上一篇介绍了强化学习的一些基本概念强化学习系列--概念介绍(Introduction to Reinforcement Learning),今天我们讲解一个简单且经典的强化学习算法:Q-Learning。
背景
按照不同分类标准,Q Learning可以被分为:model-free,off-policy,value-based,TD等类别。
Q Learning算法思想主要是去学习一个纵坐标为状态(state)、横坐标是动作(action)、取值为当前状态下执行对应action时所获得的奖励(短期激励+长期收益)的Q-table矩阵。我们通过大量试错获取经验(reward)来更新Q-table,最终通过Q-table中记录的奖励情况来指导某个state执行哪个action可以获取最大收益。
举个例子: 一个小朋友(agent)假设无任何历史奖惩经验,那么Q-table中每个元素初使值都为0。
当小朋友还没做完作业状态时(state1),去学习(action1)还是去看电视(action2)得到父母的奖励是不一样的,学习的奖励会是一个棒棒糖(+2),看电视的奖励将会是挨揍一顿(-2)。
当小朋友已经做完作业时(state2),去学习(action 1)还是去看电视得到的奖励又会和state1的情况有所不同,此时学习的奖励为+1,看电视奖励会是-1。
...
多次经验总结后,Q-table的取值更新如下:
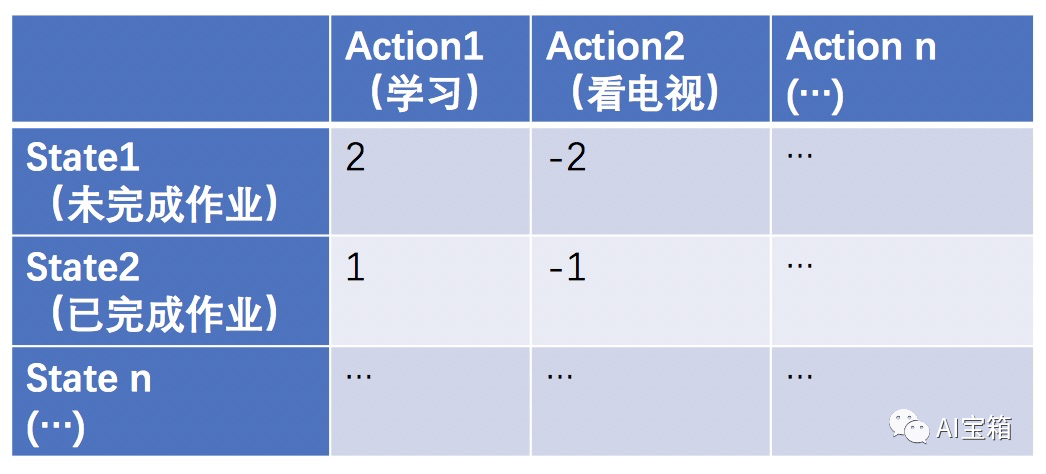
要特别说明的是,Q(s, a)除了代表本次(s, a)操作获得的reward外,还考虑未来的收益。即:Q(s, a) = reward(本次s-a操作) + Q(未来奖励)。
算法思想

Q-Learning的逻辑如上图,大致流程为:
