前言
卷积神经网络从2012年开始逐步火热起来。我是在2017年开始接触深度学习技术,完成硕士课题研究,在2019年毕业后以算法工程师职位进入AI创业公司,如今工作3年了。俗话说,温故而知新,结合自己这几年的工作经验,再重新回顾一些那些年是一知半解的,经典的深度学习网络,从大牛的视野看这些网络的设计和迭代。希望对今后工作学习更有帮助。
互联网的兴起带来的好处之一是,只要你想学习,总有很多免费网络资源。而学术界的研究院,科学家们也在不遗余力的推广深度学习技术,让更多的人了解入门深度学习,做了很多免费的视频课,出了相关的书。本系列博文的内容就是来自于亚马逊资深首席科学家、AI大牛李沐的D2L-ai系列课程。博文内容大多数来自该课程,主要是自己的学习笔记,以及个别思考,重新完善自己的知识体系。
序言 — 动手学深度学习 2.0.0-beta0 documentation
GitHub - d2l-ai/d2l-zh: 《动手学深度学习》:面向中文读者、能运行、可讨论。中英文版被55个国家的300所大学用于教学。
目标检测和边界框
图像分类是计算机视觉里面比较简单的任务,目标检测是计算机视觉里面应用最广的任务。
图像分类:识别图片里面的一个主体。
目标检测:识别图片里面所有感兴趣的物体,以及他们的位置。
物体的位置用边缘框来表示,一个边缘框用4个数字来定义
(左上x,左上y, 右下x,右下y),或者(左上x, 左上y, 宽,高)
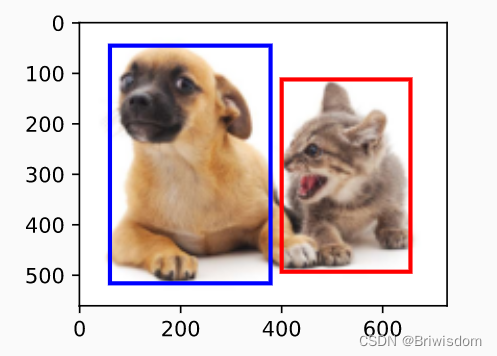
目标检测的数据集
数据集文本每行表示一个物体,排列顺序:图片文件名,物体类别,边缘框
Pascal VOC数据集
20个目标类别,包含图像分类,目标检测,目标分割,行为识别等任务。
COCO数据集
80物体,330k图片,1.5M物体
锚框的概念
目标检测模型的一个通用做法是,提前在图像上选取一些位置,形状不同的框,然后根据标注的真实框的类别,给这些预选框做标记,使用深度神经网络算法做训练预测。
预选框的一个选取方法是:
提前定义边缘框的面积sizes和高宽比ratio,然后再每个像素点根据sizes={s0,s1,...sn}和ratio={r0,r1,... rm}组合生成目标框。尽管这些锚框可能会覆盖所有真实边界框,但计算复杂性很容易过高。 在实践中,我们只考虑包含s1或r1的组合:(s1,r1),(s1,r2),...,(s1,rm),(s2,r1),(s3,r1),...(sn,r1)
所以对于宽高为w,h的图像,生成共计 w*h(n+m-1)个锚框。
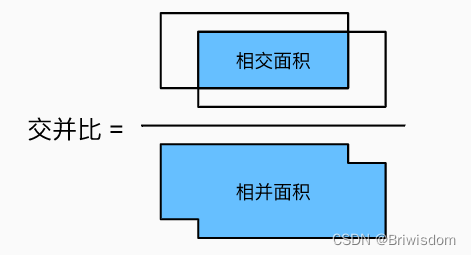
交并比
如何把预选框和真实框的类别对应起来,给这些预选框做label呢?这里需要用到交并比的概念。就是两个边界框相交的面积与相并的面积之比。交并比的取值范围在0-1之间:0表示两个边界框无重合像素,1表示两个边界框完全重合。
在训练数据中标注锚框
在训练集中,我们将每个锚框视为一个训练样本。 为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签,其中前者是与锚框相关的对象的类别,后者是真实边界框相对于锚框的偏移量。 在预测时,我们为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
假设一个图像上有n个需要识别的目标框,使用锚框规则提前生成了m个预选框。可以按照如下步骤给这些锚框标注标签。
1,定义一个m行,n列的矩阵arr[m][n],分别计算m个预选框与n个真实框的交并比,并填入。
2,找到矩阵arr中最大的交并比值,其所在的位置为i,j。则把第i个预选框的类别标记为第j个真实框的类别。
3,从arr中移除掉第2步的第i行j列。重复第2步,直到所有真实框都分配给了一个预选框。
训练的时候,所有预选框都会做分类任务,但是对于没有标记为类别的背景框,做一个mask标记,在做坐标偏移回归任务时候,这些背景框不做梯度回传。只有真实的框才会回传梯度。
