本专栏按照 https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html 顺序进行总结 。
文章目录
- 原理解析
- 总体概述
- 细节实现
- 算法实现
- 总体流程
- 代码实现
D D P G color{red}DDPG DDPG :[ paper:continuous control with deep reinforcement learning | code ]
原理解析
总体概述
之所以使用确定性策略的原因是相对与随机策略,就是因为数据的采样少,算法效率高,深度确定性策略就是使用了深度神经网络去近似值函数和策略梯度网络。总结一下DDPG算法使用以下核心思想:
(1)采用经验回放方法
(2)采用target目标网络更新(为什么要用target网络?因为训练的网络特别不稳定)
(3)AC框架
(4)确定性策略梯度
DDPG 算法流程图
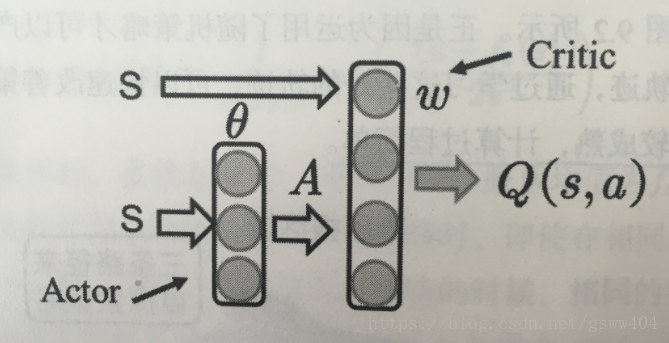
算法采用 AC 框架,Actor获取状态
s
s
s ,
s
s
s 可以是一组向量(速度,位置等),经过 Actor 网络选取动作 action,Critic 根据动作action 和
s
s
s 进行评价,采用策略梯度最终更新两个网络的权重。
细节实现
是一个结合了DPG以及DQN的无模型离线演员-评论家算法。回忆一下,DQN(深度Q网络)通过经验回访以及冻结目标网络(设置独立的目标网络)的方式来稳定Q函数的训练过程。原始的DQN算法只能在离散的动作空间上使用,DDPG算法在学习一个确定性策略的同时通过演员-评论家框架将其扩展到连续的动作空间中。
回顾 DQN
算法流程

流程图
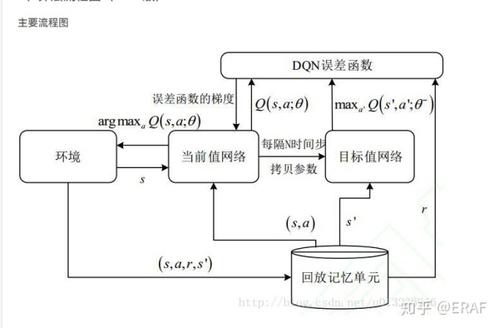
DDPG的经验回放和DQN完全相同;
下面介绍DQN中的独⽴⽬标⽹络。
DPG的更新过程如下:
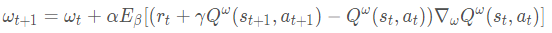
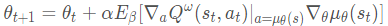
其中 a t + 1 = μ θ ( s t + 1 ) a_{t+1} = {mu _theta }(s_{t+1}) at+1=μθ(st+1),上述式子的目标值: r t + γ Q w ( s t + 1 , a t + 1 ) r_t + gamma Q^w(s_{t+1},a_{t+1}) rt+γQw(st+1,at+1)
需要修改的是 式子中的
ω
omega
ω 和
θ
theta
θ ,将其单独拿出来,利用独立的网络进行更新,DDPG的更新公式如下所示:
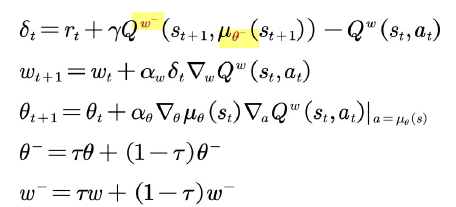
引入了DDPG,接下来从下面几个要点介绍一下。
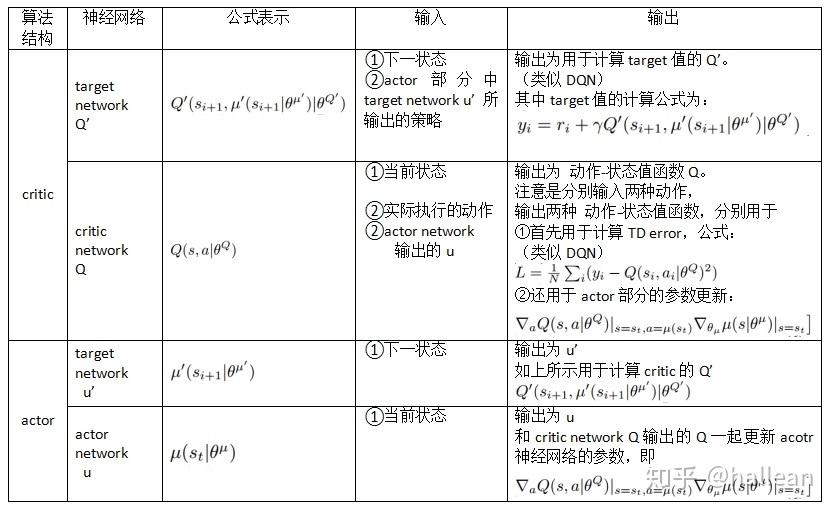
先来总结下DDPG 4个网络的功能定位:
-
Actor当前网络:负责策略网络参数 θ θ θ 的迭代更新,负责根据当前状态 S S S 选择当前动作 A A A ,用于和环境交互生成 S ′ , R S′,R S′,R 。
-
Actor目标网络:负责根据经验回放池中采样的下一状态 S ′ S′ S′ 选择最优下一动作 A ′ A′ A′ 。网络参数 θ ′ θ′ θ′ 定期从 θ θ θ 复制。
-
Critic当前网络:负责价值网络参数 w w w 的迭代更新,负责计算当前 Q Q Q 值 Q ( S , A , w ) Q(S,A,w) Q(S,A,w) 。目标 Q Q Q 值 y i = R + γ Q ′ ( S ′ , A ′ , w ′ ) yi=R+γQ′(S′,A′,w′) yi=R+γQ′(S′,A′,w′)
-
Critic目标网络:负责计算目标 Q Q Q 值中的 Q ′ ( S ′ , A ′ , w ′ ) Q′(S′,A′,w′) Q′(S′,A′,w′) 部分。网络参数 w ′ w′ w′ 定期从 w w w 复制。
DDPG除了这4个网络结构,还用到了经验回放
更新目标网络 方法
soft update是一种running average的算法 :
- 优点:target网络参数变化小,用于在训练过程中计算online网络的gradient,比较稳定,训练易于收敛。
- 缺点:参数变化小,学习过程变慢。还有一个问题是使用这种缓慢更新的 target 网络,容易引起对 Q 值的过高估计(over estimation),从而使策略很难收敛,这个缺陷在后续的升级版算法 TD3 中得到了解决。
DDPG的实现框架
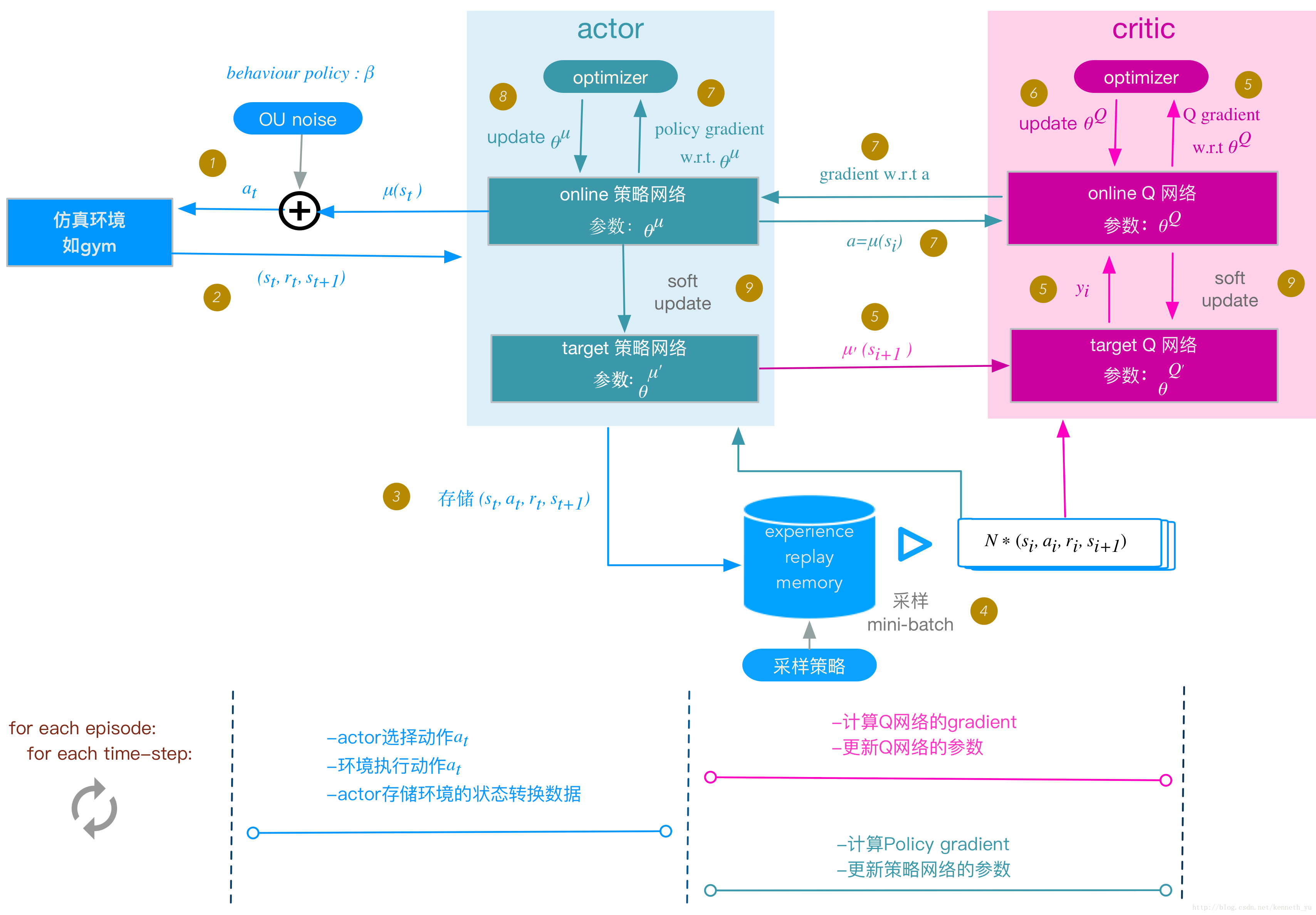
解析上图:

特点
- 不同于DQN直接将Q网络的参数定期复制到target network,DDPG通过”soft” target updates的方式来保证参数可以缓慢的更新,从而达到和DQN定期复制参数相类似的提升学习稳定性的效果。但是收敛速度慢。