1)随机选取一个状态S
2)在此S状态下,根据贪婪( 或者 ε-贪婪)选取动作 A
3)执行动作A,并根据enviroment的反馈获取reward R和下一状态S'
4)根据贪心算法,选取S’状态下reward最大的action a’。然后,使用(S,A)状态下的反馈奖励R以及(s',a')的未来奖励(Q值)采用时序差分方法(TD)更新Q(s,a)的状态奖励值
5)更新状态S
6)重复1步骤,直至Q-table内取值均收敛
代码逻辑
针对上面算法思想,我们看看代码是如何执行的,代码非常简单,就选action和更新Q-table两个主要function。备注:代码摘自莫烦github。
class QLearningTable: def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9): self.actions = actions # action 列表 self.lr = learning_rate # step4中alpha self.gamma = reward_decay # step4中gamma self.epsilon = e_greedy # step2中e-greedy概率 self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64) def choose_action(self, observation): # step 2 # action selection if np.random.uniform() # 选取Q最大的action state_action = self.q_table.loc[observation, :] # 存在Q值相同的多个action,随机选取一个 action = np.random.choice(state_action[state_action == np.max(state_action)].index) else: # 命中exploration,随机选取action # 随机选action action = np.random.choice(self.actions) return action def learn(self, s, a, r, s_): self.check_state_exist(s_) # 确认s是否是有效状态 q_predict = self.q_table.loc[s, a] # 从Q-table中获取预估值Q(s, a) if s_ != 'terminal’: q_target = r + self.gamma * self.q_table.loc[s_, :].max() # 实际的Q(s, a) = 短期环境奖励r + 长期激励Q(s',max_a) else: q_target = r # 如果下一状态游戏结束,Q(s, a)便只有当前奖励,没有未来奖励(游戏已结束,没有未来的操作) self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update实例介绍
介绍完代码思想,我再介绍一个Q-Learning的实际例子,供大家熟悉:
假设一栋建筑里有5个房间(已编号0-4),房间之间通过门相连,如下图(左图)所示。我们的目标是要走出房间,走出房间(室外编号为5)则可获得奖励100。我们对房间的连通情况进行抽象,如下图右图。
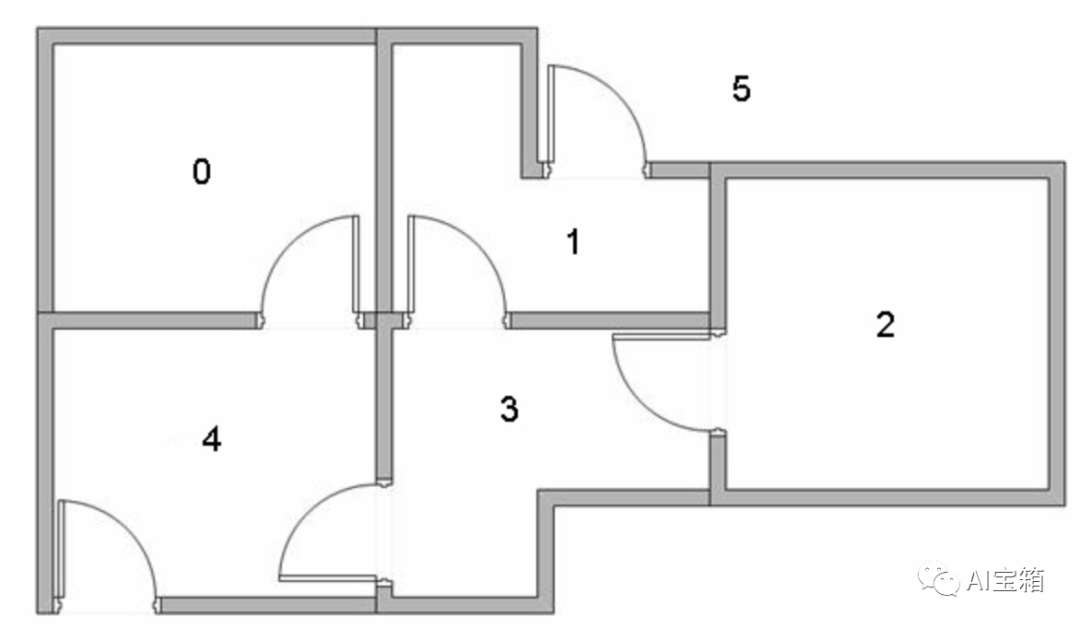
