“对于 RabbitMQ 的节点来说,有单节点模式和集群模式两种,其中集群模式又分为普通集群模式和镜像队列集群模式,而镜像队列集群模式的搭建步骤和普通集群模式是基本相同的,唯一不同的是,镜像队列集群模式,多了一步配置 policy 的步骤。本文主要介绍镜像队列的原理及实现。
”
1. 创建镜像队列模式
注意,到此步骤,我们假设是你已经创建好了 RabbitMQ 集群。
1.1 增加镜像队列的 Policy
打开你的 RabbitMQ 管理首页,在 Admin->Policy 链接下开始创建 Policy:
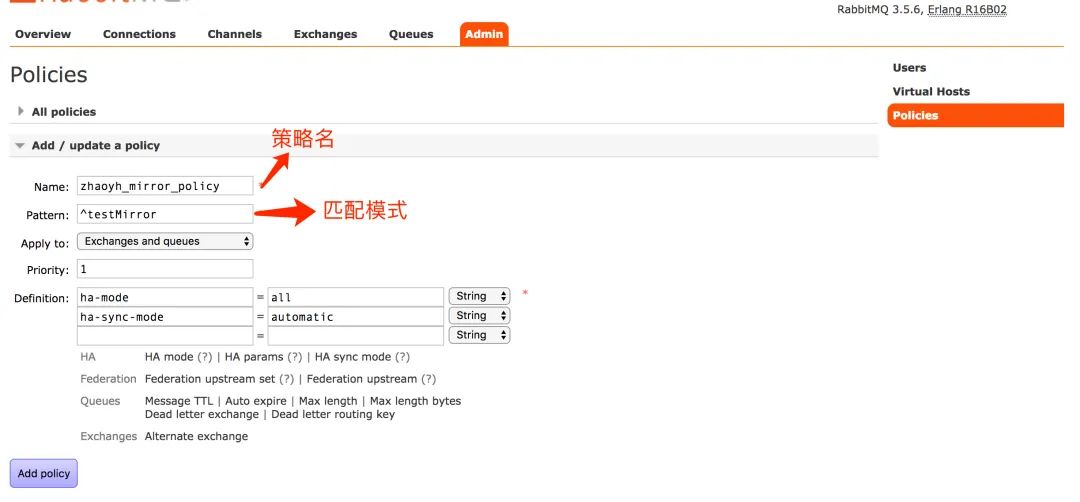
Name: 你配置的 Policy 名称;
Pattern: 匹配模式,图片的是匹配 testMirror 开头的交换机和队列;
Priority: 优先级;
Definition: 一些模式的定义,RabbitMQ 已经列出了以下常见的模式定义。ha-mode 是指定镜像队列的模式,有效值为 all/exactly/nodes。其中 all 表示在集群中所有的节点上进行镜像;exactly 表示在指定个数的节点上进行镜像,节点的个数由 ha-params 指定;nodes 表示在指定的节点上进行镜像,节点名称通过 ha-params 指定。ha-sync-mode 为指定镜像队列中消息的同步方式,有效值为 automatic(自动同步),manually(手动同步);默认是 manually,请注意一定要记得设置为 automatic(自动同步),否则消息在镜像队列中是不会自动同步的(即普通集群模式),即新节点加入时不会自动同步消息和元数据,只能通过命令手动去同步。
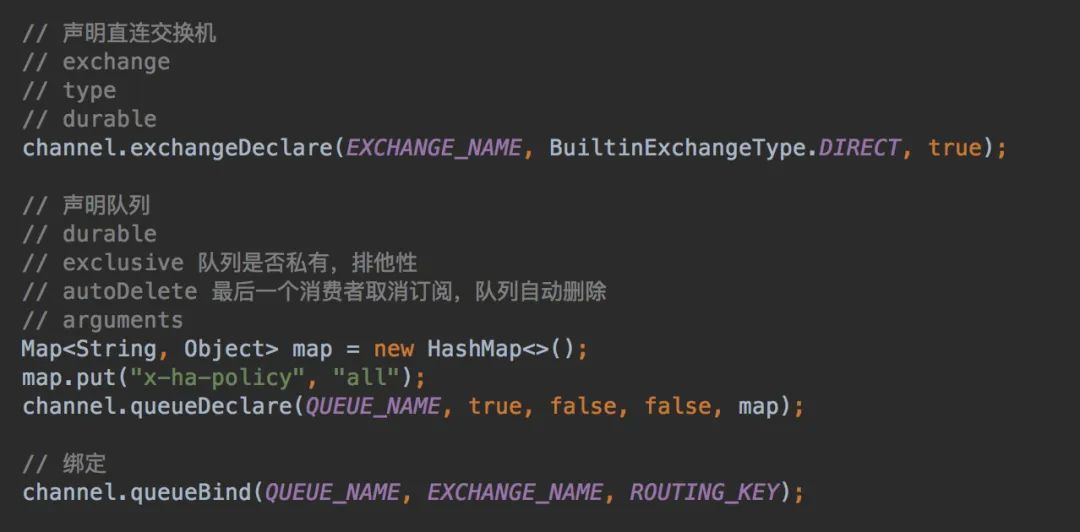
1.2 代码声明交换机、队列、绑定等
1.3 查看镜像队列是否声明成功
查看你刚声明的队列的详情:
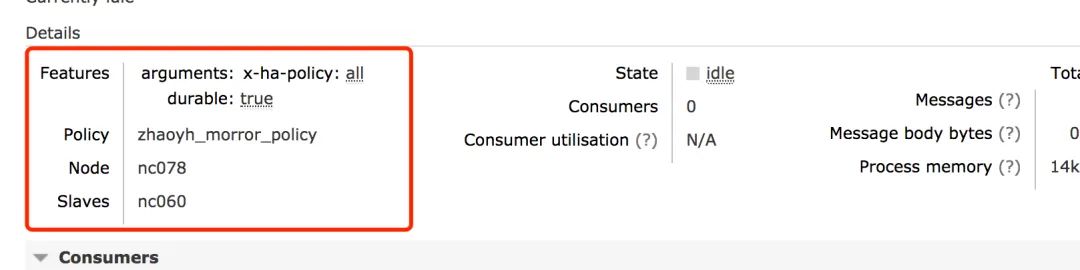
可以看到,ha-mode、node、salve 等属性都已经创建成功。
2. 镜像队列说明
2.1 关于 node 节点
queue 有 master 节点和 slave 节点。要强调的是,在 RabbitMQ 中 master 和 slave 是针对一个 queue 而言的,而不是一个 node 作为所有 queue 的 master,其它 node 作为 slave。一个 queue 第一次创建的 node 为它的 master 节点,其它 node 为 slave 节点。
2.2 镜像队列服务提供方式
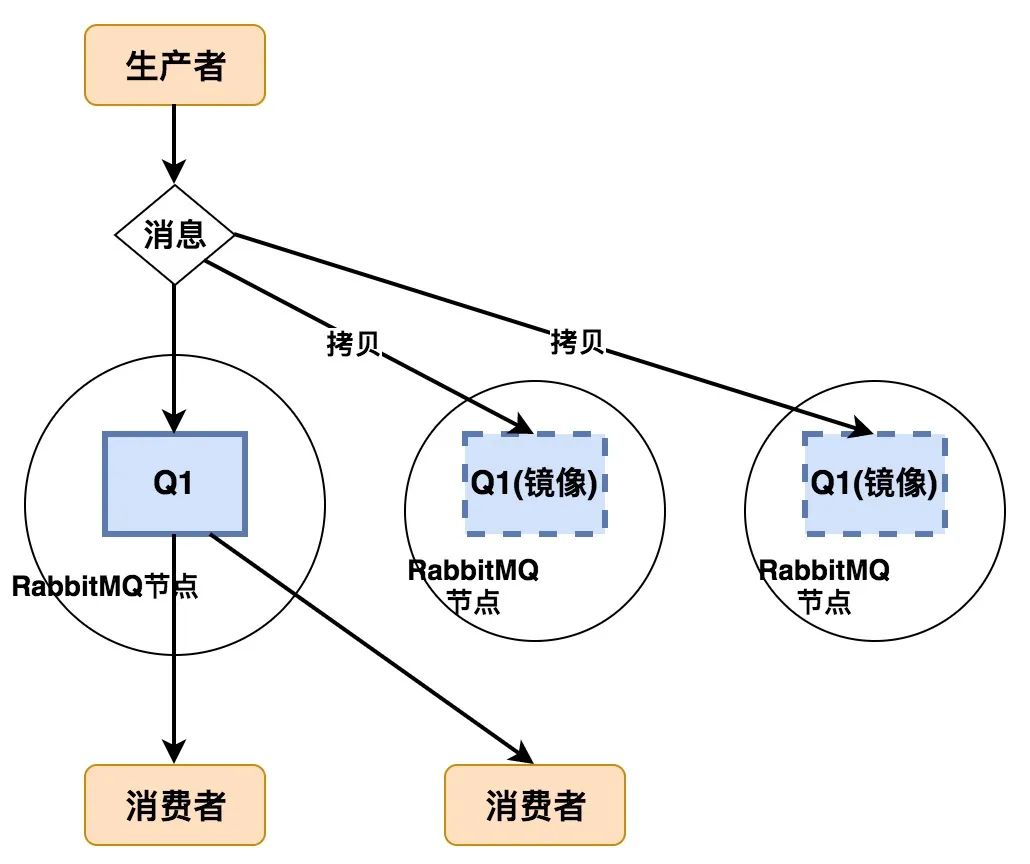
如上图所示,在镜像队列集群模式中,对某个 queue 来说,只有 master 对外提供服务,而其他 slave 只提供备份服务,在 master 所在节点不可用时,选出一个 slave 作为新的 master 继续对外提供服务。