- 虽然DDPG借鉴了DQN的思想(memory replay 和 target netwotrk),但是却不能直接使用Q-learning算法框架,因为在连续动作空间无法简单、快速地实现Q-learning的贪婪策略。所以使用的是基于确定动作策略的actor-critic算法框架。并且在actor部分采用DPG的确定性策略方式。
- DDPG算法是off-policy的,所以行为策略和评估策略的不同可以增加探索
- DDPG中,通过在行为策略的确定性策略上添加噪声来使算法结构高效“探索”。
算法实现
总体流程

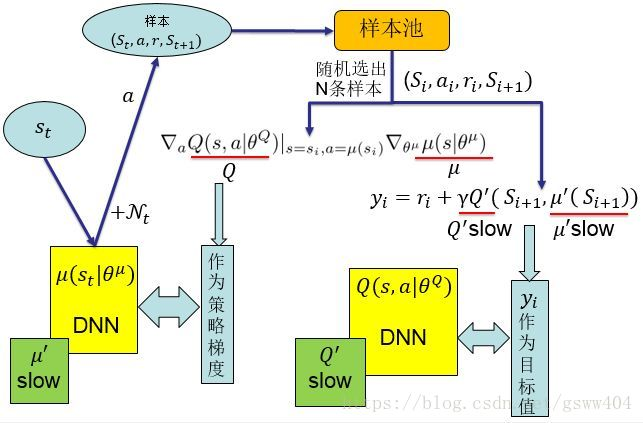
对上述算法流程做一个简要的说明:
- 初始化
(1)随机初始化Actor网络 μ ( s ∣ θ μ ) mu(sverttheta^mu) μ(s∣θμ) 和 Critic网络 Q ( s , a ) Q(s,a) Q(s,a)
(2)初始化 target 网络,复制 actor 和 critic
(3)初始化Replay Buffer R,用于打乱数据间相关性,使得数据独立同分布 - 训练Episode
(5)初始化一个随机的 N N N,相当于action的探索度
(6)获得观察到的状态 s 1 s_1 s1
(8)根据策略网络 μ mu μ 的输出以及探索度 N t N_t Nt(噪音)选择动作 a t a_t at
(9)执行action a t a_t at,得到reward r t r_t rt 和新状态 s t + 1 s_{t+1} st+1 - 存储和读取Replay Buffer R
(10)将序列存储到R
(11)再随机批量读取R中序列进行学习
(注:由于强化学习过程学习过程的序列之间有相关性,一般batch-size= 64,128,256) - 更新Critic网络结构
(12)定义 y i y_i yi
(13)使用RMSE误差,更新时直接更新值函数的损失 - 更新Actor网络结构
(15)直接更新Actor的策略梯度 - 更新target网络参数
采用soft updating方式,用 τ tau τ 延迟更新
代码实现
详情见 github:https://github.com/sweetice/Deep-reinforcement-learning-with-pytorch/tree/master/Char05%20DDPG
import argparse
from itertools import count
import os, sys, random
import numpy as np
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Normal
from tensorboardX import SummaryWriter
'''
Implementation of Deep Deterministic Policy Gradients (DDPG) with pytorch
riginal paper: https://arxiv.org/abs/1509.02971
Not the author's implementation !
'''
parser = argparse.ArgumentParser()
parser.add_argument('--mode', default='train', type=str) # mode = 'train' or 'test'
# OpenAI gym environment name, # ['BipedalWalker-v2', 'Pendulum-v0'] or any continuous environment
# Note that DDPG is feasible about hyper-parameters.
# You should fine-tuning if you change to another environment.
parser.add_argument("--env_name", default="Pendulum-v0")
parser.add_argument('--tau', default=0.005, type=float) # target smoothing coefficient
parser.add_argument('--target_update_interval', default=1, type=int)
parser.add_argument('--test_iteration', default=10, type=int)
parser.add_argument('--learning_rate', default=1e-4, type=float)
parser.add_argument('--gamma', default=0.99, type=int) # discounted factor
parser.add_argument('--capacity', default=1000000, type=int) # replay buffer size
