计算机网络5————应用层(DNS 和 HTTP)
文章目录
- 计算机网络5————应用层(DNS 和 HTTP)
- 一.应用层概述
- 二.DNS
- 1.概述
- 2.域名的树状结构
- 3.域名服务器
- 4.域名解析过程
- 三.HTTT概述
- 1.URL
- 2.GET和POST的区别
- 3.HTTP实现断点续传
- 四.一个完整的网络请求过程
- 1.DNS域名解析
- 2.TCP连接
- 3.HTTP传输数据
- 4.如何通过因特网传输数据
- 五.参考资料
一.应用层概述
应用层位于网络体系的最高层
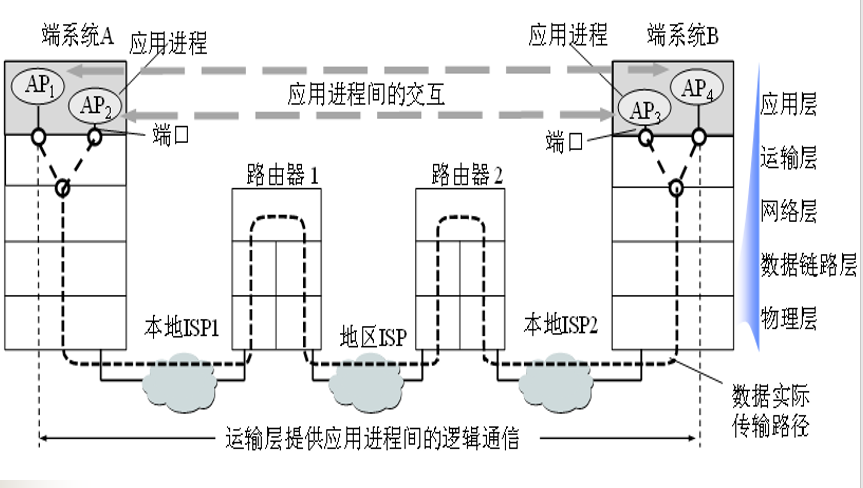
应用层字协议:
定义了运行在不同端系统上的应用程序进程之间如何传递报文,为某一类应用进程提供了通信服务的规则。
二.DNS
1.概述
DNS产生原因:
IP地址难于记忆,可使用符号地址,比如用www.hh.edu表示210.28.39.92。网络本身是使用IP地址的,因此需要一个完成二者之间相互转化的机制。因此就产生的域名系统DNS。
相关概念:
- 名称空间:定义了所有可能的名称(可为平面或者层次)的集合
- 域名:任何一个Internet上的主机或者路由器,有可有一个唯一的层次结构的名称
- 域:是名称空间中的一个可被管理的划分(域还可以继续划分为子域,如二级域,三级域)
- 域名系统维护着名称到值的映射的集合
2.域名的树状结构
域名的树状结构为:
- 跟
- 在跟下面的顶级域名
- 在某个顶级域名下的二级域名
- 在某个二级域名下的三级域名
- …
- 叶:主机名
域名表示:主机名…三级域名.二级域名.顶级域名
