Hadoop的FileSystem类是与Hadoop的某一文件系统进行交互的API,虽然我们主要聚焦于HDFS实例,但还是应该集成FileSystem抽象类,并编写代码,使其在不同的文件系统中可移植,对于测试编写的程序非常重要。可以使用本地文件系统中的存储数据快速进行测试。
一、从Hadoop FileSystem读取数据
1、java.net.URL
private FileSystem fs; /** * 通过FsUrlStreamHandlerFactory实例调用java.net.URL对象的setURLStreamHandlerFactory方法,让java程序识别Hadoop的HDFS url 每个java虚拟机只能调用一次这个方法,因此通常在静态方法中调用。这个限制意味着如果程序的其他组件已经声明了一个setURLStreamHandlerFactory实例,你 将无法使用这种方法从hadoop中读取数据 */ static { URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); } /** * 读取hadoop文件系统中文件的内容(不推荐使用) */ @Test public void catFiles(){ InputStream inputStream=null; try { //调用java.net.URL对象打开数据流 inputStream=new URL("hdfs://s100:8020/user/enmoedu/test.txt").openStream(); //调用copyBytes函数,可以在输入流和输出流之间复制数据, //System.out输出到控制台,第三个参数是设置缓冲区大小,最后一个,设置复制结束后是否关闭数据流 IOUtils.copyBytes(inputStream, System.out, 1024,false); } catch (IOException e) { e.printStackTrace(); }finally{ //关闭数据流 IOUtils.closeStream(inputStream); } }
执行结果:
hello chengpingyijun
hello enmoedu
2、org.apache.hadoop.fs.FileSystem
/** * 读取hadoop文件系统中文件的内容(推荐使用) */ @Test public void fileSystemCat(){ String url="hdfs://s100:8020/user/enmoedu/test.txt"; Configuration configuration=new Configuration(); InputStream inputStream=null; try { //通过给定的URI方案和权限来确定要使用的文件系统 fs=FileSystem.get(URI.create(url),configuration); //FileSystem实例后,调用open()来获取文件的输入流 inputStream=fs.open(new Path(url)); //调用copyBytes函数,可以在输入流和输出流之间复制数据, //System.out输出到控制台,第三个参数是设置缓冲区大小,最后一个,设置复制结束后是否关闭数据流 IOUtils.copyBytes(inputStream, System.out, 1024,false); } catch (IOException e) { e.printStackTrace(); }finally { //关闭数据流 IOUtils.closeStream(inputStream); } }
执行结果:
hello chengpingyijun
hello enmoedu
查看HDFS上test.txt中的内容
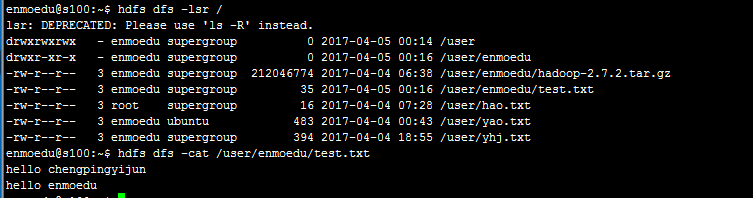
3、在HDFS上创建目录
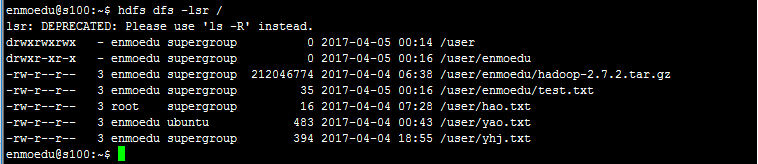
在HDFS上查看在user/目录下没有test文件
/** * 创建目录 */ @Test public void creatDir(){ String url="hdfs://s100:8020/user/test"; //configuration封装了HDFS客户端或者HDFS集群的配置信息, //该方法通过给定的URI方案和权限来确定要使用的文件系统 Configuration configuration=new Configuration(); try { //通过给定的URI方案和权限来确定要使用的文件系统 fs=FileSystem.get(URI.create(url), configuration); fs.mkdirs(new Path(url)); System.out.println("========================"); } catch (IOException e) { e.printStackTrace(); } }
执行结果
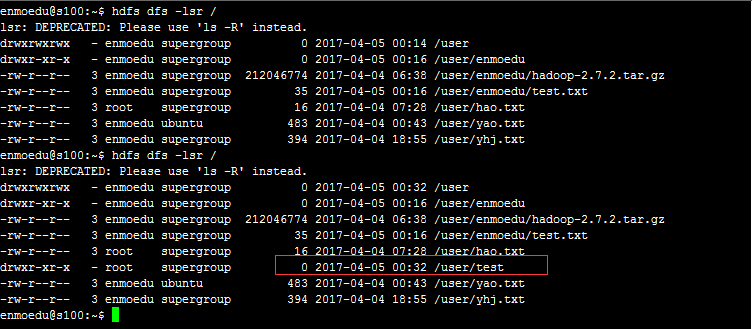
4、在HDFS上删除目录
/** * 删除目录 */ @Test public void deleteDir(){ String url="hdfs://s100:8020/user/test"; Configuration configuration=new Configuration(); try { //通过给定的URI方案和权限来确定要使用的文件系统 fs=FileSystem.get(URI.create(url), configuration); fs.delete(new Path(url)); System.out.println("========================"); } catch (IOException e) { e.printStackTrace(); } }
