阅读本文需要xx分钟 ?
前言
本文用于记录学习SSD目标检测的过程,并且总结一些精华知识点。
为什么要学习SSD,是因为SSD和YOLO一样,都是one-stage的经典构架,我们必须对其理解非常深刻才能举一反三设计出更加优秀的框架。SSD这个目标检测网络全称为Single Shot MultiBox Detector,重点在MultBox上,这个思想很好地利用了多尺度的优势,全面提升了检测精度,之后的YOLOv2就借鉴了SSD这方面的思路才慢慢发展起来。
强烈建议阅读官方的论文去好好理解一下SSD的原理以及设计思路。这里也提供了相关的pdf:http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf
当然也有很多好的博客对其进行了介绍,在本文的最下方会有相关链接。本篇文章主要为自己的笔记,其中加了一些自己的思考。
网络构架
SSD的原始网络构架建议还是以论文为准,毕竟平时我们接触到的都是各种魔改版(也就是所谓的换了backbone,例如最常见的SSD-mobilenetv2),虽然与原版大同小异,不过对于理解来说,会增大我们理解的难度,因此,完全有必要看一遍原始的论文描述。
SSD在论文中是采取的VGG网络作为主干结构,但是去除了VGG中的最后几层(也就是我们经常说的分类层),随后添加了一些新的内容(在原文中叫做auxiliary structure),这些层分别是:
- 额外的特征提取层(Extra Feature Layers),作用就是和原本
backbone的层相结合共同提取出不同尺寸的特征信息,相当于加强了之前的backbone,使其网络更深,提取能力更加强大。 - 分类层(classification headers),对之前网络中的不同位置网络层输出的特征层(不同尺度),进行卷积得出每个特征图中每个坐标对应的分类信息(每个坐标对应着许多default boxes)。
- 坐标位置回归层(regression hearders),结构与分类层相仿,只是输出的通道略有不同,通过对不同尺度的特征图进行卷积,输出的是每个特征图中每个坐标对应的default boxes的偏移坐标(文章中称为shape offset)。