非极大值抑制简化预测的边界框
在预测时,我们先为图像生成多个锚框,再为这些锚框一一预测类别和偏移量。 一个“预测好的边界框”则根据其中某个带有预测偏移量的锚框而生成。
锚框和原图相对位置的还原
假设scale为缩放比, ratio为宽高比,原图高宽是H,W, 锚框的高宽是sh,sw,如下设置,保证 sw/sh =ratio。实际中,可以根据任务自定义换算的公式。
sh=scale/sqrt(ratio)* H
sw=scale*sqrt(ratio) * H
标记类别和边缘框的偏移量
假设一个锚框A被分配了一个真实边界框B。 一方面,锚框A的类别将被标记为与B相同。 另一方面,锚框A的偏移量将根据B和A中心坐标的相对位置以及这两个框的相对大小进行标记。 鉴于数据集内不同的框的位置和大小不同,我们可以对那些相对位置和大小应用变换,使其获得分布更均匀且易于拟合的偏移量。 在这里,我们介绍一种常见的变换。 给定框A和B,中心坐标分别为(xa,ya)和(xb,yb),宽度分别为wa和wb,高度分别为ha和hb。 我们可以将A的偏移量标记为:
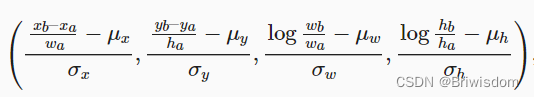
其中常量的默认值为 μx=μy=μw=μh=0,σx=σy=0.1 , σw=σh=0.2。
如果一个锚框没有被分配真实边界框,我们只需将锚框的类别标记为“背景”(background)
边缘框偏移的计算:
首先把预测框和真实框的写法,由(x1,y1,x2,y2)改变为(x,y,w,h)形式,x,y是边缘框中心点的坐标。根据上面的偏移公式,由预选框的x,y,w,h,和模型训练的偏移坐标x,y,w,h还原到预测的真实框坐标。
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset非极大值抑制
当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。 为了简化输出,我们可以使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
以下是非极大值抑制的工作原理。 对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。 假设最大的预测概率为p,则该概率所对应的类别B即为预测的类别。 具体来说,我们将p称为预测边界框B的置信度(confidence)。 在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表L。然后我们通过以下步骤操作排序列表L:
-
从L中选取置信度最高的预测边界框B1作为基准,然后将所有与B1的IoU超过预定阈值ϵ的非基准预测边界框从L中移除。这时,L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了。
-
从L中选取置信度第二高的预测边界框B2作为又一个基准,然后将所有与B2的IoU大于ϵ的非基准预测边界框从L中移除。
-
重复上述过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预测边界框的IoU都小于阈值ϵ;因此,没有一对边界框过于相似。
-
输出列表L中的所有预测边界框。
多尺度目标检测
往往一张图像上的目标是多种尺度的,如果相差较大,就需要在特征图的不同尺度上进行预测才能带来更好的效果。对于卷积神经网络来说,通过网络层数的叠加获取更宽视野的特征图。比如当设置卷积核尺寸为3*3,stride=1时候,第一层卷积之后特征图的一个像素点代表原图上3*3像素区域的视野,第二层卷积之后,特征图的一个点代表原图5*5像素点的视野。
当不同层的特征图在输入图像上分别拥有不同大小的感受野时,它们可以用于检测不同大小的目标。 例如,我们可以设计一个神经网络,其中靠近输出层的特征图单元具有更宽的感受野,这样它们就可以从输入图像中检测到较大的目标。简言之,我们可以利用深层神经网络在多个层次上对图像进行分层表示,从而实现多尺度目标检测。