- 完整的域名最长255个字符
- 每部分最长63个字符
- 不区分大小写
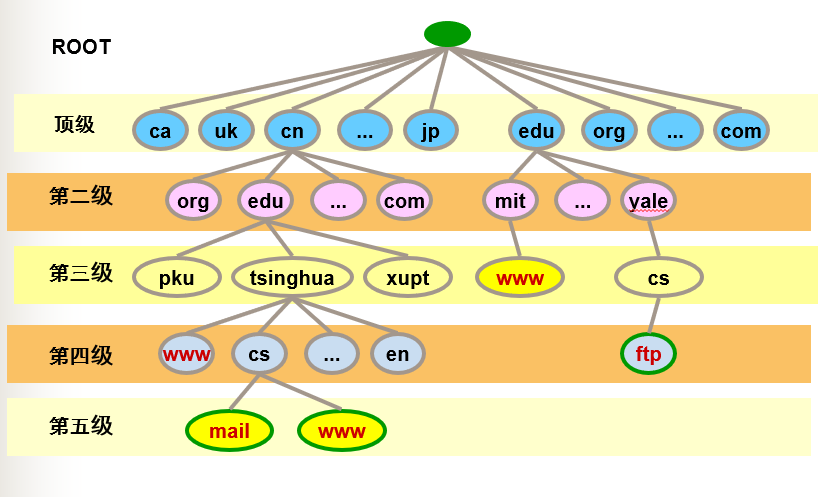
顶级域名分为三类:国际顶级域名,通用顶级域名,基础结构域名。
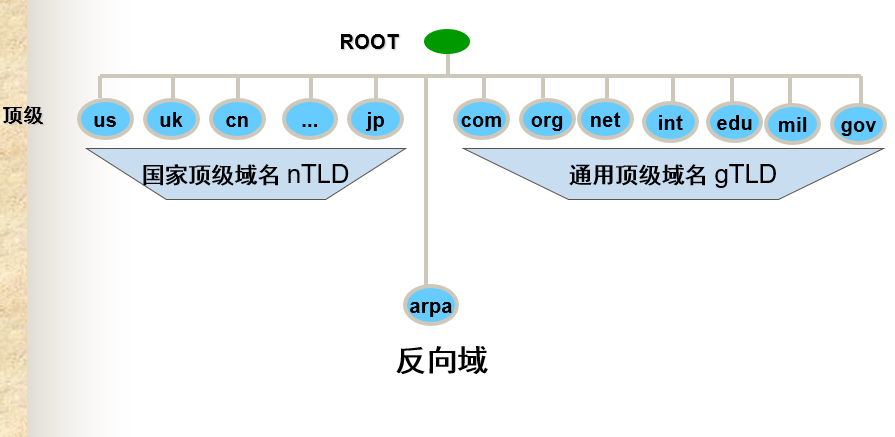
国家顶级域名:

通用顶级域名:

基础结构域名:这种域名只有一个,即arpa,用于反域名解析,因此又称为反向域名。
3.域名服务器
域名服务器有以下四种类型:
- 根域名服务器
- 顶级域名服务器
- 权限域名服务器
- 本地域名服务器
a.本地域名服务器
- 本地域名服务器又称默认域名服务器,当一个主机发出DNS查询请求时,这个查询请求报文就发送给本域名服务器。
- 每一个因特网服务提供者ISP,或者一个大学,甚至一个大学的一个系,都可以拥有一个本地域名服务器
- 当本地域名无法对因特网上的域名五福解析,就首先求助于跟域名服务器。
b.根域名服务器
- 当本地域名服务器无法解析域名时,就会首先求助于根域名服务器。
- 在因特网上共有13个不同IP地址的根域名服务器,他们的名字是用一个英文字母命名,从a一直到m,这样做的目的是为了方便用户,使世界大部分DNS域名服务器都能就近找到一个跟域名服务器
- 每个域名服务器都知道所有的顶级域名服务器的域名和IP地址。
c.顶级域名服务器
- 顶级域名服务器负责管理在其下注册的所有二级域名
d.权限域名服务器
- 权限域名服务器是负责一个区的域名服务器
- 当一个权限域名服务器还不能给出最后的查询答案时,就会告诉发出查询请求的DNS客户,下一步应当找哪一个权限域名服务器
