前言
关于PointNet模型的构成、原理、效果等等论文部分内容,我在之前一篇论文中写到过,可以参考这个链接:PointNet论文笔记 下边我就直接放一张网络组成图,并对代码进行解释,我以一种比较容易理解的顺序放置,希望耐心阅读。
网络结构图示
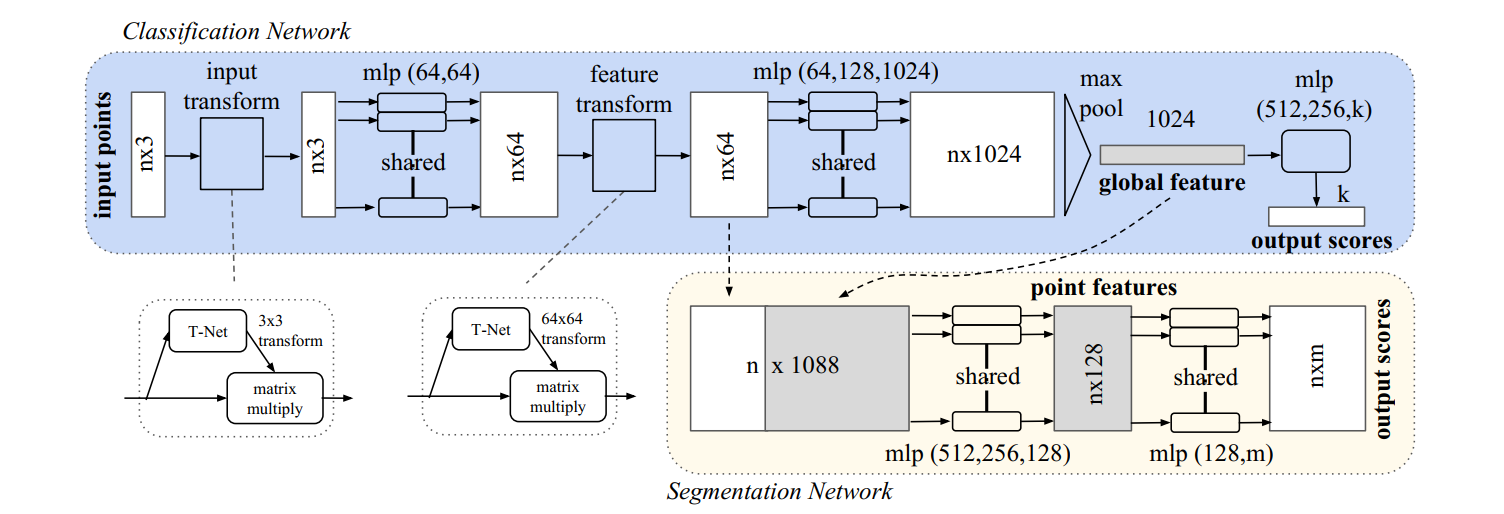
在分类网络中,输入n个点,对输入做特征变换,再进行最大池化输出k个种类;分割网络是分类网络的一个拓展,它考虑了全局和局部的特征以及每个点的输出分数。mlp代表多层感知机,括号中是感知机的层数,批标准化(Batchnorm)本用于所有带有ReLU函数的层,Dropout层被用于分类网络中最后一个多层感知机中。
代码详解
首先我先来讲解分类网络,图中深色部分,首先输入点经过一个transform,再经过多层感知机,再经过一个feature transform,再经过多层感知机和max pooling,最后经过多层感知机获得分类结果,网络结构是比较清晰的,下边一块一块看:
input transform
首先这一层的目的是对输入的每一个点云,在这里是2500个三坐标点,目的是要获得一个3×3的变换矩阵,获得这个矩阵的原因是:要对点云的姿态进行校正,而该变换矩阵就是根据点云特性,做出一个刚体变换,使点云处于一个比较容易检测的姿态。先对输入经过三级卷积核为1×1的卷积处理得到1024通道的数据,再经过全连接处映射到九个数据,最后调整为3×3
class STN3d(nn.Module):
def __init__(self):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
feature transform
下边我们先考虑后边这个feature transform层,这个其实和上边那个是一样的,只是从电源数据中获取一个64×64的变换矩阵,这个也是对特征的一种校正,一种广义的位姿变换,代码几乎没有差别
class STNkd(nn.Module):
def __init__(self, k=64):
super(STNkd, self).__init__()
self.conv1 = torch.nn.Conv1d(k, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k*k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.k = k
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1,self.k*self.k).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x主体部分
这部分讲max pooling之前的剩余部分,首先经过STN3d获得3×3矩阵,乘以点云做完位姿变换,再经过多层感知机(实际上多层感知机与卷积核边长为1的卷积操作本质是一样的),再乘以经过STNkd获得的64×64的矩阵,完成位姿变换,再经过多层感知机(这里同样用边长为1的卷积核的卷积操作),得到n×1024的矩阵,n为每批次读入的数据文件个数。下边这个类中调用了前边两个类。
class PointNetfeat(nn.Module):
def __init__(self, global_feat = True, feature_transform = False):
super(PointNetfeat, self).__init__()
self.stn = STN3d()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feat = global_feat
self.feature_transform = feature_transform
if self.feature_transform:
self.fstn = STNkd(k=64)
def forward(self, x):
n_pts = x.size()[2]
trans = self.stn(x)
x = x.transpose(2, 1)
x = torch.bmm(x, trans)
x = x.transpose(2, 1)
x = F.relu(self.bn1(self.conv1(x)))
if self.feature_transform:
trans_feat = self.fstn(x)
x = x.transpose(2,1)
x = torch.bmm(x, trans_feat)
x = x.transpose(2,1)
else:
trans_feat = None
pointfeat = x
