第二章 TensorRT Workflows
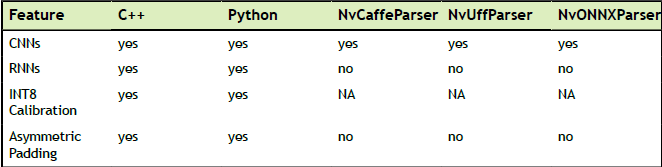
下列表格列出了TensorRT特点一支持的API以及解析器。
表2 特点与支持的API’s
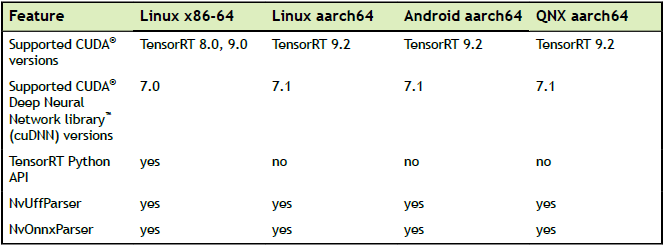
下列表格列出了TensorRT特点以及支持的平台
表3 特点与支持的平台
注:序列化引擎不能再不同TensorRT版本间与不同平台间交叉使用。
2.1 Key Concepts
请确保你知悉以下关键概念:
UFF
UFF(Universal Framework Format)是一种描述DNN执行图的数据格式。绑定执行图的是输入与输出。UFF有严格规定的语法,并且支持核心运算的扩展,与完全用户自定义的运算。
包括以下内容:
Ø 具体序列化的格式,采用protobuf格式。
Ø 各种运算的有效定义,以python描述符来表述。
Ø 每个核心运算符执行文档。
PLANfile
PLAN文件是运行引擎用于执行网络的序列化数据。包含权重,网络中执行步骤以及用来决定如何绑定输入与输出缓存的网络信息。
NEF(NetworkExchange Format)
NEF是用来交换神经网络信息的数据格式。Caffe,UFF与ONNX是各种格式网络交换格式的样例。
Parser
TensorRT中设计用来解析NEF格式数据,建立运行引擎的前端。
Execution Context
运行上下文是前向引擎运行时需要的执行环境。
Engine
Engine是ICudaEngine的实例,Engine是前向运算示例。
NetworkDefinition
网络定义是由运算或者tensor组成的计算图。再TensorRT中是INetworkDefinition类型的示例,
CaffeFormat
Caffe格式的网络参数交换格式。
ONNX
ONNX格式的网络参数交换格式。
2.2 Workflow Diagrams
图1展示了典型的部署工作流程,用户在数据集上训练模型,训练好的网络可以用来进行前向运算。
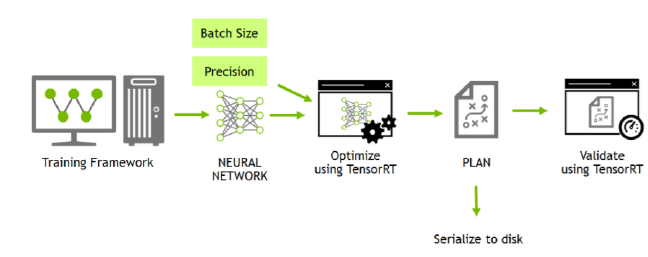
图1 典型部署工作流
图1表示将训练网络导入到TensorRT中。用户将训练好的网络导入到TensorRT中,优化网络产生PLAN。PLAN用于前向运算,例如,验证优化是否正确的进行。
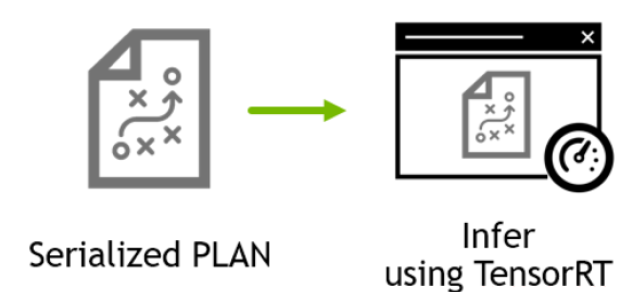
PLAN可以序列化到硬盘上以便之后TensorRT后续无需再次进行优化步骤就可以进行调用(见图2)。
图2 典型生产流程
2.3 Exporting From Frameworks
使用TensorRT的第一步是建立一个用户网络的TensorRT表达。一旦这个网络建立好了,TensorRT可以由此建立一个网络优化的运行引擎。由两种建立TensorRT网络的方式。
1、 使用Builder API从头开始建立。
2、 从现有的NVCaffe,ONNX或者TensorFlow网络模型使用ParserAPI加载(选择性的使用插件API加载部分TensorRT不支持的网络结构)。
两种方式都在下文中有介绍,以C++或者Python例程的形式展示。
有些网络模块TensorRT不支持。因此,你可以通过使用Plugin API或者修改原始网络结构,使用类似的模块替代。
2.3.1 NVCaffe Workflow
2.3.1.1 NVCaffe C++ Workflow
TensorRT可以直接加载NVCaffe的模型,通过NvCaffeParser接口。
使用NvCaffeParser的使用例程可以在SampleMNIST中找到。TensorRT网络定义结构直接从NVCaffe模型中通过NvCaffeParser库解析出来:
INetworkDefinition* network =builder->createNetwork();
CaffeParser* parser = createCaffeParser();
std::unordered_map<std::string, infer1::Tensor>blobNameToTensor;
const IBlobNameToTensor* blobNameToTensor =
parser->parse(locateFile(deployFile).c_str(),
locateFile(modelFile).c_str(),
*network,
DataType::kFLOAT);
NvCaffeParser通过指令生成32-bit float权重的网络,我们可以通过DataType::kHALF来生成16位的模型。
与主流的网络定义方式一样,解析器返回从NVCaffe blob名字映射到TensorRT tensors的maps。
注: TensorRT网络定义中没有原位操作的概念,例如ReLU的输入输出tensors是不同的。当NVCaffe网络中进行原位操作时,TensorRT的tensor返回blob中最后一次写入的内容对应的字典。例如,如果卷积层生成了一个blob,紧接着一个原位操作的ReLU,blob的名字将会映射到ReLU对应的TensorRT tensor。
由于NVCaffe模型并没有指定那个tensors时网络的输出,我们需要在解析后明确指定:
for (auto& s : outputs)
network->markOutput(*blobNameToTensor->find(s.c_str()));
对于输出tensors的个数没有限制,但是将tensor标记为输出可能会影响对tensor的一些优化操作。
注:
不要立即释放解析器实例,因为网络定义的参数是由NVCaffe模型引用过来的。只有在build过程时权重从NVCaffe模型中加载。
2.3.1.2 NVCaffe Python Workflow
TensorRT提供了Python接口,用于加载与优化NVCaffe模型,NVCaffe模型可以执行与存储与PLAN文件中。下列例子展示了实现的工作流程。例子中,你将学习如何在python中使用TensorRT来优化NVCaffe模型。
Python中TensorRT库由tensorrt表示。
你可以像加载其它任何包一样加载tensorrt。例如:、
import tensorrt as trt
有些工具会经常与python接口TensorRT同时使用,例如PyCUDA,NumPy。PyCUDA处理CUDA操作,比如在GPU上申请内显存,将数据传输到GPU上,结果回传到CPU。NumPy是存储与转移数据的常用工具。
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
本例中,我们导入一个图像处理库(以pillow库为例)与randint。
from random import randint
from PIL import Image
由于我们需要转换NVCaffe模型,我们还需要使用位于tensorrt.parsers的caffeparser。
from tensorrt.parsers import caffeparser
通常,第一件事是建立一个日志模块,在模型转换与前向运算时许多地方都会使用。在tensorrt.infer.ConsolueLogger里有个简单的日志模块。
G_LOGGER = trt.infer.ConsoleLogger(trt.infer.LogSeverity.ERROR)
第二步,定义一些你模型相关的常量。本例中,我们利用DIGITS训练MNIST数据集的模型。
INPUT_LAYERS = ['data']
OUTPUT_LAYERS = ['prob']
INPUT_H = 28
INPUT_W = 28
OUTPUT_SIZE = 10
此外,定义一些路径。将下列路径映射到例子中你放数据的位置。
MODEL_PROTOTXT = '/data/mnist/mnist.prototxt'
CAFFE_MODEL = '/data/mnist/mnist.caffemodel'
DATA = '/data/mnist/'
IMAGE_MEAN = '/data/mnist/mnist_mean.binaryproto'
这一步开始建立引擎。TensorRT的python接口提供了一些实用工具是的这一步变得十分简单。我们使用tensorrt.utils中NVCaffe模型转换工具。我们提供一个日志模块,模型prototxt路径,模型路径,最大batchsize,最大workspace大小,输出层与权重的数据类型。