4.域名解析过程
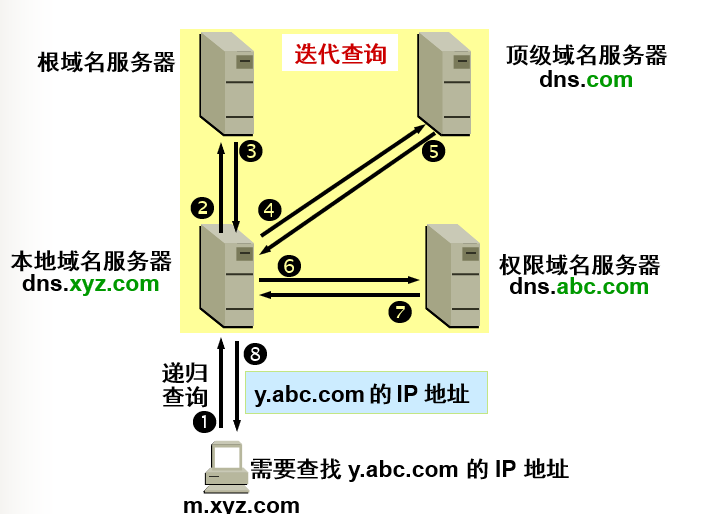
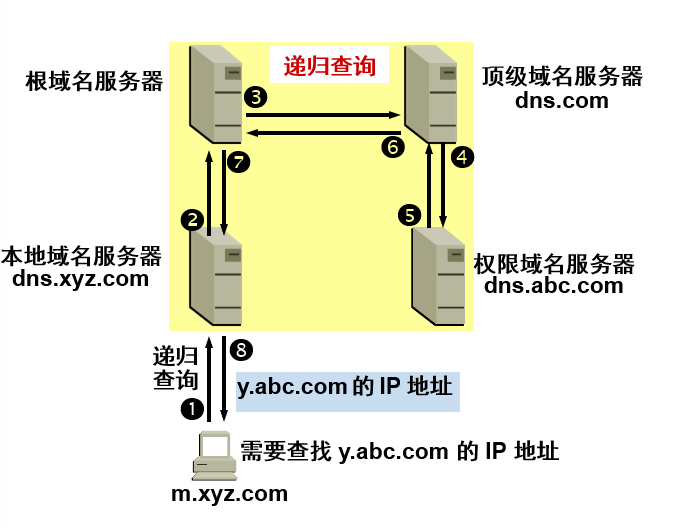
域名解析分为两种查询:迭代查询和递归查询
迭代查询:
递归查询
- 主机向本地域名服务器的查询一般都是采用递归查询。如果主机所询问的本地域名服务器不知道被查询域名的IP地址,那么本地域名服务器就以DNS客户的身份,向其他跟域名服务器继续发出查询请求报文。
- 本地域名服务器向跟域名服务器的查询通常是采用的迭代查询。当跟域名服务器收到本地域名服务器的迭代查询请求报文时,要么给出所要查询的IP地址,要么告诉本地域名服务器:你的下一步应当向哪一个域名服务器进行查询。然后让本地域名服务器进行后续的查询。
三.HTTT概述
关于HTTP的大部分内容(报文格式,请求方法,状态码,各个版本),在我的另一篇博客中,都有比较详细的内容:Android之网络请求1————HTTP协议
在这里我主要,是对上面那篇博文的补充以及我在被头条面试时,问到的两个问题
1.URL
URL是浏览器寻找信息时所需要的资源位置,通过URL,人类和应用程序才能找到,使用并共享因特网上大量的数据资源,URL是人们对HTTP和其他协议的常用访问点:一个人将浏览器指向一个URL,浏览器会使用恰当的协议报文来获取人们所期望的资源。
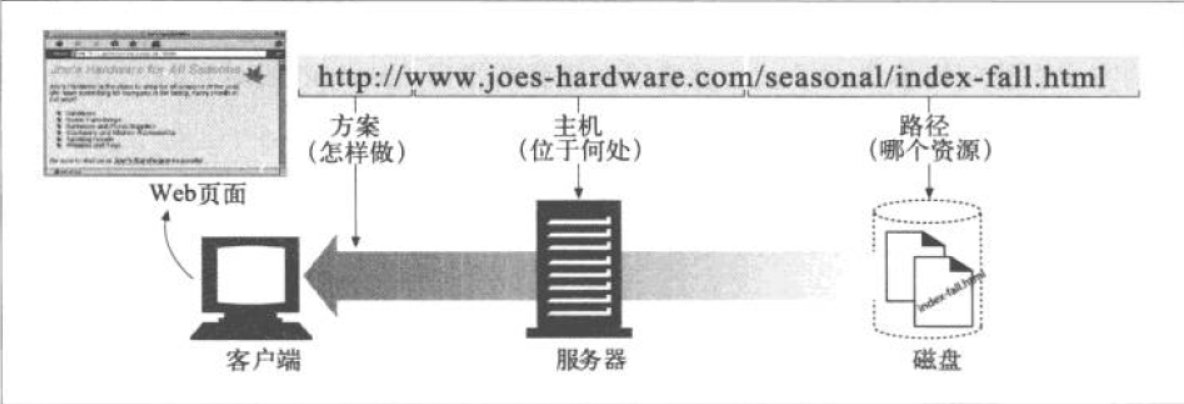
比如你要获取URL:http://www.joes-hardware.com/seasonal/index-fall.html.
