")
关于卷积神经网络CNN,网络和文献中有非常多的资料,我在工作/研究中也用了好一段时间各种常见的model了,就想着简单整理一下,以备查阅之需。如果读者是初接触CNN,建议可以先看一看“Deep Learning(深度学习)学习笔记整理系列”中关于CNN的介绍[1],是介绍我们常说的Lenet为例,相信会对初学者有帮助。
- Lenet,1986年
- Alexnet,2012年
- GoogleNet,2014年
- VGG,2014年
- Deep Residual Learning,2015年
Lenet
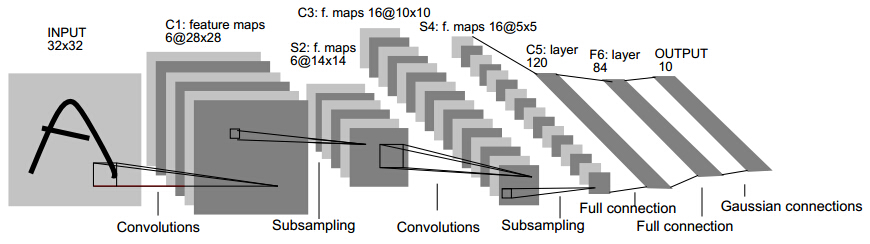
就从Lenet说起,可以看下caffe中lenet的配置文件(点我),可以试着理解每一层的大小,和各种参数。由两个卷积层,两个池化层,以及两个全连接层组成。 卷积都是5*5的模板,stride=1,池化都是MAX。下图是一个类似的结构,可以帮助理解层次结构(和caffe不完全一致,不过基本上差不多)