单发多框检测(SSD)
该模型在目标检测领域属于one-stage模型,即目标框分类和预测一步完成。像RCNN系列属于先进行粗粒度目标框分类和回归,再进行系粒度的分类回归预测两步走模型。
单发多框检测是一种多尺度目标检测模型。基于基础网络块和各个多尺度特征块,单发多框检测生成不同数量和不同大小的锚框,并通过预测这些锚框的类别和偏移量检测不同大小的目标。
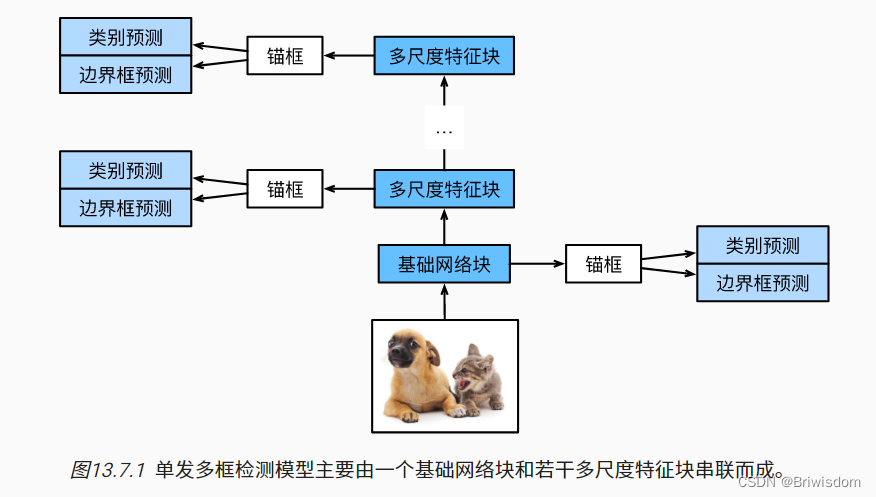
类别和边界框预测层
由一个二维卷积层实现类别预测和边界框回归预测,比如锚框有num_anchors, 类别有num_classes时候,卷积层的类别预测输出通道是num_anchors*(num_classes+1), 类别加1为背景类。边界框预测的通道是num_anchors*4, 一个框由4个值组成。
锚框参数的设置
由上文可知,预选的目标框需要提前给定scale的sizes参数可高宽比参数ratios。ratios一般大家都设置为1,2,0.5,而ratios可以在不同尺度下,有规律的设置一些值。比如在小尺度上设置更小的size,大目标尺度上设置较大的size。均匀分布吧。
比如,每个尺度设置两个sizes值,较小的为0.2、0.37、0.54、0.71和0.88,他们较大的值由sprt(0.2×0.37)=0.272、sqrt(0.37×0.54)=0.447等给出。即
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
区域卷积神经网络(R-CNN)系列
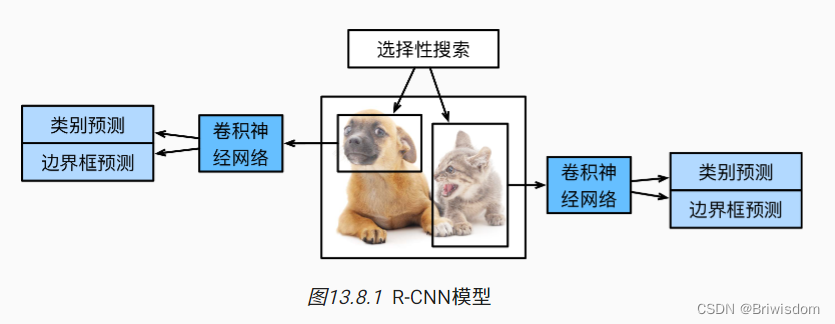
R-CNN
尽管R-CNN模型通过预训练的卷积神经网络有效地抽取了图像特征,但它的速度很慢。R-CNN包含以下步骤,
-
对输入图像使用选择性搜索来选取多个高质量的提议区域 [Uijlings et al., 2013]。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
-
选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征。
-
将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别。
-
将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
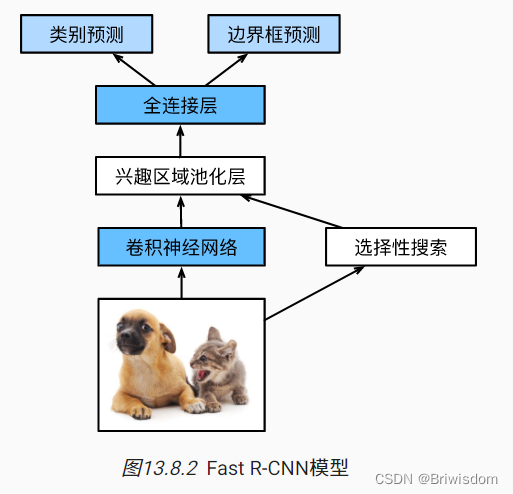
Fast-RCNN
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。 由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。 Fast R-CNN [Girshick, 2015]对R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播。
Fast-RCNN的主要计算如下:
-
与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。此外,这个网络通常会参与训练。设输入为一张图像,将卷积神经网络的输出的形状记为1×c×h1×w1。
-
假设选择性搜索生成了n个提议区域。这些形状各异的提议区域在卷积神经网络的输出上分别标出了形状各异的兴趣区域。然后,这些感兴趣的区域需要进一步抽取出形状相同的特征(比如指定高度h2和宽度w2),以便于连结后输出。为了实现这一目标,Fast R-CNN引入了兴趣区域汇聚层(RoI pooling):将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为n×c×h2×w2。