这个URL分为三部分:
- 第一部分(http)是URL方案。方案可以告知web客户端怎样访问资源。在这个例子中,URL使用的HTTP协议
- 第二部分(www.joes-hardware.com)指的是服务的位置。这部分告知web客户端资源位于何处
- 第三部分(/seasonal/index-fall.html)是资源路径。路径说明了请求的是服务器上哪个特定的本地资源
 a.URL的语法
a.URL的语法
大多数URL的语法建立在这个由9部分构成的通用格式上:
< scheme >://< user >:< password >@< host >:< port >/ < path > ; < patrams > ? | < query >#< frag > ]
- 方案(scheme):访问服务器以获取资源时要使用哪种协议
- 用户(user):某些方案访问资源时需要的用户名
- 密码(password):用户名后面可能要包含的密码
- 主机(host):资源宿主服务器的主机名或者ip地址
- 端口(port):资源宿主服务器正在监听的端口号。很多方案都有默认的端口号(http:80)
- 路径(path):服务器上资源的本地名,由一个斜杠将其与前面的URL组件分割开。路径组件的语法是和方案有关的
- 参数(patrams):某些方案会用这个组件来指定输入参数,参数为名/值对。URL可以包含多个参数字段,他们之间以及路径其余部分用分号分隔
- 查询(query):某些方案会用这个组件传递参数以激活应用程序。查询组件内容没有通用格式。用字符‘?’将其与其他部分分割出来
- 片段(frag):一小片或者一部分资源的名字。引用对象是,不会将frag字段传送给服务器,这个字段是在客户端内部使用的。通过字符‘#’将其与URL的其余部分分割开。
对于任意一个URL而言,方案,主机,路径这三个是必不可少的。
b.方案
url除了http之外,有什么其他的方案呢?
常用URL Scheme,这篇博客里介绍了Android大部分常用的方案。
其他常见的方案:
- http:超文本传输协议,与通用的URL格式相符(除了没有用户名和密码之外)。若省略了端口,则默认是80。
- https:与http是一对。区别在于https使用了SSL(SSL为HTTP连接提供了端到端的加密机制)语法和HTTP的相同,默认端口是443
- mailto:URL指向E-mail地址
- ftp:文件传输协议URL可从FTP服务器上下载或上传文件,并获取FTP服务器上的目录结构内容的列表
- rtsp,rtspu: RTSP URL是可以通过实时流传输协议(Real Time Streaming Protocol)解析的音/视频媒体资源的标识符
- file:表示一台主机上可直接访问的文件
- telnet:用于访问交互式业务
2.GET和POST的区别
这个问题当时在面试字节跳动实习岗的时候,被问到这个问题,当时只是简单的回答了一下,回答的很糟。所以在这里系统的整理下
先简单看看两者的作用
GET:通常用于请求服务器发送某个资源。
POST:POST方法起初是用来向服务器输入数据的。但实际上,通常会用它来支持HTML的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送给它要去的地方。
两者的差别:
- POST相对来说更安全些(不会作为URL的一部分,不会缓存保存在服务器日志 以及浏览记录中)
- POST发送的数据更大(get有URL长度限制)
- POST能发送更多的数据类型(get只能发送ASCLL字符)