Alexnet
2012年,Imagenet比赛冠军的model——Alexnet [2](以第一作者alex命名)。caffe的model文件在这里。说实话,这个model的意义比后面那些model都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,确实让CNN和GPU都大火了一把,顺便推动了有监督DL的发展。
模型结构见下图,别看只有寥寥八层(不算input层),但是它有60M以上的参数总量,事实上在参数量上比后面的网络都大。
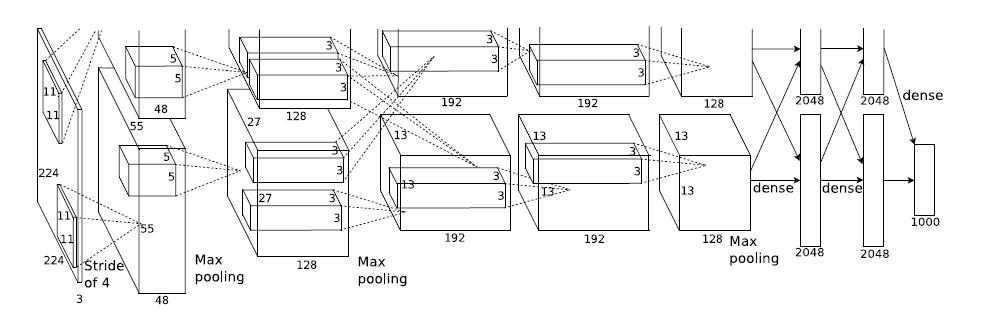
这个图有点点特殊的地方是卷积部分都是画成上下两块,意思是说吧这一层计算出来的feature map分开,但是前一层用到的数据要看连接的虚线,如图中input层之后的第一层第二层之间的虚线是分开的,是说二层上面的128map是由一层上面的48map计算的,下面同理;而第三层前面的虚线是完全交叉的,就是说每一个192map都是由前面的128+128=256map同时计算得到的。
Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理。下面是我画的示意图:
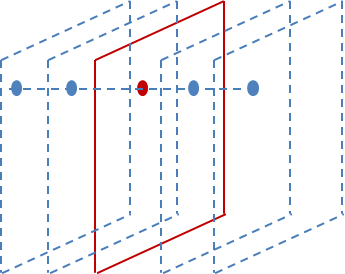
前后几层(对应位置的点)对中间这一层做一下平滑约束,计算方法是:
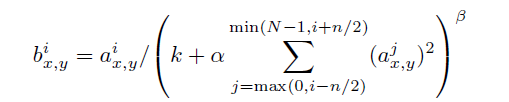
具体打开Alexnet的每一阶段(含一次卷积主要计算)来看[2][3]:
(1)con - relu - pooling - LRN

具体计算都在图里面写了,要注意的是input层是227*227,而不是paper里面的224*224,这里可以算一下,主要是227可以整除后面的conv1计算,224不整除。如果一定要用224可以通过自动补边实现,不过在input就补边感觉没有意义,补得也是0。
(2)conv - relu - pool - LRN
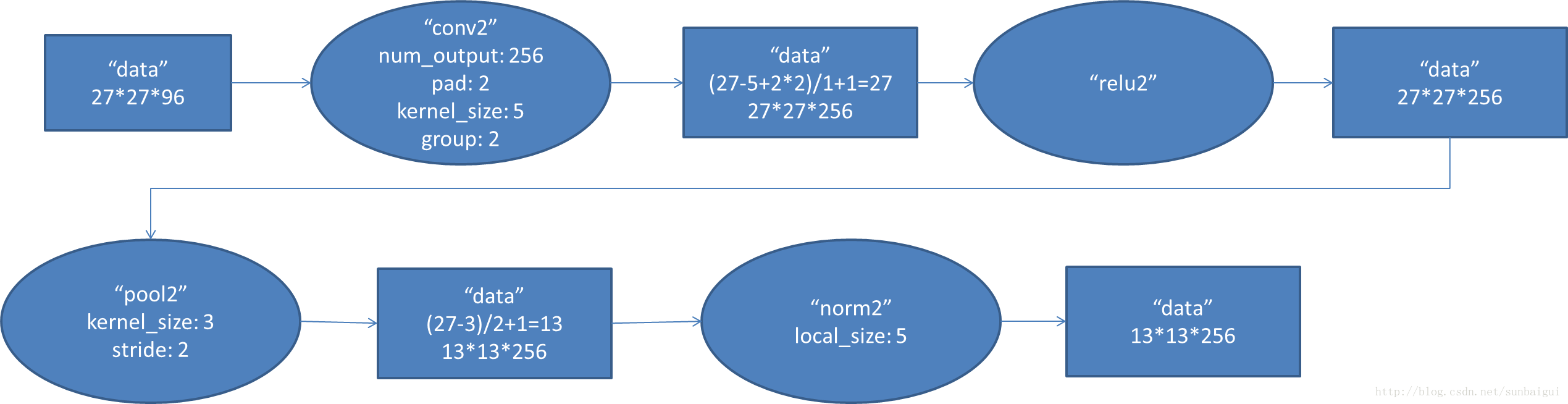
和上面基本一样,唯独需要注意的是group=2,这个属性强行把前面结果的feature map分开,卷积部分分成两部分做。
(3)conv - relu

(4)conv-relu

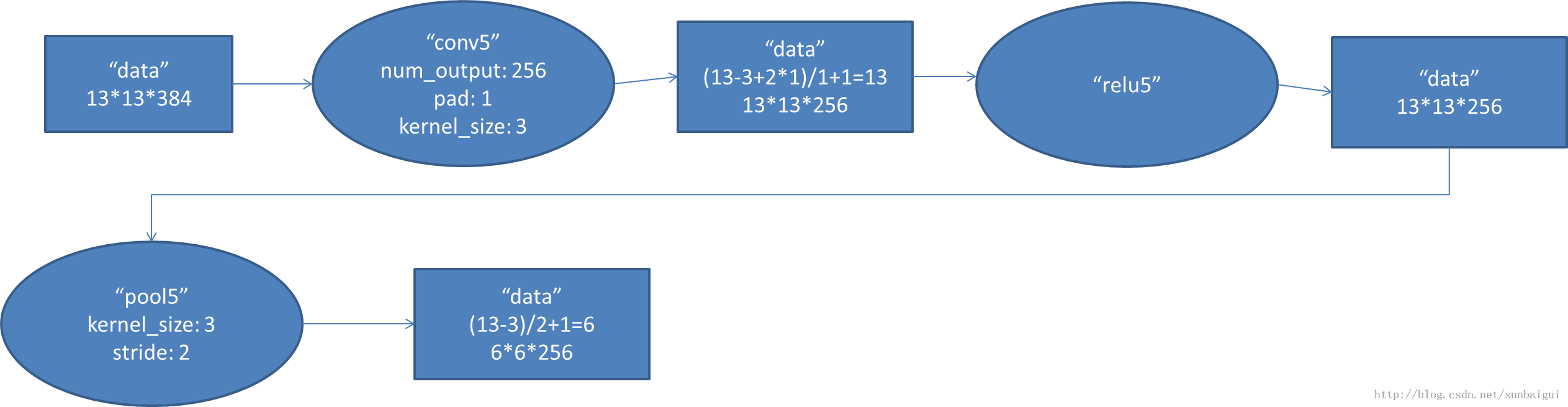
(5)conv - relu - pool
(6)fc - relu - dropout
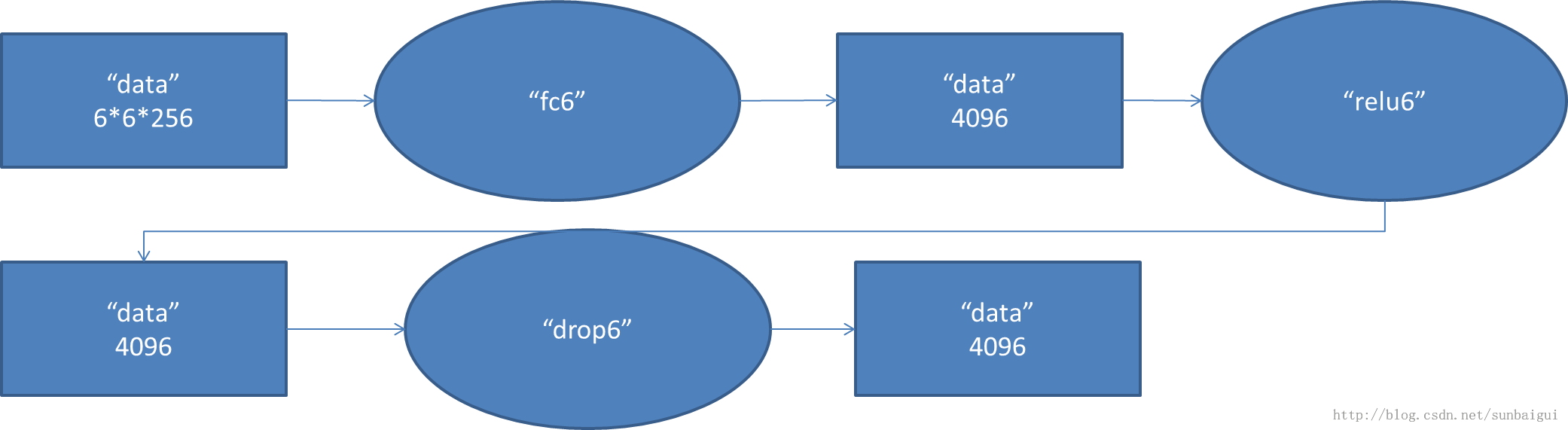
这里有一层特殊的dropout层,在alexnet中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。
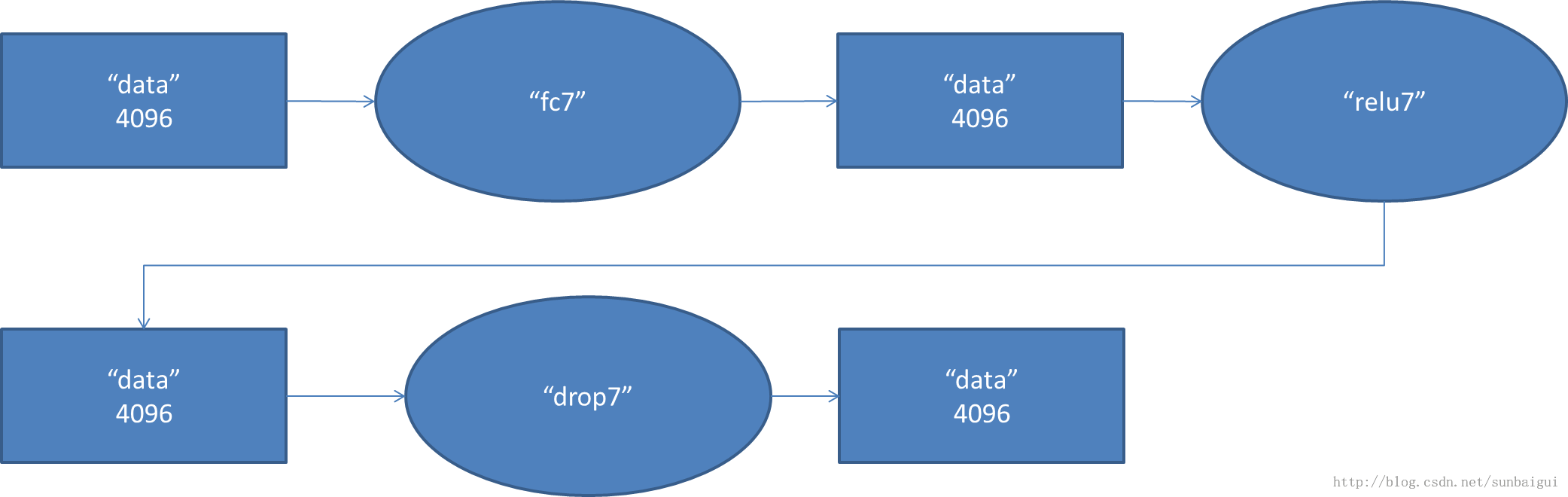
(7)
fc - relu - dropout
(8)fc - softmax

以上图借用[3],感谢。
GoogleNet
