。其中,“遗忘门”和“输入门”是 LSTM 单元结构的核心。
-
遗忘门,用来让 LSTM“忘记”之前没有用的信息。它会根据当前时刻节点的输入 X_t 、上一时刻节点的状态C_{t-1}和上一时刻节点的输出 h_{t-1}来决定哪些信息将被遗忘。
-
输入门,LSTM 来决定当前输入数据中哪些信息将被留下来。在 LSTM 使用遗忘门“忘记”部分信息后需要从当前的输入留下最新的记忆。输入门会根据当前时刻节点的输入 X_t 、上一时刻节点的状态 C_{t-1}和上一时刻节点的输出 h_{t-1}来决定哪些信息将进入当前时刻节点的状态 C_t,模型需要记忆这个最新的信息。
-
输出门,LSTM 在得到最新节点状态 C_t后,结合上一时刻节点的输出 h_{t-1}和当前时刻节点的输入 X_t来决定当前时刻节点的输出。
6.GRU 结构
GRU(Gated Recurrent Unit)是2014年提出来的新的 RNN 架构,它是简化版的 LSTM。
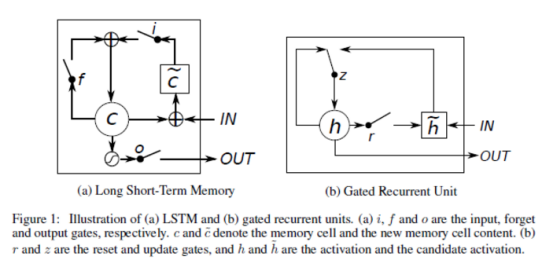
在超参数均调优的前提下,据说效果和 LSTM 差不多,但是参数少了1/3,不容易过拟合。如果发现 LSTM 训练出来的模型过拟合比较严重,可以试试 GRU。
7.基于 Keras 的 LSTM 和 GRU 文本分类
使用的数据集是司法数据。
整个过程包括:
- 语料加载
- 分词和去停用词
- 数据预处理
- 使用 LSTM 分类
- 使用 GRU 分类
7.1 准备数据
7.1.1 加载数据
# 加载语料库和停用词
import random
import jieba
import pandas as pd
ch_path = '/data/'
#加载停用词
stopwords=pd.read_csv(ch_path+'stopwords.txt',index_col=False,quoting=3,sep="t",names=['stopword'], encoding='utf-8')
stopwords=stopwords['stopword'].values
#加载语料
laogong_df = pd.read_csv(ch_path+'beilaogongda.csv', encoding='utf-8', sep=',')
laopo_df = pd.read_csv(ch_path+'beilaopoda.csv', encoding='utf-8', sep=',')
erzi_df = pd.read_csv(ch_path+'beierzida.csv', encoding='utf-8', sep=',')
nver_df = pd.read_csv(ch_path+'beinverda.csv', encoding='utf-8', sep=',')
#删除语料的nan行
laogong_df.dropna(inplace=True)
laopo_df.dropna(inplace=True)
erzi_df.dropna(inplace=True)
nver_df.dropna(inplace=True)
#转换
laogong = laogong_df.segment.values.tolist()
laopo = laopo_df.segment.values.tolist()
erzi = erzi_df.segment.values.tolist()
nver = nver_df.segment.values.tolist()
7.1.2 分词、去停用词
# 分词、去除停用词
# 定义分词和打标签函数preprocess_text
#参数content_lines即为上面转换的list
#参数sentences是定义的空list,用来储存打标签之后的数据
#参数category 是类型标签
def preprocess_text(content_lines, sentences, category):
for line in content_lines:
try:
segs=jieba.lcut(line)
segs = [v for v in segs if not str(v).isdigit()]#去数字
segs = list(filter(lambda x:x.strip(), segs)) #去左右空格
segs = list(filter(lambda x:len(x)>1, segs))#长度为1的字符
segs = list(filter(lambda x:x not in stopwords, segs)) #去掉停用词
sentences.append((" ".join(segs), category))# 打标签
except Exception:
print(line)
continue
#调用函数、生成训练数据
sentences = []
preprocess_text(laogong, sentences,0)
preprocess_text(laopo, sentences, 1)
preprocess_text(erzi, sentences, 2)
preprocess_text(nver, sentences, 3)
7.1.3 打散数据、并获取输入特征和文本标签
# 打散数据,使数据分布均匀,然后获取特征和标签列表:
#打散数据,生成更可靠的训练集
random.shuffle(sentences)
#控制台输出前10条数据,观察一下
for sentence in sentences[:10]:
print(sentence[0], sentence[1])
#所有特征和对应标签
all_texts = [ sentence[0] for sentence in sentences]
all_labels = [ sentence[1] for sentence in sentences]
7.1.4 数据拆分
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.layers import Dense, Input, Flatten, Dropout
from keras.layers import LSTM, Embedding,GRU
from keras.models import Sequential
import numpy as np
# 数据拆分
#预定义变量
MAX_SEQUENCE_LENGTH = 100 #最大序列长度
EMBEDDING_DIM = 200 #embdding 维度
VALIDATION_SPLIT = 0.18 #验证集比例