- POST比GET慢
- POST用于修改和写入数据,get一般用于搜索排序和筛选之类的操作(淘宝,支付宝的搜索查询都是get提交),目的是资源的获取,读取数据
POST请求为什么慢
- POST需要在请求的Body部分包含数据,所以会多几个数据描述部分,但这部分微乎其微。
- 最重要的是POST请求过程比GET请求多了一次请求,POST在请求时,会先发送请求头,服务器确认之后,才会发送真正的数据。
- get会将数据缓存起来,所以get请求可以享受到各种缓存机制,而post不会
关于GET请求传参的最大长度限制
- http协议并未规定get和post的长度限制
- get的最大长度限制是因为浏览器和web服务器限制了URL的长度
- 不同的浏览器和web服务器,限制的最大长度不一样
- 要支持IE,则最大长度为2083byte,若支持Chrome,则最大长度8182byte
3.HTTP实现断点续传
a.概述
断点续传:指的是在上传/下载时,将任务(一个文件或压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传/下载,如果碰到网络故障,可以从已经上传/下载的部分开始继续上传/下载未完成的部分,而没有必要从头开始上传/下载。可以节省时间,提高速度。
b.相关的参数
从http1.1开始后,开始支持获取文件的部分内容,这为并行下载以及断点续传提供了技术支持。它通过在 Header 里两个参数实现的,客户端发请求时对应的是 Range ,服务器端响应时对应的是 Content-Range。
Range
用于请求头中,指定第一个字节的位置和最后一个字节的位置,一般格式:Range:(unit=first byte pos)-[last byte pos]
Range: bytes=0-499 表示第 0-499 字节范围的内容
Range: bytes=500-999 表示第 500-999 字节范围的内容
Range: bytes=-500 表示最后 500 字节的内容
Range: bytes=500- 表示从第 500 字节开始到文件结束部分的内容
Range: bytes=0-0,-1 表示第一个和最后一个字节
Range: bytes=500-600,601-999 同时指定几个范围
Content-Range
用于响应头中,在发出带 Range 的请求后,服务器会在 Content-Range 头部返回当前接受的范围和文件总大小。一般格式:Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity legth]
Content-Range: bytes 0-499/22400
0-499 是指当前发送的数据的范围,而 22400 则是文件的总大小。
而在响应完成后,返回的响应头内容也不同:
HTTP/1.1 200 Ok(不使用断点续传方式)
HTTP/1.1 206 Partial Content(使用断点续传方式)
c.增强校验
在实际场景中,会出现一种情况,即在终端发起续传请求时,URL 对应的文件内容在服务器端已经发生变化,此时续传的数据肯定是错误的。如何解决这个问题了?显然此时需要有一个标识文件唯一性的方法。
在 RFC2616 中也有相应的定义,比如实现 Last-Modified 来标识文件的最后修改时间,这样即可判断出续传文件时是否已经发生过改动。同时 FC2616 中还定义有一个 ETag 的头,可以使用 ETag 头来放置文件的唯一标识。
Last-Modified