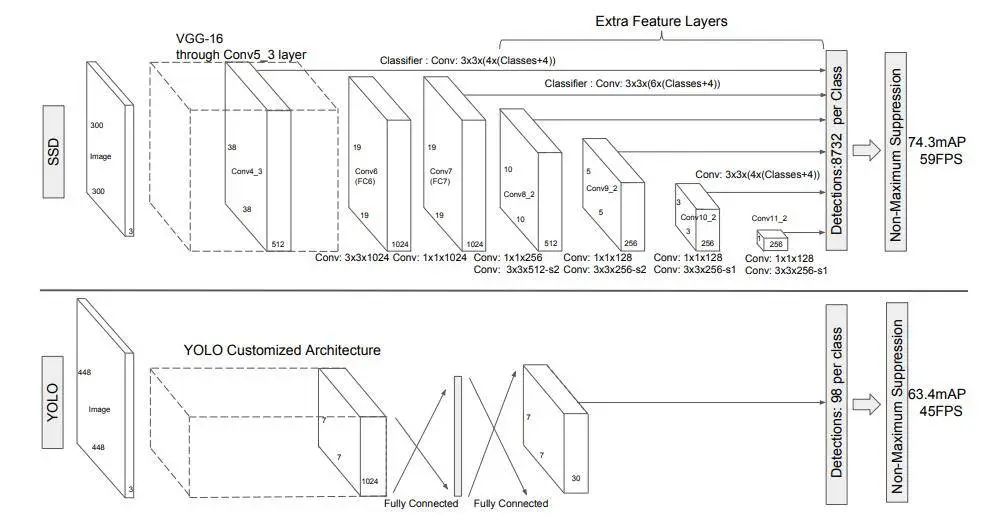
总体来说,SSD网络结构其实有四部分组成,backbone部分、额外添加的特征提取层、分类层以及坐标位置回归层。注意当初这篇SSD是出于Yolo一代之后二代之前,Yolo二代三代中不同尺度的特征图思想是有借鉴于SSD的。
用于检测的多尺度特征图
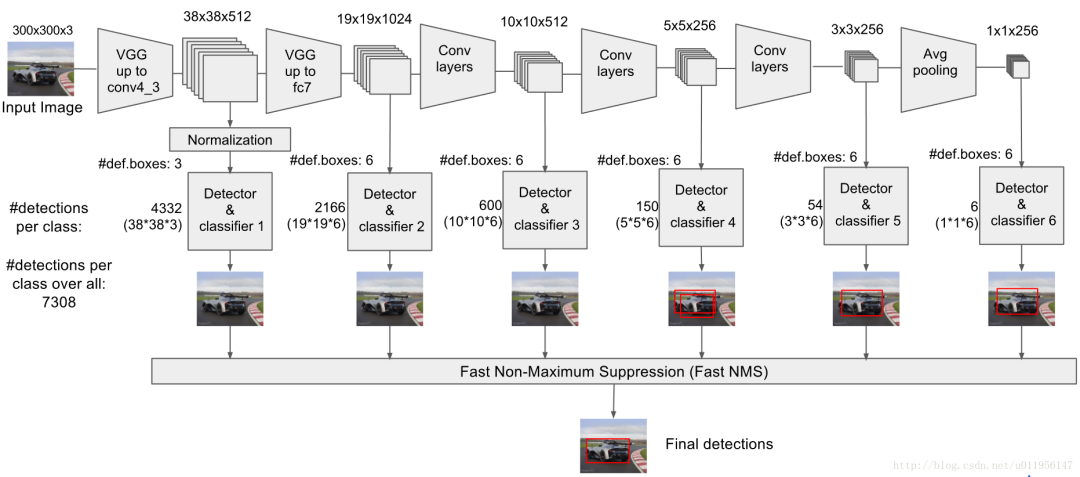
多尺度特征图具体表示就是SSD在整个网络的不同位置,取出相应的特征层进行预测,每个特征层因为尺度不一样可以检测的视野以及目标物体的大小也不同。每个特征图可以预测出分类信息和位置信息,如下图中可以看到整个网络使用从前到后使用了6个不同的特征图,从38x38x512到1x1x256一共六个不同尺度的特征图。
也就是使用低层feature map检测小目标,使用高层feature map检测大目标,是SSD的突出贡献。
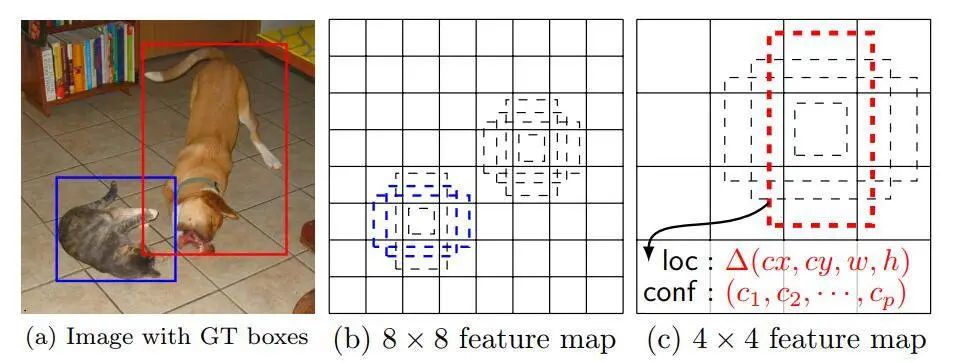
那么default box是如何产生?
default box
论文中的原话是这样的:
We associate a set of default bounding boxes with each feature map cell, for multiple feature maps at the top of the network. The default boxes tile the feature map in a convolutional manner, so that the position of each box relative to its corresponding cell is fixed. At each feature map cell, we predict the offsets relative to the default box shapes in the cell, as well as the per-class scores that indicate the presence of a class instance in each of those boxes.