-
通过全连接层将输出形状变换为n×d,其中超参数d取决于模型设计。
-
预测n个提议区域中每个区域的类别和边界框。更具体地说,在预测类别和边界框时,将全连接层的输出分别转换为形状为n×q(q是类别的数量)的输出和形状为n×4的输出。其中预测类别时使用softmax回归。
Faster-RCNN
为了较精确地检测目标结果,Fast R-CNN模型通常需要在选择性搜索中生成大量的提议区域。 Faster R-CNN [Ren et al., 2015]提出将选择性搜索替换为区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
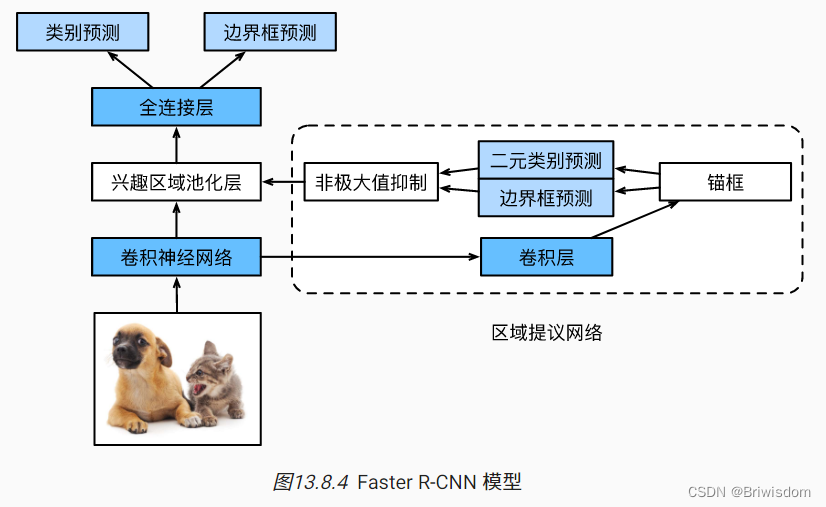
与Fast R-CNN相比,Faster R-CNN只将生成提议区域的方法从选择性搜索改为了区域提议网络,模型的其余部分保持不变。具体来说,区域提议网络的计算步骤如下:
-
使用填充为1的3×3的卷积层变换卷积神经网络的输出,并将输出通道数记为c。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为c的新特征。
-
以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
-
使用锚框中心单元长度为c的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
-
使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
值得一提的是,区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。 换句话说,Faster R-CNN的目标函数不仅包括目标检测中的类别和边界框预测,还包括区域提议网络中锚框的二元类别和边界框预测。 作为端到端训练的结果,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少了从数据中学习的提议区域的数量的情况下,仍保持目标检测的精度。
Mask R-CNN
Mask R-CNN是基于Faster R-CNN修改而来的。 具体来说,Mask R-CNN将兴趣区域汇聚层替换为了 兴趣区域对齐层,使用双线性插值(bilinear interpolation)来保留特征图上的空间信息,从而更适于像素级预测。 兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图。 它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置。
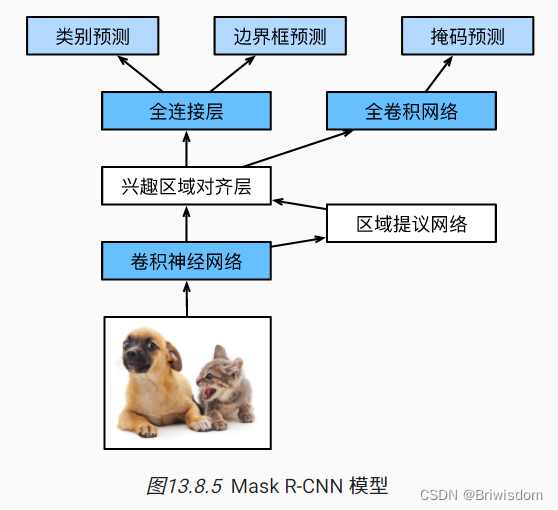
小结
-
R-CNN对图像选取若干提议区域,使用卷积神经网络对每个提议区域执行前向传播以抽取其特征,然后再用这些特征来预测提议区域的类别和边界框。
-
Fast R-CNN对R-CNN的一个主要改进:只对整个图像做卷积神经网络的前向传播。它还引入了兴趣区域汇聚层,从而为具有不同形状的兴趣区域抽取相同形状的特征。
-
Faster R-CNN将Fast R-CNN中使用的选择性搜索替换为参与训练的区域提议网络,这样后者可以在减少提议区域数量的情况下仍保证目标检测的精度。
-
Mask R-CNN在Faster R-CNN的基础上引入了一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度。
最后
以上就是要减肥钥匙最近收集整理的关于深度学习二三事-计算机视觉目标检测回顾目标检测和边界框多尺度目标检测的全部内容,更多相关深度学习二三事-计算机视觉目标检测回顾目标检测和边界框多尺度目标检测内容请搜索靠谱客的其他文章。








发表评论 取消回复