googlenet[4][5],14年比赛冠军的model,这个model证明了一件事:用更多的卷积,更深的层次可以得到更好的结构。(当然,它并没有证明浅的层次不能达到这样的效果)
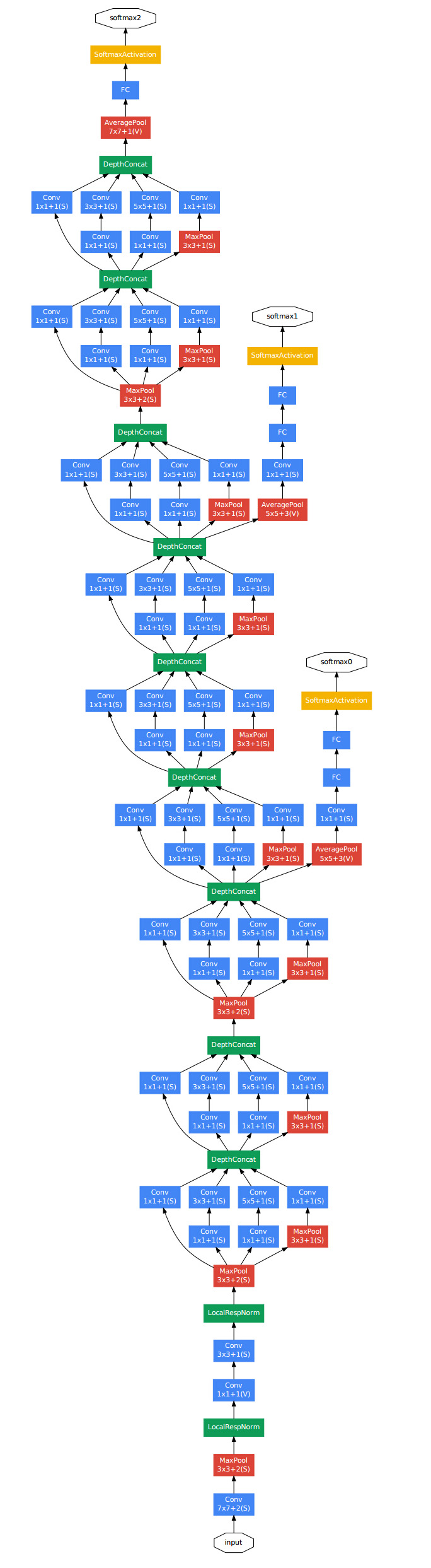
这个model基本上构成部件和alexnet差不多,不过中间有好几个inception的结构:
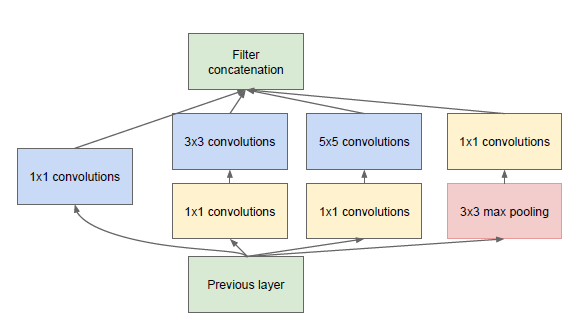
是说一分四,然后做一些不同大小的卷积,之后再堆叠feature map。
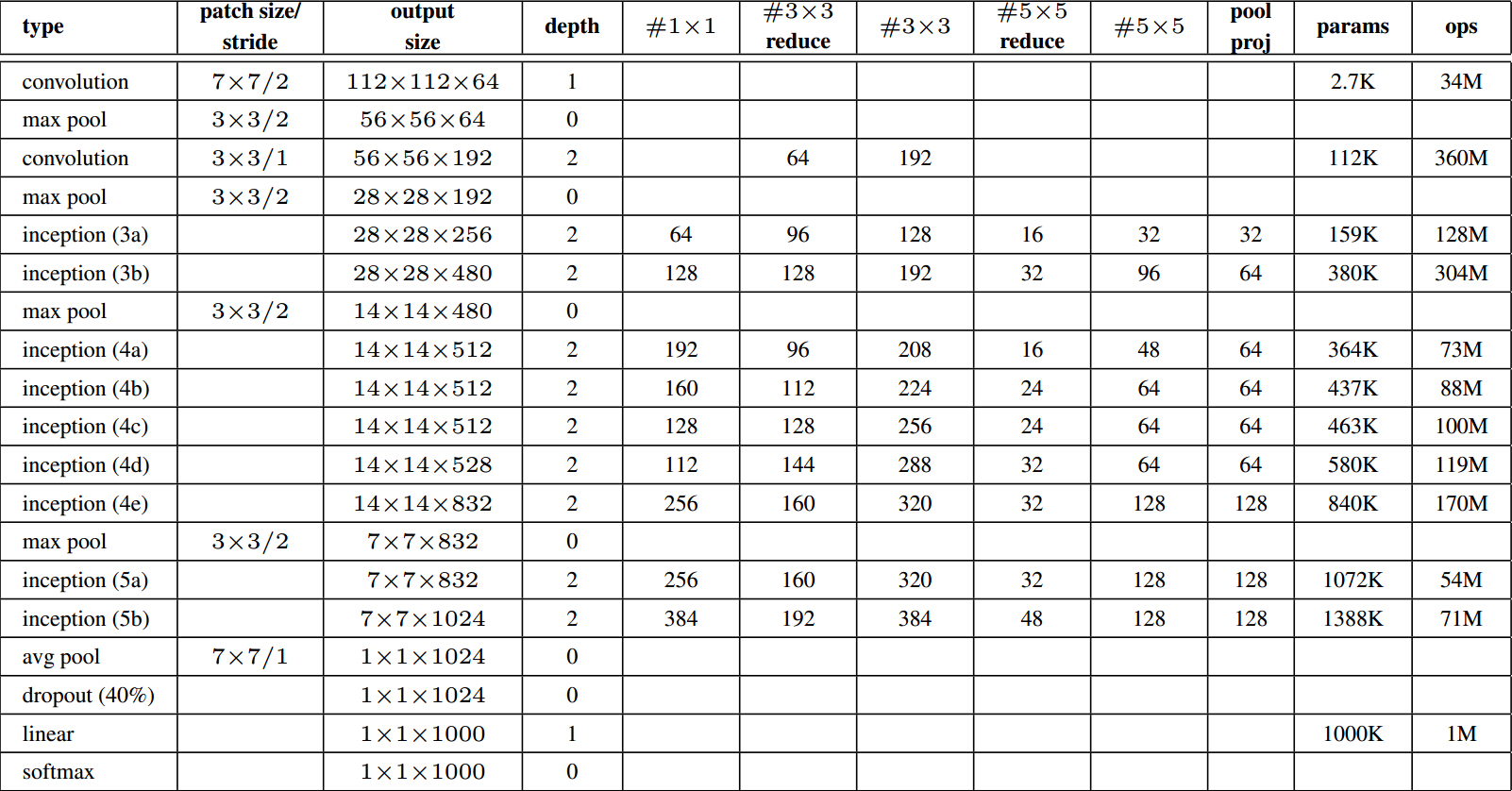
计算量如下图,可以看到参数总量并不大,但是计算次数是非常大的。
VGG
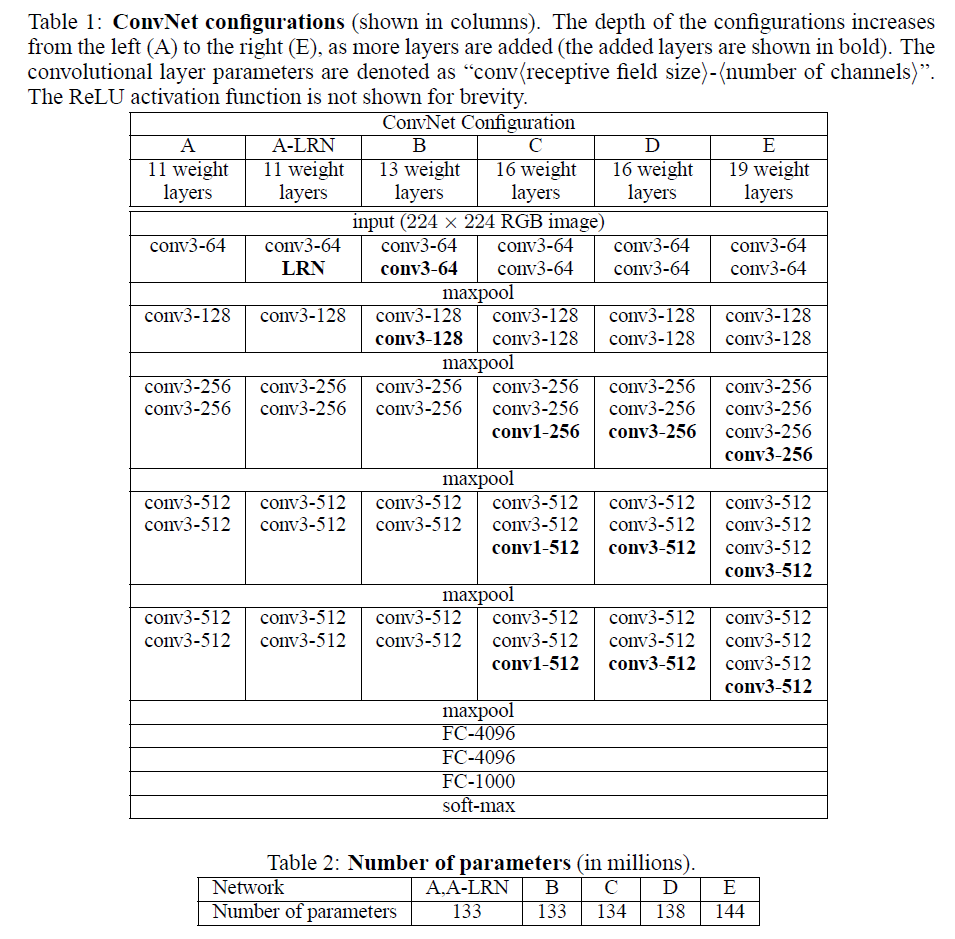
VGG有很多个版本,也算是比较稳定和经典的model。它的特点也是连续conv多,计算量巨大(比前面几个都大很多)。具体的model结构可以参考[6],这里给一个简图。基本上组成构建就是前面alexnet用到的。