TEST_SPLIT = 0.2 #测试集比例
#keras的sequence模块文本序列填充
tokenizer = Tokenizer()
tokenizer.fit_on_texts(all_texts)#生成词典tok.fit_on_texts
sequences = tokenizer.texts_to_sequences(all_texts)# 使用字典将对应词转成index。shape为 (文档数,每条文档的长度)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(all_labels))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
#数据切分
p1 = int(len(data)*(1-VALIDATION_SPLIT-TEST_SPLIT))
p2 = int(len(data)*(1-TEST_SPLIT))
x_train = data[:p1]
y_train = labels[:p1]
x_val = data[p1:p2]
y_val = labels[p1:p2]
x_test = data[p2:]
y_test = labels[p2:]
7.2 LSTM 文本分类
#LSTM训练模型
model = Sequential()
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH))
model.add(LSTM(200, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
#模型编译
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
print(model.metrics_names)
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=10, batch_size=128)
model.save('lstm.h5')
#模型评估
print(model.evaluate(x_test, y_test))
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 100, 200) 96200
_________________________________________________________________
lstm_1 (LSTM) (None, 200) 320800
_________________________________________________________________
dropout_2 (Dropout) (None, 200) 0
_________________________________________________________________
dense_4 (Dense) (None, 64) 12864
_________________________________________________________________
dense_5 (Dense) (None, 4) 260
=================================================================
Total params: 430,124
Trainable params: 430,124
Non-trainable params: 0
_________________________________________________________________
[]
Epoch 1/10
9/9 [==============================] - 11s 1s/step - loss: 1.3527 - acc: 0.3481 - val_loss: 1.2389 - val_acc: 0.4205
Epoch 2/10
9/9 [==============================] - 10s 1s/step - loss: 1.1471 - acc: 0.6856 - val_loss: 1.7617 - val_acc: 0.2682
Epoch 3/10
9/9 [==============================] - 10s 1s/step - loss: 0.9292 - acc: 0.8380 - val_loss: 0.8591 - val_acc: 0.5662
Epoch 4/10
9/9 [==============================] - 10s 1s/step - loss: 0.5811 - acc: 0.8862 - val_loss: 0.2736 - val_acc: 0.9901
Epoch 5/10
9/9 [==============================] - 10s 1s/step - loss: 0.2969 - acc: 0.9479 - val_loss: 0.1745 - val_acc: 0.9934
Epoch 6/10
9/9 [==============================] - 10s 1s/step - loss: 0.0883 - acc: 0.9981 - val_loss: 0.1853 - val_acc: 0.9636
Epoch 7/10
9/9 [==============================] - 10s 1s/step - loss: 0.0713 - acc: 0.9923 - val_loss: 0.0233 - val_acc: 1.0000
Epoch 8/10
9/9 [==============================] - 10s 1s/step - loss: 0.0258 - acc: 0.9971 - val_loss: 0.3943 - val_acc: 0.8146
Epoch 9/10
9/9 [==============================] - 10s 1s/step - loss: 0.0925 - acc: 0.9711 - val_loss: 0.0245 - val_acc: 1.0000
Epoch 10/10
9/9 [==============================] - 10s 1s/step - loss: 0.0159 - acc: 0.9990 - val_loss: 0.0113 - val_acc: 1.0000