执行结果:
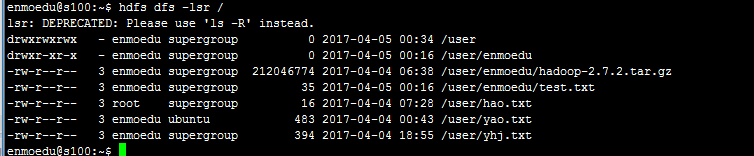
5、列出目录下的文件或目录名称示例
/** * 列出目录下的文件或目录名称示例 */ @Test public void listFiles(){ String urls[]={"hdfs://s100:8020/user/","hdfs://s100:8020/user/test.txt"}; Configuration configuration=new Configuration(); try { //通过给定的URI方案和权限来确定要使用的文件系统 fs=FileSystem.get(URI.create(urls[1]), configuration); //FileStatus类中封装了文件系统中文件和目录的元数据,包括文件的长度、块大小、复本、所有者、及权限信息 FileStatus file=fs.getFileStatus(new Path(urls[1])); //文件大小 long lenthg=file.getLen(); //块大小 long size=file.getBlockSize(); //最近修改时间 long time=file.getModificationTime(); //复本数 int n=file.getReplication(); //所有者 String owner=file.getOwner(); //权限信息 String chmod=file.getPermission().toString(); System.out.println("user目录下的方件有"); System.out.println("===================================="); //调用FileSystem中的listStatus()方法返回一个FileStatus[]数组 FileStatus[] listFiles=fs.listStatus(new Path(urls[0])); //遍历listFiles for (int i = 0; i < listFiles.length; i++) { FileStatus fileStatus = listFiles[i]; System.out.println(fileStatus.getPath().toString()); } System.out.println("user目录下的文件所具有的属性"); System.out.println("===================================="); System.out.println("文件大小是:"+lenthg); System.out.println("块大小"+size); System.out.println("最近修改时间:"+time); System.out.println("复本数"+n); System.out.println("文件所有者"+owner); System.out.println("权限信息"+chmod); //关闭输入流 fs.close(); } catch (IOException e) { e.printStackTrace(); } }
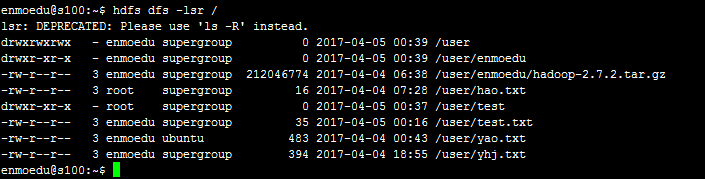
执行结果
user目录下的方件有
====================================
hdfs://s100:8020/user/enmoedu
hdfs://s100:8020/user/hao.txt
hdfs://s100:8020/user/test
hdfs://s100:8020/user/test.txt
hdfs://s100:8020/user/yao.txt
hdfs://s100:8020/user/yhj.txt
user目录下的文件所具有的属性
====================================
文件大小是:35
块大小134217728
最近修改时间:1491376577359
复本数3
文件所有者enmoedu
权限信息rw-r--r--
6、查看文件系统中文件存储的位置信息
/** * 查看文件系统中文件存储节点的位置信息 */ @Test public void locationFile(){ //测试hdfs上hadoop-2.7.2.tar.gz包的位置信息,其中hadoop-2.7.2.tar.gz的大小是212046774kb约202M String url="hdfs://s100:8020/user/enmoedu/hadoop-2.7.2.tar.gz"; //configuration封装了HDFS客户端或者HDFS集群的配置信息, //该方法通过给定的URI方案和权限来确定要使用的文件系统 Configuration configuration=new Configuration(); try { //通过给定的URI方案和权限来确定要使用的文件系统 fs=FileSystem.get(URI.create(url), configuration); //FileStatus的getFileStatus()方法用于获取文件或目录的FileStatus对象 FileStatus fileStatu=fs.getFileStatus(new Path(url)); //通过getFileBlockLocations方法获取location节点信息,第一个参数FileStatus对象,第二个是起始,第三个是结束 BlockLocation [] locationMsg=fs.getFileBlockLocations(fileStatu, 0, fileStatu.getLen()); //遍历BlockLocation对象 for (int i = 0; i < locationMsg.length; i++) { //获取主机名 String hosts[] =locationMsg[i].getHosts(); System.out.println("block_"+i+"_location:"+hosts[i]); } } catch (IOException e) { e.printStackTrace(); } }
