文章目录
- 值函数迭代算法
- Q函数迭代算法
- Why is this algorithm off-policy?
- What is fitted Q iteration optimizing?
- Online Q-learning algorithms
- Exploration with Q-learning
- The theory of algorithm
PG算法与AC算法本质上都是寻找策略梯度,只是AC算法同时使用了某种值函数来试图给出策略梯度的更好估计。但是策略梯度算法通常有非常高的方差,因此希望能够抛开策略梯度这一架构。
优势函数 A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) A^{pi}(s_t,a_t)=Q^{pi}(s_t,a_t)-V^{pi}(s_t) Aπ(st,at)=Qπ(st,at)−Vπ(st),指的是给定策略,在状态 s t s_t st下,采用了行动 a t a_t at能比该策略的平均情况期望今后收益多出多少。我们在演员-评论家算法里面花了很大力气去估计这个东西。假设我们在某个策略下已经知道这个函数,则在状态 S t S_t St下我们可以根据优势函数得到一个当前最好的决策 a t = arg max a t A π ( s t , a t ) a_t=arg max_{a_t}A^{pi}(s_t,a_t) at=argmaxatAπ(st,at)。由于 A π ( s t , a t ) A^{pi}(s_t,a_t) Aπ(st,at)与 Q π ( s t , a t ) Q^{pi}(s_t,a_t) Qπ(st,at)间只相差一个常数项 V π ( s t ) V^{pi}(s_t) Vπ(st),因此 arg max a t A π ( s t , a t ) = arg max a t Q π ( s t , a t ) arg max_{a_t}A^{pi}(s_t,a_t)=arg max_{a_t}Q^{pi}(s_t,a_t) argmaxatAπ(st,at)=argmaxatQπ(st,at)。需要注意的是这是一个确定性策略。
值函数迭代算法
我们知道策略迭代的步骤可以写成:
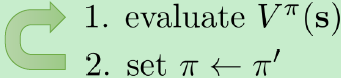
价值迭代的步骤可以写成:
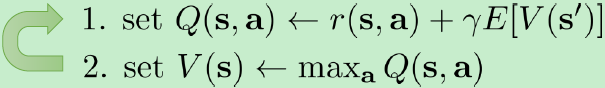
现在我们引入一个参数为
ϕ
phi
ϕ的神经网络来拟合价值函数
V
:
S
→
V: S rightarrow
V:S→
R
mathbb{R}
R,定义损失函数为
L
(
ϕ
)
=
1
2
∣
∣
V
ϕ
(
s
)
−
max
a
Q
π
(
s
,
a
)
∣
∣
2
L(phi)=frac{1}{2}||V_{phi}(s)-max_aQ^{pi}(s,a)||^2
