【Torch笔记】DataLoader与Dataset
torch.utils.data.DataLoader 用于构建可迭代的数据装载器:
- dataset:Dataset类,决定数据从哪里读取以及如何读取
- batchsize:批大小
- num_works:是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_last:当样本数不能被 bathsize 整除时,是否舍弃最后一批数据
Epoch:所有训练样本都已输入到模型中,称为一个 Epoch
Iteration:一批样本输入到模型中,称之为一个 Iteration
Batchsize:批大小,决定一个 Epoch 有多少个 Iteration
torch.utils.data.Dataset 是 Dataset 抽象类,所有自定义的 Dataset 都要继承它,并完成复写 __getitem__()。
__get_item__() 接收一个索引,放回一个样本。
先实现 Dataset,然后创建 Dataset 实例,再根据实例创建 DataLoader。
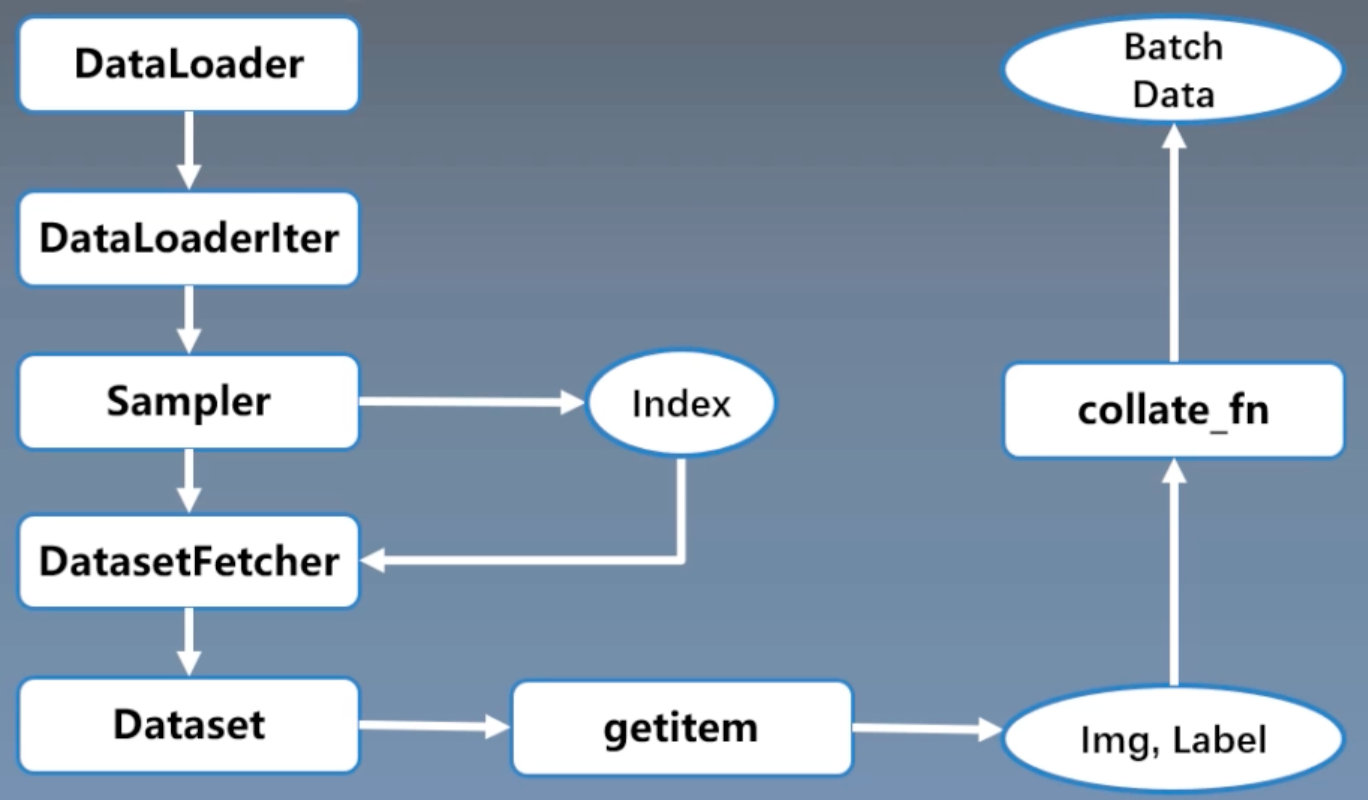
【Pytorch的数据读取机制】
Q1:读哪些数据?
A1:Sampler会返回index,确定读取哪些数据。
Q2:从哪些数据?
A2:在Dataset中进行设置。
Q3:怎么读数据?
A3:使用Dataset中的getitem。
最后
以上就是美好灯泡最近收集整理的关于【Torch笔记】DataLoader与Dataset【Torch笔记】DataLoader与Dataset的全部内容,更多相关【Torch笔记】DataLoader与Dataset【Torch笔记】DataLoader与Dataset内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复