engine = tensorrt.utils.caffe_to_trt_engine(G_LOGGER,
MODEL_PROTOTXT,
CAFFE_MODEL,
1,
1 << 20,
OUTPUT_LAYERS,
trt.infer.DataType.FLOAT)
下一步,对输入图片进行均值处理。我们使用caffeparser读取.binaryproto文件。
parser = caffeparser.create_caffe_parser()
mean_blob = parser.parse_binary_proto(IMAGE_MEAN)
parser.destroy()
mean = mean_blob.get_data(INPUT_W ** 2) #NOTE: This is different than theC++
API, you must provide the size of the data
data = np.empty([INPUT_W ** 2])
for i in range(INPUT_W ** 2):
data[i] = float(img[i]) - mean[i]
mean_blob.destroy()
建立一个前向运算的运行环境,创建一个引擎的运行上下文。
runtime = trt.infer.create_infer_runtime(G_LOGGER)
context = engine.create_execution_context()
运行前向运算。第一步确认数据类型是否正确(本例中是FP32)。第二步,创建一个CPU下的array空间,存储前向运算的结果。
assert(engine.get_nb_bindings() == 2)
#convert input data to Float32
img = img.astype(np.float32)
#create output array to receive data
output = np.empty(OUTPUT_SIZE, dtype = np.float32)
第三步,使用PyCUDA申请GPU显存并在引擎中注册。申请的大小是整个batchsize大小的输入以及期望的输出指针大小。
d_input = cuda.mem_alloc(1 * img.size * img.dtype.itemsize)
d_output = cuda.mem_alloc(1 * output.size * output.dtype.itemsize)
引擎需要绑定GPU显存的指针。PyCUDA通过分配成ints实现内存申请。
bindings = [int(d_input), int(d_output)]
我们还需要建立一个CUDAstream前向运算。
stream = cuda.Stream()
下一步,将数据传输到GPU上,运行前向运算,复制结果回掉。
#transfer input data to device
cuda.memcpy_htod_async(d_input, img, stream)
#execute model
context.enqueue(1, bindings, stream.handle, None)
#transfer predictions back
cuda.memcpy_dtoh_async(output, d_output, stream)
#synchronize threads
stream.synchronize()
现在我们以及得到结果了,我们可以运行ArgMax得到最终预测的结果。
print("Test Case: " + str(rand_file))
print ("Prediction: " + str(np.argmax(output)))
我们也可以将我们的引擎存在文件中以备之后调用。
trt.utils.write_engine_to_file("/data/mnist/new_mnist.engine",
engine.serialize())
我们可以之后将通过以下命令将引擎加载运行。
new_engine =
trt.utils.load_engine(G_LOGGER,
"/data/mnist/new_mnist.engine")
最后一步,清理context,engine与runtime:
context.destroy()
engine.destroy()
new_engine.destroy()
runtime.destroy()
2.3.1.3 NvCaffeParser
尽管TensorRT独立于任何其它框架,TensorRT还是包含一个NVCaffe模型的解析器,叫做NvCaffeParser。
NvCaffeParser提供了一种简单的加载网络定义的机制。NvCaffeParser使用TensorRT层实现NVCaffe中的层。例如:
Ø Convolution
Ø Rectified Linear Unit(ReLU)
Ø Sigmoid
Ø Hyperbolic Tangent(tanh)
Ø Pooling
Ø Power
Ø BatchNorm
Ø ElementEise(Eltwise)
Ø Local Response Normalization(LRN)
Ø InnerProduct(在NVCaffe中称为FullyConnected层)
Ø SoftMax
Ø Scale
Ø Deconvolution
Ø Reduction
TensorRT中不支持的NVCaffe功能包括:
Ø Parammetric Rectified Linear Unit(PReLU)
Ø Leaky Rectified Linear Unit(Leaky ReLU)
Ø Scale(除了per-channel scaling)
Ø 多于两个输入的ElementWise(Eltwise)
注:
NvCaffeParser不支持原版NVCaffe的prototxt格式。特别注意的是,prototxt中层的类型需要由双引号括起来。
2.3.2 ONNX Workflow
TensorRT可以直接通过NvParser接口导入ONNX格式模型。解析器接口可以使用C++与Python代码。
2.3.2.1 ONNX C++ Workflow
在sampleONNXMNIST中,TensorRT网络定义结构利用ONNX解析器直接从ONNX模型中读取,在libnvparsers库中定义。ONNX解析器使用辅助参数管理器SampleConfig实例来将输入参数传到执行程序中来解析,例如:
//Create ONNX ParserConfiguration Object
nvonnxparser::IOnnxConfig*config = nvonnxparser::createONNXConfig();
//Copy relevant infofrom the Sample Config to ONNX Parser Config
sampleONNX::copyConfig(&apex,config);
//Create Parser
nvonnxparser::IONNXParser*parser = nvonnxparser::createONNXParser(*config);
//ONNX ParserIncludes a Logger object, it can be used for the sample
nvinfer1::ILogger*gLogger = parser->getLogger();
const char*onnx_filename = apex.getModelFileName();
constnvinfer1::DataType dataType = apex.getModelDtype();
//Parse the ONNXModel. The parser creates the equivalent TRT Network
if(!parser->parse(onnx_filename, dataType)) {
stringmsg("failed to parse onnx file");
gLogger->log(nvinfer1::ILogger::Severity::kERROR,msg.c_str());
exit(EXIT_FAILURE);
}
