1.可以先查询一下路径(可以是数据所在的路径)
![]()
需要更改路径的话用setwd(“路径”)
2.安装需要的包并使用
install.package("包名")
library("包名")randomForest:随机森林包
caret:常用于机器学习,数据处理,模型的结果展示。可用于数据的分割(训练集,测试集),查看混淆矩阵等等
pROC:衡量模型好坏
3.导入数据
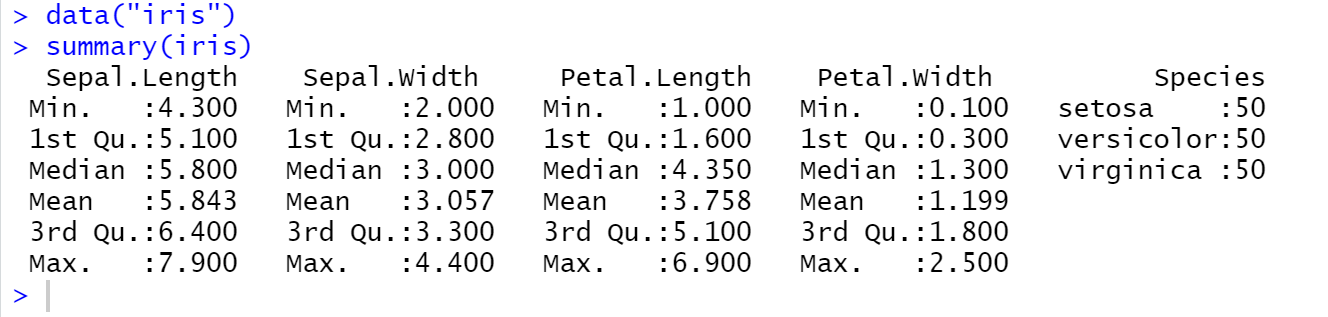
如果用R自带的数据,以iris为例:有5个变量,3个种类
可以把Species作为因变量,用其它4个变量来预测种类
如果要调用本地的数据:
data <- read.csv("./dataset.csv",header=T)
表示导入此路径的下的一个csv文件
4.划分数据集、测试集

用createDataPartition()来划分,p=0.8表示80%的数据作为训练集,20%作为测试集,一般的训练集和测试集是比例是7:3或者8:2
将trainlist中的数作为训练集trainset,将不在trainlist中的数作为测试集testset
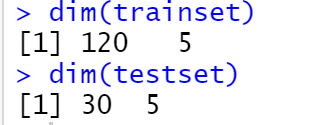
训练集有120行,5个变量
测试集有30行,5个变量
变量数目要保持一致
5.构建模型
R语言可以自动识别因变量的类型,如果是因子,就是做分类模型
为了复现模型,设置set.seed(数字随便写)
![]()