无论客户端的请求打到 master 还是 slave 最终数据都是从 master 节点获取。当请求打到 master 节点时,master 节点直接将消息返回给 client,同时 master 节点会通过 GM(Guaranteed Multicast)协议将 queue 的最新状态广播到 slave 节点。GM 保证了广播消息的原子性,即要么都更新要么都不更新。
当请求打到 slave 节点时,slave 节点需要将请求先重定向到 master 节点,master 节点将将消息返回给 client,同时 master 节点会通过 GM 协议将 queue 的最新状态广播到 slave 节点。
所以,多个客户端连接不同的镜像队列不会产生同一 message 被多次接受的情况。
2.3 RabbitMQ 集群处理新增节点
如果有新节点加入,RabbitMQ 不会同步之前的历史数据,新节点只会复制该节点加入到集群之后新增的消息。既然 master 节点退出集群会选一个 slave 作为 master,那么如果不幸选中了一个刚刚加入集群的节点怎么办?那消息不就丢了吗?这里您可以把心放到肚子里,RabbitMQ 集群内部会维护节点的状态是否已经同步,使用 rabbitmqctl 的 synchronised_slave_pids 参数,就可以查看状态。如果 slave_pids 和 synchronised_slave_pids 里面的节点是一致的,那说明全都同步了;如果不一致很容易比较出来哪些还没有同步,集群只会在 “最老” 的 slave 节点之间选一个出来作为新的 master 节点。另外对于 node 节点的重启也是按照新节点来处理的。
2.4 镜像队列注意点
镜像队列不能作为负载均衡使用,因为每个声明和消息操作都要在所有节点复制一遍。
ha-mode 参数和 durable declare 对 exclusive 队列都不生效,因为 exclusive 队列是连接独占的,当连接断开,队列自动删除。所以实际上这两个参数对 exclusive 队列没有意义。
每当一个节点加入或者重新加入 (例如从网络分区中恢复回来) 镜像队列,之前保存的队列内容会被清空。
对于镜像队列,客户端 basic.publish 操作会同步到所有节点;而其他操作则是通过 master 中转,再由 master 将操作作用于 salve。比如一个 basic.get 操作,假如客户端与 slave 建立了 TCP 连接,首先是 slave 将 basic.get 请求发送至 master,由 master 备好数据,返回至 slave,投递给消费者。
2.5 镜像队列的故障恢复
假设两个节点 (A 和 B) 组成一个镜像队列。
场景 1:A 先停,B 后停。该场景下 B 是 master(disk 节点,A 是 ram),只要先启动 B,再启动 A 即可。或者先启动 A,再在 30 秒之内启动 B 即可恢复镜像队列。
