faster-rcnn
faster-rcnn loss主要分为两个部分RPN的loss和fast-rcnn部分的loss:
1.rpn loss
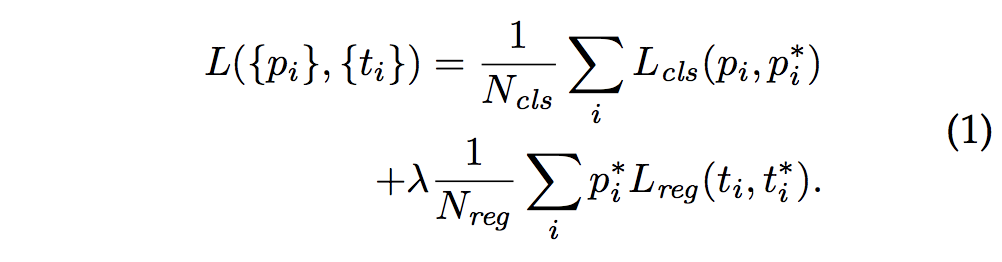
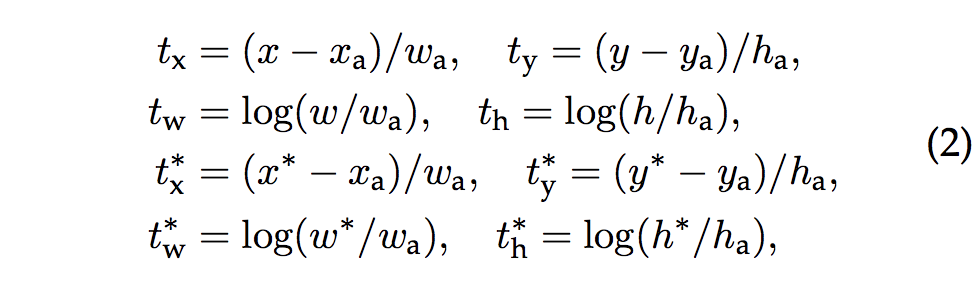
分为两个部分,其中cls就是BCE loss,而reg用的是smooth L1 loss
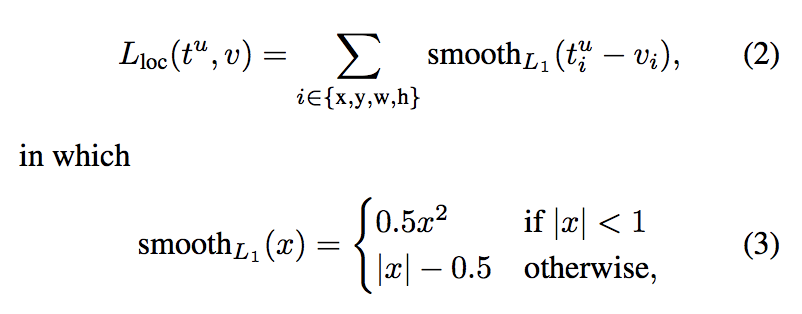
为什么使用这种loss,文章中的说法是对异常点更加鲁棒,x大于1之后,梯度都是常量了。这边要注意的就是,他并不是对(x,y,w,h)原值进行回归,(x,y)使用对应的b-box进行了normalize,(w,h)也是用b-box对应的参数相除之后求对数。我的理解是做归一化后,达到同一尺度,可以加快训练或者提升训练效果。
2.faster-rcnn loss
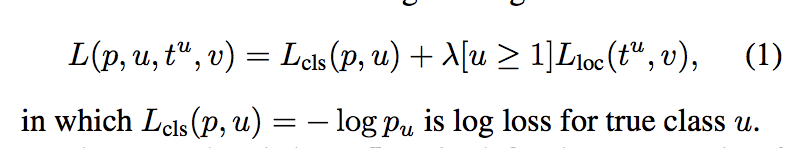
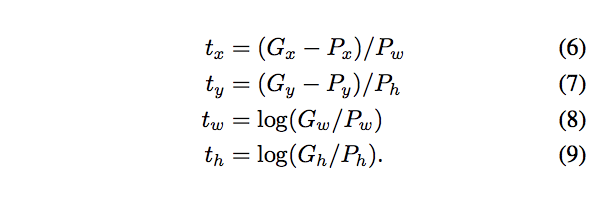
基本上跟rpn的loss差不多,要注意的就是rpn分类只分前后景,这边会分所有类别。
还有个想说的就是:
rpn在feature map 的同一个位置上,不同的anchors都用相同的feature,而在fast-rcnn部分,会根据proposals的size去做roipooling。
yolov3
yolo这边除了v1,v2和v3都没有在论文里面把loss具体写出来,这边主要根据源码详述一下yolov3的loss。
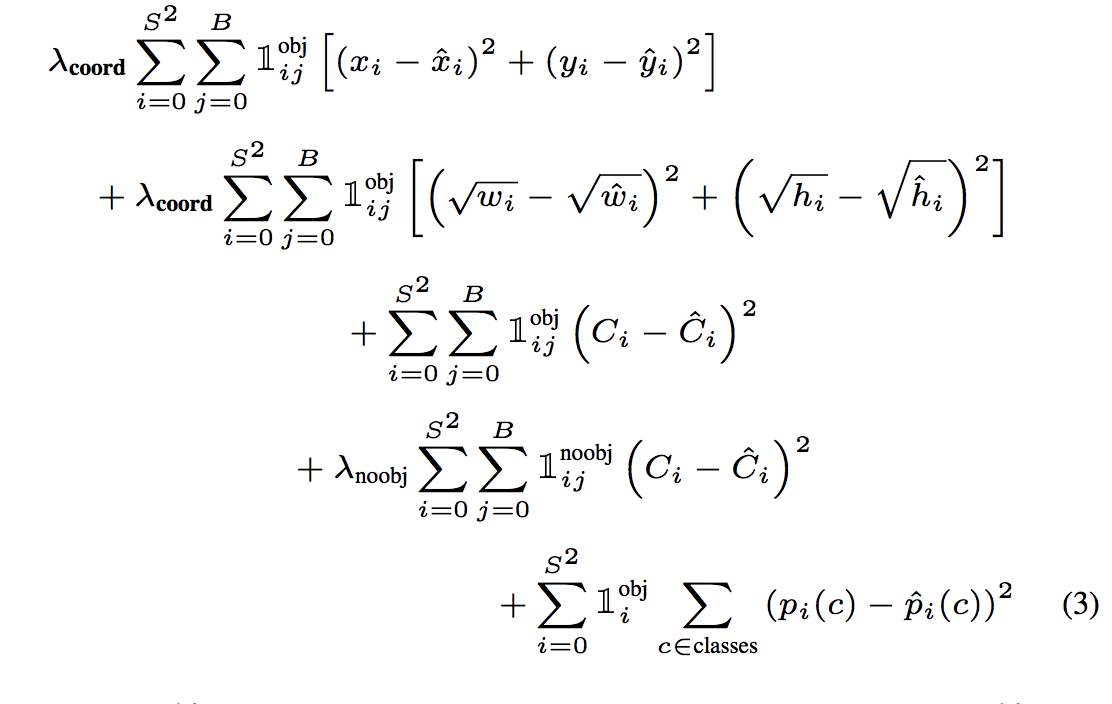
这边回归的loss就比较粗糙,直接是sum square error,虽然w,h加了个root,但是loss还是对小物体不友好。