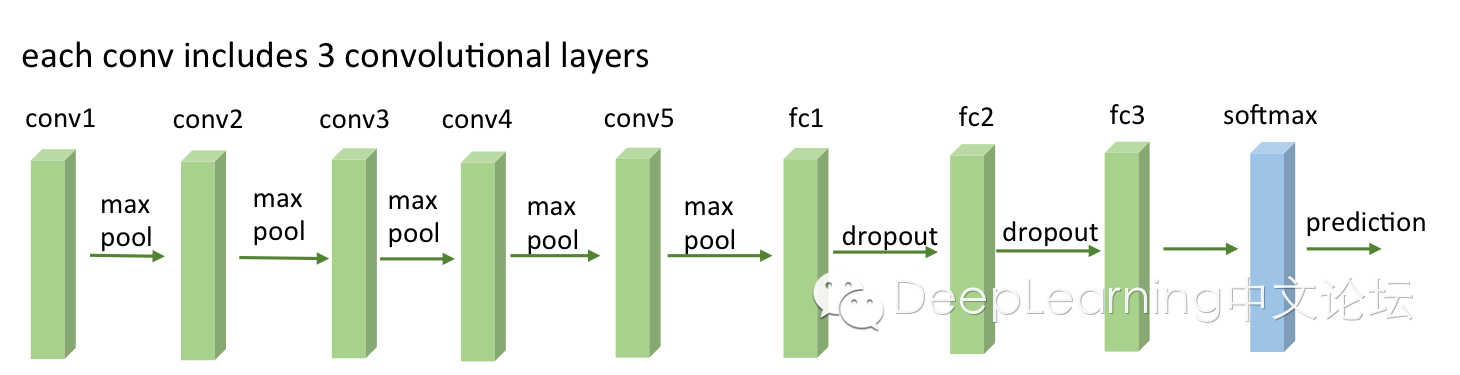
下面是几个model的具体结构,可以查阅,很容易看懂。
Deep Residual Learning
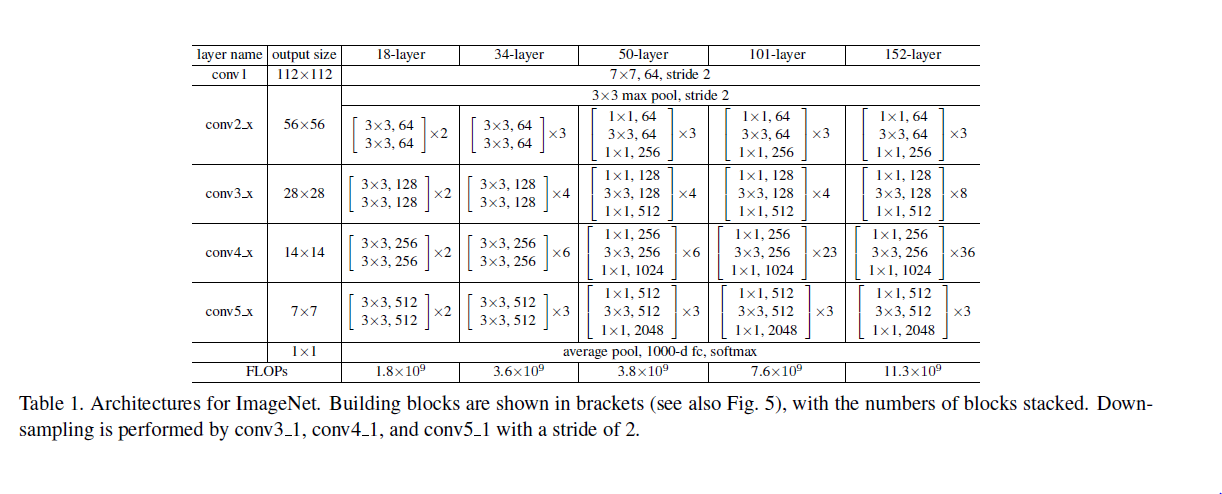
这个model是2015年底最新给出的,也是15年的imagenet比赛冠军。可以说是进一步将conv进行到底,其特殊之处在于设计了“bottleneck”形式的block(有跨越几层的直连)。最深的model采用的152层!!下面是一个34层的例子,更深的model见表格。

其实这个model构成上更加简单,连LRN这样的layer都没有了。
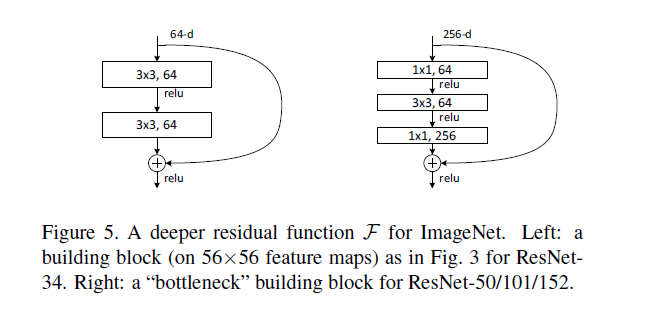
block的构成见下图:
总结
OK,到这里把常见的最新的几个model都介绍完了,可以看到,目前cnn model的设计思路基本上朝着深度的网络以及更多的卷积计算方向发展。虽然有点暴力,但是效果上确实是提升了。当然,我认为以后会出现更优秀的model,方向应该不是更深,而是简化。是时候动一动卷积计算的形式了。
参考资料
[1]
[2] ImageNet Classification with Deep Convolutional Neural Networks
[3]
[4]
[5] Going deeper with convolutions
[6] VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
最后
以上就是甜美枫叶最近收集整理的关于Alexnet VGG GoogleNet ResNet的全部内容,更多相关Alexnet内容请搜索靠谱客的其他文章。

![[深度学习]AlexNet和VGG论文笔记AlexNetVGGNetAlexNet 和 VGGNet的对比](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)






发表评论 取消回复