if(!parser->convertToTRTNetwork()) {
stringmsg("ERROR, failed to convert onnx network into TRT network");
gLogger->log(nvinfer1::ILogger::Severity::kERROR,msg.c_str());
exit(EXIT_FAILURE);
}
nvinfer1::INetworkDefinition*trtNetwork = parser->getTRTNetwork();
这里,如果trtNetwork是非空的,那么你成功的创建了trtNetwork。
下一步,我们建立一个engine builder:
nvinfer1::IBuildertrt_builder =
samples_common::infer_object(nvinfer1::createInferBuilder((*gLogger)));
给builder指定合适的参数:
trt_builder->setMaxBatchSize(apex.getMaxBatchSize());
trt_builder->setMaxWorkspaceSize(apex.getMaxWorkSpaceSize());
ONNX parser生成网络的默认权重精度是32比特的浮点型。此外你还可以通过指令生成一个16位权重的模型。
if(apex.getModelDtype() == nvinfer1::DataType::kHALF) {
trt_builder->setHalf2Mode(true);
}
当前INT8精度还不支持,也可以尝试使用以下方法:
if(apex.getModelDtype() == nvinfer1::DataType::kINT8)
{
stringmsg("Int8 mode not yet supported");
gLogger->log(nvinfer1::ILogger::Severity::kERROR,msg.c_str());
exit(EXIT_FAILURE);
}
nvinfer1::ICudaEngine*trt_engine = trt_builder->buildCudaEngine(*trtNetwork);
其它的使用方法与NVCaffe或者UFF一致。
2.3.2.2 ONNX Python Workflow
用户可以直接使用OnnxParser与Python接口来加载ONNX模型。你可以像加载其它任何包一样加载tensorrt包。例如:
Import tensorrt astrt
加载ONNXParser直接将ONNX模型转换成TensorRT网络。与C++接口类似,sample_onnx的Python例子中使用config实例将用户参数传入解析器实例。
fromtensorrt.parsers import onnxparser
apex =onnxparser.create_onnxconfig()
本例中,我们将解析一个训练好的图像分类模型,生成用于前向运算TensorRT engine。
这里我们通过解析用户输入参数来生成config实例:
apex.set_model_filename(“model_file_path”)
apex.set_model_dtype(trt.infer.DataType.FLOAT)
apex.set_print_layer_info(True)// Optional debug option
apex.report_parsing_info()// Optional debug option
为了控制debug的输出,有许多种控制冗余信息的方式,例如:
apex.add_verbosity()
apex.reduce_verbosity()
或者,你可以指定调试信息等级,例如:
apex.set_verbosity_level(3)
在config实例创建并且配置完成后,用户可以创建一个parser。此外,确保你从创建好的实例中可以检索出参数来解析输入的模型文件:
trt_parser =onnxparser.create_onnxparser(apex)
data_type =apex.get_model_dtype()
onnx_filename =apex.get_model_file_name()
解析模型后生成TensorRT网络结构,例如:
trt_parser.parse(onnx_filename,data_type)
// retrieve thenetwork from the parser
trt_parser.convert_to_trtnetwork()
trt_network =trt_parsr.get_trt_network()
// create builderand engine
trt_builder =trt.infer.create_infer_builder(G_LOGGER)
下一步,依据数据类型,设置合适的模式。当前,INT8模式不支持。
If(apex.get_model_dtype() == trt.infer.DataType_kHALF):
trt_builder.set_half_2mode(True)
elif
(apex.get_model_dtype()== trt.infer.DataType_kINT8):
msg = "Int8Model not supported"
G_LOGGER.log(trt.infer.Logger.Severity_kERROR,msg)
trt_engine =trt_builder.build_cuda_engine(trt_network)
其他的前向步骤与NVCaffe与UFFpython例子一致。
最后一步,清理parser,runtime,engine与builder,如下:
trt_parser.destroy()
trt_network.destroy()
trt_context.destroy()
trt_engine.destroy()
trt_builder.destroy()
2.3.3 TensorFlow Workflow
2.3.3.1 TensorFlow Python Workflow
TensorRT3.0引入了UFF(Universal Framework Format)解析器,可以载入UFF模型,并生成TensorRTengines。TensorRT中集成了UFF工具支持将TensorFlow模型转为UFF格式,因此,使得TensorFlow用户可以使用TensorRT来改善效率。本例中,你将学习如何使用使用TensorRT的Python接口将TensorFlow模型转成TensorRT格式。
使用TensorRT的Python接口,用户可以同一个python程序中完成TensorFlow训练与TensorRT部署。本例中,我们将在利用手写数据训练分类模型并生成TensorRT前向运算引擎。
在Python中,TensorRT库被称为tensorrt。
加载TensorFlow与其它相关库:
import tensorflow astf
fromtensorflow.examples.tutorials.mnist import input_data
同样有一些公用库与TensorRT的python接口一起使用,典型的有,例如,PyCUDA与NumPy。PyCUDA 处理CUDA相关操作,例如在GPU上申请显存,将输出传到GPU上,将结构传回CPU。NumPy广泛用于存储于传递数据。
import pycuda.driveras cuda
importpycuda.autoinit
import numpy as np
from random importrandint # generate a random test case
from PIL importImage
import time #importsystem tools
import os
最后,加载UFF工具,将TensorFlow中一系列frozen的图转为UFF格式。
import uff
用户可以通过以下命令导入TensorRT以及相关解析器:
import tensorrt astrt
fromtensorrt.parsers import uffparser
十分重要的一点是,确认UFF的版本符合TensorRT中要求的版本。TensorRT包中提供了接口来确认环境:
trt.utils.get_uff_version()