场景 2: A, B 同时停。该场景可能是由掉电等原因造成,只需在 30 秒之内连续启动 A 和 B 即可恢复镜像队列。
场景 3:A 先停,B 后停,且 A 无法恢复。该场景是场景 1 的加强版,因为 B 是 master,所以等 B 起来后,在 B 节点上调用 rabbitmqctl forget_cluster_node A,解除与 A 的 cluster 关系,再将新的 slave 节点加入 B 即可重新恢复镜像队列。
场景 4:A 先停,B 后停,且 B 无法恢复。该场景是场景 3 的加强版,比较难处理,早在 3.1.x 时代之前貌似都没什么好的解决方法,但是现在已经有解决方法了,在 3.4.2 版本亲测有效(我们当前使用的是 3.3.5)。因为 B 是 master,所以直接启动 A 是不行的,当 A 无法启动时,也就没办法在 A 节点上调用 rabbitmqctl forget_cluster_node B 了。新版本中,forget_cluster_node 支持–offline 参数,offline 参数允许 rabbitmqctl 在离线节点上执行 forget_cluster_node 命令,迫使 RabbitMQ 在未启动的 slave 节点中选择一个作为 master。当在 A 节点执行 rabbitmqctl forget_cluster_node –offline B 时,RabbitMQ 会 mock 一个节点代表 A,执行 forget_cluster_node 命令将 B 剔出 cluster,然后 A 就能正常启动了。最后将新的 slave 节点加入 A 即可重新恢复镜像队列。
场景 5: A 先停,B 后停,且 A、B 均无法恢复,但是能得到 A 或 B 的磁盘文件。该场景是场景 4 的加强版,更加难处理。将 A 或 B 的数据库文件 (默认在 $RABBIT_HOME/var/lib 目录中) 拷贝至新节点 C 的目录下,再将 C 的 hostname 改成 A 或 B 的 hostname。如果拷过来的是 A 节点磁盘文件,按场景 4 处理方式;如果拷过来的是 B 节点磁盘文件,按场景 3 处理方式。最后将新的 slave 节点加入 C 即可重新恢复镜像队列。
场景 6:A 先停,B 后停,且 A、B 均无法恢复,且无法得到 A 或 B 的磁盘文件。洗洗睡吧,该场景下已无法恢复 A、B 队列中的内容了。
作者:zhaoyh
来源链接:
http://zhaoyh.com.cn/2018/10/16/RabbitMQ%E9%95%9C%E5%83%8F%E9%98%9F%E5%88%97%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90/#more

最后
以上就是辛勤小土豆最近收集整理的关于RabbitMQ 镜像队列原理分析1. 创建镜像队列模式2. 镜像队列说明的全部内容,更多相关RabbitMQ内容请搜索靠谱客的其他文章。








发表评论 取消回复