11/11 [==============================] - 1s 79ms/step - loss: 0.0237 - acc: 0.9910
[0.0236809104681015, 0.9910447597503662]
7.3 GRU 文本分类
model = Sequential()
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH))
model.add(GRU(200, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
print(model.metrics_names)
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=10, batch_size=128)
model.save('gru.h5')
print(model.evaluate(x_test, y_test))
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 200) 96200
_________________________________________________________________
gru (GRU) (None, 200) 241200
_________________________________________________________________
dropout_1 (Dropout) (None, 200) 0
_________________________________________________________________
dense_2 (Dense) (None, 64) 12864
_________________________________________________________________
dense_3 (Dense) (None, 4) 260
=================================================================
Total params: 350,524
Trainable params: 350,524
Non-trainable params: 0
_________________________________________________________________
[]
Epoch 1/10
9/9 [==============================] - 10s 1s/step - loss: 1.3271 - acc: 0.3905 - val_loss: 1.1334 - val_acc: 0.5033
Epoch 2/10
9/9 [==============================] - 9s 1s/step - loss: 1.3673 - acc: 0.6548 - val_loss: 0.8140 - val_acc: 0.8079
Epoch 3/10
9/9 [==============================] - 10s 1s/step - loss: 0.6799 - acc: 0.8505 - val_loss: 0.7402 - val_acc: 0.7517
Epoch 4/10
9/9 [==============================] - 10s 1s/step - loss: 0.4569 - acc: 0.9171 - val_loss: 0.2887 - val_acc: 0.9735
Epoch 5/10
9/9 [==============================] - 10s 1s/step - loss: 0.2114 - acc: 0.9932 - val_loss: 0.2679 - val_acc: 0.8874
Epoch 6/10
9/9 [==============================] - 9s 1s/step - loss: 0.1509 - acc: 0.9788 - val_loss: 0.0708 - val_acc: 0.9967
Epoch 7/10
9/9 [==============================] - 9s 1s/step - loss: 0.0417 - acc: 0.9990 - val_loss: 0.0357 - val_acc: 0.9967
Epoch 8/10
9/9 [==============================] - 10s 1s/step - loss: 0.0179 - acc: 0.9990 - val_loss: 0.0136 - val_acc: 1.0000
Epoch 9/10
9/9 [==============================] - 9s 1s/step - loss: 0.0092 - acc: 0.9990 - val_loss: 0.0057 - val_acc: 1.0000
Epoch 10/10
9/9 [==============================] - 10s 1s/step - loss: 0.0615 - acc: 0.9730 - val_loss: 0.0162 - val_acc: 0.9967
11/11 [==============================] - 1s 68ms/step - loss: 0.0547 - acc: 0.9851
[0.05468611791729927, 0.9850746393203735]
最后
以上就是清爽金针菇最近收集整理的关于12.NLP中的RNN、LSTM、GRU1.N-gram 语言模型2.NNLM语言模型3.RNNLM 语言模型4.RNN5.LSTM结构6.GRU 结构7.基于 Keras 的 LSTM 和 GRU 文本分类的全部内容,更多相关12.NLP中的RNN、LSTM、GRU1.N-gram内容请搜索靠谱客的其他文章。





![[人工智能-深度学习-49]:循环神经网络 - RNN与NLP的关系以及RNN在人工神经网络中的位置](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)


发表评论 取消回复