parser =uffparser.create_uff_parser()
defget_uff_required_version(parser):
returnstr(parser.get_uff_required_version_major()) + '.'
+str(parser.get_uff_required_version_minor()) + '.' +
str(parser.get_uff_required_version_patch())
iftrt.utils.get_uff_version() != get_uff_required_version(parser):
raiseImportError("""ERROR: UFF TRT Required versionmismatch""")
2.3.3.1.1 Training A Model In TensorFlow
本例中第一步定义一些超参数,之后定义一些帮助函数,使得代码简介。
STARTER_LEARNING_RATE= 1e-4
BATCH_SIZE = 10
NUM_CLASSES = 10
MAX_STEPS = 5000
IMAGE_SIZE = 28
IMAGE_PIXELS =IMAGE_SIZE ** 2
OUTPUT_NAMES =["fc2/Relu"]
注意我们padding我们的Conv2d层,TensorRT期望对称的padding层。
def WeightsVariable(shape):
returntf.Variable(tf.truncated_normal(shape, stddev=0.1, name='weights'))
defBiasVariable(shape):
returntf.Variable(tf.constant(0.1, shape=shape, name='biases'))
def Conv2d(x, W, b,strides=1):
# Conv2D wrapper,with bias and relu activation
filter_size =W.get_shape().as_list()
pad_size =filter_size[0]//2
pad_mat =np.array([[0,0],
[pad_size,pad_size],
[pad_size,pad_size],
[0,0]])
x = tf.pad(x,pad_mat)
x = tf.nn.conv2d(x,
W,
strides=[1, strides,strides, 1],
padding='VALID')
x =tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def MaxPool2x2(x,k=2):
# MaxPool2D wrapper
pad_size = k//2
pad_mat =np.array([[0,0],
[pad_size,pad_size],
[pad_size,pad_size],
[0,0]])
returntf.nn.max_pool(x,
ksize=[1, k, k, 1],
strides=[1, k, k,1],
padding='VALID')
这一步我们将定义网络结构,并且定义我们的loss方法,训练与测试的steps,输入节点,与数据加载器:
def network(images):
# Convolution 1
withtf.name_scope('conv1'):
weights =WeightsVariable([5,5,1,32])
biases =BiasVariable([32])
conv1 =tf.nn.relu(Conv2d(images, weights, biases))
pool1 =MaxPool2x2(conv1)
# Convolution 2
withtf.name_scope('conv2'):
weights =WeightsVariable([5,5,32,64])
biases =BiasVariable([64])
conv2 =tf.nn.relu(Conv2d(pool1, weights, biases))
pool2 =MaxPool2x2(conv2)
pool2_flat =tf.reshape(pool2, [-1, 7 * 7 * 64])
Fully Connected 1
withtf.name_scope('fc1'):
weights =WeightsVariable([7 * 7 * 64, 1024])
biases =BiasVariable([1024])
fc1 =tf.nn.relu(tf.matmul(pool2_flat, weights) + biases)
# Fully Connected 2
withtf.name_scope('fc2'):
weights =WeightsVariable([1024, 10])
biases =BiasVariable([10])
fc2 =tf.reshape(tf.matmul(fc1,weights) + biases, shape= [-1,10] ,
name='Relu')
return fc2
defloss_metrics(logits, labels):
cross_entropy =tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels,
logits=logits,
name='softmax')
returntf.reduce_mean(cross_entropy, name='softmax_mean')
def training(loss):
tf.summary.scalar('loss',loss)
global_step =tf.Variable(0, name='global_step', trainable=False)
learning_rate =tf.train.exponential_decay(STARTER_LEARNING_RATE,
global_step,
100000,
0.75,
staircase=True)
tf.summary.scalar('learning_rate',learning_rate)
optimizer =tf.train.MomentumOptimizer(learning_rate, 0.9)
train_op =optimizer.minimize(loss, global_step=global_step)
return train_op
defevaluation(logits, labels):
correct =tf.nn.in_top_k(logits, labels, 1)
returntf.reduce_sum(tf.cast(correct, tf.int32))
def do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_set,
summary):
true_count = 0
steps_per_epoch =data_set.num_examples // BATCH_SIZE
num_examples =steps_per_epoch * BATCH_SIZE
for step inrange(steps_per_epoch):
feed_dict =fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
log, correctness =sess.run([summary, eval_correct],
feed_dict=feed_dict)
true_count +=correctness
precision =float(true_count) / num_examples
tf.summary.scalar('precision',tf.constant(precision))
print('Num examples%d, Num Correct: %d Precision @ 1: %0.04f' %
(num_examples,true_count, precision))
return log
defplaceholder_inputs(batch_size):
images_placeholder =tf.placeholder(tf.float32,