as.factor():R语言可以自动识别因变量的类型,如果是因子,就是做分类模型
data:训练集
importace:变量重要性排序
na.action:处理缺失值
na.pass:略过缺失值
na.omit:删除缺失值
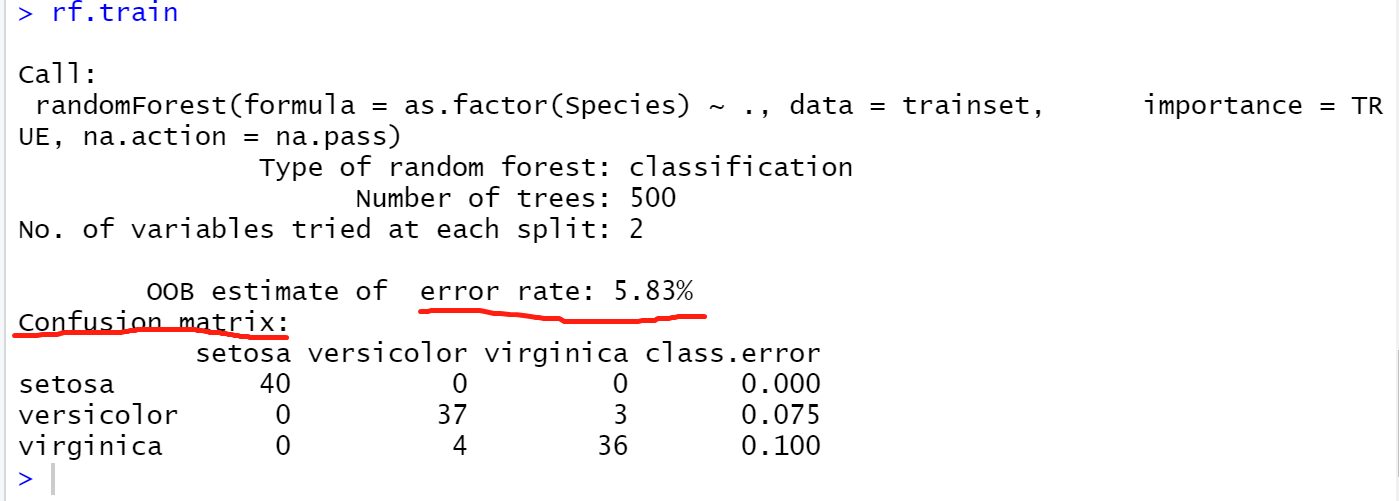
错误率:5.83%
混淆矩阵:看对角线,setosa的40个都预测正确,versicolor错了4个,virgincica错了3个
也可以画图看一下效果
plot(rf.train,main="randomforest origin") 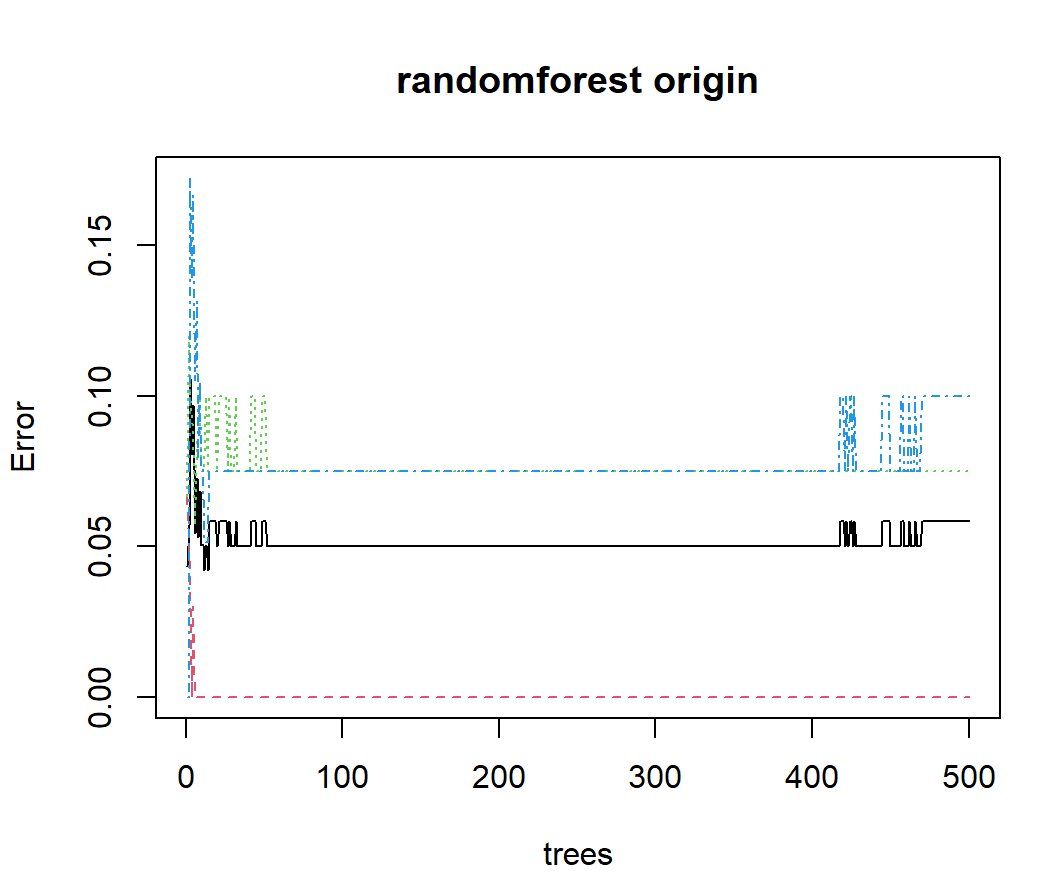
6.预测
得到预测结果:
rf.test <- predict(rf.train,newdata=testset,type="class")查看各项指标:
> rf.cf <- caret::confusionMatrix(as.factor(rf.test),as.factor(testset$Species))
> rf.cf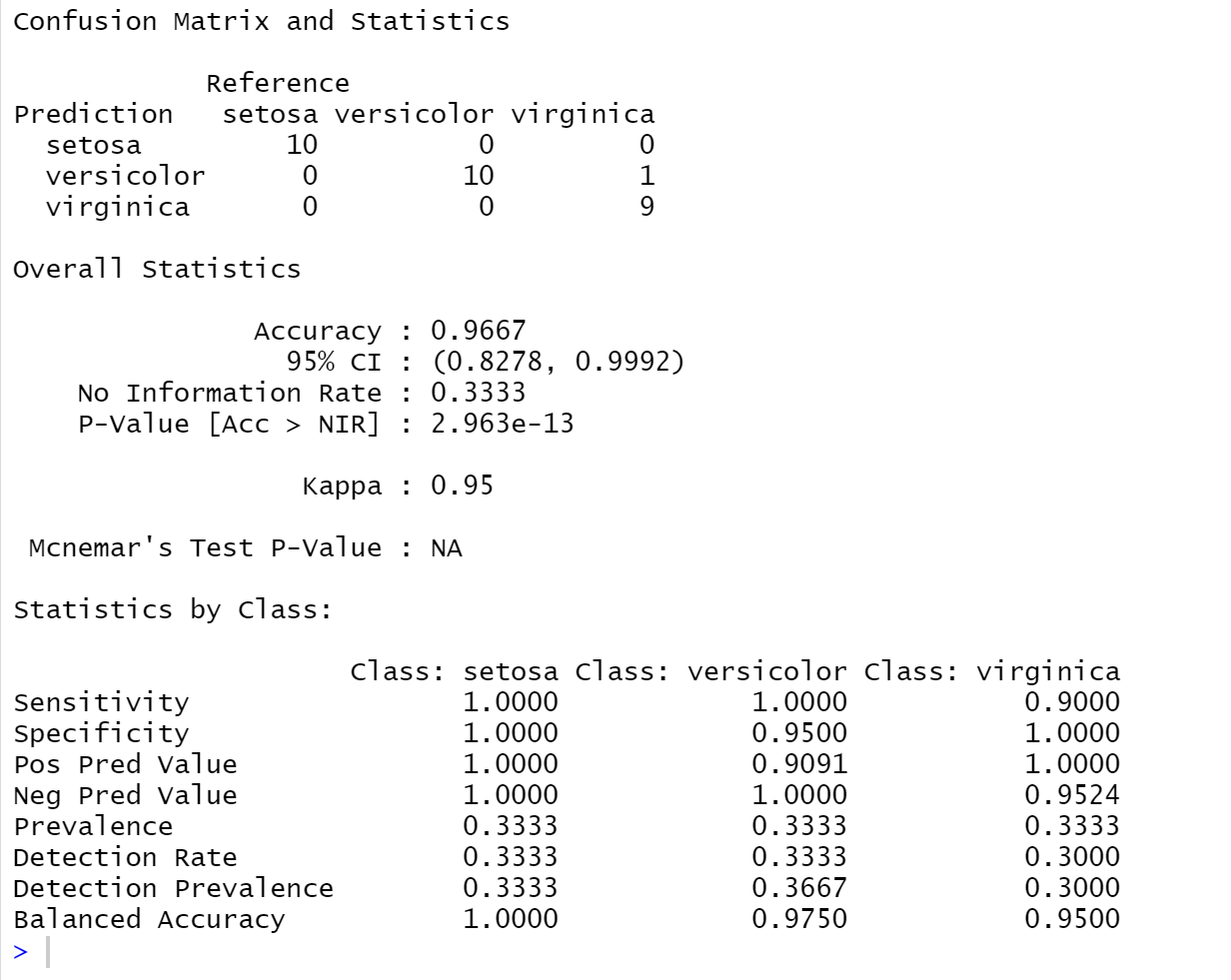
Reference
Prediction setosa versicolor virginica
setosa 10 0 0
versicolor 0 10 1
virginica 0 0 9
上方的混淆矩阵显示:第一,二个种类的预测全对,第三个错了1个,错的是把virginica预测成bersicolor