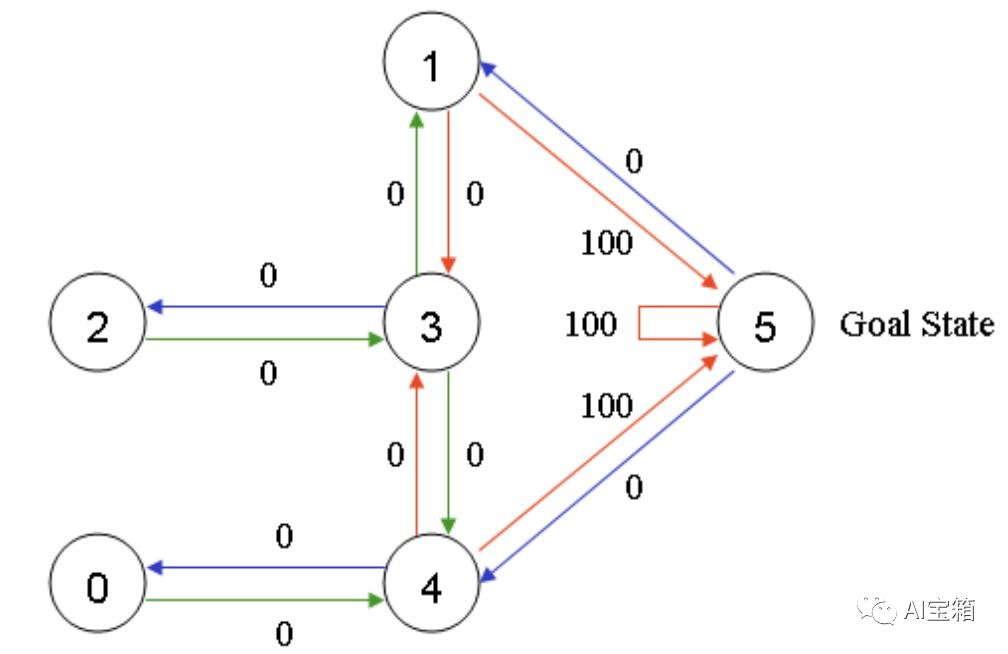
针对上述状态转移过程,我们可以以状态为行,动作为列,构建一个关于(s,a)的reward值的矩阵R如下图,其中-1表示空值。
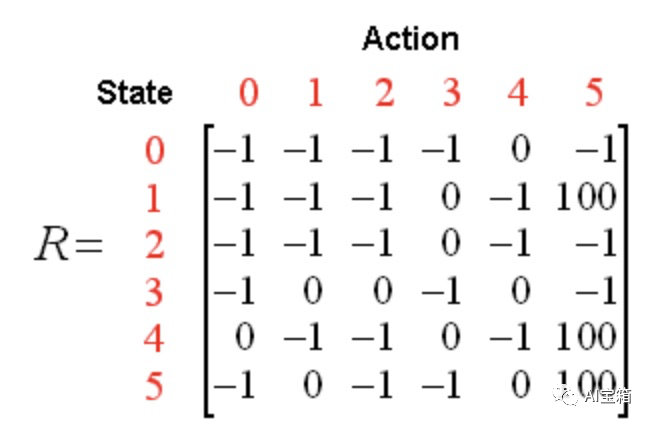
算法转移规则: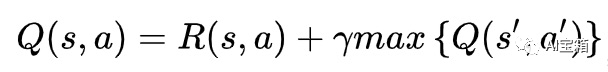 ,其中s,a表示当前的状态和动作, s',a' 表示下一个状态及行为,折扣系数
,其中s,a表示当前的状态和动作, s',a' 表示下一个状态及行为,折扣系数  。
。
ok,前期背景已经介绍妥当,我们手撕Q-learning。
首先,令折扣系数为 0.8 ,初始状态为房间1,并将Q初始化全零矩阵。初始化Q-table矩阵,全部置为0,如下:
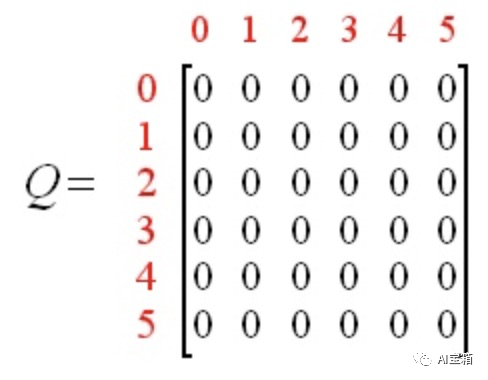
假设,我们随机选取state为房间1(state1),那么根据reward矩阵R可得:
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
到达目标状态,一次episode完成,Q表更新为:
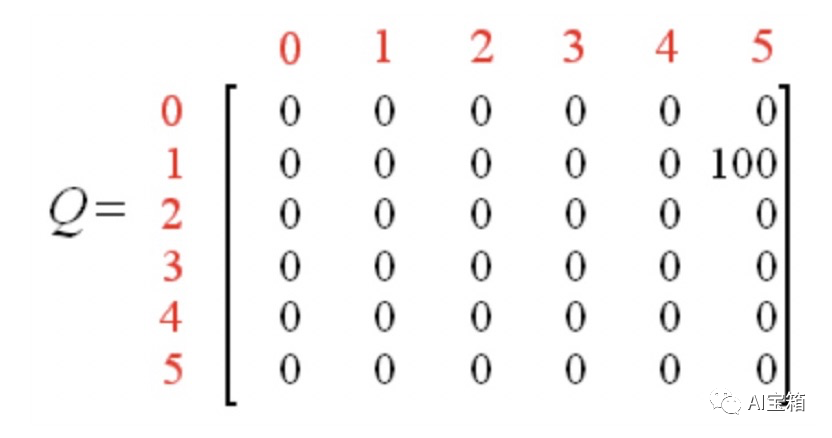
重新开始一次episod,本次我们随机选取房间为3(state3),那么根据reward矩阵R可得:
Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 3), Q(1, 5)] = 0 + 0.8 * Max(0, 100) = 80
Q表更新为,
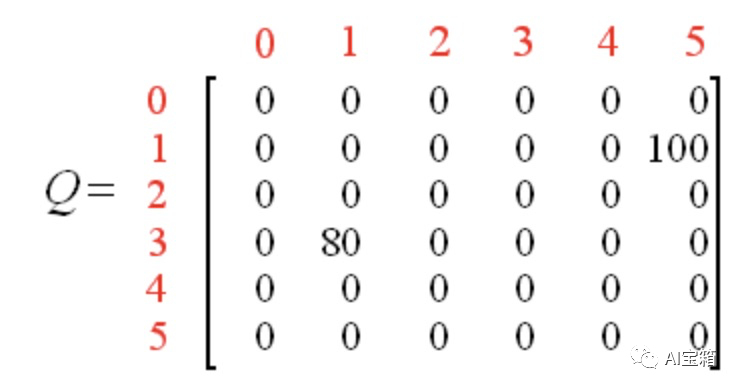