shape=(None, 28, 28,1))
labels_placeholder =tf.placeholder(tf.int32, shape=(None))
returnimages_placeholder, labels_placeholder
deffill_feed_dict(data_set, images_pl, labels_pl):
images_feed,labels_feed = data_set.next_batch(BATCH_SIZE)
feed_dict = {
images_pl:np.reshape(images_feed, (-1,28,28,1)),
labels_pl:labels_feed,
}
return feed_dict
这一步我们将在函数中定义我们的训练流水线,使得训练完毕后输出frozen的模型,并删除训练nodes:
defrun_training(data_sets):
withtf.Graph().as_default():
images_placeholder,labels_placeholder = placeholder_inputs(BATCH_SIZE)
logits =network(images_placeholder)
loss =loss_metrics(logits, labels_placeholder)
train_op =training(loss)
eval_correct = evaluation(logits,labels_placeholder)
summary =tf.summary.merge_all()
init =tf.global_variables_initializer()
saver =tf.train.Saver()
gpu_options =tf.GPUOptions(
per_process_gpu_memory_fraction=0.5)
sess = tf.Session(
config=tf.ConfigProto(gpu_options=gpu_options))
summary_writer =tf.summary.FileWriter(
"/tmp/tensorflow/mnist/log",
graph=tf.get_default_graph())
test_writer =tf.summary.FileWriter(
"/tmp/tensorflow/mnist/log/validation",
graph=tf.get_default_graph())
sess.run(init)
for step inrange(MAX_STEPS):
start_time =time.time()
feed_dict =fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value =sess.run([train_op, loss],
feed_dict=feed_dict)
duration =time.time() - start_time
if step % 100 == 0:
print('Step %d: loss= %.2f (%.3f sec)' %
(step, loss_value,duration))
summary_str =sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str,step)
summary_writer.flush()
if (step + 1) % 1000== 0 or (step + 1) == MAX_STEPS:
Checkpoint_file =os.path.join(
"/tmp/tensorflow/mnist/log",
"model.ckpt")
saver.save(sess,checkpoint_file, global_step=step)
print('ValidationData Eval:')
log = do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation,
summary)
test_writer.add_summary(log,step)
graphdef =tf.get_default_graph().as_graph_def()
frozen_graph =tf.graph_util.convert_variables_to_constants(sess,
graphdef,OUTPUT_NAMES)
returntf.graph_util.remove_training_nodes(frozen_graph)
这一步骤中我们加载TensorFlow的MNIST数据加载器,并进行训练。生成的模型放在了一起,使得用户恶意通过TensorBoard监视训练。
MNIST_DATASETS =input_data.read_data_sets(
'/tmp/tensorflow/mnist/input_data')
tf_model =run_training(MNIST_DATASETS)
2.3.3.1.2 Converting A TensorFlow Model To UFF
本实例中,我们用uff.from_tensorflow中的UFF工具与帮助函数将TensorFlow模型转为序列化的UFF模型。为了进行模型转换,我们至少需要提供model stream与需要输出的节点名称。UFF工具还包含uff.from_tensorFlow_frozen_model函数来加载TensorFlowprotobuf文件路径。
两种工具,例如uff.from_tensorflow(serialized graph)与uff.from_tensorflow_frozen_model (protobuf file)都包含以下选项:
quiet
抑制转换日志
Input_node
在图中定义一系列输入节点。默认是placeholder节点。
text
使得用户可以在除二进制UFF文件外生成一个可读版本的UFF模型。
List_nodes
图中节点的列表。
Output_filename
如果设置了此参数,模型将输出到指定路径,而不是一系列模型。
为了将模型转为UFF格式,使用以下命令:
uff_model =uff.from_tensorflow(tf_model, ["fc2/Relu"])
2.3.3.1.3 Import A UFF Model Into TensorRT
我们现在有了一个UFF模型,我们可以通过生成一个TensorRT的logger来生成TensorRTengine。
G_LOGGER =trt.infer.ConsoleLogger(trt.infer.LogSeverity.ERROR)
创建一个UFF解析器,定义期望的输入与输出节点。
parser =uffparser.create_uff_parser()
parser.register_input("Placeholder",(1,28,28),0)
parser.register_output("fc2/Relu")
通过logger,parser,UFF模型stream,以及其他一些设置(最大batchsize与最大workspace大小),最终创建engine。
engine =trt.utils.uff_to_trt_engine(G_LOGGER,
uff_model,
parser,
1,
1 << 20)
激活engine时在CPU上申请一些内存:
host_mem =parser.hidden_plugin_memory()
销毁解析器:
parser.destroy()
利用TensorFlow数据加载器(将数据转为FP32)建立一个测试实例:
img, label =MNIST_DATASETS.test.next_batch(1)
img = img[0]
#convert input datato Float32
img =input_img.astype(np.float32)
label = label[0]
创建一个engine的运行环境与执行上下文:
runtime =trt.infer.create_infer_runtime(G_LOGGER)
context =engine.create_execution_context()