Accuracy : 0.9667 #准确率是0.9667
95% CI : (0.8278, 0.9992)
No Information Rate : 0.3333
P-Value [Acc > NIR] : 2.963e-13
Kappa : 0.95 #越接近1说明模型效果越好
Balanced Accuracy 1.0000 0.9750 0.9500
#在样本数量不均匀时要看这个
7.ROC和AUC
前面需要的是类别,所以type="class"
而ROC需要一个概率,所以type=“prob”
> rf.test2 <- predict(rf.train,newdata = testset,type = "prob")
> head(rf.test2)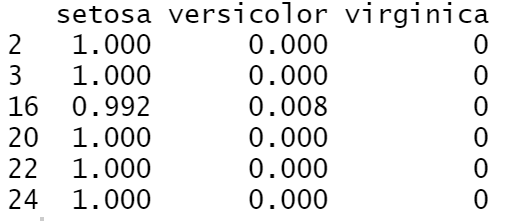
可以看到1,0.992说明很好
画ROC曲线
由于有三个变量,所以用多分类muticlass.roc(testser$Species,rf.test2)
如果只有两个变量,二分类调用roc(testset$Species, rf.test2)
> roc.rf <- multiclass.roc(testset$Species,rf.test2)
> roc.rf 
AUC值是0.995,很理想
最后
以上就是虚拟菠萝最近收集整理的关于随机森林实例(R语言实现)的全部内容,更多相关随机森林实例(R语言实现)内容请搜索靠谱客的其他文章。








发表评论 取消回复