parser.add_argument('--batch_size', default=100, type=int) # mini batch size
parser.add_argument('--seed', default=False, type=bool)
parser.add_argument('--random_seed', default=9527, type=int)
# optional parameters
parser.add_argument('--sample_frequency', default=2000, type=int)
parser.add_argument('--render', default=False, type=bool) # show UI or not
parser.add_argument('--log_interval', default=50, type=int) #
parser.add_argument('--load', default=False, type=bool) # load model
parser.add_argument('--render_interval', default=100, type=int) # after render_interval, the env.render() will work
parser.add_argument('--exploration_noise', default=0.1, type=float)
parser.add_argument('--max_episode', default=100000, type=int) # num of games
parser.add_argument('--print_log', default=5, type=int)
parser.add_argument('--update_iteration', default=200, type=int)
args = parser.parse_args()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
script_name = os.path.basename(__file__)
env = gym.make(args.env_name)
if args.seed:
env.seed(args.random_seed)
torch.manual_seed(args.random_seed)
np.random.seed(args.random_seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
min_Val = torch.tensor(1e-7).float().to(device) # min value
directory = './exp' + script_name + args.env_name +'./'
class Replay_buffer():
'''
Code based on:
https://github.com/openai/baselines/blob/master/baselines/deepq/replay_buffer.py
Expects tuples of (state, next_state, action, reward, done)
'''
def __init__(self, max_size=args.capacity):
self.storage = []
self.max_size = max_size
self.ptr = 0
def push(self, data):
if len(self.storage) == self.max_size:
self.storage[int(self.ptr)] = data
self.ptr = (self.ptr + 1) % self.max_size
else:
self.storage.append(data)
def sample(self, batch_size):
ind = np.random.randint(0, len(self.storage), size=batch_size)
x, y, u, r, d = [], [], [], [], []
for i in ind:
X, Y, U, R, D = self.storage[i]
x.append(np.array(X, copy=False))
y.append(np.array(Y, copy=False))
u.append(np.array(U, copy=False))
r.append(np.array(R, copy=False))
d.append(np.array(D, copy=False))
return np.array(x), np.array(y), np.array(u), np.array(r).reshape(-1, 1), np.array(d).reshape(-1, 1)