If-Modified-Since,和 Last-Modified 一样都是用于记录页面最后修改时间的 HTTP 头信息,只是 Last-Modified 是由服务器往客户端发送的 HTTP 头,而 If-Modified-Since 则是由客户端往服务器发送的头,可以看到,再次请求本地存在的 cache 页面时,客户端会通过 If-Modified-Since 头将先前服务器端发过来的 Last-Modified 最后修改时间戳发送回去,这是为了让服务器端进行验证,通过这个时间戳判断客户端的页面是否是最新的,如果不是最新的,则返回新的内容,如果是最新的,则返回 304 告诉客户端其本地 cache 的页面是最新的,于是客户端就可以直接从本地加载页面了,这样在网络上传输的数据就会大大减少,同时也减轻了服务器的负担。
Etag
主要为了解决 Last-Modified 无法解决的一些问题。
1.一些文件也许会周期性的更改,但是内容并不改变(仅改变修改时间),这时候我们并不希望客户端认为这个文件被修改了,而重新 GET。
2.某些文件修改非常频繁,例如:在秒以下的时间内进行修改(1s 内修改了 N 次),If-Modified-Since 能检查到的粒度是 s 级的,这种修改无法判断(或者说 UNIX 记录 MTIME 只能精确到秒)。
3.某些服务器不能精确的得到文件的最后修改时间。
Etag 仅仅是一个和文件相关的标记,可以是一个版本标记,
If-Range
用于判断实体是否发生改变,如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体
一般格式:If-Range: Etag | HTTP-Date
If-Range 必须与 Range 配套使用。如果请求报文中没有 Range,那么 If-Range 就会被忽略。如果服务器不支持 If-Range,那么 Range 也会被忽略。
d.工作原理
Etag 由服务器端生成,客户端通过 If-Range 条件判断请求来验证资源是否修改。请求一个文件的流程如下:
第一次请求:
- 客户端发起 HTTP GET 请求一个文件。
- 服务器处理请求,返回文件内容以及相应的 Header,其中包括 Etag(例如:627-4d648041f6b80)(假设服务器支持 Etag 生成并已开启了 Etag)状态码为 200。
第二次请求(断点续传):
- 客户端发起 HTTP GET 请求一个文件,同时发送 If-Range(该头的内容就是第一次请求时服务器返回的 Etag:627-4d648041f6b80)。
- 服务器判断接收到的 Etag 和计算出来的 Etag 是否匹配,如果匹配,那么响应的状态码为 206;否则,状态码为 200。
四.一个完整的网络请求过程
在之前的几篇文章里,我们详细完整的介绍了,传输层,网络层,数据链路层。最后我想用一个完整的网络请求为例,将前面的知识串起来。
问题:从输入网址到获得页面的网络请求的过程。
简答:
- 解析Web页面的URL,得到Web服务器的域名。
- 浏览器向DNS请求解析www.nowcoder.com地址,获得web服务器的ip地址。
- 浏览器与服务器建立TCP连接。
- 浏览器发起HTTP请求,向Web服务器获得URL指定的文档。
- web服务器响应请求,并将请求的文档发给浏览器
- 浏览器解析html代码并请求html中的js/css/图片等资源
- 浏览器进行页面渲染呈现给用户
下面主要以2.3.4为重点展开接收
1.DNS域名解析
以Chrome浏览器为例,Chrome会解析域名对应的IP地址。