关于V3的loss,我这边大概描述一下,具体的可参考:https://blog.csdn.net/weixin_42078618/article/details/85005428
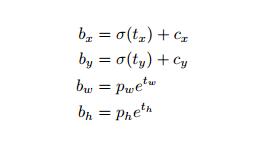
其中t是我们的预测值,b是我们的目标值。
但是根据源码,(x,y)的预测值更像是sigmoid(t),而不是t。
各个loss
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + (1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
比较奇怪的就是xy_loss为什么会用交叉熵,我的理解就是xy经过sigmoid也缩放到了0-1,所以可以。
wh_loss就是square loss。
置信度就是一个BCE。
分类loss就是多个BCE(因为是多个二分类,文章中说使用softmax并没有产生一个比较好的结果,我觉得还有可能是V2中9000多类不互斥吧)。
SSD
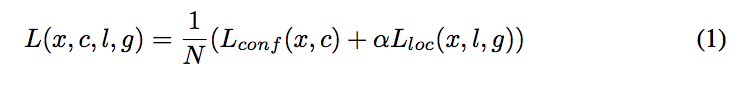
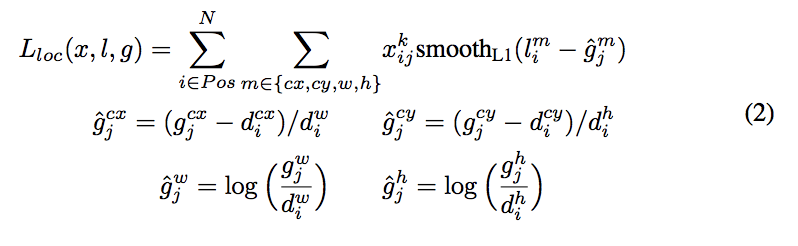
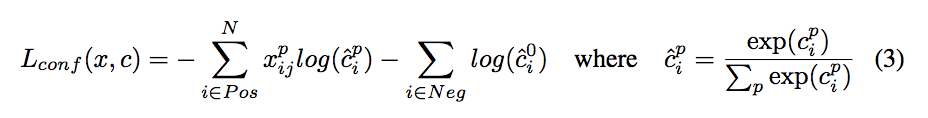
基本上跟faster-rcnn一致吧,没什么特别的改动。smoothL1加softmax
最后
以上就是喜悦网络最近收集整理的关于faster-rcnn、yolov3和ssd loss总结faster-rcnnyolov3SSD的全部内容,更多相关faster-rcnn、yolov3和ssd内容请搜索靠谱客的其他文章。








发表评论 取消回复