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = self.max_action * torch.tanh(self.l3(x))
return x
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.l1 = nn.Linear(state_dim + action_dim, 400)
self.l2 = nn.Linear(400 , 300)
self.l3 = nn.Linear(300, 1)
def forward(self, x, u):
x = F.relu(self.l1(torch.cat([x, u], 1)))
x = F.relu(self.l2(x))
x = self.l3(x)
return x
class DDPG(object):
def __init__(self, state_dim, action_dim, max_action):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=1e-4)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = Critic(state_dim, action_dim).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=1e-3)
self.replay_buffer = Replay_buffer()
self.writer = SummaryWriter(directory)
self.num_critic_update_iteration = 0
self.num_actor_update_iteration = 0
self.num_training = 0
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def update(self):
for it in range(args.update_iteration):
# Sample replay buffer
x, y, u, r, d = self.replay_buffer.sample(args.batch_size)
state = torch.FloatTensor(x).to(device)
action = torch.FloatTensor(u).to(device)
next_state = torch.FloatTensor(y).to(device)
done = torch.FloatTensor(1-d).to(device)
reward = torch.FloatTensor(r).to(device)
# Compute the target Q value
target_Q = self.critic_target(next_state, self.actor_target(next_state))
target_Q = reward + (done * args.gamma * target_Q).detach()
# Get current Q estimate
current_Q = self.critic(state, action)
# Compute critic loss
critic_loss = F.mse_loss(current_Q, target_Q)
self.writer.add_scalar('Loss/critic_loss', critic_loss, global_step=self.num_critic_update_iteration)
# Optimize the critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Compute actor loss
actor_loss = -self.critic(state, self.actor(state)).mean()
self.writer.add_scalar('Loss/actor_loss', actor_loss, global_step=self.num_actor_update_iteration)
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Update the frozen target models
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(args.tau * param.data + (1 - args.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(args.tau * param.data + (1 - args.tau) * target_param.data)
self.num_actor_update_iteration += 1