就是对于上述每一个不同尺度的特征图(38x38、19x19、10x10、5x5、3x3、1x1),每一个特征图中的坐标中(cell)产生多个default box。对于每个default box,SSD预测出与真实标定框的偏移(offsets,一共是4个数值,代表位置信息)以及对应于每个类的概率confidence()。如果一共有c类,每一个坐标产生k个box,那么我们在进行训练的时候,每个cell就会产生(c+4)k个数据,如果特征图大小为mxn,那么总共就是(c+4)kmn,例如3x3的特征图,mxn就是3x3。
注意下,上述的那个offset不仅是相对于default box,换个角度来说,也是相对于真实标定框的偏移,通俗了说就是default box加上offsets就是真实标定框的位置。这个offsets是我们在训练学习过程中可以计算出来用于损失函数来进行优化的。
在实际预测中,我们要预测出每个default box的category以及对应的offset。
这部分我看到更好的介绍,所以这里不进行赘述,可以直接看这里:解读SSD中的Default box(Prior Box)。
训练过程
不光要从论文中理解一个网络的细节部分,还需要详细了解一下训练的具体过程:
因为我们要在特征图上生成default box,那么在训练阶段我们就需要将GT(Ground Truth)与default box相对应才能进行训练,怎么个对应法,SSD中使用了一个IOU阈值来控制实际参与计算的default box的数量,这一步骤发生在数据准备中:

首先要保证每个GT与和它度量距离最近的(就是iou最大)default box对应,这个很重要,可以保证我们训练的正确性。另外,因为我们有很多很多的default box,所以不只是iou最大的default box要保留,iou满足一定阈值大小的也要保留下来。
也就是说,训练的过程中就是要判断哪个default boxes和具体每一张图中的真实标定框对应,但实际中我们在每个特征图的每个cell中已经产生了很多default boxes,SSD是将所有和真实标定框的IOU(也就是jaccard overlap)大于一定阈值(论文中设定为0.5)的default boxes都保留下来,而不是只保留那个最大IOU值的default box(为什么要这么做,原论文中说这样有利于神经网络的学习,也就是学习难度会降低一些)。
这样我们就在之前生成的default boxes中,精挑细选出用于训练的default boxes(为了方便,实际训练中default boxes的数量是不变的,只不过我们直接将那些iou低于一定阈值的default boxes的label直接置为0也就是背景)。
损失函数
损失函数也是很简单,一共有俩,分别是位置损失以及分类损失:
其中为matched default boxes的数量,这个就是训练过程一开始中精挑细选出来的default boxes。当为0的时候,此时总体的损失值也为0。而是通过交叉验证最终得到的权重系数,论文中的值为1。
位置损失
其中表示当前defalut box是否与真实的标定框匹配(第个defalut box与第个真实的标定框,其中类别是),经过前面的match步骤后,有大于等于1。
注意,上式中的是进行变化后的GroundTruth,变化过程与default box有关,也就是我们训练过程中使用的GroundTruth值是首先通过default box做转换,转化后的值,分别为,这四个值,分别是真实的标定框对应default box的中心坐标以及宽度和高度的偏移量。
也就是下面四个转换关系,稍微花一点心思就可以看明白,在训练的时候实际带入损失函数的就是下面这四个转化后的值:
同理,既然我们在训练过程中学习到的是default box -> GroundTruth Box的偏移量,那么我们在推测的时候自然也要有一个相反的公式给计算回来,将上面的四个公式反转一下即可。
分类损失
分类损失使用交叉熵损失,
需要注意一点就是代表此时的预测box是否与真实标定框匹配,匹配则为1,也就是说分类损失前半部分只考虑与label匹配的,也就是positive boxes。而后半部分则表示背景分类的损失,即negative boxes的损失,想要让越大(背景正确被分为背景),就必须让后半部分的损失越小。
Hard negative mining
这个过程发生在实际训练过程中,因为图像中预测出来的box有很多,而且大部分是negative boxes,所以这里将消除大部分的negative boxes从而使positive与negative的比例达到1:3。首先对之前经过match步骤,精挑细选之后的default boxes计数。这些default boxes算是positive default boxes,算出此时positive的数量,然后乘以3则是negative boxes的数量。
那么如何去挑选合适数量的negative boxes?SSD中的挑选规则是:挑选loss最大的boxes,也就是最难学的boxes,根据预测出来的confidence来判断(这段部分的实现可能与论文中会有所不同),那么什么算最难学的,因为我们首先已经根据label(这个label是之前matching过程后的label,label的数量与整张特征图中的boxes数量相同,只不过其中的label已经根据matching步骤进行了调整)得到了positive boxes,这些positive boxes与实际目标都满足一定的条件,而且其中很大概率都有物体。那么最难学的boxes该如何挑选呢?
我们在其余的boxes中,因为其余的这些boxes已经不可能包含目标(因为有目标的在matching中都已经被挑选了,这些是剩下的),所以这些boxes的label理应被预测为background也就是背景,所以这些boxes关于背景的损失值应该是比较小的,也就是模型较为正确预测了背景。那么我们要选最难识别的boxes,也就是最难识别为背景的boxes,这些叫做negative boxes,首先我们将其余的这些boxes关于背景的loss排序,然后选取前面一定数量(与positive boxes的比值是3:1)的boxes作为negative boxes即可。
这段描述可能有些抽象,配上代码可能更好看一些:
def hard_negative_mining(loss, labels, neg_pos_ratio):
"""
It used to suppress the presence of a large number of negative prediction.