下一步,GPU上申请显存,申请CPU内存来存放前向运算后的结果。存储空间的大小是batchsize的输入与期望输出指针大小。
output =np.empty(10, dtype = np.float32)
#allocate devicememory
d_input =cuda.mem_alloc(1 * img.size * img.dtype.itemsize)
d_output =cuda.mem_alloc(1 * output.size * output.dtype.itemsize)
engine需要绑定GPU显存的指针,PyCUDA通过将那些内存转为ints来申请内存空间。
bindings =[int(d_input), int(d_output)]
创建一个CUDAstream来运行推理运算。
stream =cuda.Stream()
将数据传输到GPU,运行推理运算,并取回结果。
#transfer input datato device
cuda.memcpy_htod_async(d_input,img, stream)
#execute model
context.enqueue(1,bindings, stream.handle, None)
#transferpredictions back
cuda.memcpy_dtoh_async(output,d_output, stream)
#synchronize threads
stream.synchronize()
现在我们有运行结果了,运行ArgMax取得预测结果:
print("TestCase: " + str(label))
print("Prediction: " + str(np.argmax(output)))
用户还可以将engine存到文件中以备后用。
trt.utils.write_engine_to_file("/data/mnist/tf_mnist.engine",
engine.serialize())
用户可以随后通过tensorrt.utils.load_engine来使用engine。
new_engine =trt.utils.load_engine(G_LOGGER, "/data/mnist/new_mnist.engine")
最后一步后,清理context,engine与runtime。
context.destroy()
engine.destroy()
new_engine.destroy()
runtime.destroy()
2.3.3.2 Exporting TensorFlow To A UFF File
TensorRT有UFF解析器来加载.uff文件,创建推理引擎。因此,为了转换TensorFlow模型到TensorRT可以运行的文件,必须用convert-to-uff工具将TensorFlow代码freeze为.pb文件,并转换成.uff格式。Convert-to-uff工具包含在uff.whl文件中,作为TensorRT安装包的一部分。
尽管网络可以使用NHWC与NCHW格式,还是鼓励TensorFlow用户使用NCHW数据格式用于达到最佳的性能。
1. 对于TensorFlow或者Keras(TensorFlow作为后端),将图freeze生成.pb(protobuf)文件。请参考SampleCode 1: Freezing the Graph from TensorFlow to .pb 与Sample Code2: Freezing Keras Code to .pb得到更多使用信息。
2. 使用convert-to-uff.py工具,将.pb格式的图转换成.uff格式文件。请参考Sample Code 3: Running convert_to_uff.py得到跟多代码与使用信息。
2.3.3.2.1 Freezing The Graph From TensorFlow
TensorFlow提供freeze_graph函数,使用方式可在freeze_graph_test.py文件中查看。为了使用这种方法,图必须使用graph.io.write_graph保存为.pb文件。其次,freeze_graph可以调用来转换变量为const ops来阐述一个新的frozen.pb文件。更多的freeze_graph信息可以在以下链接找到。
2.3.3.2.2 Sample Code 1:Freezing Keras Code To .pb
转换Keras模型,使用以下代码:
from keras.modelsimport load_model
import keras.backendas K
fromtensorflow.python.framework import graph_io
fromtensorflow.python.tools import freeze_graph
fromtensorflow.core.protobuf import saver_pb2
fromtensorflow.python.training import saver as saver_lib
defconvert_keras_to_pb(keras_model, out_names, models_dir,
model_filename):
model =load_model(keras_model)
K.set_learning_phase(0)
sess =K.get_session()
saver =saver_lib.Saver(write_version=saver_pb2.SaverDef.V2)
checkpoint_path =saver.save(sess, 'saved_ckpt', global_step=0,
latest_filename='checkpoint_state')
graph_io.write_graph(sess.graph,'.', 'tmp.pb')
freeze_graph.freeze_graph('./tmp.pb','',
False,checkpoint_path, out_names,
"save/restore_all","save/Const:0",
models_dir+model_filename,False, "")
2.3.3.2.3 Sample Code 2:Running convert-to-uff
为了将.pb的frozen graph转成.uff格式文件,见下列例程代码:
convert-to-ufftensorflow -o name_of_output_uff_file --inputfile
name_of_input_pb_file-O name_of_output_tensor
为了确定name_of_output_tensor,用户可以列出TensorFlow层:
convert-to-ufftensorflow --input-file name_of_input_pb_file -l
2.3.3.2.4 Supported TensorFlow Operations
当前输出支持TensorFlow以下原生层:
Ø placeholder转换成UFF输入层
Ø Const转成UFF的Const层
Ø Add,Sub,Mul,Div,Minimun与Maximum转成UFF二进制层
Ø BiasAdd转成UFF二进制层
Ø Negative,Abs,Sqrt,Rsqrt,Pow,Exp与Log转成UFF的Unary层
Ø FusedBatchNorm转换成UFF BatchNorm层
Ø Tanh,Relu,Sigmoid转换成UFF Activation层
Ø SoftMax转换成SoftMax层
Ø Mean转换成UFF Reduce层
Ø ConcatV2转换成UFFConcat层
Ø Reshape转换成UFFReshape层
Ø Transpose层转换成UFF Transpose层
Ø Conv2D与DepthwiseConv2dNative转换成UFF Conv层
Ø ConvTranspose2D转换成UFFConvTranspose层
Ø MaxPool与AvePool转换成UFF Pooling层
Ø 如果Pad是接在以下TensorFlow层后面则可以使用,Conv2D,DepthwiseConv2dNative,MaxPool与AvgPool
2.3.3.3 NvUffParser
关于如何将UFF文件导入到TensorRT中,见例子SampleUffMNISTUFF