L(ϕ)=21∣∣Vϕ(s)−maxaQπ(s,a)∣∣2。从而上述价值迭代法可以改写为以下的拟合值函数迭代算法 (Fitted Value Iteration):
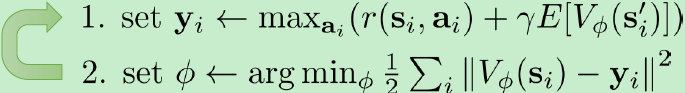
上述步骤中第一步与Critic一样计算出一个目标,第二步使用梯度下降方法更新网络参数。然而事实上,第一步的这个max操作是非常难做的:一个最大的问题是我们假设我们已经知道了系统的转移概率(不知道执行动作
a
i
a_i
ai有多大概率能够转移到状态
s
i
′
s_i'
si′)!要做这个max,我们必须知道每一个不同行动的结果(reward)。我们用一些无模型的增强学习,可能可以执行很多操作来看结果,但状态往往不能回撤复原以尝试其他的选项,第一步的max要求我们尝试各种不同的操作来看结果。
Q函数迭代算法
为了避免这么强的假设,我们使用
Q
π
(
s
,
a
)
←
Q^{pi}(s,a)leftarrow
Qπ(s,a)←
r
(
s
,
a
)
+
γ
E
s
′
∼
p
(
s
′
∣
s
,
a
)
[
Q
π
(
s
′
,
π
(
s
′
)
)
]
r(s,a)+gamma E_{s'sim p(s'|s,a)}[Q^{pi}(s',pi (s'))]
r(s,a)+γEs′∼p(s′∣s,a)[Qπ(s′,π(s′))]更新
Q
Q
Q。上式可以使用样本进行拟合。因此,只要有Q函数,一切就可以在不知道系统转移概率的情况下运转起来。进一步,我们也考虑将Q函数使用诸如神经网络的结构来近似,得到拟合Q函数迭代算法 (Fitted Q-Iteration):
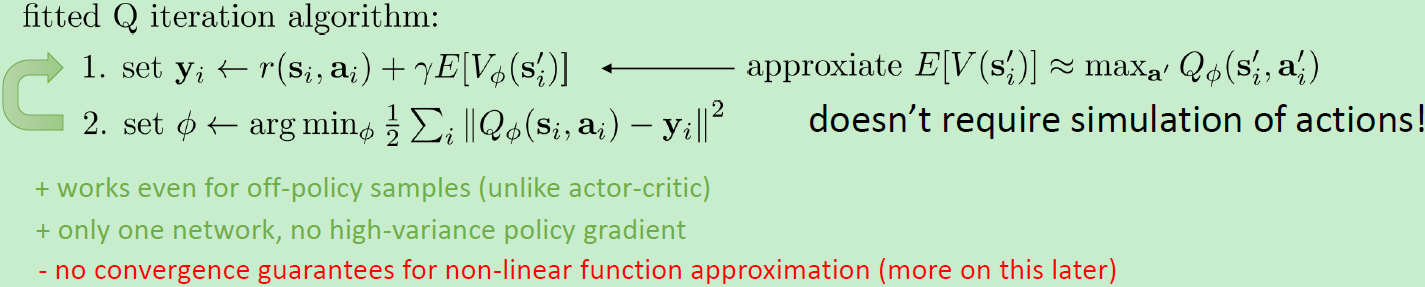
可以发现,这样的决策算法的根本好处在于不需要去同一状态尝试不同的行动选项,因为Q函数已经告诉你不同行动的效果了。此外,我们这样的两步算法有很大的优点:
- 算法中只需要用到很多 ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′)的一步转移样本,而这些样本是可以off-policy的,这个在AC算法中是不通用的;
- 这个算法只用到一个网络,没有用到策略梯度,因此也没有高方差的问题。
但是,这个算法的致命缺点是,对于这样的非线性函数拟合机制下的算法,没有任何收敛性保证。
完整的Q函数迭代算法框架如下:

Why is this algorithm off-policy?
- 奖励 r ( s i , a i ) r(s_i,a_i) r(si,ai)在给定状态和行为的情况下与当前策略无关;
- max a i ′ Q ϕ ( s i ′ , a i ′ ) max_{a_i'}Q_{phi}(s_i',a_i') maxai′Qϕ(si′,ai′)只需对决策空间进行枚举。
即上式第一步需要依据一定策略产生数据,但第二部第三步都不需要策略。
What is fitted Q iteration optimizing?