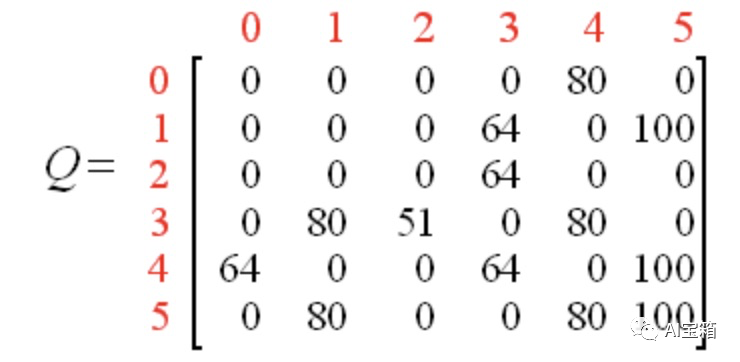
经过多个episode的多轮迭代,矩阵Q最终收敛成:

归一化后为:
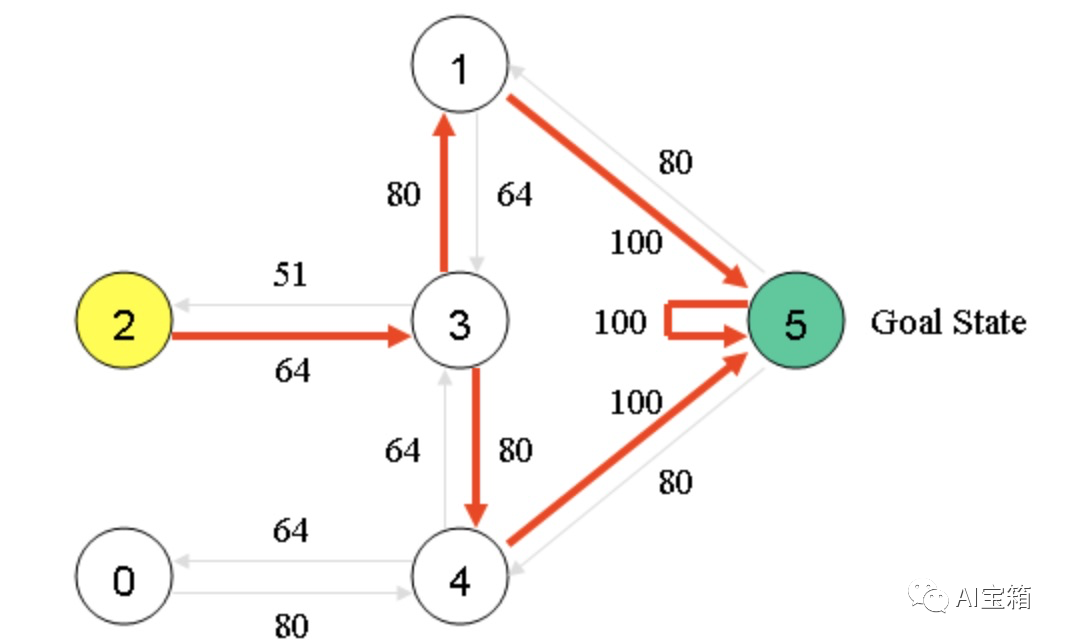
Q-Learning收敛后,Q-table中的Q值,便可以做为状态转移的最佳路径,如下图。
总结
综上,Q-Learning是一个基于时序差分(TD)的off-policy强化学习算法,本质就是这个公式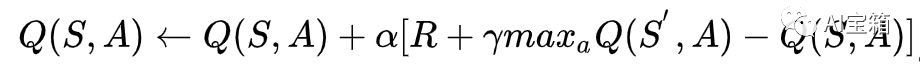 。
。
Q-Learning算法,简单容易理解,但它只能学习到样本中已有的(s, a)状态转移价值,也正是这个缺陷导致它无法在复杂空间下进行直接使用。所以,才有了大名鼎鼎的DQN,我们后续再逐步进行讲解。
据笔者了解,oCPX智能出价场景中,有些公司就曾采用了Q-Learning进行出价反馈的调节优化,感兴趣的话,大家可以想想如何去做。欢迎留言交流讨论。
References
1.强化学习(七)--Q-Learning和Sarsa https://zhuanlan.zhihu.com/p/46850008
2.http://mnemstudio.org/path-finding-q-learning-tutorial.htm
3.什么是Q-Learning https://zhuanlan.zhihu.com/p/24808797
最后
以上就是仁爱人生最近收集整理的关于qlearning算法_强化学习系列Q Learning的全部内容,更多相关qlearning算法_强化学习系列Q内容请搜索靠谱客的其他文章。








发表评论 取消回复