x = F.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
if self.global_feat:
return x, trans, trans_feat
else:
x = x.view(-1, 1024, 1).repeat(1, 1, n_pts)
return torch.cat([x, pointfeat], 1), trans, trans_feat
后处理部分
下边就要进行最大池化和多层感知机进行分类了,经过全连接分成k类,根据概率来判别究竟属于哪一类
class PointNetCls(nn.Module):
def __init__(self, k=2, feature_transform=False):
super(PointNetCls, self).__init__()
self.feature_transform = feature_transform
self.feat = PointNetfeat(global_feat=True, feature_transform=feature_transform)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k)
# 防止过拟合
self.dropout = nn.Dropout(p=0.3)
# 归一化防止梯度爆炸与梯度消失
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
def forward(self, x):
# 完成网络主体部分
x, trans, trans_feat = self.feat(x)
# 经过三个全连接层(多层感知机)映射成k类
x = F.relu(self.bn1(self.fc1(x)))
x = F.relu(self.bn2(self.dropout(self.fc2(x))))
x = self.fc3(x)
# 返回的是该点云是第ki类的概率
return F.log_softmax(x, dim=1), trans, trans_feat分割网络
分割网络是借用了分类网络的两部分,分别是64通道和1024通道,堆积在一起形成1088通道的输入,经过多层感知机输出了结果m通道的结果,m代表类的个数,也就是每个点属于哪一类,实际上分割是在像素级或者点级的分类,本质上是一样的
class PointNetDenseCls(nn.Module):
def __init__(self, k = 2, feature_transform=False):
super(PointNetDenseCls, self).__init__()
self.k = k
self.feature_transform=feature_transform
self.feat = PointNetfeat(global_feat=False, feature_transform=feature_transform)
self.conv1 = torch.nn.Conv1d(1088, 512, 1)
self.conv2 = torch.nn.Conv1d(512, 256, 1)
self.conv3 = torch.nn.Conv1d(256, 128, 1)
self.conv4 = torch.nn.Conv1d(128, self.k, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
batchsize = x.size()[0]
n_pts = x.size()[2]
x, trans, trans_feat = self.feat(x)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.conv4(x)
x = x.transpose(2,1).contiguous()
x = F.log_softmax(x.view(-1,self.k), dim=-1)
x = x.view(batchsize, n_pts, self.k)
return x, trans, trans_feat训练结果
训练过程可以参考源码
网络分类性能还是很强的,只是迭代了一次,精度就达到了91%以上
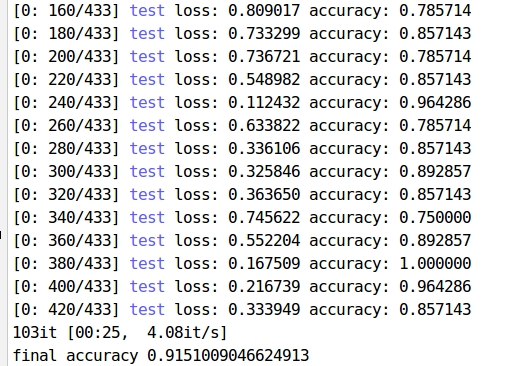
在点较少的情况下,分割效果也还是可以的,5次迭代可以达到 80.0mIoU

最后
以上就是快乐水池最近收集整理的关于PointNet模型的Pytorch代码详解前言网络结构图示代码详解 分割网络训练结果的全部内容,更多相关PointNet模型内容请搜索靠谱客的其他文章。








发表评论 取消回复