(1)Chrome浏览器会首先搜索浏览器自身的DNS缓存(可以使用 chrome://net-internals/#dns 来进行查看),浏览器自身的DNS缓存有效期比较短,且容纳有限,大概是1000条。如果自身的缓存中存在blog.csdn.net 对应的IP地址并且没有过期,则解析成功。
(2)如果(1)中未找到,那么Chrome会搜索操作系统自身的DNS缓存(可以在命令行下使用 ipconfig /displaydns 查看)。如果找到且没有过期则成功。
(3)如果(2)中未找到,那么尝试读取位于C:WindowsSystem32driversetc下的hosts文件,如果找到对应的IP地址则解析成功。
(4)如果(3)中未找到,浏览器首先会找TCP/IP参数中设置的本地DNS服务器,如果要查询的域名包含在本地配置的区域资源中,则完成域名解析,否则根据本地DNS服务器会请求根DNS服务器。后面就是迭代或者递归查询的过程。
2.TCP连接
下图就是TCP的三次握手的过程
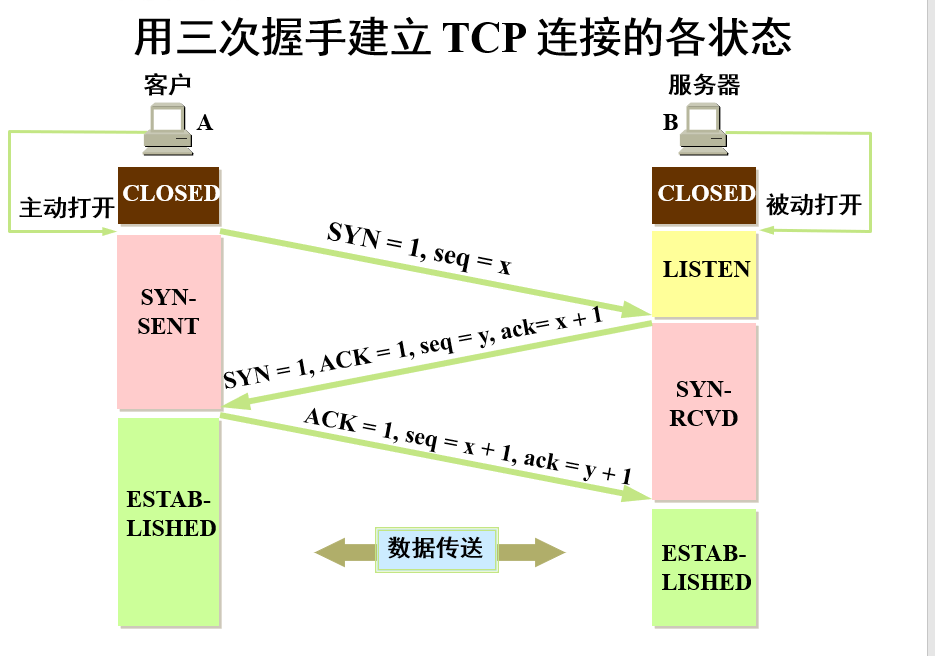 更详细的内容可以看我上一篇的博客 计算机网络4————运输层
更详细的内容可以看我上一篇的博客 计算机网络4————运输层
3.HTTP传输数据
当连接建立好之后,就可以进行数据的传输。一般而言会以GET或者POST的方式进行传输通信,以GET请求为例
下面是一个GET请求报文格式
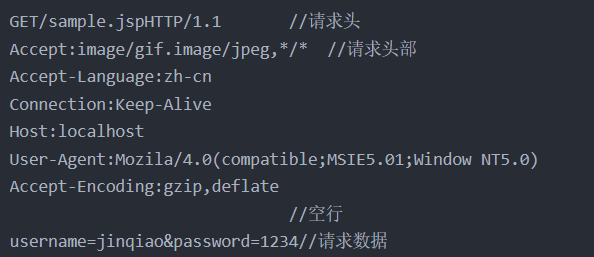
客户端将这个报文经过因特网发送给服务器
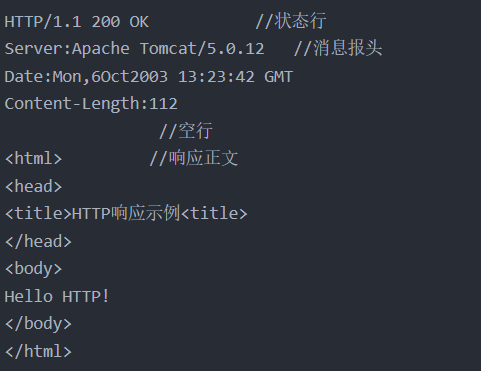
服务器收到这个报文之后,处理之后,给客户端返回一个响应
即HTTP响应,响应报文格式如下:
4.如何通过因特网传输数据
上面只是简单的说,通过因特网进行传输,那么他究竟如何通过因特网传输的?
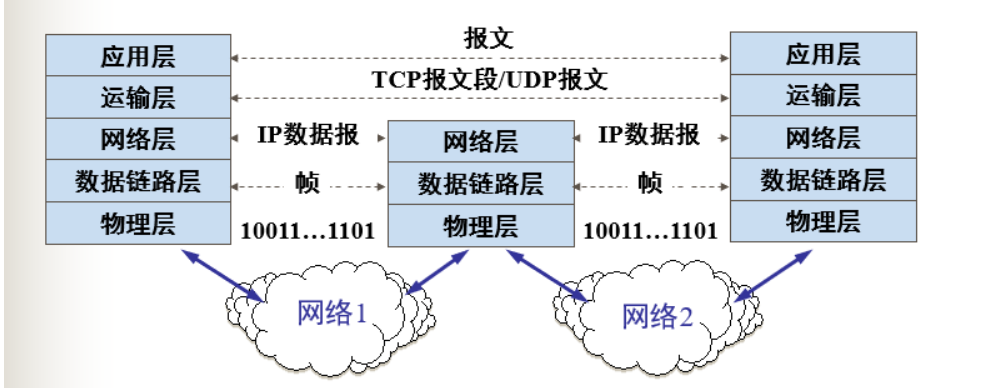 就是如上面所示,根据TCP/IP的协议。
就是如上面所示,根据TCP/IP的协议。
- 先添加TCP头部,这一块负责流量控制,拥塞控制,以及负责连接的建立和断开。详细内容见计算机网络4————运输层
- 在添加IP头部,这一块是负责寻址,用IP地址,经过路由器中路由表的分组转发,最终到达服务器。而路由表的生成,有静态路由和动态路由之分。动态路由有RIP(距离向量),OSPF(链路选择),BGP协议来生成对应的路由表,详细内容见计算机网络3————网络层
- 在添加MAC协议头部,在数据链路层使用的以太网协议,这一块是负责,根据mac地址,在局域网内寻找目标,进行转发。比如主机寻找另一个主机,或者路由器。路由器寻找主机或者另一个路由器。网络层之间的路由间的转发,实际上就是靠mac地址来完成的。mac地址是通过arp协议将ip转换为mac地址。详细内容见计算机网络2————数据链路层
- 最后就是物理层,将完整的数据包(http报文+TCP头部+IP头部+MAC头部)转换为二进制,在转为为对于的物理信号,通过光缆或者电缆将这些数据进行传输。
五.参考资料
《计算机网络:原理和实践》
《HTTP权威指南》
字节跳动面试题:从输入网址到获得页面的网络请求的过程,请详细说一下
http GET 和 POST 请求的优缺点和误区 --前端优化
最后
以上就是自觉金针菇最近收集整理的关于计算机网络5————应用层(DNS 和 HTTP)计算机网络5————应用层(DNS 和 HTTP)的全部内容,更多相关计算机网络5————应用层(DNS内容请搜索靠谱客的其他文章。








发表评论 取消回复