上式第三步实际是在最小化Bellman误差(期望误差),当误差为0时其为确定最优Q函数的Bellman方程,对应了最优策略
π
′
pi'
π′。
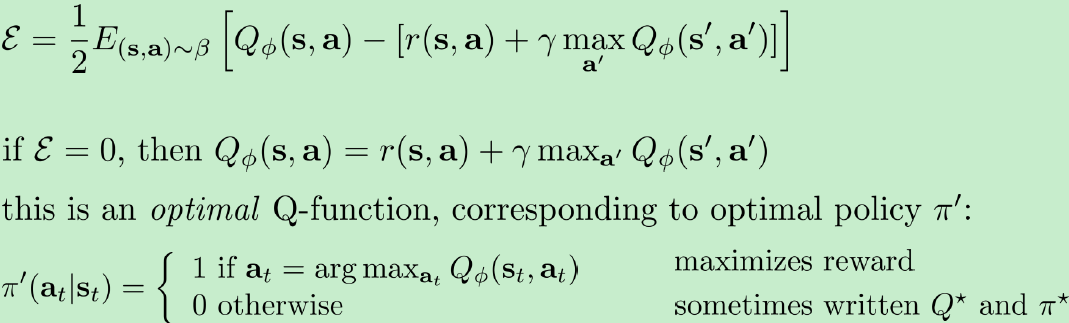
尽管算法是off-policy的,但需尽可能确保收集的数据中包含了真正运行时会访问到的那些状态和行动。此外,如果我们使用诸如神经网络去近似拟合Q函数表,那么之前所说的大量理论保证将丧失。
Online Q-learning algorithms
在之前的拟合Q函数迭代算法中,我们收集大量数据,然后反复做样本-做回归。我们把每次收集的样本数设为1,然后把K设为1,并且设置只走一个梯度步,就变成了在线Q迭代算法 (Online Q-iteration),循环以下三步(第三步公式为对损失函数求导得到)。

Exploration with Q-learning
第一步的支撑集希望足够大。那么如何选择行动呢?我们最终的行动服从一个单点分布,选择一个使得Q最大的行动。但是如果我们把这个东西直接搬过来在学习过程中使用的话,是不好的。事实上,这是在线学习中的一个很纠结的问题:探索 (exploration) 和开发 (exploitation)。学习就是一个探索的过程,如果我们还没进行足够的探索,在Q函数还不够准确的时候,我们根本无法分别出到底哪个是真正好的,会忽略掉真正优秀的方案。在在线学习中,有多种启发式方法来脱离这一局面。如生成数据的时候使用 ϵ − epsilon- ϵ−贪心策略。
The theory of algorithm
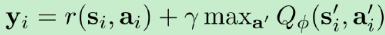
上式是在无穷维进行收缩映射,而下式是在二维空间进行收缩映射,其组合并不是一个收缩映射,因为收缩的维度不同。
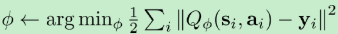
下图是一个该算法发散的例子。假设最优解
V
∗
V^*
V∗在那个五角星处,然后我们从
V
V
V开始一脚走到了
B
V
BV
BV,然后被投影回归扯回了
V
′
V'
V′。从图上看,我们的解到最优解的距离越来越远了。注意到,不用无穷模的原因是当状态空间很大或者无限的情况下,无穷模下的投影问题极其难解。我们只能寻求找到最优解的一个投影(同样对于策略梯度法我们也只能期望找到最优策略的一个投影),但是事与愿违的是,反复进行拟合值函数迭代算法,可能使你从较好的解开始越来越差。
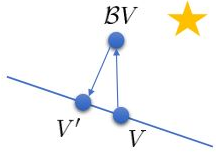
因此我们的结论是,值函数迭代法在表格中是收敛的,但是拟合值函数迭代法在一般意义下是不收敛的,在实践中也通常不收敛,但是有一些方法来缓解这些问题。
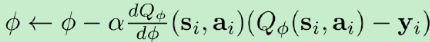
上式看起来在走一个梯度步,我们看似抓住了一个救命稻草:梯度下降法应该是可以收敛的?但是,Q函数方法的梯度并不是目标函数的梯度,因此与策略梯度法并不同,它并不是梯度下降法。
这个不收敛结论同样也适用于演员-评论家算法,拟合下的自助法做的策略评估同样不具有收敛性。
最后
以上就是完美台灯最近收集整理的关于CS294(7) 基于值函数的方法(总结版)的全部内容,更多相关CS294(7)内容请搜索靠谱客的其他文章。








发表评论 取消回复