Usage。
2.3.4 Converting A Model From An Unsupported Framework ToTensorRT With The TensorRT Python API
随着UFF版本的发布,将兼容框架的模型转换为TensorRT引擎变得十分容易。然而,也有些框架当前或者后续不会支持UFF加载器。TensorRT的Python接口提供了一种前向算法的方式,使得基于Python的框架可以使用NumPy兼容层参数。
以PyTorch为例,我们将展示如何训练一个模型,并且手动将模型转换为TensorRT的engine。
在Python中TensorRT库表示为tenssort。
同样有些工具配合TensorRT的Python接口,典型的工具,例如PyCUDA与NumPy。PyCUDA负责处理CUDA操作,用于GPU显存申请,将数据传送到GPU上,结构回传CPU上。NumPy是一种通用的数据转存工具。
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
载入PyTorch以及相关包:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
用户可以像使用其他包一样载入tensorrt。例如:
import tensorrt as trt
2.3.4.1 Training A Model In PyTorch
本例中,通过设置一些超参数,创建一个数据加载器,定义你的网络结构,设置优化方式,定义训练与测试的steps。
BATCH_SIZE = 64
TEST_BATCH_SIZE = 1000
EPOCHS = 3
LEARNING_RATE = 0.001
SGD_MOMENTUM = 0.5
SEED = 1
LOG_INTERVAL = 10 #Enable Cuda
torch.cuda.manual_seed(SEED) #Dataloader
kwargs = {'num_workers': 1, 'pin_memory': True}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('/tmp/mnist/data', train=True,download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE,
shuffle=True,
**kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('/tmp/mnist/data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=TEST_BATCH_SIZE,
shuffle=True,
**kwargs) #Network
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, kernel_size=5)
self.conv2 = nn.Conv2d(20, 50, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(800, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), kernel_size=2,stride=2)
x = F.max_pool2d(self.conv2(x), kernel_size=2,stride=2)
x = x.view(-1, 800)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x)
model = Net()
model.cuda() optimizer = optim.SGD(model.parameters(),
lr=LEARNING_RATE,
momentum=SGD_MOMENTUM)
def train(epoch):
model.train()
for batch, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch % LOG_INTERVAL == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]tLoss:{:.6f}'
.format(epoch,
batch * len(data),
len(train_loader.dataset),
100. * batch / len(train_loader),
loss.data[0]))
def test(epoch):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True),Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).data[0]
pred = output.data.max(1)[1]
correct += pred.eq(target.data).cpu().sum()
test_loss /= len(test_loader)
print('Test: Average loss: {:.4f}, Accuracy: {}/{}({:.0f}%)n'
.format(test_loss,
correct,
len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
下一步,训练模型
for e in range(EPOCHS):
train(e + 1)
test(e + 1)
2.3.4.2 Converting The Model Into A TensorRT Engine
我们现在有训练好的模型了,我们需要利用state_dict提取层参数作为模型转换的第一步。
weights = model.state_dict()
为了将模型转成TensorRT使用,首先,建立一个builder与一个logger。
G_LOGGER =trt.infer.ConsoleLogger(trt.infer.LogSeverity.ERROR)
builder = trt.infer.create_infer_builder(G_LOGGER)
下一步,通过复制上述网络结构,并且从PyTorch模型中提取NumPy格式存储的权重。PyTorch中的NumPy矩阵展示了层的维度,然而我们对参数进行flatten操作。
注:TensorRT权重的格式是NCHW,因此,如果你的框架使用的是其他格式,你肯定需要在flatten前进行一些预处理。
network = builder.create_network()
#Name for the input layer, data type, tuple fordimension
data = network.add_input("data",
trt.infer.DataType.FLOAT,
(1, 28, 28))
assert(data)
#-------------
conv1_w =weights['conv1.weight'].cpu().numpy().reshape(-1)
conv1_b =weights['conv1.bias'].cpu().numpy().reshape(-1)
conv1 = network.add_convolution(data, 20, (5,5),conv1_w, conv1_b)
assert(conv1)
conv1.set_stride((1,1))
#-------------
pool1 = network.add_pooling(conv1.get_output(0),
trt.infer.PoolingType.MAX,
(2,2))
assert(pool1)
pool1.set_stride((2,2))
#-------------
conv2_w =weights['conv2.weight'].cpu().numpy().reshape(-1)
conv2_b =weights['conv2.bias'].cpu().numpy().reshape(-1)
conv2 = network.add_convolution(pool1.get_output(0),50, (5,5), conv2_w,
conv2_b)
assert(conv2)