执行结果
block_0_location:s102
block_1_location:s105
二、Hadoop SequenceFile的读写操作
SequenceFile是HDFS API提供的一种二进制文件支持,这种二进制文件直接将<key,value>序列化到文件中。
1、通过SequenceFile向方件中写入数据
/** * 通过SequenceFile向方件中写入内容 */ @Test public void wirteSequenceFile(){ String [] text={"Right Here Waiting","Oceans apart, day after day","and I slowly go insane.", " I hear your voice on the line,","But it doesn't stop the pain. "}; String url="hdfs://s100:8020/user/testsqu"; Configuration configuration=new Configuration(); //Writer内部类用于文件的写操作,假设Key和Value都为Text类型 SequenceFile.Writer writer=null; try { fs=FileSystem.get(URI.create(url), configuration); //相当于java中的int IntWritable key=new IntWritable(); Text value=new Text(); writer=SequenceFile.createWriter(fs, configuration, new Path(url), key.getClass(), value.getClass()); for (int i = 0; i < text.length; i++) { key.set(text.length-i); value.set(text[i%text.length]); //通过writer向文档中写入记录 writer.append(key, value); } } catch (IOException e) { e.printStackTrace(); }finally { IOUtils.closeStream(writer); } }
执行结果
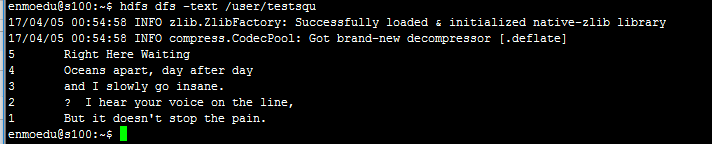
2、通过SequenceFile读取文件中的类容
/** * 读取SequenceFile中的内容 */ @Test public void readSequenceFile(){ String url="hdfs://s100:8020/user/testsqu"; Configuration configuration=new Configuration(); //Reader内部类用于文件的读取操作 SequenceFile.Reader reader=null; try { fs=FileSystem.get(URI.create(url), configuration); reader=new SequenceFile.Reader(fs, new Path(url), configuration); Writable key=(Writable) ReflectionUtils.newInstance(reader.getKeyClass(),configuration); Writable value=(Writable) ReflectionUtils.newInstance(reader.getValueClass(), configuration); long position=reader.getPosition(); while (reader.next(key, value)) { System.out.printf("[%s]t%sn",key,value); position=reader.getPosition(); } } catch (IOException e) { e.printStackTrace(); }finally { IOUtils.closeStream(reader); } }
执行结果
[5] Right Here Waiting
[4] Oceans apart, day after day
[3] and I slowly go insane.
[2] I hear your voice on the line,
[1] But it doesn't stop the pain.
转载于:https://www.cnblogs.com/cpyj/p/6669111.html
最后
以上就是虚拟咖啡豆最近收集整理的关于hadoop FileSystem类和SequenceFile类实例的全部内容,更多相关hadoop内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复