It works on image level not batch level.
For any example/image, it keeps all the positive predictions and
cut the number of negative predictions to make sure the ratio
between the negative examples and positive examples is no more
the given ratio for an image.
Args:
loss (N, num_priors): the loss for each example.
labels (N, num_priors): the labels.
neg_pos_ratio: the ratio between the negative examples and positive examples.
"""
pos_mask = labels > 0
num_pos = pos_mask.long().sum(dim=1, keepdim=True)
num_neg = num_pos * neg_pos_ratio
loss[pos_mask] = -math.inf # put all positive loss to -max
_, indexes = loss.sort(dim=1, descending=True) # sort loss in reverse order (bigger loss ahead)
_, orders = indexes.sort(dim=1)
neg_mask = orders return pos_mask | neg_mask
图像增强
SSD中已经采取了一些比较好的图像增强方法来提升SSD检测不同大小不同形状的物体,那就是randomly sample,也就是随机在图像片进行crop,提前设定一些比例,然后根据这个比例来对图像进行crop,但是有一点需要注意那就是这个randomly sample中需要考虑到IOU,也就是我们crop出来的图像必须和原始图像中的GT box满足一定的IOU关系,另外crop出来的图像也必须满足一定的比例。
通过randomly sample后的图像其中必定包含原始的GT boxes(不一定全包含),而且crop后的boxes也是正确的。
这部分说起来比较抽象,可以看看这篇文章,我自己懒得进行演示了:
- 目标检测:SSD的数据增强算法(https://blog.csdn.net/zbzb1000/article/details/81037852)
学习率设置
- 官方:优化器使用SGD,初始的学习率为
0.001,momentum为0.9,weight-decay为0.0005,batch-size为32。 - 我个人和官方使用的优化器相同,只不过在学习率上通过
multi-step的方式(具体可以看Pytorch相关实现部分),在80和150个epoch阶段将学习率衰减至之前的1/10。一共训练300个epoch。
训练部分的系数设置仅供参考,不同数据的训练系数略有不同。
预训练权重
个人使用mobilenetv2-SSD的构架对自己的数据进行了训练,在所有超参数和训练系数不变的情况下,如果采用预训练好的mobilenetv2的权重(在ImageNet上),那么训练速度和最终的训练精度都会高出一截(相同epoch下),所以采用预训练好的权重信息很重要。
总结
SSD是一个优雅的目标检测结构,到现在依然为比较流行的目标检测框架之一,值得我们学习,但是SSD对小目标的检测效果有点差,召回率不是很高,这与SSD的特征图以及semantic语义信息有关,另外SSD中也提到了一些对于提升mAP的原因,其中很大部分是因为图像增强部分,之前提到的random patch可以变相地理解为对图像进行"zoom in"或者"zoom out",也就是方法或者缩小,这样增强了网络监测大目标和小目标的能力(但监测小目标的能力还是稍微差一点)。
对于SSD的更多讨论,我这里也收集了一些其他优秀的文章,这里就不赘述了:
- SSD究竟如何实现功能以及如何优化--个人探讨(https://zhuanlan.zhihu.com/p/63700297)
- 为什么SSD(Single Shot MultiBox Detector)对小目标的检测效果不好?(https://www.zhihu.com/question/49455386/answer/135983998)
本文为SSD系列第一篇,主要讲解一些原理,之后还会有SSD具体实战部署以及加速相关文章,以及对Anchor的代码级别详细讲解,请关注??
来者是客
如果你喜欢这里的内容
如果你觉得很有收获
如果你和我一样有着相似的想法
不妨留个言吧

- OpenVino初探(实际体验)
- 一个Tensor的生命历程(Pytorch版)-上篇
- 解密Deepfake(深度换脸)-基于自编码器的(Pytorch代码)换脸技术
- 利用TensorRT对深度学习进行加速
- 深度学习快一年,作为研究生,谈谈自己的感受

最后
以上就是呆萌书包最近收集整理的关于ssd网络结构_封藏的SSD(Single Shot MultiBox Detector)笔记前言网络构架总结的全部内容,更多相关ssd网络结构_封藏的SSD(Single内容请搜索靠谱客的其他文章。








发表评论 取消回复