self.num_critic_update_iteration += 1
def save(self):
torch.save(self.actor.state_dict(), directory + 'actor.pth')
torch.save(self.critic.state_dict(), directory + 'critic.pth')
# print("====================================")
# print("Model has been saved...")
# print("====================================")
def load(self):
self.actor.load_state_dict(torch.load(directory + 'actor.pth'))
self.critic.load_state_dict(torch.load(directory + 'critic.pth'))
print("====================================")
print("model has been loaded...")
print("====================================")
def main():
agent = DDPG(state_dim, action_dim, max_action)
ep_r = 0
if args.mode == 'test':
agent.load()
for i in range(args.test_iteration):
state = env.reset()
for t in count():
action = agent.select_action(state)
next_state, reward, done, info = env.step(np.float32(action))
ep_r += reward
env.render()
if done or t >= args.max_length_of_trajectory:
print("Ep_i t{}, the ep_r is t{:0.2f}, the step is t{}".format(i, ep_r, t))
ep_r = 0
break
state = next_state
elif args.mode == 'train':
if args.load: agent.load()
total_step = 0
for i in range(args.max_episode):
total_reward = 0
step =0
state = env.reset()
for t in count():
action = agent.select_action(state)
action = (action + np.random.normal(0, args.exploration_noise, size=env.action_space.shape[0])).clip(
env.action_space.low, env.action_space.high)
next_state, reward, done, info = env.step(action)
if args.render and i >= args.render_interval : env.render()
agent.replay_buffer.push((state, next_state, action, reward, np.float(done)))
state = next_state
if done:
break
step += 1
total_reward += reward
total_step += step+1
print("Total T:{} Episode: t{} Total Reward: t{:0.2f}".format(total_step, i, total_reward))
agent.update()
# "Total T: %d Episode Num: %d Episode T: %d Reward: %f
if i % args.log_interval == 0:
agent.save()
else:
raise NameError("mode wrong!!!")
if __name__ == '__main__':
main()
最后
以上就是个性糖豆最近收集整理的关于RL策略梯度方法之(七): Deep Deterministic Policy Gradient(DDPG)原理解析算法实现的全部内容,更多相关RL策略梯度方法之(七):内容请搜索靠谱客的其他文章。






![[ICLR2016]All You Need is a Good Init](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)

发表评论 取消回复