conv2.set_stride((1,1))
#-------------
pool2 = network.add_pooling(conv2.get_output(0),trt.infer.PoolingType.MAX,
(2,2))
assert(pool2)
pool2.set_stride((2,2))
#-------------
fc1_w = weights['fc1.weight'].cpu().numpy().reshape(-1)
fc1_b = weights['fc1.bias'].cpu().numpy().reshape(-1)
fc1 = network.add_fully_connected(pool2.get_output(0),500, fc1_w, fc1_b)
assert(fc1)
#-------------
relu1 = network.add_activation(fc1.get_output(0),trt.infer.ActivationType.RELU)
assert(relu1)
#-------------
fc2_w =weights['fc2.weight'].cpu().numpy().reshape(-1)
fc2_b = weights['fc2.bias'].cpu().numpy().reshape(-1)
fc2 = network.add_fully_connected(relu1.get_output(0),10, fc2_w, fc2_b)
assert(fc2)
标记处输出层。
fc2.get_output(0).set_name("prob")
network.mark_output(fc2.get_output(0))
创建一个算法引擎并且利用torch的数据加载器创建一个测试实例。
runtime = trt.infer.create_infer_runtime(G_LOGGER)
img, target = next(iter(test_loader))
img = img.numpy()[0]
target = target.numpy()[0]
print("Test Case: " + str(target))
img = img.ravel()
为算法引擎创建一个运行上下文。
context = engine.create_execution_context()
在GPU上申请显存,在CPU上申请用来存储推理运算结果的内存。申请的大小是batchsize大小的输入与输出指针的大小。
output = np.empty(10, dtype = np.float32)
#allocate device memory
d_input = cuda.mem_alloc(1 * img.size *img.dtype.itemsize)
d_output = cuda.mem_alloc(1 * output.size *output.dtype.itemsize)
engine需要绑定GPU的显存。PyCUDA使得用户可以通过ints的方式进行内存申请。
bindings = [int(d_input), int(d_output)]
将数据传送到GPU上,运行推理,将结果传回。
#transfer input data to device
cuda.memcpy_htod_async(d_input, img, stream)
#execute model
context.enqueue(1, bindings, stream.handle, None)
#transfer predictions back
cuda.memcpy_dtoh_async(output, d_output, stream)
#synchronize threads
stream.synchronize()
现在我们得到了处理的结果,进行ArgMax就可以得到预测结果。
print("Test Case: " + str(target))
print ("Prediction: " +str(np.argmax(output)))
也可以将engine保存为文件以备后用。
trt.utils.write_engine_to_file("/data/mnist/pyt_mnist.engine",
engine.serialize())
后续可以使用tensorrt.util.load_engine来加载engine。
new_engine = trt.utils.load_engine(G_LOGGER,
"/data/mnist/new_mnist.engine")
最后,清理context,engine与runtime。
context.destroy()
engine.destroy()
new_engine.destroy()
runtime.destroy()
2.4 Build Phase
在build阶段,TensorRT载入网络定义,进行性能优化并生成推理引擎。
build阶段会消耗较多的时间,特别是在嵌入式平台上。因此,一般应用的时候会build意思engine,之后以serialize的方式使用。
build阶段在层图上进行了一下优化:
Ø 消除层输出没有被使用的层
Ø 融合卷积、偏置与非线性映射操作
Ø 将使用类似参数运算与相同源tensor(例如googleNetv5的inception模块中的1乘1卷积)进行聚合。
Ø 通过将层输出直接输出到正确的最终位置进行串联层合并
此外,build阶段还在虚拟数据上运行层以选择最快的核类型,进行权重的预格式化与适当的内存优化。
2.5 Execution Phase
在execution阶段,进行以下任务:
Ø 运行时库执行优化过的engine
Ø engine使用GPU输入与输出buffer运行推理任务
2.6 Command Line Wrapper
在samples目录下包含TensorRT的command linewrapper,称为giexec。可以用来作为网络在随机数据集上的benchmark,用于产生模型对应的系列engines。
命令行的参数如下:
Mandatory params:
--deploy=<file> Caffe deploy file
--output=<name> Output blob name (can bespecified
multiple times)
Optional params:
--model=<file> Caffe model file (default = nomodel,
random weights
used)
--batch=N Set batch size (default = 1)
--device=N Set cuda device to N (default = 0)
--iterations=N Run N iterations (default = 10)
--avgRuns=N Set avgRuns to N - perf is measured as an
average of
avgRuns (default=10)
--workspace=N Set workspace size in megabytes (default=
16)
--half2 Run in paired fp16 mode (default = false)
--int8 Run in int8 mode (default = false)
--verbose Use verbose logging (default = false)
--hostTime Measure host time rather than GPU time
(default =
false)
--engine=<file> Generate a serialized GIE engine
--calib=<file> Read INT8 calibration cache file
例如:
giexec --deploy=mnist.prototxt--model=mnist.caffemodel --
output=prob
如果没有提供模型,会使用随机权值。
最后
以上就是追寻含羞草最近收集整理的关于TensorRT4.0开发手册(2)第二章 TensorRT Workflows的全部内容,更多相关TensorRT4.0开发手册(2)第二章内容请搜索靠谱客的其他文章。








发表评论 取消回复